構想網格數據庫架構設計 實現海量數據處理
對于一個具有海量數據的系統來說,性能的瓶頸最終就只能落在數據庫身上了,這時候硬件升級和程序優化已經是無能為力,一個簡單的查詢也有可能給數據庫帶來沉重的負擔。網格計算可把把一個需要巨大的計算能力才能解決的問題分割成許多小部分,然后把這些小部分分配給許多計算機進行處理,***把這些計算結果綜合起來得到最終結果。對數據庫進行網絡計算的架構設計,無疑可能解決上述的性能問題。
那么怎么把一個巨大的數據庫分割成許多小的數據庫呢?現階段比較行之有效的方法是對數據庫進行分區處理。對于一個巨大容量的數據表,可不可以按日期,或者按類型,或者按區域,或者按ID號進行分割呢?答案是肯定的,這種分區方法也就是所謂的水平分區方法。另一方面,對于不同類型的數據,比如一個電子商務系統中的用戶數據、商品數據、交易數據等,它們之間的聯系不是很緊密,可以存放在不同的數據庫中,這樣就可實現了垂直分區。
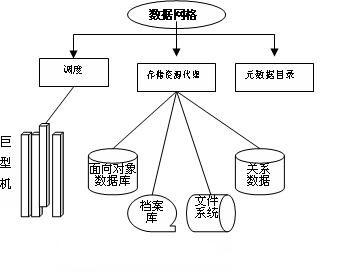
經過分區處理,一個大的數據庫,可以分成許多小的數據庫。但是這樣一來,對于這些小數據庫的訪問,和怎么進行綜合處理,就引發出新的問題出來了。
在一個系統中,對這些數據庫進行訪問不是沒有可能,使用多個連接,多重處理,無論在哪種框架中都很容易實現。問題是,在一個系統中分別對這些數據庫進行訪問,其程序的復雜度和處理效率,有可能會產生出另一個瓶頸,這就不是我們需要的結果了。當然也可以使用負載均衡設計,但是其程序的復雜度還是不可避免。
這里,再引進另一個概念:SOA架構,即面向服務的體系結構。SOA可以通過服務生產者/服務消費者的方式,或訂閱/發布的方式等提供松散耦合的分布式服務體系。那么,對于各個不同區域的數據庫,就可以按照SOA架構做成不同的服務中心,對外提供數據庫訪問接口。SOA可以使用CORBA、Web Service等方式予以實現。
這樣一來,數據庫服務器的壓力分散了,程序計算的壓力也分散了,不管數據庫的數據量有多大,程序計算有多復雜,系統的性能都能得到***限度的提升。
***,大家可能會說,如果有一個網格數據庫系統就好了,應用系統的設計就不用那么復雜了。是的,現在的數據庫系統也有向這一方向設計的趨勢,只是技術還沒有成熟。相信在不久的將來,應該可以用到網格數據庫。
原文標題:網格數據庫架構設計構想
鏈接:http://www.cnblogs.com/chrischen662/archive/2010/09/03/1817081.html
延伸閱讀
網格計算已經成為熱點,它所帶來的低成本、高性能以及方便的計算資源共享正是眾多企業所追求的。未來的數據庫將構筑在網格計算環境之上。
RAC(Real Application Cluster,真正應用集群)是Oracle9i數據庫中采用的一項新技術,也是Oracle數據庫支持網格計算環境的核心技術。它的出現解決了傳統數據庫應用中面臨的一個重要問題:高性能、高可伸縮性與低價格之間的矛盾。
除了RAC技術,Oracle9i數據庫還提供其他功能來支持網格計算,包括支持在數據庫之間進行數據快速復制的Transportable Tablespaces、支持數據流更新的Oracle Streams、支持應用可移植性的One Portable Codebase等。Mendelsohn認為,對那些需要建立數據中心的企業來說,Oracle9i RAC加上刀片服務器和Linux操作系統,就完全能夠替代傳統的基于大型機的數據系統。
準確的說應為支持網格的數據庫技術,Oracle10g中的g即為gridding網格。
【編輯推薦】