













SQL Server數(shù)據(jù)挖掘之理解聚類算法和順序聚類算法
最近與一個(gè)客戶的開發(fā)團(tuán)隊(duì)探討和學(xué)習(xí)SQL Server的數(shù)據(jù)挖掘及其應(yīng)用。有幾個(gè)比較有意思的問題,整理出來
關(guān)于數(shù)據(jù)挖掘的基本知識(shí)和學(xué)習(xí)資料,可以參考http://msdn.microsoft.com/zh-cn/library/bb510517.aspx
上一篇:SQL Server數(shù)據(jù)挖掘中的幾個(gè)問題之理解列的用法
這一篇我們來探討一下兩個(gè)有時(shí)候會(huì)引起混淆的算法:聚類和順序聚類
聚類算法是使用非常多的一種算法,它的作用是對(duì)數(shù)據(jù)進(jìn)行分組,將特征相近的實(shí)體組織在一起,以便幫助我們對(duì)于目標(biāo)實(shí)體分類決策。典型的情況,例如人口分析,客戶分析。
聚類算法大致的效果如下(下面的分類名都可以修改,定義成我們更加容易理解的,例如“金牌客戶”,“銀牌客戶”等等)

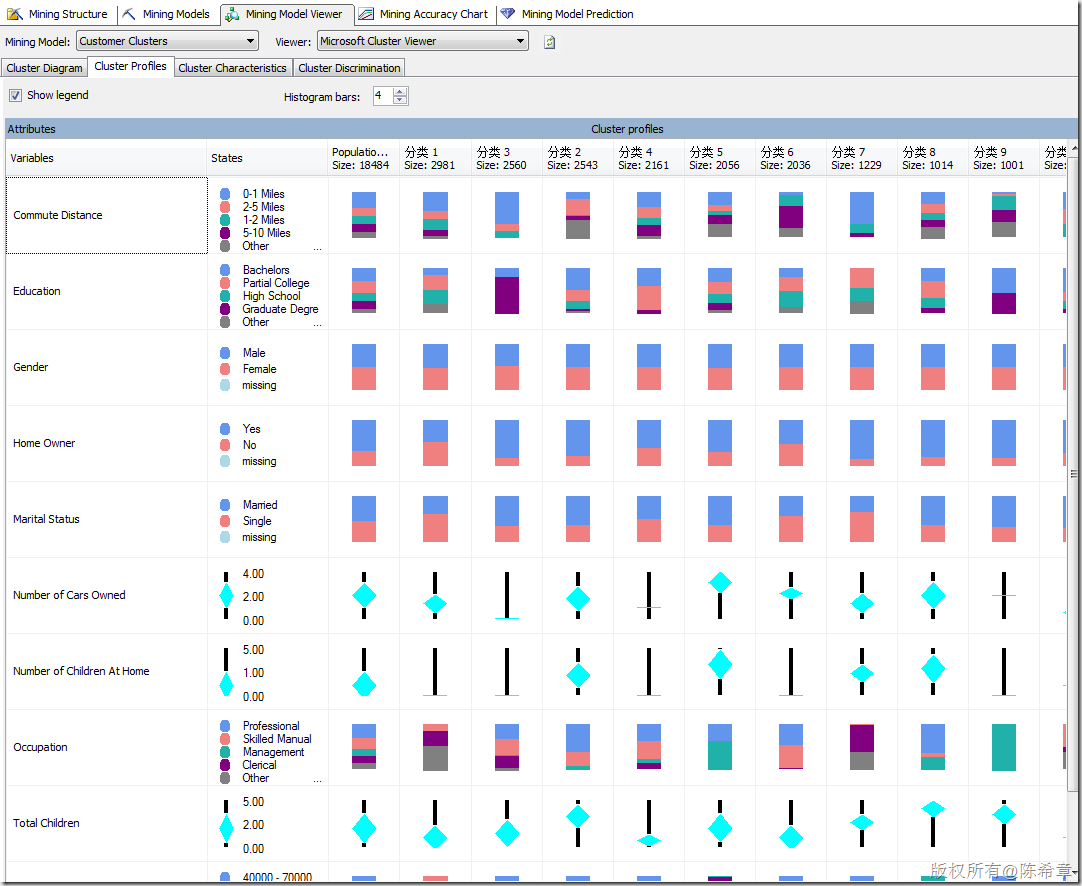
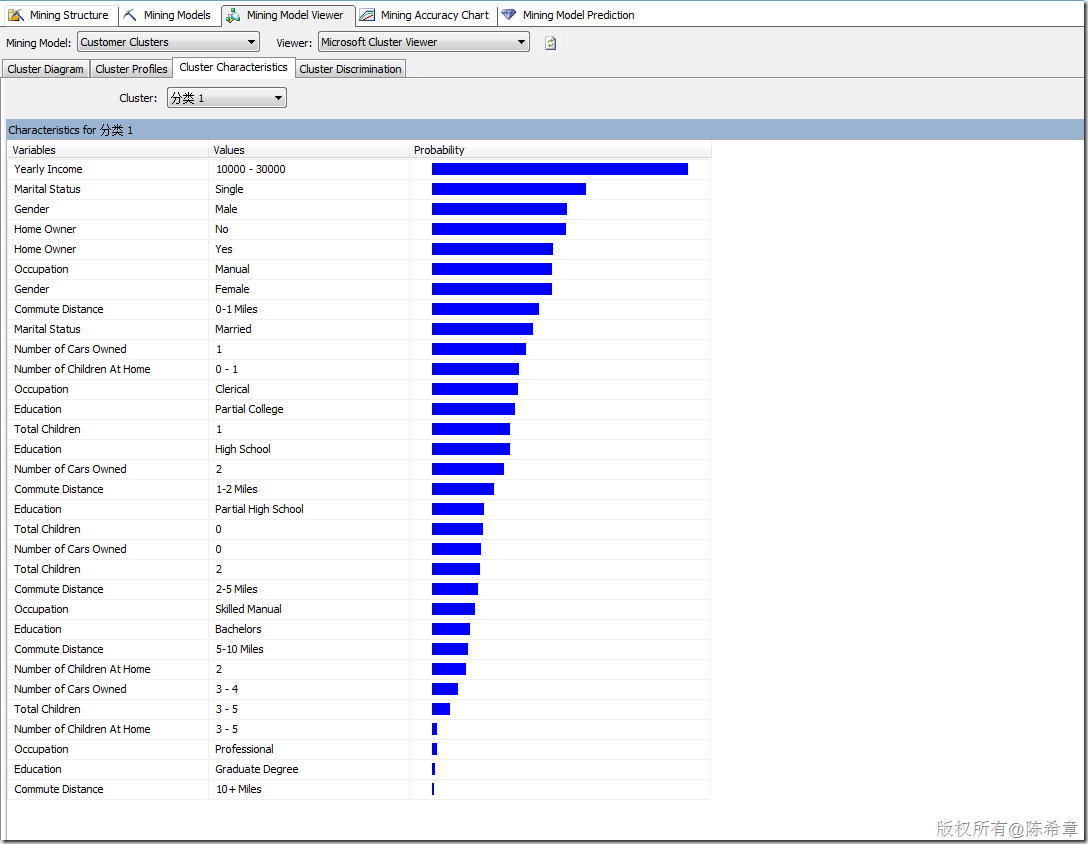
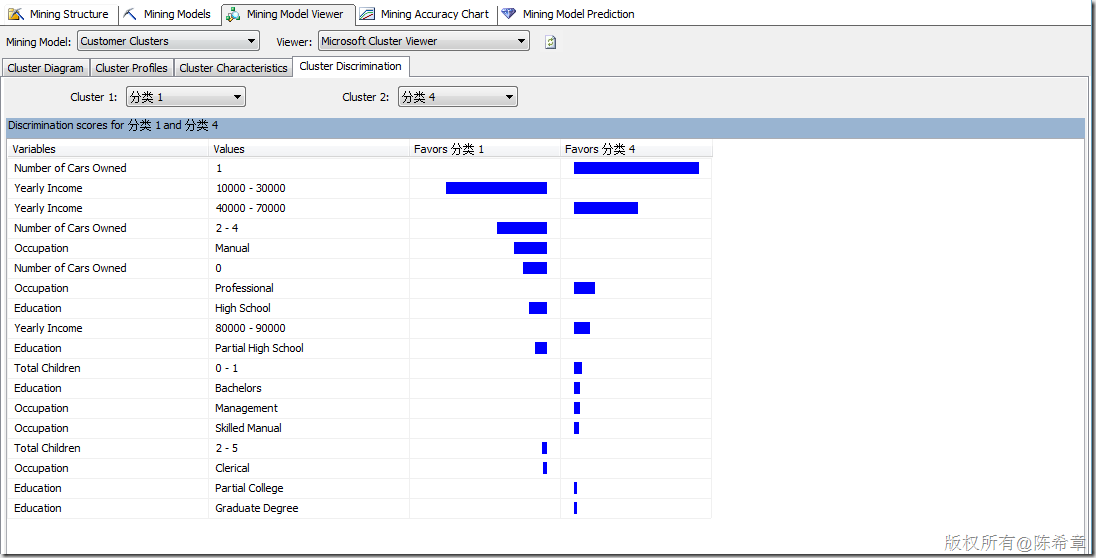
有關(guān)聚類算法,有一個(gè)常見的問題就是:同一個(gè)實(shí)體會(huì)不會(huì)出現(xiàn)在不同的類里面呢?也就是說是否有可能會(huì)有重疊的情況?
這個(gè)問題的答案是:是否有重疊的情況,取決于算法的設(shè)置,默認(rèn)情況下,是可能重疊的。
下面這個(gè)算法參數(shù)列表中,有一個(gè)CLUSTERING_METHOD,默認(rèn)為1.就是所謂的EM(Expectation Maximization)這種算法,這是允許重疊的。
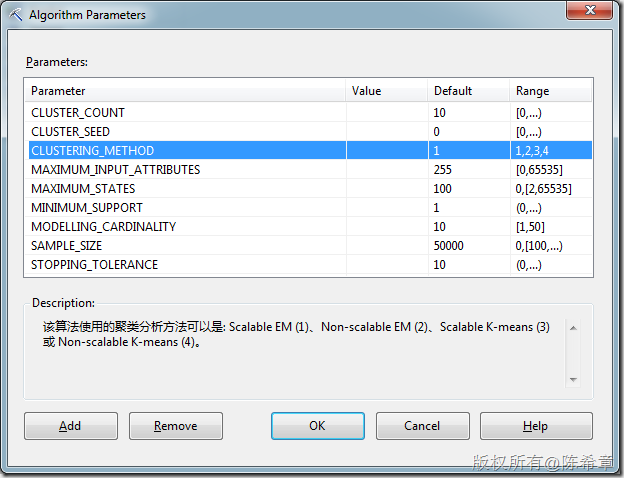
如果設(shè)置為3或者4,則不允許重疊。至于是否可以伸縮(Scalable)表示的是該算法讀取數(shù)據(jù)的規(guī)則,如果可伸縮,則表示會(huì)先讀取50000條記錄作為種子進(jìn)行建模,如果足夠,則停止讀取。否則繼續(xù)讀取下50000個(gè)。而不可伸縮則每次都讀取所有的實(shí)體。
那么,什么是“順序聚類”呢?其實(shí)它的完整名稱應(yīng)該是”Microsoft 順序分析和聚類分析”,也就是結(jié)合了順序分析和聚類分析的一種特殊的算法。
#p#
這個(gè)算法建立模型之后,大致看到的效果是下面這樣的
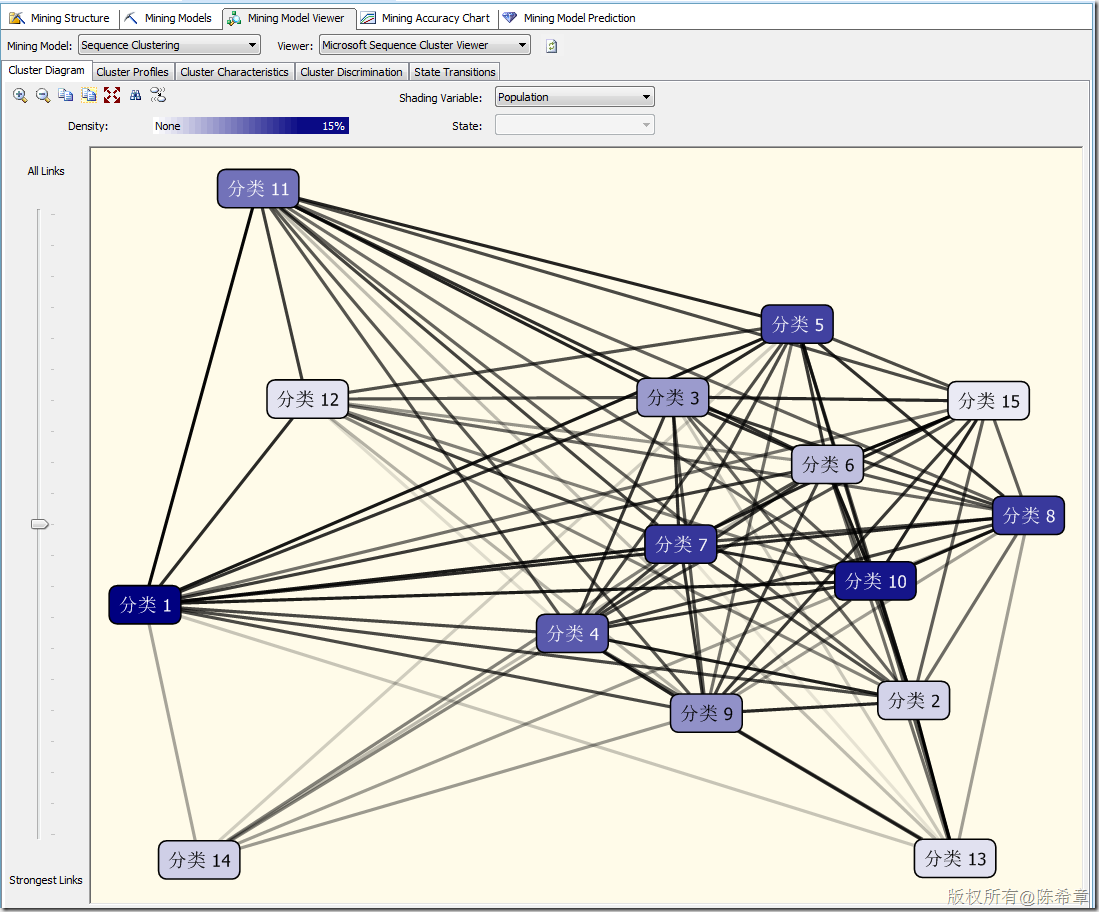
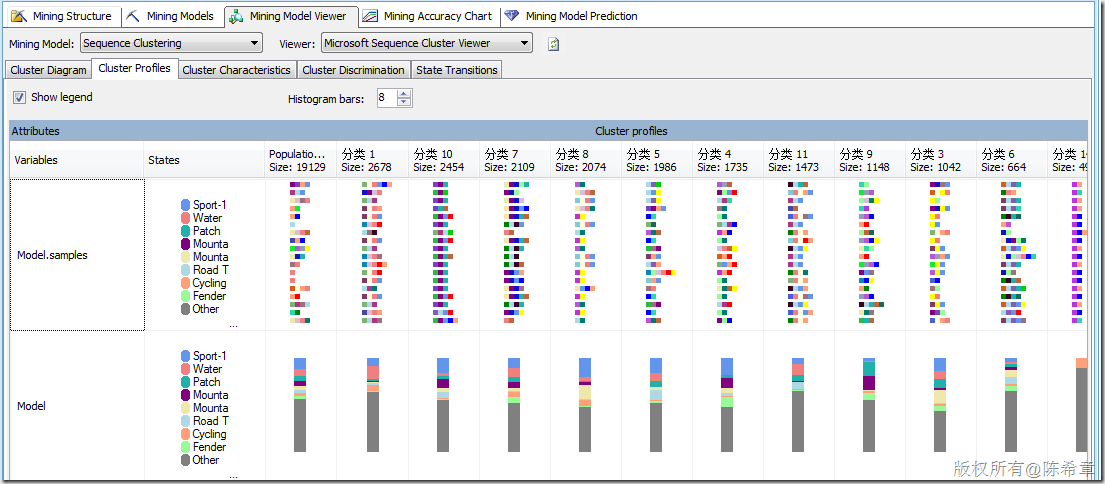
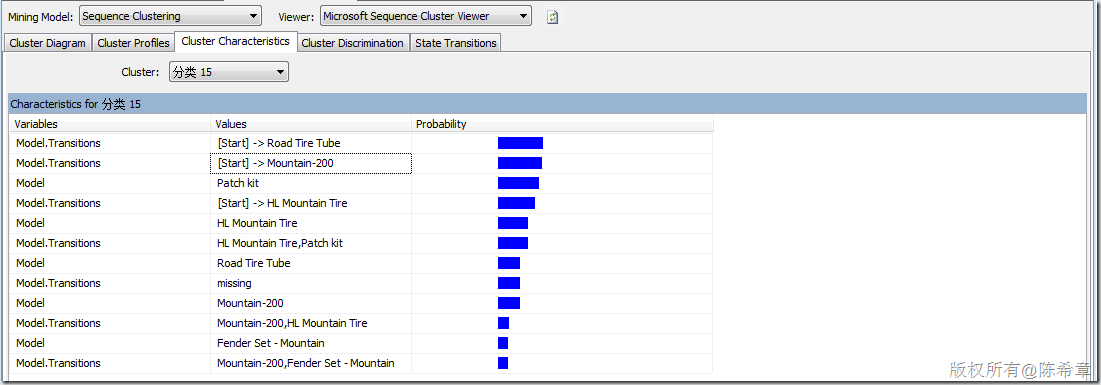
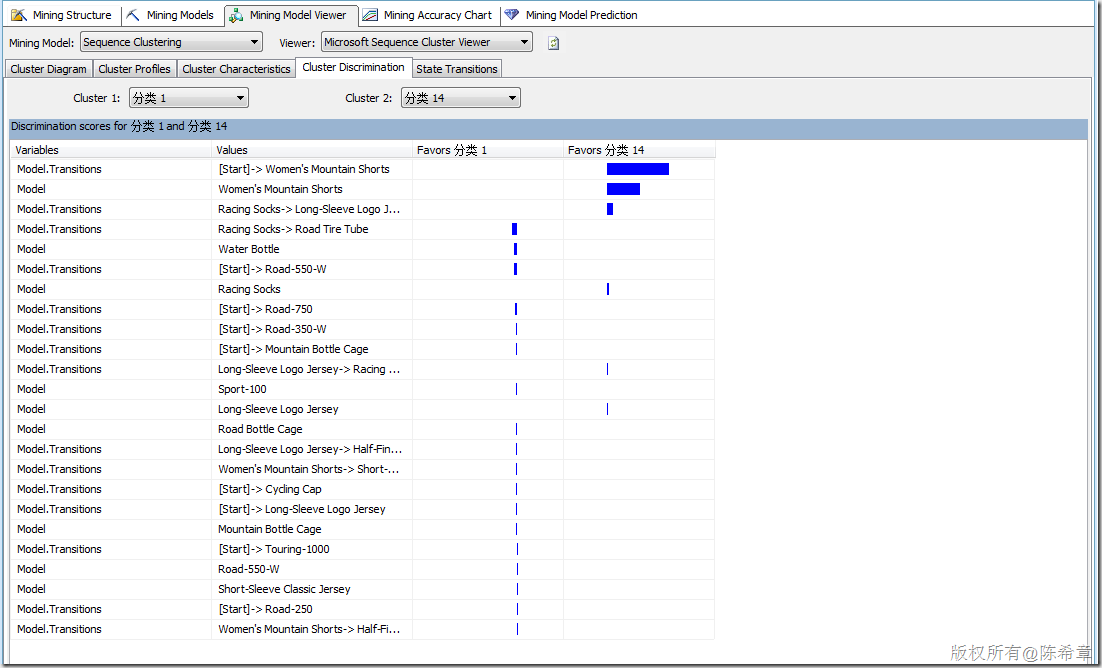
【備注】這里一定要注意,除了標(biāo)準(zhǔn)的屬性之外,順序聚類會(huì)多出來所謂的“Transitions”,這里也就是體現(xiàn)了順序的概念。并且順序聚類算法與標(biāo)準(zhǔn)的聚類算法相比,更多出來另外一個(gè)專門的圖形,請(qǐng)看下圖
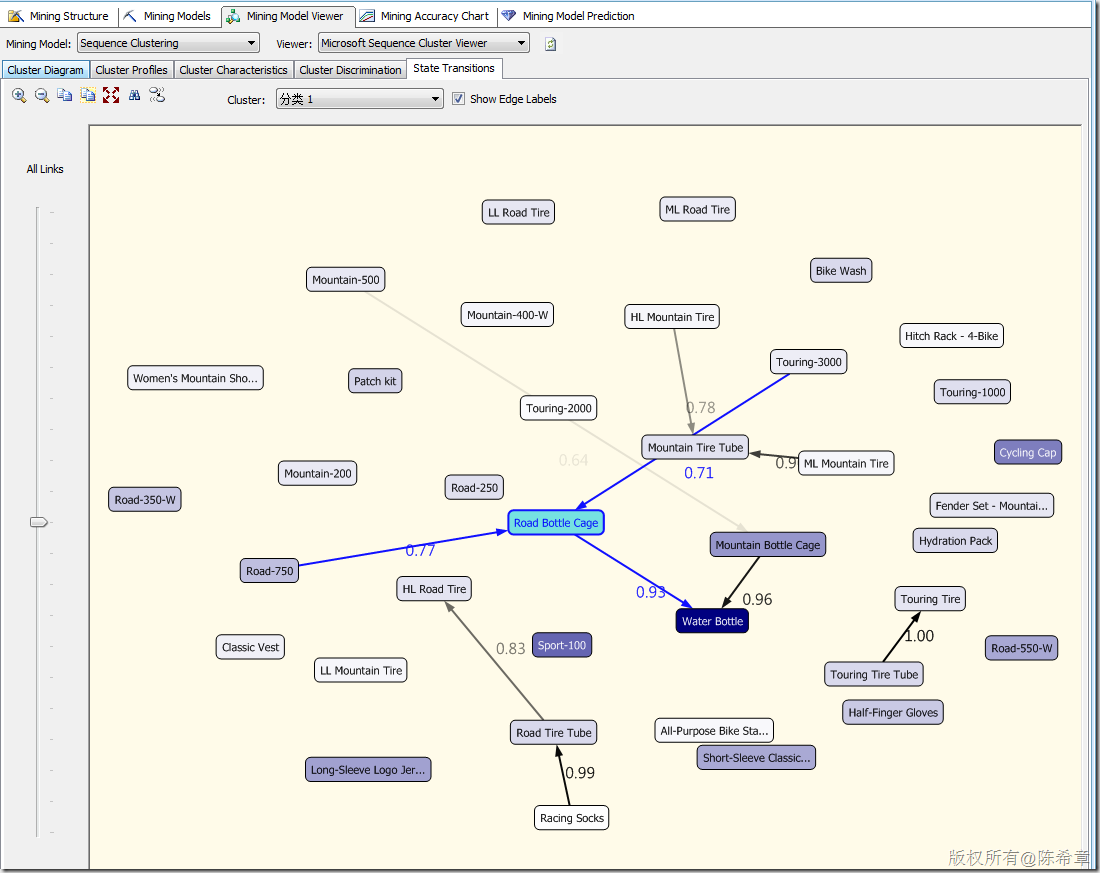
關(guān)鍵就在于,這個(gè)圖你該如何理解呢?我總結(jié)這么幾點(diǎn)
- 順序聚類算法,首先它是一個(gè)聚類算法,他會(huì)對(duì)輸入的實(shí)體進(jìn)行分組。
- 之所以稱為順序聚類,是說它可以在分完組之后,針對(duì)這些組的實(shí)體的一些行為(主要是與時(shí)間有關(guān)的行為)進(jìn)行分析,展示。
典型的情況有:分析不同客戶群體將物品放入購物籃的順序,分析不同用戶群體訪問公司網(wǎng)頁的點(diǎn)擊順序流。
上面這個(gè)圖的舉例解釋就是:“分類1”的這個(gè)組,通常是買了“Road-750”這個(gè)產(chǎn)品后,有77%的可能性買”Road Bottle Cage”,然后又有93%的可能性買“Water Bottle”
原文鏈接:http://www.cnblogs.com/chenxizhang/archive/2011/07/24/2115331.html
【編輯推薦】





















