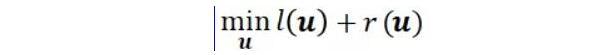大規模機器學習框架的四重境界
1. 背景
自從google發表著名的GFS、MapReduce、BigTable三篇paper以后,互聯網正式迎來了大數據時代。大數據的顯著特點是大,哪里都大的大。本篇主要針對volume大的數據時,使用機器學習來進行數據處理過程中遇到的架構方面的問題做一個系統的梳理。
有了GFS我們有能力積累海量的數據樣本,比如在線廣告的曝光和點擊數據,天然具有正負樣本的特性,累積一兩個月往往就能輕松獲得百億、千億級的訓練樣本。這樣海量的樣本如何存儲?用什么樣的模型可以學習海量樣本中有用的pattern?這些問題不止是工程問題,也值得每個做算法的同學去深入思考。
1.1簡單模型or復雜模型
在深度學習概念提出之前,算法工程師手頭能用的工具其實并不多,就LR、SVM、感知機等寥寥可數、相對固定的若干個模型和算法;那時候要解決一個實際的問題,算法工程師更多的工作主要是在特征工程方面。而特征工程本身并沒有很系統化的指導理論(至少目前沒有看到系統介紹特征工程的書籍),所以很多時候特征的構造技法顯得光怪陸離,是否有用也取決于問題本身、數據樣本、模型以及運氣。
在特征工程作為算法工程師主要工作內容的時候,構造新特征的嘗試往往很大部分都不能在實際工作中work。據我了解,國內幾家大公司在特征構造方面的成功率在后期一般不會超過20%。也就是80%的新構造特征往往并沒什么正向提升效果。如果給這種方式起一個名字的話,大概是簡單模型+復雜特征;簡單模型說的是算法比如LR、SVM本身并不服務,參數和表達能力基本呈現一種線性關系,易于理解。復雜特征則是指特征工程方面不斷嘗試使用各種奇技淫巧構造的可能有用、可能沒用的特征,這部分特征的構造方式可能會有各種trick,比如窗口滑動、離散化、歸一化、開方、平方、笛卡爾積、多重笛卡爾積等等;順便提一句,因為特征工程本身并沒有特別系統的理論和總結,所以初入行的同學想要構造特征就需要多讀paper,特別是和自己業務場景一樣或類似的場景的paper,從里面學習作者分析、理解數據的方法以及對應的構造特征的技法;久而久之,有望形成自己的知識體系。
深度學習概念提出以后,人們發現通過深度神經網絡可以進行一定程度的表示學習(representation learning),例如在圖像領域,通過CNN提取圖像feature并在此基礎上進行分類的方法,一舉打破了之前算法的天花板,而且是以極大的差距打破。這給所有算法工程師帶來了新的思路,既然深度學習本身有提取特征的能力,干嘛還要苦哈哈的自己去做人工特征設計呢?
深度學習雖然一定程度上緩解了特征工程的壓力,但這里要強調兩點:1.緩解并不等于徹底解決,除了圖像這種特定領域,在個性化推薦等領域,深度學習目前還沒有完全取得絕對的優勢;究其原因,可能還是數據自身內在結構的問題,使得在其他領域目前還沒有發現類似圖像+CNN這樣的***CP。2.深度學習在緩解特征工程的同時,也帶來了模型復雜、不可解釋的問題。算法工程師在網絡結構設計方面一樣要花很多心思來提升效果。概括起來,深度學習代表的簡單特征+復雜模型是解決實際問題的另一種方式。
兩種模式孰優孰劣還難有定論,以點擊率預測為例,在計算廣告領域往往以海量特征+LR為主流,根據VC維理論,LR的表達能力和特征個數成正比,因此海量的feature也完全可以使LR擁有足夠的描述能力。而在個性化推薦領域,深度學習剛剛萌芽,目前google play采用了WDL的結構[1],youtube采用了雙重DNN的結構[2]。
不管是那種模式,當模型足夠龐大的時候,都會出現模型參數一臺機器無法存放的情況。比如百億級feature的LR對應的權重w有好幾十個G,這在很多單機上存儲都是困難的,大規模神經網絡則更復雜,不僅難以單機存儲,而且參數和參數之間還有邏輯上的強依賴;要對超大規模的模型進行訓練勢必要借用分布式系統的技法,本文主要是系統總結這方面的一些思路。
1.2數據并行vs模型并行
數據并行和模型并行是理解大規模機器學習框架的基礎概念,其緣起未深究,***次看到是在姐夫(Jeff Dean)的blog里,當時匆匆一瞥,以為自己懂了。多年以后,再次開始調研這個問題的時候才想起長者的教訓,年輕人啊,還是圖樣,圖森破。如果你和我一樣曾經忽略過這個概念,今天不放復習一下。
這兩個概念在[3]中沐帥曾經給出了一個非常直觀而經典的解釋,可惜不知道什么原因,當我想引用時卻發現已經被刪除了。我在這里簡單介紹下這個比喻:如果要修兩棟樓,有一個工程隊,怎么操作?***個方案是將人分成兩組,分別蓋樓,改好了就裝修;第二種做法是一組人蓋樓,等***棟樓蓋好,另一組裝修***棟,然后***組繼續蓋第二棟樓,改完以后等裝修隊裝修第二棟樓。咋一看,第二種方法似乎并行度并不高,但***種方案需要每個工程人員都擁有“蓋樓”和“裝修”兩種能力,而第二個方案只需要每個人擁有其中一種能力即可。***個方案和數據并行類似,第二個方案則道出了模型并行的精髓。
數據并行理解起來比較簡單,當樣本比較多的時候,為了使用所有樣本來訓練模型,我們不妨把數據分布到不同的機器上,然后每臺機器都來對模型參數進行迭代,如下圖所示
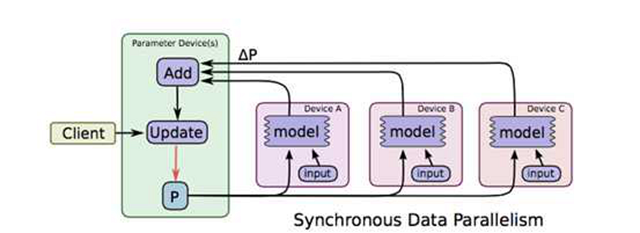
圖片取材于TensorFlow的paper[4],圖中ABC代表三臺不同的機器,上面存儲著不同的樣本,模型P在各臺機器上計算對應的增量,然后在參數存儲的機器上進行匯總和更新,這就是數據并行。先忽略synchronous,這是同步機制相關的概念,在第三節會有專門介紹。
數據并行概念簡單,而且不依賴于具體的模型,因此數據并行機制可以作為框架的一種基礎功能,對所有算法都生效。與之不同的是,模型并行因為參數間存在依賴關系(其實數據并行參數更新也可能會依賴所有的參數,但區別在于往往是依賴于上一個迭代的全量參數。而模型并行往往是同一個迭代內的參數之間有強依賴關系,比如DNN網絡的不同層之間的參數依照BP算法形成的先后依賴),無法類比數據并行這樣直接將模型參數分片而破壞其依賴關系,所以模型并行不僅要對模型分片,同時需要調度器來控制參數間的依賴關系。而每個模型的依賴關系往往并不同,所以模型并行的調度器因模型而異,較難做到完全通用。關于這個問題,CMU的Erix Xing在[5]中有所介紹,感興趣的可以參考。
模型并行的問題定義可以參考姐夫的[6],這篇paper也是tensorflow的前身相關的總結,其中圖
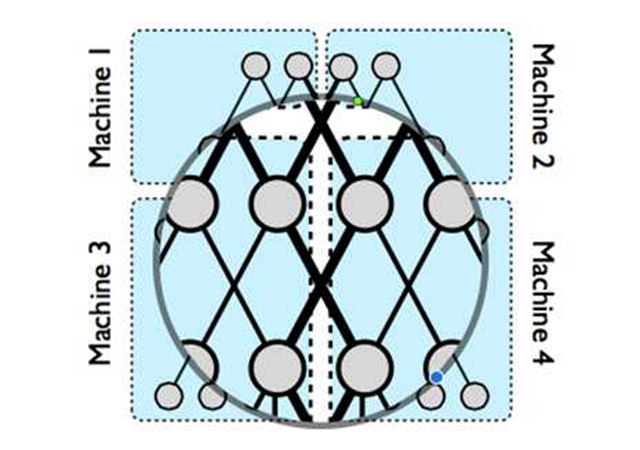
解釋了模型并行的物理圖景,當一個超大神經網絡無法存儲在一臺機器上時,我們可以切割網絡存到不同的機器上,但是為了保持不同參數分片之間的依賴,如圖中粗黑線的部分,則需要在不同的機器之間進行concurrent控制;同一個機器內部的參數依賴,即途中細黑線部分在機器內即可完成控制。
黑線部分如何有效控制呢?如下圖所示
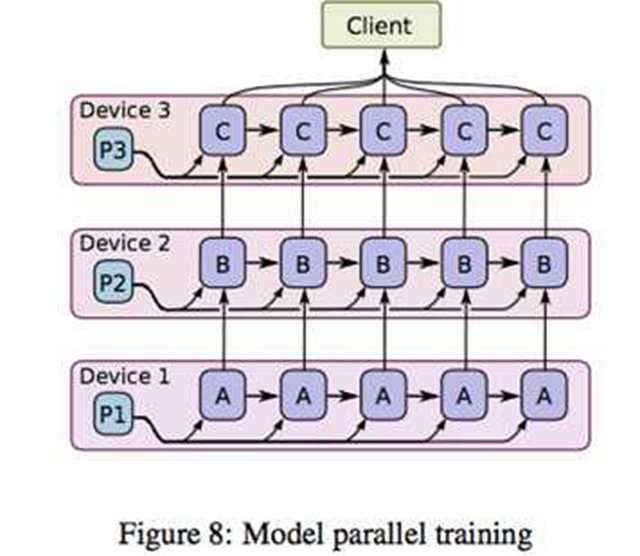
在將模型切分到不同機器以后,我們將參數和樣本一起在不同機器間流轉,途中ABC代表模型的不同部分的參數;假設C依賴B,B依賴A,機器1上得到A的一個迭代后,將A和必要的樣本信息一起傳到機器2,機器2根據A和樣本對P2更新得到,以此類推;當機器2計算B的時候,機器1可以展開A的第二個迭代的計算。了解CPU流水線操作的同學一定感到熟悉,是的,模型并行是通過數據流水線來實現并行的。想想那個蓋樓的第二種方案,就能理解模型并行的精髓了。
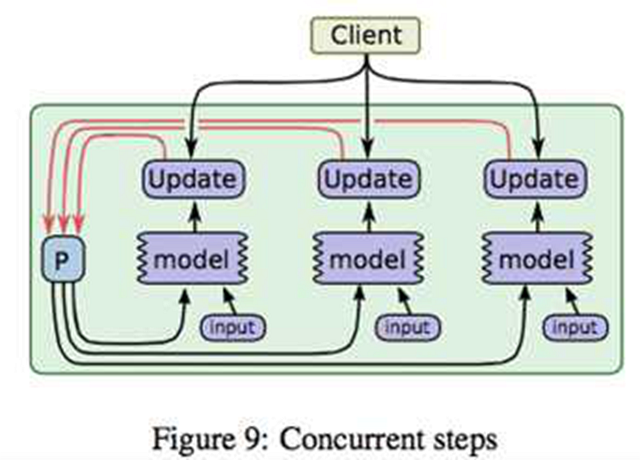
上圖則是對控制模型參數依賴的調度器的一個示意圖,實際框架中一般都會用DAG(有向無環圖)調度技術來實現類似功能,未深入研究,以后有機會再補充說明。
理解了數據并行和模型并行對后面參數服務器的理解至關重要,但現在讓我先蕩開一筆,簡單介紹下并行計算框架的一些背景信息。
2. 并行算法演進
2.1 MapReduce路線
從函數式編程中的受到啟發,google發布了MapReduce[7]的分布式計算方式;通過將任務切分成多個疊加的Map+Reduce任務,來完成復雜的計算任務,示意圖如下
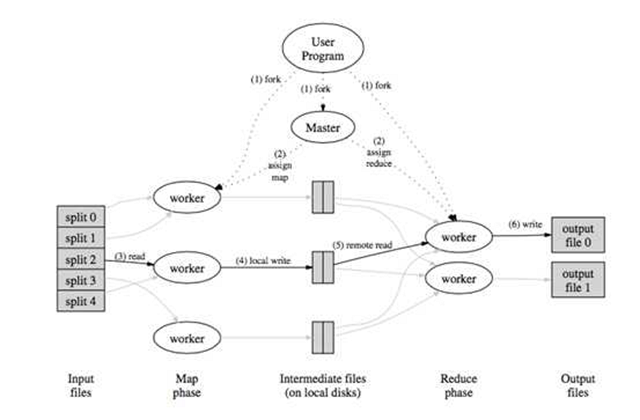
MapReduce的主要問題有兩個,一是原語的語義過于低級,直接使用其來寫復雜算法,開發量比較大;另一個問題是依賴于磁盤進行數據傳遞,性能跟不上業務需求。
為了解決MapReduce的兩個問題,Matei在[8]中提出了一種新的數據結構RDD,并構建了Spark框架。Spark框架在MR語義之上封裝了DAG調度器,極大降低了算法使用的門檻。較長時間內spark幾乎可以說是大規模機器學習的代表,直至后來沐帥的參數服務器進一步開拓了大規模機器學習的領域以后,spark才暴露出一點點不足。如下圖
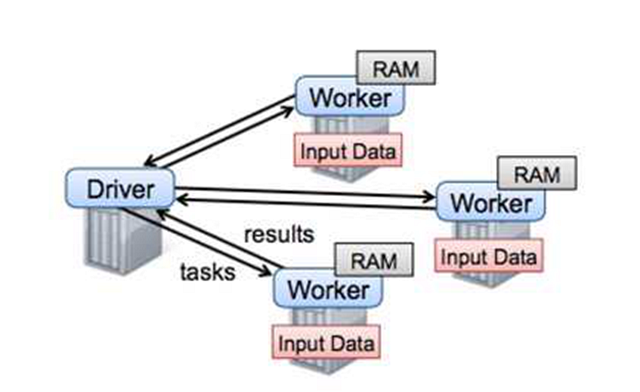
從圖中可以看出,spark框架以Driver為核心,任務調度和參數匯總都在driver,而driver是單機結構,所以spark的瓶頸非常明顯,就在Driver這里。當模型規模大到一臺機器存不下的時候,Spark就無法正常運行了。所以從今天的眼光來看,Spark只能稱為一個中等規模的機器學習框架。劇透一句,公司開源的Angel通過修改Driver的底層協議將Spark擴展到了一個高一層的境界。后面還會再詳細介紹這部分。
MapReduce不僅是一個框架,還是一種思想,google開創性的工作為我們找到了大數據分析的一個可行方向,時至今日,仍不過時。只是逐漸從業務層下沉到底層語義應該處于的框架下層。
2.2 MPI技術
沐帥在[9]中對MPI的前景做了簡要介紹;和Spark不同,MPI是類似socket的一種系統通信API,只是支持了消息廣播等功能。因為對MPI研究不深入,這里簡單介紹下優點和缺點吧;優點是系統級支持,性能杠杠的;缺點也比較多,一是和MR一樣因為原語過于低級,用MPI寫算法,往往代碼量比較大。另一方面是基于MPI的集群,如果某個任務失敗,往往需要重啟整個集群,而MPI集群的任務成功率并不高。阿里在[10]中給出了下圖:
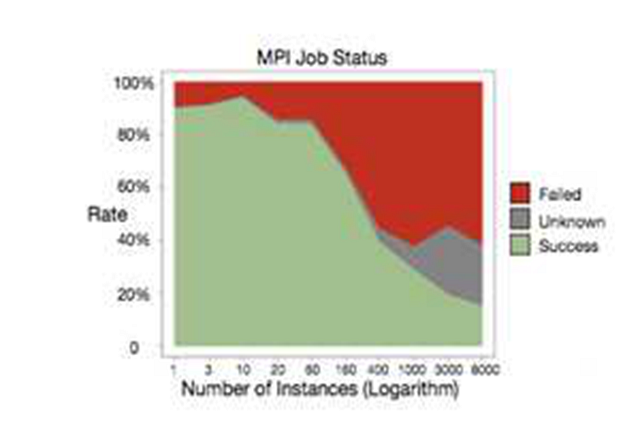
從圖中可以看出,MPI作業失敗的幾率接近五成。MPI也并不是完全沒有可取之處,正如沐帥所說,在超算集群上還是有場景的。對于工業屆依賴于云計算、依賴于commodity計算機來說,則顯得性價比不夠高。當然如果在參數服務器的框架下,對單組worker再使用MPI未嘗不是個好的嘗試,[10]的鯤鵬系統正式這么設計的。
3. 參數服務器演進
3.1 歷史演進
沐帥在[12]中將參數服務器的歷史劃分為三個階段,***代參數服務器萌芽
于沐帥的導師Smola的[11],如下圖所示:
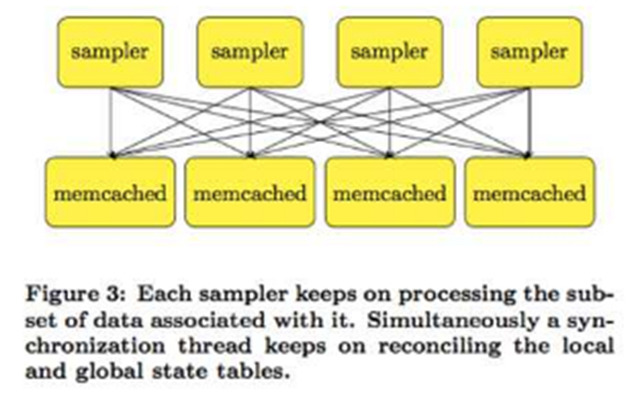
這個工作中僅僅引入memcached來存放key-value數據,不同的處理進程并行對其進行處理。[13]中也有類似的想法,第二代參數服務器叫application-specific參數服務器,主要針對特定應用而開發,其中最典型的代表應該是tensorflow的前身[6]。
第三代參數服務器,也即是通用參數服務器框架是由百度少帥李沐正式提出的,和前兩代不同,第三代參數服務器從設計上就是作為一個通用大規模機器學習框架來定位的。要擺脫具體應用、算法的束縛,做一個通用的大規模機器學習框架,首先就要定義好框架的功能;而所謂框架,往往就是把大量重復的、瑣碎的、做了一次就不想再來第二次的臟活、累活進行良好而優雅的封裝,讓使用框架的人可以只關注與自己的核心邏輯。第三代參數服務器要對那些功能進行封裝呢?沐帥總結了這幾點,我照搬如下:
- 高效的網絡通信:因為不管是模型還是樣本都十分巨大,因此對網絡通信的高效支持以及高配的網絡設備都是大規模機器學習系統不可缺少的;
- 靈活的一致性模型:不同的一致性模型其實是在模型收斂速度和集群計算量之間做tradeoff;要理解這個概念需要對模型性能的評價做些分析,暫且留到下節再介紹。
- 彈性可擴展:顯而易見
- 容災容錯:大規模集群協作進行計算任務的時候,出現Straggler或者機器故障是非常常見的事,因此系統設計本身就要考慮到應對;沒有故障的時候,也可能因為對任務時效性要求的變化而隨時更改集群的機器配置。這也需要框架能在不影響任務的情況下能做到機器的熱插拔。
- 易用性:主要針對使用框架進行算法調優的工程師而言,顯然,一個難用的框架是沒有生命力的。
在正式介紹第三代參數服務器的主要技術之前,先從另一個角度來看下大規模機器學習框架的演進
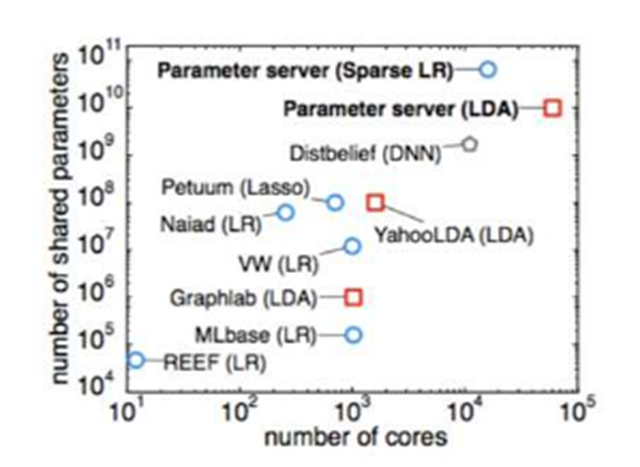
這張圖可以看出,在參數服務器出來之前,人們已經做了多方面的并行嘗試,不過往往只是針對某個特定算法或特定領域,比如YahooLDA是針對LDA算法的。當模型參數突破十億以后,則可以看出參數服務器一統江湖,再無敵手。
首先我們看看第三代參數服務器的基本架構
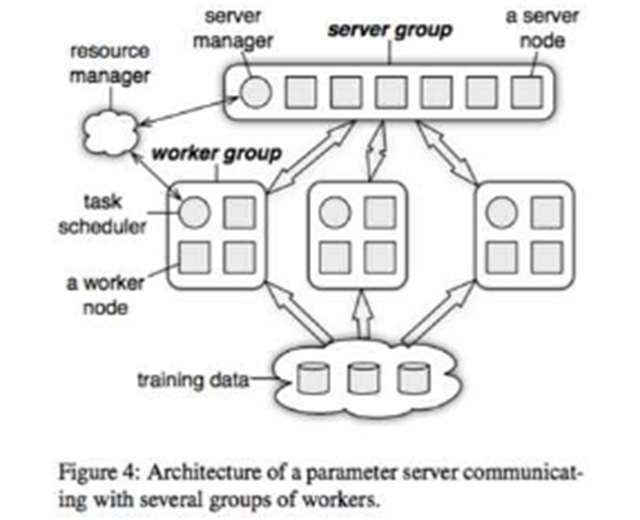
上圖的resourcemanager可以先放一放,因為實際系統中這部分往往是復用現有的資源管理系統,比如yarn或者mesos;底下的training data毋庸置疑的需要類似GFS的分布式文件系統的支持;剩下的部分就是參數服務器的核心組件了。
圖中畫了一個server group和三個worker group;實際應用中往往也是類似,server group用一個,而worker group按需配置;server manager是server group中的管理節點,一般不會有什么邏輯,只有當有server node加入或退出的時候,為了維持一致性哈希而做一些調整。
Worker group中的task schedule則是一個簡單的任務協調器,一個具體任務運行的時候,task schedule負責通知每個worker加載自己對應的數據,然后去server node上拉取一個要更新的參數分片,用本地數據樣本計算參數分片對應的變化量,然后同步給server node;server node在收到本機負責的參數分片對應的所有worker的更新后,對參數分片做一次update。
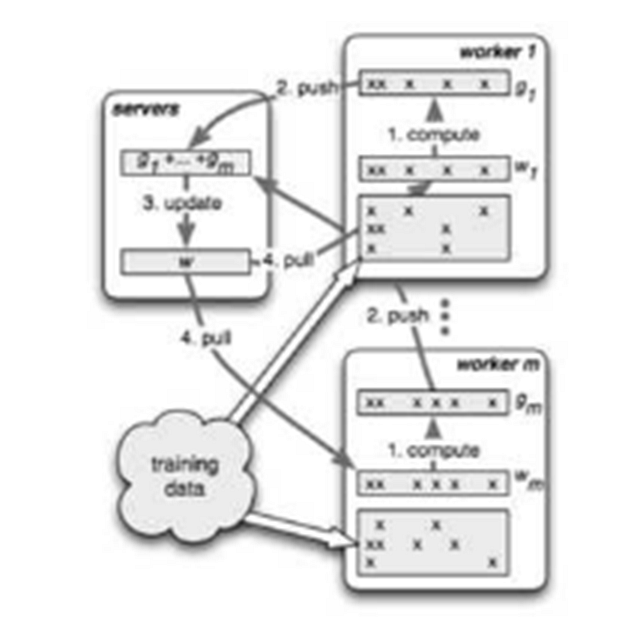
如圖所示,不同的worker同時并行運算的時候,可能因為網絡、機器配置等外界原因,導致不同的worker的進度是不一樣的,如何控制worker的同步機制是一個比較重要的課題。詳見下節分解。
3.2同步協議
本節假設讀者已經對隨機梯度優化算法比較熟悉,如果不熟悉的同學請參考吳恩達經典課程機器學習中對SGD的介紹,或者我之前多次推薦過的書籍《***化導論》。
我們先看一個單機算法的運行過程,假設一個模型的參數切分成三個分片k1,k2,k3;比如你可以假設是一個邏輯回歸算法的權重向量被分成三段。我們將訓練樣本集合也切分成三個分片s1,s2,s3;在單機運行的情況下,我們假設運行的序列是(k1,s1)、(k2,s1)、(k3、s1)、(k1、s2)、(k2、s2)、(k3、s2)。。。看明白了嗎?就是假設先用s1中的樣本一次對參數分片k1、k2、k3進行訓練,然后換s2;這就是典型的單機運行的情況,而我們知道這樣的運行序列***算法會收斂。
現在我們開始并行化,假設k1、k2、k3分布在三個server node上,s1、s2、s3分布在三個worker上,這時候如果我們還要保持之前的計算順序,則會變成怎樣?work1計算的時候,work2和worker3只能等待,同樣worker2計算的時候,worker1和work3都得等待,以此類推;可以看出這樣的并行化并沒有提升性能;但是也算簡單解決了超大規模模型的存儲問題。
為了解決性能的問題,業界開始探索這里的一致性模型,***出來的版本是前面提到的[11]中的ASP模式,就是完全不顧worker之間的順序,每個worker按照自己的節奏走,跑完一個迭代就update,然后繼續,這應該是大規模機器學習中的freestyle了,如圖所示
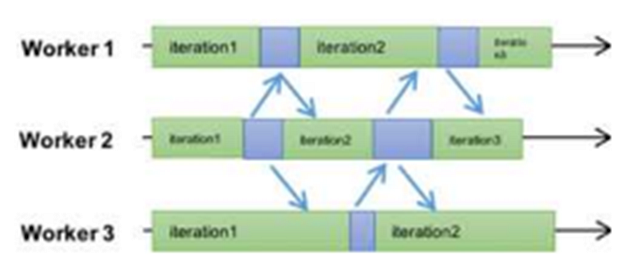
ASP的優勢是***限度利用了集群的計算能力,所有的worker所在的機器都不用等待,但缺點也顯而易見,除了少數幾個模型,比如LDA,ASP協議可能導致模型無法收斂。也就是SGD徹底跑飛了,梯度不知道飛到哪里去了。
在ASP之后提出了另一種相對極端的同步協議BSP,spark用的就是這種方式,如圖所示
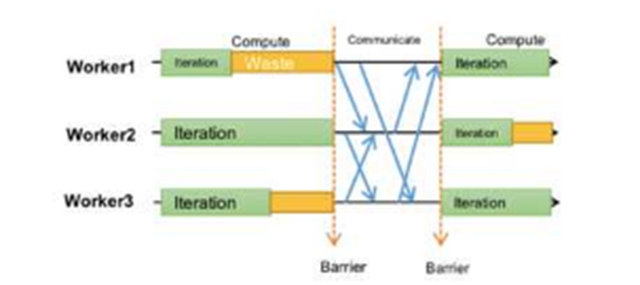
每個worker都必須在同一個迭代運行,只有一個迭代任務所有的worker都完成了,才會進行一次worker和server之間的同步和分片更新。這個算法和嚴格一直的算法非常類似,區別僅僅在于單機版本的batch size在BSP的時候變成了有所有worker的單個batch size求和得到的總的butch size替換。毫無疑問,BSP的模式和單機串行因為僅僅是batch size的區別,所以在模型收斂性上是完全一樣的。同時,因為每個worker在一個周期內是可以并行計算的,所以有了一定的并行能力。
以此協議為基礎的spark在很長時間內成為機器學習領域實際的霸主,不是沒有理由的。此種協議的缺陷之處在于,整個worker group的性能由其中最慢的worker決定;這個worker一般稱為straggler。讀過GFS文章的同學應該都知道straggler的存在是非常普遍的現象。
能否將ASP和BSP做一下折中呢?答案當然是可以的,這就是目前我認為***的同步協議SSP;SSP的思路其實很簡單,既然ASP是允許不同worker之間的迭代次數間隔任意大,而BSP則只允許為0,那我是否可以取一個常數s?如圖所示

不同的worker之間允許有迭代的間隔,但這個間隔數不允許超出一個指定的數值s,圖中s=3.
SSP協議的詳細介紹參見[14],CMU的大拿Eric Xing在其中詳細介紹了SSP的定義,以及其收斂性的保證。理論推導證明常數s不等于無窮大的情況下,算法一定可以在若干次迭代以后進入收斂狀態。其實在Eric提出理論證明之前,工業界已經這么嘗試過了:)
順便提一句,考察分布式算法的性能,一般會分為statistical performance和hard performance來看。前者指不同的同步協議導致算法收斂需要的迭代次數的多少,后者是單次迭代所對應的耗時。兩者的關系和precision\recall關系類似,就不贅述了。有了SSP,BSP就可以通過指定s=0而得到。而ASP同樣可以通過制定s=∞來達到。
3.3核心技術
除了參數服務器的架構、同步協議之外,本節再對其他技術做一個簡要的介紹,詳細的了解請直接閱讀沐帥的博士論文和相關發表的論文。
熱備、冷備技術:為了防止server node掛掉,導致任務中斷,可以采用兩個技術,一個是對參數分片進行熱備,每個分片存儲在三個不同的server node中,以master-slave的形式存活。如果master掛掉,可以快速從slave獲取并重啟相關task。
除了熱備,還可以定時寫入checkpoint文件到分布式文件系統來對參數分片及其狀態進行備份。進一步保證其安全性。
Server node管理:可以使用一致性哈希技術來解決server node的加入和退出問題,如圖所示

當有server node加入或退出的時候,server manager負責對參數進行重新分片或者合并。注意在對參數進行分片管理的情況下,一個分片只需要一把鎖,這大大提升了系統的性能,也是參數服務器可以實用的一個關鍵點。
4. 大規模機器學習的四重境界
到這里可以回到我們的標題了,大規模機器學習的四重境界到底是什么呢?
這四重境界的劃分是作者個人閱讀總結的一種想法,并不是業界標準,僅供大家參考。
境界1:參數可單機存儲和更新
此種境界較為簡單,但仍可以使用參數服務器,通過數據并行來加速模型的訓練。
境界2:參數不可單機存儲,可以單機更新
此種情況對應的是一些簡單模型,比如sparse logistic regression;當feature的數量突破百億的時候,LR的權重參數不太可能在一臺機器上完全存下,此時必須使用參數服務器架構對模型參數進行分片。但是注意一點,SGD的更新公式
w’=w-α,其中可以分開到單個維度進行計算,但是單個維度的wi=f(w)xi
這里的f(w)表示是全部參數w的一個函數,具體推倒比較簡單,這里篇幅所限就不贅述了。只是想說明worker在計算梯度的時候可能需要使用到上一輪迭代的所有參數。而我們之所以對參數進行分片就是因為我們無法將所有參數存放到一臺機器,現在單個worker有需要使用所有的參數才能計算某個參數分片的梯度,這不是矛盾嗎?可能嗎?
答案是可能的,因為單個樣本的feature具有很高的稀疏性(sparseness)。例如一個百億feature的模型,單個訓練樣本往往只在其中很小一部分feature上有取值,其他都為0(假設feature取值都已經離散化了)。因此計算f(w)的時候可以只拉取不為0的feature對應的那部分w即可。有文章統計一般這個級別的系統,稀疏性往往在0.1%(or 0.01%,記得不是很準,大致這樣)以下。這樣的稀疏性,可以讓單機沒有任何阻礙的計算f(w)。
目前公司開源的angel和AILab正在做的系統都處于這個境界。而原生spark還沒有達到這個境界,只能在中小規模的圈子里廝混。Angel改造的基于Angel的Spark則達到了這個境界。
境界3:參數不可單機存儲,不可單機更新,但無需模型并行
境界3順延境界2二來,當百億級feature且feature比較稠密的時候,就需要計算框架進入到這層境界了,此時單個worker的能力有限,無法完整加載一個樣本,也無法完整計算f(w)。怎么辦呢?其實很簡單,學過線性代數的都知道,矩陣可以分塊。向量是最簡單的矩陣,自然可以切成一段一段的來計算。只是調度器需要支持算符分段而已了。
境界4:參數不可單機存儲,不可單機更新,需要模型并行
進入到這個層次的計算框架,可以算是世界***了。可以處理超大規模的神經網絡。這也是最典型的應用場景。此時不僅模型的參數不能單機存儲,而且同一個迭代內,模型參數之間還有強的依賴關系,可以參見姐夫對distbelief的介紹里的模型切分。
此時首先需要增加一個coordinator組件來進行模型并行的concurrent控制。同時參數服務器框架需要支持namespace切分,coordinator將依賴關系通過namespace來進行表示。
一般參數間的依賴關系因模型而已,所以較難抽象出通用的coordinator來,而必須以某種形式通過腳本parser來生產整個計算任務的DAG圖,然后通過DAG調度器來完成。對這個問題的介紹可以參考Erix Xing的分享[5]。
Tensorflow
目前業界比較知名的深度學習框架有Caffee、MXNet、Torch、Keras、Theano等,但目前最炙手可熱的應該是google發布的Tensorflow。這里單獨拿出來稍微分解下。
前面不少圖片引自此文,從TF的論文來看,TF框架本身是支持模型并行和數據并行的,內置了一個參數服務器模塊,但從開源版本所曝光的API來看,TF無法用來10B級別feature的稀疏LR模型。原因是已經曝光的API只支持在神經網絡的不同層和層間進行參數切分,而超大規模LR可以看做一個神經單元,TF不支持單個神經單元參數切分到多個參數服務器node上。
當然,以google的實力,絕對是可以做到第四重境界的,之所以沒有曝光,可能是基于其他商業目的的考量,比如使用他們的云計算服務。
綜上,個人認為如果能做到第四重境界,目前可以說的上是世界***的大規模機器學習框架。僅從沐帥的ppt里看他曾經達到過,google內部應該也是沒有問題的。第三重境界應該是國內***,第二充應該是國內前列吧。
5. 其他
5.1 資源管理
本文沒有涉及到的部分是資源管理,大規模機器學習框架部署的集群往往
資源消耗也比較大,需要專門的資源管理工具來維護。這方面yarn和mesos都是佼佼者,細節這里也就不介紹了。
5.2 設備
除了資源管理工具,本身部署大規模機器學習集群本身對硬件也還是有些要
求的,雖然理論上來說,所有commodity機器都可以用來搭建這類集群,但是考慮到性能,我們建議盡量用高內存的機器+萬兆及以上的網卡。沒有超快速的網卡,玩參數傳遞和樣本加載估計會比較苦逼。
6. 結語
從后臺轉算法以來,長期沉浸于算法推理的論文無法自拔,對自己之前的后
臺工程能力漸漸輕視起來,覺得工程對算法的幫助不大。直到最近一個契機,需要做一個這方面的調研,才豁然發現,之前的工程經驗對我理解大規模機器學習框架非常有用,果然如李宗盛所說,人生每一步路,都不是白走的。
在一個月左右的調研中,腦子每天都充斥這各種疑問和困惑,曾經半夜4點醒來,思考同步機制而再也睡不著,干脆起來躲衛生間看書,而那天我一點多才睡。當腦子里有放不下的問題的時候,整個人會處于一種非常亢奮的狀態,除非徹底想清楚這個問題,否則失眠是必然的,上一次這種狀態已經是很多年前了。好在***我總算理清了這方面的所有關鍵細節。以此,記之。Carbonzhang于2017年8月26日凌晨!
致謝
感謝wills、janwang、joey、roberty、suzi等同學一起討論,特別感謝burness在TF方面的深厚造詣和調研。因為本人水平所限,錯漏難免,另外還有相當多的細節因為篇幅限制并未一一展開,僅僅是從較高抽象層面上簡述了下大規模機器學習框架的關鍵思路,其他如分片向量鎖、通信協議、時鐘邏輯、DAG調度器、資源調度模塊等均為展開來講,希望以后有機會能補上。