如何對機(jī)器學(xué)習(xí)代碼進(jìn)行單元測試?

目前,關(guān)于神經(jīng)網(wǎng)絡(luò)代碼,并沒有一個(gè)特別完善的單元測試的在線教程。甚至像 OpenAI 這樣的站點(diǎn),也只能靠 盯著每一行看來思考哪里錯(cuò)了來尋找 bug。很明顯,大多數(shù)人沒有那樣的時(shí)間,并且也討厭這么做。所以希望這篇教程能幫助你開始穩(wěn)健的測試系統(tǒng)。
首先來看一個(gè)簡單的例子,嘗試找出以下代碼的 bug。

看出來了嗎?網(wǎng)絡(luò)并沒有實(shí)際融合(stacking)。寫這段代碼時(shí),只是復(fù)制、粘貼了 slim.conv2d(…) 這行,修改了核(kernel)大小,忘記修改實(shí)際的輸入。
這個(gè)實(shí)際上是作者一周前剛剛碰到的狀況,很尷尬,但是也是重要的一個(gè)教訓(xùn)!這些 bug 很難發(fā)現(xiàn),有以下原因。
- 這些代碼不會崩潰,不會拋出異常,甚至不會變慢。
- 這個(gè)網(wǎng)絡(luò)仍然能訓(xùn)練,并且損失(loss)也會下降。
- 運(yùn)行多個(gè)小時(shí)后,值回歸到很差的結(jié)果,讓人抓耳撓腮不知如何修復(fù)。
只有最終的驗(yàn)證錯(cuò)誤這一條線索情況下,必須回顧整個(gè)網(wǎng)絡(luò)架構(gòu)才能找到問題所在。很明顯,你需要需要一個(gè)更好的處理方式。
比起在運(yùn)行了很多天的訓(xùn)練后才發(fā)現(xiàn),我們?nèi)绾翁崆邦A(yù)防呢?這里可以明顯注意到,層(layers)的值并沒有到達(dá)函數(shù)外的任何張量(tensors)。在有損失和優(yōu)化器情況下,如果這些張量從未被優(yōu)化,它們會保持默認(rèn)值。
因此,只需要比較值在訓(xùn)練步驟前后有沒有發(fā)生變化,我們就可以發(fā)現(xiàn)這種情況。

哇。只需要短短 15 行不到的代碼,就能保證至少所有創(chuàng)建的變量都被訓(xùn)練到了。
這個(gè)測試,簡單但是卻很有用。現(xiàn)在問題修復(fù)了,讓我們來嘗試添加批量標(biāo)準(zhǔn)化。看你能否用眼睛看出 bug 來。
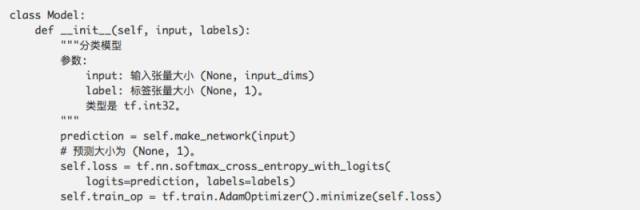
發(fā)現(xiàn)了嗎?這個(gè) bug 很巧妙。在 tensorflow 中,batch_norm 的 is_training 默認(rèn)值是 False,所以在訓(xùn)練過程中添加這行代碼,會導(dǎo)致輸入無法標(biāo)準(zhǔn)化!幸虧,我們剛剛添加的那個(gè)單元測試會立即捕捉到這個(gè)問題!(3 天前,它剛剛幫助我捕捉到這個(gè)問題。)
讓我們看另外一個(gè)例子。這是我從 reddit 帖子中看來的。我們不會太深入原帖,簡單的說,發(fā)帖的人想要創(chuàng)建一個(gè)分類器,輸出的范圍在 0 到 1 之間。看看你能否看出哪里不對。
發(fā)現(xiàn)問題了嗎?這個(gè)問題很難發(fā)現(xiàn),結(jié)果非常難以理解。簡單的說,因?yàn)轭A(yù)測只有單個(gè)輸出值,應(yīng)用了 softmax 交叉熵函數(shù)后,損失就會永遠(yuǎn)是 0 了。
最簡單的發(fā)現(xiàn)這個(gè)問題的測試方式,就是保證損失永遠(yuǎn)不等于 0。

我們***個(gè)實(shí)現(xiàn)的測試,也能發(fā)現(xiàn)這種錯(cuò)誤,但是要反向檢查:保證只訓(xùn)練需要訓(xùn)練的變量。就生成式對抗網(wǎng)絡(luò)(GAN)為例,一個(gè)常見的 bug 就是在優(yōu)化過程中不小心忘記設(shè)置需要訓(xùn)練哪個(gè)變量。這樣的代碼隨處可見。

這段代碼***的問題是,優(yōu)化器默認(rèn)會優(yōu)化所有的變量。在像生成式對抗網(wǎng)絡(luò)這樣高級的結(jié)構(gòu)中,這意味著遙遙無期的訓(xùn)練時(shí)間。然而只需要一個(gè)簡單測試,就可以檢查到這種錯(cuò)誤:

也可以對判定模型(discriminator)寫一個(gè)同類型的測試。同樣的測試,也可以應(yīng)用來加強(qiáng)大量其他的學(xué)習(xí)算法。很多演員評判家(actor-critic)模型,有不同的網(wǎng)絡(luò)需要用不同的損失來優(yōu)化。
這里列出一些作者推薦的測試模式。
- 確保輸入的確定性。如果發(fā)現(xiàn)一個(gè)詭異的失敗測試,但是卻再也無法重現(xiàn),將會是很糟糕的事情。在特別需要隨機(jī)輸入的場景下,確保用了同一個(gè)隨機(jī)數(shù)種子。這樣出現(xiàn)了失敗后,可以再次以同樣的輸入重現(xiàn)它。
- 確保測試很精簡。不要用同一個(gè)單元測試檢查回歸訓(xùn)練和檢查一個(gè)驗(yàn)證集合。這樣做只是浪費(fèi)時(shí)間。
- 確保每次測試時(shí)都重置了圖。
作為總結(jié),這些黑盒算法仍然有大量方法來測試!花一個(gè)小時(shí)寫一個(gè)簡單的測試,可以節(jié)約成天的重新運(yùn)行時(shí)間,并且大大提升你的研究能力。天才的想法,永遠(yuǎn)不要因?yàn)橐粋€(gè)充滿 bug 的實(shí)現(xiàn)而無法成為現(xiàn)實(shí)。
這篇文章列出的測試遠(yuǎn)遠(yuǎn)沒有完備,但是是一個(gè)很好的起步!如果你發(fā)現(xiàn)有其他的建議或者某種特定類型的測試,請?jiān)?twitter 上給我消息!我很樂意寫這篇文章的續(xù)集。
文章中所有的觀點(diǎn),僅代表作者的個(gè)人經(jīng)驗(yàn),并沒有 Google 的支持、贊助。
查看英文原文
https://medium.com/@keeper6928/how-to-unit-test-machine-learning-code-57cf6fd81765