為 Key-Value 數(shù)據(jù)庫實現(xiàn)MVCC 事務
ACID 是軟件領域使用最廣泛的技術之一,它是關系數(shù)據(jù)庫的基石,是企業(yè)級中間件不可或缺的部分,但通常通過黑盒的方式提供。但是在許多情況下,這種古老的事務方式已經不能夠適應現(xiàn)代大規(guī)模系統(tǒng)和NoSQL數(shù)據(jù)庫的需要了,現(xiàn)代系統(tǒng)要求更高的性能要求,更大的數(shù)據(jù)量,更高的可用性。在這種情況下,傳統(tǒng)的事務模型被定制的事務或者半事務模型所取代,而在這些模型中事務性并不像以往那樣被看重。
在本文中我們會討論一下key-value數(shù)據(jù)庫的無鎖事務操作,這種技術可以廣泛應用于任何一種數(shù)據(jù)庫系統(tǒng)。在GridDynamics中,我們就用這種技術在Oracle Coherence上實現(xiàn)了一個輕量級的非標準的事務機制。在***部分我們會通過幾個重要的用例來了解兩種簡單的方法,在第二部分我們會研究更多更通用的方法,比如說PostgreSQL的MVCC實現(xiàn)。
原子性緩存切換,讀提交隔離
讓我們從一個簡單易于實現(xiàn)的方法開始,這個方法適用于讀遠多于寫的系統(tǒng)。比如說電子商務系統(tǒng)中每天要進行的數(shù)據(jù)更新,一些管理性操作例如無效貨品的修復以及緩存更新。
最簡單的例子是把所有數(shù)據(jù)都加載進緩存里,然后通過一個代理接口來執(zhí)行諸如 get() 和 put() 這樣的操作。這個接口會與兩個緩存打交道,A和B,按照以下邏輯運行(圖 1):
任何時候只能有一個緩存處于可用狀態(tài),代理接口會把所有的請求路由給它(圖1.1)。
更新數(shù)據(jù)的時候把新數(shù)據(jù)加載到目前不可用的緩存中(圖1.2)。
更新進程切換標志哪個緩存可用的標記(圖1.3),代理接口開始把新的讀請求分發(fā)到新標記為可用的緩存。
緩存切換階段的事務可以依據(jù)不用的持久性和隔離性要求來分別處理。如果允許“不可重復讀” ,那么切換很簡單,老數(shù)據(jù)會被立刻清理掉。否則,代理接口會維護一個仍未結束的事務列表,并把屬于這個列表中的每一個請求都路由到原來的緩存中。只有當列表中的所有事物都提交或者放棄之后老數(shù)據(jù)才會被清空。
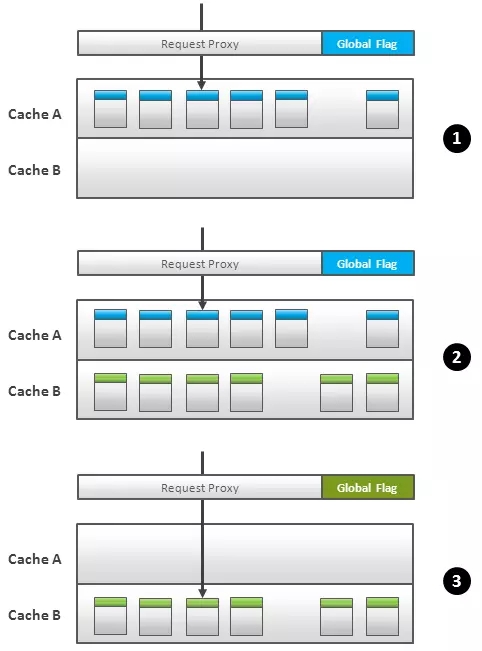
Fig.1 Cache Switch
相同的技術也可用于部分更新。依據(jù)存儲方式的不同也有多種實現(xiàn)方法,我們來看一個有三個緩存簡單例子。這個例子中的框架遇上一個類似,但是代理接口按照以下邏輯運行(圖 2):
用戶請求被路由到主緩存("PRIMARY"緩存)(圖 2.1)
新增數(shù)據(jù)和更新數(shù)據(jù)加載進2號緩存(“NEW”緩存),刪除項的key放入3號緩存("DELETE"緩存)(圖2.2)
提交進程(特指寫事務)切換全局標示,這個標示會告訴代理接口先去"NEW"和"DELETE"緩存去查找所請求的數(shù)據(jù),如果在這兩個區(qū)域中沒有發(fā)現(xiàn)再去"PRIMARY"緩存查找(圖2.3)。換句話說,在這一步所有的請求都被改派到了更新過的數(shù)據(jù)中查找。
提交進程將 NEW 和 DELETE 區(qū)域的變化傳遞給PRIMARY。也即在PRIMARY緩存區(qū)以非原子的方式更新、增加、刪除數(shù)據(jù)項(圖2.4)。
***,所有的提交進程把全局標識切換回來,所有的請求仍然路由到 PRIMARY 緩存區(qū)域(圖2.5)。
在第4步,可以把老數(shù)據(jù)拷貝到另一個緩存區(qū),這樣就可以支持回滾操作。即使是全量更新也可以用這種方法。
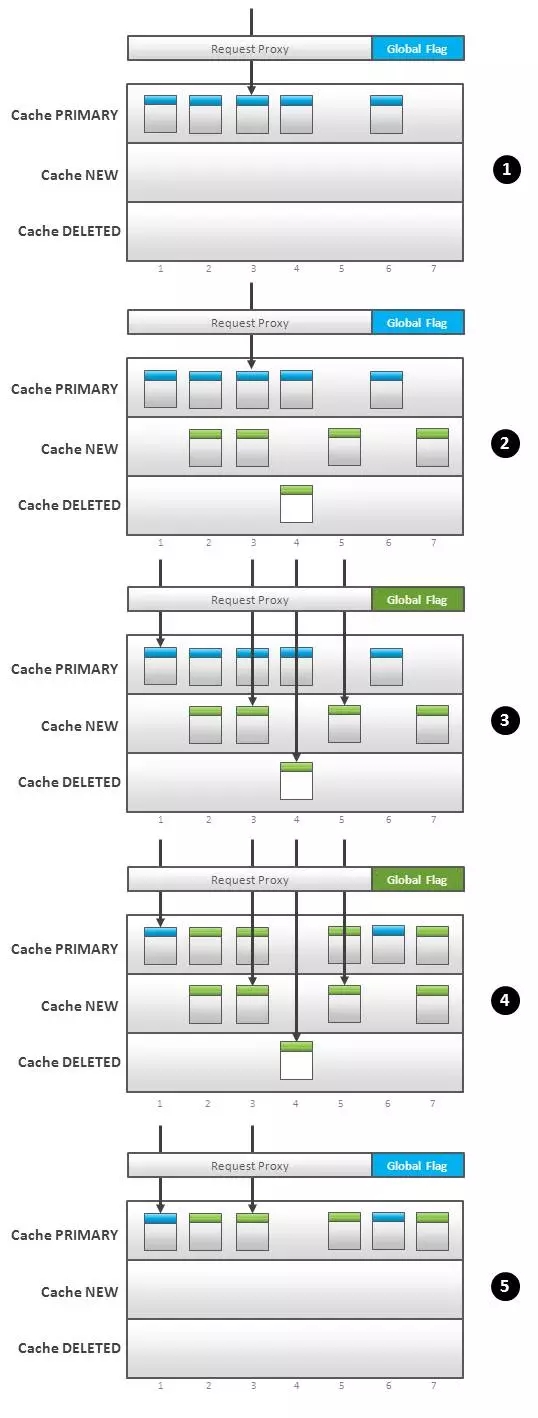
Fig.2 Partial Cache Switch
從上面的兩個例子我們可以看出,專用于讀的數(shù)據(jù)快照避免了數(shù)據(jù)更新的干擾,大大降低了復雜性。在一個寫密集型的環(huán)境中就不容易做到這一點了。在下一節(jié)我們會討論一種非常好的方法可以***的解決這個問題。
MVCC 事務,可重復讀隔離
事物間的隔離可以通過給數(shù)據(jù)項加上版本號來實現(xiàn)。有許多方法能做到這一點,下面我們會介紹一種與PostgreSQL 的事務處理方法非常相似的辦法。
正如前面所說,每個事務可以對應于一個部分數(shù)據(jù)快照。在同一時間,每一個數(shù)據(jù)項都有他自己的生命周期 - 從加入緩存到移出緩存或者被更新(被新版本所取代)。所以可以通過給每條數(shù)據(jù)打兩個時間戳來實現(xiàn)隔離,每個事物通過開始時間(兩個時間戳之一,譯者注)來找出在事務開始時處于可見狀態(tài)的數(shù)據(jù)。但在實踐中常用一個單調遞增的計數(shù)來代替時間戳:
- 新事務開始的時候:
它會獲得一個全局唯一且單調遞增的事務ID ,也叫 XID。
進程里保存著所有事務的XID.
- 緩存里的每個數(shù)據(jù)項有兩個額外標記,xmin 和 xmax。按照以下規(guī)則賦值:
當數(shù)據(jù)項被某個事務建立的時候, xmin 設置為該事務的XID ,xmax 無值。
當數(shù)據(jù)被某個事務移除的時候,xmin 不變,xmax 設置為該事務的XID。數(shù)據(jù)并沒有真的從緩存中清除,只是被標記為已刪除。
當數(shù)據(jù)被某個事務更新的時候,老數(shù)據(jù)仍然保存在緩存里,xmax 被賦值為事務的XID,同時增加一條新的數(shù)據(jù),新數(shù)據(jù)的 xmin 也賦值為XID 并且xmax 為空。換句話說更新操作等于一次刪除加一次增加。
- 如果以下兩個條件成立,那么數(shù)據(jù)對于某次事務是可見的:
xmin 有值并且小于或等于當前事務ID。
xmax 為空,或者等于未提交事務(放棄的或者還未完成的)的XID ,或者大于當前事務ID。
xmin 和 xmax 可以存儲兩個位標記,表明事務是否放棄或者提交,這樣才能進行上面的檢查(xmax 是否等于未提交事務的ID)。
邏輯如下圖所示:
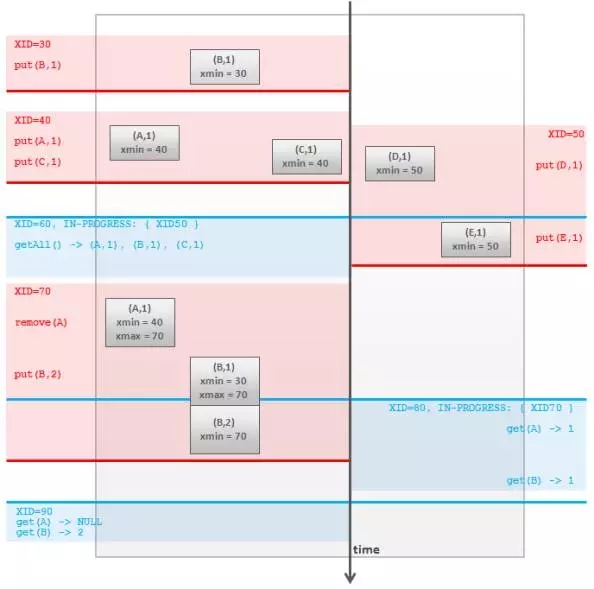
Fig.3 PostgeSQL-like MVCC
這種方法的缺點是廢棄數(shù)據(jù)的移除有些繁瑣。因為不同事務看到的數(shù)據(jù)版本不同,決定何時將數(shù)據(jù)標為不可見或者移除是比較復雜的。不過也有兩種以上的方法能夠做到,***種是PostgreSQL中使用的,第二種是Oracle使用的:
所有的版本都存儲在同一個key-value空間中,對版本數(shù)量沒有限制(也即可以儲存任意多的版本,譯者注)。由一個后臺進程來回收老版本數(shù)據(jù),這個回收可以按計劃調度執(zhí)行也可以再讀或者寫的時候觸發(fā)。
主key-value 空間只儲存***的版本,之前的版本儲存在另外的地方,且儲存老版本的空間大小是固定的。 ***的版本會指向之前的版本,但是卻不能夠由此上溯到之前的任意版本, 因為存儲老版本數(shù)據(jù)的區(qū)域大小是固定的, 太早的版本會被移除。如果某個事務不能夠找到指定版本的數(shù)據(jù)就會失敗。