自然語言處理是如何工作的?一步步教你構建NLP流水線
計算機更擅長理解結構化數據,讓計算機去理解主要以文化習慣沉淀下來的人類語言實在是太為難它們了。那自然語言處理獲得的成功又是如何成就的呢?那就是,把人類語言(盡可能)結構化。本文以簡單的例子一步步向我們展示了自然語言處理流水線的每個階段的工作過程,也就是將語言結構化的過程,從句子分割、詞匯標記化、...、到共指解析。作者的解釋很直觀、好理解,對于剛入門 NLP 的小伙伴是不可多得的好文。
計算機是如何理解人類語言的。
計算機非常擅長使用結構化數據,例如電子表格和數據庫表。但是我們人類通常用文字交流,而不是使用電子表格來交流。這對計算機來說不是一件好事。
遺憾的是,在歷史的進程中我們從未生活在一個充滿結構化數據的世界里。

世界上很多信息是非結構化的——例如英語或其他人類語言中的原始文本。那我們要如何讓計算機了解非結構化文本并從中提取數據呢?

自然語言處理,或簡稱為 NLP,是 AI 的子領域,重點放在使計算機能夠理解和處理人類語言。接下來讓我們看看 NLP 是如何工作,并學習如何使用 Python 編程來從原始文本中提取信息。
注意:如果你不關心 NLP 是如何工作的,只想復制和粘貼一些代碼,請跳過到「在 Python 中實現 NLP 流水線」的部分。
一、計算機能理解語言嗎?
只要計算機一直存在,程序員就一直在嘗試編寫出能理解像英語這樣的語言的程序。原因很明顯——人類已經書寫下了幾千年的信息,如果計算機能夠讀取和理解所有的這些數據,這將是非常有幫助的。
盡管計算機還不能像人類那樣真正地理解英語——但是已經可以做很多事情了!在某些特定的領域,你可以用 NLP 技術去做一些看起來很神奇的事情,也可以在自己的項目中應用 NLP 技術來節省大量的時間。
更為便利的是,目前最新的 NLP 技術進展都可以通過開源的 Python 庫(例如 spaCy、textacy、neuralcoref 等)來調用,僅僅需要幾行 Python 代碼即可實現 NLP 技術。
二、從文本中提取含義并不容易
閱讀和理解英語的過程是非常復雜的,這個過程甚至沒有包括考慮到英語有時并不遵循邏輯和一致的規則。例如,這條新聞標題是什么意思?
| 「Environmental regulators grill business owner over illegal coal fires.」 |
是監管者質疑企業所有者非法燃燒煤炭嗎?還是監管者真的在架起企業所有者并用煤炭燒烤?正如你所看到的,用計算機解析英語將會變得非常復雜。
在機器學習中做任何復雜的事情通常意味著需要建立一條流水線 (pipeline)。這個想法是把你的問題分解成非常小的部分,然后用機器學習來分別解決每個部分,最后通過把幾個互相饋送結果的機器學習模型連接起來,這樣你就可以解決非常復雜的問題。
這正是我們要運用在 NLP 上的策略。我們將把理解英語的過程分解成小塊,然后看看每個小塊是如何工作的。
三、一步一步建立 NLP 流水線
讓我們來看看來自維基百科的一段文字:
| London is the capital and most populous city of England and the United Kingdom. Standing on the River Thames in the south east of the island of Great Britain, London has been a major settlement for two millennia. It was founded by the Romans, who named it Londinium. |
(倫敦是英格蘭的首都同時也是英國人口最大的城市,是大不列顛東南部的泰晤士河流域兩千年來的主要人類定居點,由羅馬人建立,取名為倫蒂尼恩 (Londinium)。
這一段話包含了一些有用的事實。如果一臺電腦能閱讀這篇文章,理解到倫敦是一座城市,倫敦位于英國,倫敦由羅馬人定居,那就太好了。但是為了達到這個目的,我們首先必須教會計算機最基本的書面語言概念,然后基于此再逐步進行完善。
步驟 1:句子分割
流水線的第一步是把文本拆分成單獨的句子,像這樣:
- 「倫敦是英格蘭的首都同時也是英國人口最多的城市。」
- 「位于大不列顛島東南部的泰晤士河流域的倫敦是兩千年以來的主要人類定居點。」
- 「由羅馬人建立,取名為倫蒂尼恩 (Londinium)。」
我們可以假設英語中的每個句子都表達了一個獨立的思想或想法。編寫一個程序來理解一個句子比理解整個段落要容易得多。
編碼一個句子分割模型可以很簡單地在任何看到標點符號的時候拆分句子。但是,現代 NLP 流水線通常使用更為復雜的技術,以應對那些沒有被格式化干凈的文件。
步驟 2:詞匯標記化
現在我們已經把文檔分割成句子,我們可以一次處理一個。讓我們從文檔中的第一句話開始:
| 「London is the capital and most populous city of England and the United Kingdom.」 |
我們的下一步是把這個句子分成不同的單詞或標記,這叫做標記化,下面是標記化后的結果:
| 「London」,「is」,「the」,「capital」,「and」,「most」,「populous」,「city」,「of」,「England」,「and」,「the」,「United」,「Kingdom」,「.」 |
英語中的標記化是很容易做到的。只要它們之間有空格,我們就把它們分開。我們也將標點符號當作單獨的記號來對待,因為標點也是有意義的。
步驟 3:預測每個標記的詞性
接下來,我們來看看每一個標記,并嘗試猜測它的詞類:名詞,動詞,形容詞等等。知道每個單詞在句子中的作用將幫助我們弄清楚句子的意思。
我們可以把每個單詞(和它周圍的一些額外的單詞用于上下文)輸入預先訓練的詞性分類模型:

詞性模型最初是通過給它提供數以百萬計的英語句子來訓練的,每一個單詞的詞性都已經標注出來,并讓它學會復制這種行為。
需要注意的是,這個模型完全是基于統計數據的,它并沒有真正理解單詞的意思(如人類所思考的一樣)。它只知道如何根據相似的句子和單詞來猜測詞性。
在處理完整個句子之后,我們將得到這樣的結果:

有了這些信息,我們就可以開始獲取一些非常基本的意思了。例如,我們可以看到句子中的名詞包括「倫敦」和「首都」,所以這個句子很可能說的的是關于倫敦。
步驟 4:文本詞形還原
在英語(和大多數語言)中,單詞以不同的形式出現。看這兩個句子:
- I had a pony.
- I had two ponies.
兩個句子都是在討論一個名詞 - 小馬(pony),但它們分別使用了不同的詞形變化 (一個單數形式,一個復數形式)。當在計算機中處理文本時,了解每個單詞的基本形式是有幫助的,這樣你才知道這兩個句子都在討論同一個概念。否則,對計算機來說字串「pony」和「ponies」看起來就像兩個完全不同的詞匯。
在 NLP 中,我們把這個過程稱為詞形還原——找出句子中每個單詞的最基本的形式或詞條。
同樣也適用于動詞。我們也可以通過找到它們的詞根,通過詞形還原來將動詞轉換成非結合格式。所以「I had two ponies.」變成「I [have] two [pony].」
詞形還原通常是通過基于詞性的詞條形式的查找表來完成的,并且可能通過一些自定義規則來處理一些你從未見過的單詞。
下面是詞形還原加上動詞的詞根形式后,我們的句子變成如下:

我們唯一的改變是把「is」變成「be」。
步驟 5:識別停止詞
接下來,我們要考慮句子中每個詞的重要性。英語有很多填充詞,它們經常出現,如「and」、「the」和「a」。當對文本進行統計時,這些詞引入了大量的噪聲,因為它們比其他詞更頻繁地出現。一些 NLP 流水線將它們標記為「停止詞」,也就是說,在進行任何統計分析之前,這可能是你想要過濾掉的單詞。
下面是我們將停止詞變成灰色后的句子:

停止詞通常通過檢查已知的停止詞的硬編碼列表來識別。但是沒有適用于所有應用程序的停止詞的標準列表。要忽略的單詞列表可以根據應用程序而變化。
例如,如果你正在建造一個搖滾樂隊搜索引擎,你要確保你不忽略「The」這個詞。因為這個詞出現在很多樂隊的名字中,還有一個著名的 1980 搖滾樂隊叫做「The The」!
步驟 6a:依賴解析
下一步是弄清楚我們句子中的所有單詞是如何相互關聯的,這叫做依賴解析。
我們的目標是構建一棵樹,它給句子中的每個單詞分配一個單一的父詞。樹的根結點是句子中的主要動詞。下面是我們的句子的解析樹一開始的樣子:

但我們可以更進一步。除了識別每個單詞的父詞外,我們還可以預測兩個詞之間存在的關系類型:

這棵解析樹告訴我們,句子的主語是名詞「London」,它與「capital」有「be」關系。我們終于知道了一些有用的東西——倫敦是一個首都!如果我們遵循完整的解析樹的句子(除上方所示),我們甚至會發現,倫敦是英國的首都。
就像我們先前使用機器學習模型預測詞性一樣,依賴解析也可以通過將單詞輸入機器學習模型并輸出結果來工作。但是解析單詞的依賴項是一項特別復雜的任務,需要一篇完整的文章來詳細說明。如果你想知道它是如何工作的,一個很好的開始閱讀的地方是 Matthew Honnibal 的優秀文章「Parsing English in 500 Lines of Python」。
但是,盡管作者在 2015 的一篇文章中說這種方法在現在是標準的,但它實際上已經過時了,甚至不再被作者使用。在 2016,谷歌發布了一個新的依賴性分析器,稱為 Parsey McParseface,它使用了一種新的深度學習方法并超越了以前的基準,它迅速地遍及整個行業。一年后,他們發布了一種新的叫做 ParseySaurus 的模型,它改進了更多的東西。換句話說,解析技術仍然是一個活躍的研究領域,在不斷地變化和改進。
同樣需要記住的是,很多英語句子都是模棱兩可的,難以解析的。在這種情況下,模型將根據該句子的解析版本進行猜測,但它并不完美,有時該模型將導致令人尷尬的錯誤。但隨著時間的推移,我們的 NLP 模型將繼續以更好的方式解析文本。
步驟 6b:尋找名詞短語
到目前為止,我們把句子中的每個詞都看作是獨立的實體。但是有時候把代表一個想法或事物的單詞組合在一起更有意義。我們可以使用依賴解析樹中的相關信息自動將所有討論同一事物的單詞組合在一起。
例如:

我們可以將名詞短語組合以產生下方的形式:

我們是否做這一步取決于我們的最終目標。如果我們不需要更多的細節來描述哪些詞是形容詞,而是想更多地關注提取完整的想法,那么這是一種快速而簡單的方法。
步驟 7:命名實體識別(NER)
現在我們已經完成所有困難的工作,終于可以超越小學語法,開始真正地提取想法。
在我們的句子中,我們有下列名詞:

這些名詞中有一些是真實存在的。例如,「London 倫敦」、「England 英格蘭」和「United Kingdom 英國」代表地圖上的物理位置。很高興能檢測到這一點!利用這些信息,我們可以使用 NLP 自動提取到文檔中提到的真實世界地名的列表。
命名實體識別(NER)的目標是用它們所代表的真實世界的概念來檢測和標記這些名詞。以下是我們在使用 NER 標簽模型運行每個標簽之后的句子:

但是 NER 系統不僅僅是簡單的字典查找。相反,他們使用的是一個單詞如何出現在句子中的上下文和一個統計模型來猜測單詞代表的是哪種類型的名詞。一個好的 NER 系統可以通過上下文線索來區分「Brooklyn Decker」這個人名和「Brooklyn」這個位置。
下面是一些典型的 NER 系統可以標記的對象類型:
- 人名
- 公司名稱
- 地理位置(物理和政治)
- 產品名稱
- 日期與時間
- 金錢數量
- 事件名稱
NER 有大量的用途,因為它可以很容易地從文本中獲取結構化數據。這是從 NLP 流水線中快速獲取有價值信息的最簡單方法之一。
步驟 8:共指解析
到此,我們對句子已經有了一個很好的表述。我們知道每個單詞的詞性、單詞如何相互關聯、哪些詞在談論命名實體。
然而,我們還有一個大問題。英語里充滿了人稱代詞,比如他、她,還有它。這些是我們使用的快捷表述方法,而不需要在每個句子中一遍又一遍地寫名字。人類可以根據上下文來記錄這些詞所代表的內容。但是我們的 NLP 模型不知道人稱代詞是什么意思,因為它一次只檢查一個句子。
讓我們看看文檔中的第三句話:
| 「It was founded by the Romans, who named it Londinium.」 |
如果我們用 NLP 流水線來解析這個句子,我們就會知道「it」是由羅馬人建立的。但知道「London」是由羅馬人建立的則更為有用。
人類閱讀這個句子時,可以很容易地理解「it」的意思是「London」。共指解析的目的是通過追蹤句子中的代詞來找出相同的映射。我們想找出所有提到同一個實體的單詞。
下面是我們的文檔中對「London」一詞的共指解析的結果:

利用共指信息與解析樹和命名實體信息相結合,我們可以從文檔中提取大量信息。
共指解析是 NLP 流水線實現中最困難的步驟之一。這比句子分析更困難。深度學習的最新進展研究出了更精確的新方法,但還不完善。如果您想了解更多關于它是如何工作的,請查看:https://explosion.ai/demos/displacy-ent。
四、NLP 流水線的 PYTHON 實現
下面是我們完整的 NLP 流水線的概述:

共指解析是一個不一定要完成的可選步驟。
喲,看起來有好多步驟!
注意:在我們繼續之前,值得一提的是,這些是典型的 NLP 流水線中的步驟,但是您可以將跳過某些步驟或重新排序步驟,這取決于您想做什么以及如何實現 NLP 庫。例如,像 spaCy 這樣的一些庫是在使用依賴性解析的結果后才在流水線中進行句子分割。
那么,我們應該如何對這個流水線進行編碼呢?感謝像 spaCy 這樣神奇的 Python 庫,它已經完成了!這些步驟都是編碼過的,可以隨時使用。
首先,假設已經安裝了 Python 3,可以這樣安裝 spaCy:
- # Install spaCy
- pip3 install -U spacy
- # Download the large English model for spaCy
- python3 -m spacy download en_core_web_lg
- # Install textacy which will also be useful
- pip3 install -U textacy
然后,在一段文本上運行 NLP 流水線的代碼看起來如下:
- import spacy
- # Load the large English NLP model
- nlp = spacy.load('en_core_web_lg')
- # The text we want to examine
- text = """London is the capital and most populous city of England and
- the United Kingdom. Standing on the River Thames in the south east
- of the island of Great Britain, London has been a major settlement
- for two millennia. It was founded by the Romans, who named it Londinium.
- """
- # Parse the text with spaCy. This runs the entire pipeline.
- doc = nlp(text)
- # 'doc' now contains a parsed version of text. We can use it to do anything we want!
- # For example, this will print out all the named entities that were detected:
- for entity in doc.ents:
- print(f"{entity.text} ({entity.label_})")
如果你運行到 z 這里,你將得到一個在我們的文檔中檢測到的命名實體和實體類型的列表:
- London (GPE)
- England (GPE)
- the United Kingdom (GPE)
- the River Thames (FAC)
- Great Britain (GPE)
- London (GPE)
- two millennia (DATE)
- Romans (NORP)
- Londinium (PERSON)
您可以在這里查找這些代碼:https://spacy.io/usage/linguistic-features#entity-types。
注意它在「Londinium」上犯了一個錯誤,認為它是一個人的名字而不是一個地方。這可能是因為在訓練數據集中沒有類似的東西,所以它做了最好的猜測。命名實體檢測通常需要一小段模型微調(https://spacy.io/usage/training#section-ner),如果您正在解析具有獨特或專用術語的文本。
讓我們來檢測實體并使用它來建立一個數據洗滌器。假設你正試圖遵守新的 GDPR 隱私規則
(https://medium.com/@ageitgey/understand-the-gdpr-in-10-minutes-407f4b54111f),并且你發現你有數以千計的文件,其中包含有個人可識別的信息,比如人的名字。你接到了移除文檔中所有名字的任務。
通過數以千計的文件去搜尋并刪除所有的名字,人工可能需要幾年。但是使用 NLP,這是很容易實現的。這里有一個簡單的洗滌器,去除它檢測到的所有名字:
- import spacy
- # Load the large English NLP model
- nlp = spacy.load('en_core_web_lg')
- # Replace a token with "REDACTED" if it is a name
- def replace_name_with_placeholder(token):
- if token.ent_iob != 0 and token.ent_type_ == "PERSON":
- return "[REDACTED] "
- else:
- return token.string
- # Loop through all the entities in a document and check if they are names
- def scrub(text):
- doc = nlp(text)
- for ent in doc.ents:
- ent.merge()
- tokens = map(replace_name_with_placeholder, doc)
- return "".join(tokens)
- s = """
- In 1950, Alan Turing published his famous article "Computing Machinery and Intelligence". In 1957, Noam Chomsky’s
- Syntactic Structures revolutionized Linguistics with 'universal grammar', a rule based system of syntactic structures.
- """
- print(scrub(s))
如果你運行它,你會發現它的結果是符合你的預期的:
- In 1950, [REDACTED] published his famous article "Computing Machinery and Intelligence". In 1957, [REDACTED]
- Syntactic Structures revolutionized Linguistics with 'universal grammar', a rule based system of syntactic structures.
五、提取事實
你能用 spaCy 做的事情是非常多的。但是,您也可以使用 spaCy 解析的輸出作為更復雜的數據提取算法的輸入。有一個 Python 庫叫做 textacy,它在 spaCy 之上實現了幾種常見的數據抽取算法。這是一個很好的起點。
它實現的一種算法被稱為半結構化語句提取。我們可以用它來搜索解析樹,用于簡單的語句,其中主語是「London」,動詞是「be」的形式。這將有助于我們找到有關倫敦的事實。
以下是它的代碼實現:
- import spacy
- import textacy.extract
- # Load the large English NLP model
- nlp = spacy.load('en_core_web_lg')
- # The text we want to examine
- text = """London is the capital and most populous city of England and the United Kingdom.
- Standing on the River Thames in the south east of the island of Great Britain,
- London has been a major settlement for two millennia. It was founded by the Romans,
- who named it Londinium.
- """
- # Parse the document with spaCy
- doc = nlp(text)
- # Extract semi-structured statements
- statements = textacy.extract.semistructured_statements(doc, "London")
- # Print the results
- print("Here are the things I know about London:")
- for statement in statements:
- subject, verb, fact = statement
- print(f" - {fact}")
結果如下:
- Here are the things I know about London:
- - the capital and most populous city of England and the United Kingdom.
- - a major settlement for two millennia.
也許這不太令人印象深刻。但是如果你在整個倫敦維基百科的文章文本上運行相同的代碼而不僅僅是三個句子,你會得到更令人印象深刻的結果:
- Here are the things I know about London:
- - the capital and most populous city of England and the United Kingdom
- - a major settlement for two millennia
- - the world's most populous city from around 1831 to 1925
- - beyond all comparison the largest town in England
- - still very compact
- - the world's largest city from about 1831 to 1925
- - the seat of the Government of the United Kingdom
- - vulnerable to flooding
- - "one of the World's Greenest Cities" with more than 40 percent green space or open water
- - the most populous city and metropolitan area of the European Union and the second most populous in Europe
- - the 19th largest city and the 18th largest metropolitan region in the world
- - Christian, and has a large number of churches, particularly in the City of London
- - also home to sizeable Muslim, Hindu, Sikh, and Jewish communities
- - also home to 42 Hindu temples
- - the world's most expensive office market for the last three years according to world property journal (2015) report
- - one of the pre-eminent financial centres of the world as the most important location for international finance
- - the world top city destination as ranked by TripAdvisor users
- - a major international air transport hub with the busiest city airspace in the world
- - the centre of the National Rail network, with 70 percent of rail journeys starting or ending in London
- - a major global centre of higher education teaching and research and has the largest concentration of higher education institutes in Europe
- - home to designers Vivienne Westwood, Galliano, Stella McCartney, Manolo Blahnik, and Jimmy Choo, among others
- - the setting for many works of literature
- - a major centre for television production, with studios including BBC Television Centre, The Fountain Studios and The London Studios
- - also a centre for urban music
- - the "greenest city" in Europe with 35,000 acres of public parks, woodlands and gardens
- - not the capital of England, as England does not have its own government
現在事情正在變得更加趣了!這是我們自動收集的大量信息。
要獲得額外的支持,請嘗試安裝 neuralcoref 庫,并將 Coreference 解析添加到流水線中。這會讓你得到更多的事實,因為它會抓住談論「it」而不是直接提及「London」的句子。
六、我們還能做些什么呢?
通過瀏覽 spaCy 文檔和 textacy 文檔,你可以看到許多可以用解析文本處理的示例。到目前為止,我們看到的只是一個小型示例。
下面是另一個實際例子:假設你正在構建一個網站,讓用戶使用最后一個例子中提取的信息查看世界上每一個城市的信息。
如果你在網站上有一個搜索功能,那么可以自動完成像谷歌這樣的普通搜索查詢:
| Google‘s autocomplete suggestions for「London」 |
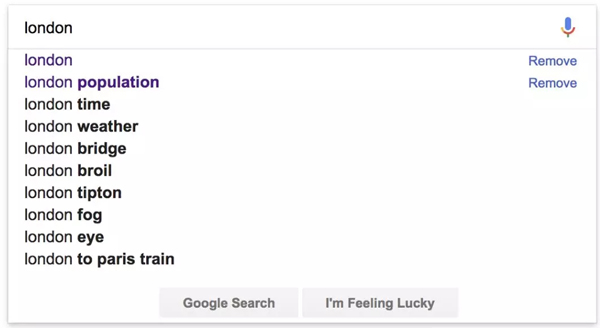
谷歌對「London」的自我完善的建議
但是要做到這一點,我們需要一個可能的完善建議的列表來向用戶提出建議。我們可以使用 NLP 來快速生成這些數據。
下面是從文檔中提取頻繁提到的名詞塊的一種方法:
- import spacy
- import textacy.extract
- # Load the large English NLP model
- nlp = spacy.load('en_core_web_lg')
- # The text we want to examine
- text = """London is [.. shortened for space ..]"""
- # Parse the document with spaCy
- doc = nlp(text)
- # Extract noun chunks that appear
- noun_chunks = textacy.extract.noun_chunks(doc, min_freq=3)
- # Convert noun chunks to lowercase strings
- noun_chunks = map(str, noun_chunks)
- noun_chunks = map(str.lower, noun_chunks)
- # Print out any nouns that are at least 2 words long
- for noun_chunk in set(noun_chunks):
- if len(noun_chunk.split(" ")) > 1:
- print(noun_chunk)
如果你在倫敦維基百科的文章上運行,你會得到這樣的輸出:
- westminster abbey
- natural history museum
- west end
- east end
- st paul's cathedral
- royal albert hall
- london underground
- great fire
- british museum
- london eye
- .... etc ....
七、深入探討
這只是一個微小的嘗試,讓你去理解可以用 NLP 做什么。在以后的文章中,我們將討論 NLP 的其他應用,如文本分類以及 Amazon Alexa 等系統如何解析問題。
但在此之前,先安裝 spaCy(https://spacy.io/)并開始去使用它!可能你不是一個 Python 用戶,也可能你最終使用是一個不同的 NLP 庫,但這些想法都應該是大致相同。
原文鏈接:
https://medium.com/@ageitgey/natural-language-processing-is-fun-9a0bff37854e
【本文是51CTO專欄機構“機器之心”的原創文章,微信公眾號“機器之心( id: almosthuman2014)”】