每月處理15億次登錄,Auth0高可用架構(gòu)實(shí)踐
原創(chuàng)【51CTO.com原創(chuàng)稿件】如今,身份驗(yàn)證對(duì)絕大多數(shù)應(yīng)用程序而言至關(guān)重要。Auth0 可以為任何堆棧上的各類(移動(dòng)、Web 和原生)應(yīng)用程序提供身份驗(yàn)證、授權(quán)和單點(diǎn)登錄服務(wù)。
我們?cè)O(shè)計(jì)的 Auth0 一開始就可以在任何地方運(yùn)行:我們的云、你的云,甚至在你自己的私有基礎(chǔ)設(shè)施上。
在本文中我們將詳細(xì)探討我們的公共 SaaS 部署,并簡(jiǎn)要介紹 auth0.com 背后的基礎(chǔ)設(shè)施,以及用來確保它順暢運(yùn)行的高可用性策略。
我們?cè)?nbsp;2014 年撰文介紹了 Auth0 的架構(gòu),自那以來 Auth0 已發(fā)生了很大的變化,下面是幾大要點(diǎn):
· 我們從每月處理數(shù)百萬次登錄升級(jí)至每月處理逾 15 億次登錄,為成千上萬的客戶提供服務(wù),包括 FuboTV、Mozilla 和 JetPrivilege 等。
· 我們實(shí)施了新功能,比如自定義域、擴(kuò)展的 bcrypt 操作以及大大改進(jìn)的用戶搜索等。
· 為了擴(kuò)展我們組織的規(guī)模并處理流量的增加,我們產(chǎn)品的服務(wù)數(shù)量從不到 10 個(gè)增加到了 30 多個(gè)。
· 云資源的數(shù)量也大幅增長,我們過去在一個(gè)環(huán)境(美國)中有幾十個(gè)節(jié)點(diǎn),現(xiàn)在我們?cè)谒膫€(gè)環(huán)境(美國、美國-2、歐盟和澳大利亞)有 1000 多個(gè)節(jié)點(diǎn)。
· 我們決定為自己的每個(gè)環(huán)境使用單一云提供商,并將所有公共云基礎(chǔ)設(shè)施遷移到了 AWS。
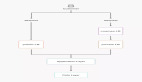
核心服務(wù)架構(gòu)
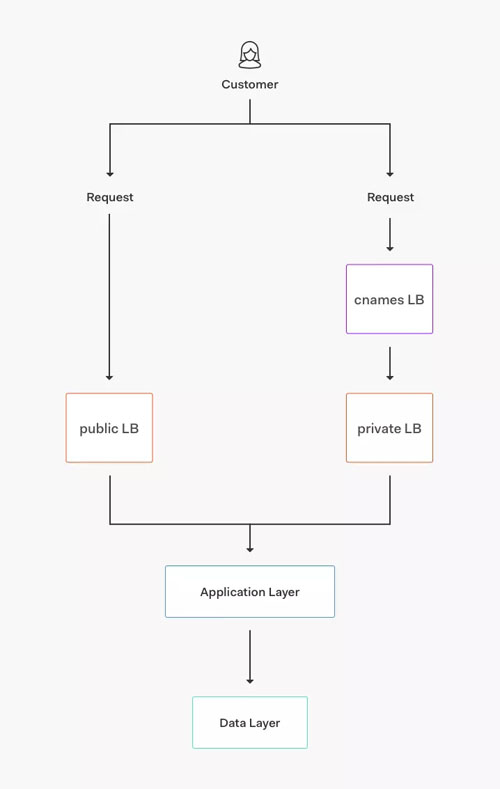
圖 1:Auth0.com 的核心服務(wù)架構(gòu)
我們的核心服務(wù)包括如下不同的層:
· 核心應(yīng)用程序:可自動(dòng)擴(kuò)展的服務(wù)器組,這些服務(wù)器運(yùn)行我們堆棧的不同服務(wù)(身份驗(yàn)證、管理 API 和多因子身份驗(yàn)證 API 等)。
· 數(shù)據(jù)存儲(chǔ):MongoDB、Elasticsearch、Redis 和 PostgreSQL 集群,為不同的應(yīng)用程序和功能特性存儲(chǔ)眾多數(shù)據(jù)集。
· 傳輸/隊(duì)列:Kinesis 數(shù)據(jù)流以及 RabbitMQ、SNS 和 SQS 隊(duì)列。
· 基礎(chǔ)服務(wù):針對(duì)速率限制、bcrypt 集群和功能標(biāo)志等其他的服務(wù)。
· 路由:AWS 負(fù)載均衡系統(tǒng)(來自 AWS 的 ALB、NLB 和 ELB)以及一些運(yùn)行 Nginx 充當(dāng)代理的節(jié)點(diǎn)。
高可用性
2014 年,我們使用了多云架構(gòu)(使用 Azure 和 AWS,還有谷歌云上的一些額外資源),多年來該架構(gòu)為我們提供了良好的服務(wù)。隨著使用量(和負(fù)載)迅速增加,我們發(fā)現(xiàn)自己越來越依賴 AWS 資源。
最初,我們將環(huán)境中的主區(qū)域切換到 AWS,Azure 留作故障切換區(qū)域。我們開始使用更多的 AWS 資源(比如 Kinesis 和 SQS)時(shí),將同樣的功能特性放在這兩家提供商處開始遇到了麻煩。
隨著移動(dòng)(和擴(kuò)展)的速度越來越快,我們選擇繼續(xù)支持 Azure,但功能同等性(feature parity)有限。
如果 AWS 上的一切出現(xiàn)故障,我們?nèi)钥梢允褂?nbsp;Azure 集群來支持身份驗(yàn)證等核心功能,但是不支持我們一直在開發(fā)的許多新功能。
2016 年出現(xiàn)幾次嚴(yán)重宕機(jī)后,我們決定最終集中到 AWS 上。我們停止了與確保服務(wù)和自動(dòng)化平臺(tái)無關(guān)的全部工作,而是專注于:
· 在 AWS 內(nèi)部提供更好的故障切換機(jī)制,使用多個(gè)區(qū)域,每個(gè)區(qū)域至少 3 個(gè)可用區(qū)。
· 增加使用 AWS 特有的資源,比如自動(dòng)擴(kuò)展組(而不是使用固定的節(jié)點(diǎn)集群)和應(yīng)用程序負(fù)載均衡系統(tǒng)(ALB)等。
· 編寫更好的自動(dòng)化:我們改進(jìn)了自動(dòng)化,完全采用基礎(chǔ)設(shè)施即代碼,使用 TerraForm 和 SaltStack 來配置新的 Auth0 環(huán)境(以及替換現(xiàn)有環(huán)境)。
這讓我們從每秒處理約 300 次登錄的部分自動(dòng)化環(huán)境升級(jí)到每秒處理逾 3400 次登錄的全自動(dòng)化環(huán)境;使用新工具更容易向上擴(kuò)展(必要的話還可以向下擴(kuò)展)。
我們實(shí)現(xiàn)的自動(dòng)化水平并不***,但讓我們極其方便地?cái)U(kuò)大到新的區(qū)域、創(chuàng)建新的環(huán)境。
· 編寫更好的劇本(playbook):隨著時(shí)間的推移,我們發(fā)現(xiàn)除了自動(dòng)化外,還需要更好的劇本,以便了解、管理和響應(yīng)與我們?cè)絹碓烬嫶蟮姆?wù)網(wǎng)格相關(guān)的事件。
這極大地提高了可擴(kuò)展性和可靠性,同時(shí)加快了新員工的入職。
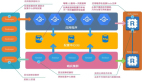
比如說,不妨看看我們的美國環(huán)境架構(gòu)。我們有這個(gè)總體結(jié)構(gòu),如下圖:

圖 2:Auth0 美國環(huán)境架構(gòu)
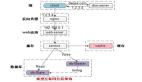
下圖是單一可用區(qū)內(nèi)部的結(jié)構(gòu):
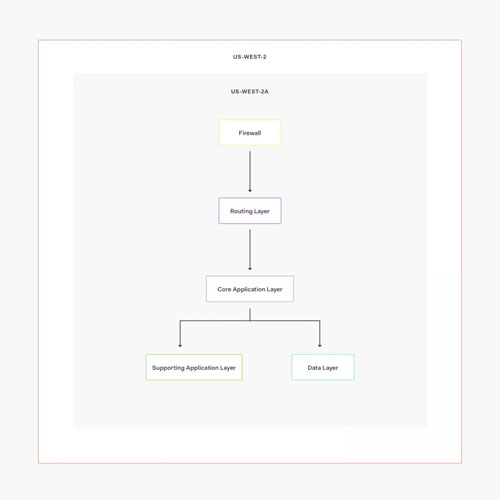
圖 3:Auth0 單一可用區(qū)
在這種情況下,我們使用兩個(gè) AWS 區(qū)域:
· us-west-2(我們的主區(qū)域)
· us-west-1(故障切換區(qū)域)
正常情況下,所有請(qǐng)求都流向 us-west-2,由三個(gè)獨(dú)立的可用區(qū)處理請(qǐng)求。
這就是我們實(shí)現(xiàn)高可用性的方式:所有服務(wù)(包括數(shù)據(jù)庫)在每個(gè)可用區(qū)(AZ)上都有運(yùn)行中的實(shí)例。
如果一個(gè)可用區(qū)因數(shù)據(jù)中心故障而宕機(jī),我們?nèi)杂袃蓚€(gè)可用區(qū)來處理請(qǐng)求;如果整個(gè)區(qū)域宕機(jī)或出現(xiàn)錯(cuò)誤,我們可以通知 Route53 故障切換到 us-west-1、恢復(fù)操作。
我們?cè)诜?wù)故障切換方面有不同的成熟度級(jí)別:一些服務(wù)(比如在 Elasticsearch 上構(gòu)建緩存的用戶搜索 v2)可正常運(yùn)行,但數(shù)據(jù)稍顯陳舊,不過核心功能按預(yù)期運(yùn)行。
在數(shù)據(jù)層中,我們使用:
· 面向 MongoDB 的跨區(qū)域集群。
· 面向 PostgreSQL 的 RDS 復(fù)制。
· 面向 Elasticsearch 的每個(gè)區(qū)域的集群,自動(dòng)快照和恢復(fù)定期運(yùn)行,以解決缺少跨區(qū)域集群的問題。
我們每年至少進(jìn)行一次故障切換演練,我們有劇本和自動(dòng)化,幫助新的基礎(chǔ)設(shè)施工程師盡快了解如何演練以及由此帶來的影響。
我們的部署通常由 Jenkins 節(jié)點(diǎn)觸發(fā);視服務(wù)而定,我們使用 Puppet、SaltStack 及/或 Ansible 來更新單個(gè)節(jié)點(diǎn)或一組節(jié)點(diǎn),或者我們更新 AMI,為不可變的部署創(chuàng)建新的自動(dòng)擴(kuò)展組。
我們?yōu)樾屡f服務(wù)部署了不同類型的環(huán)境;由于我們需要為應(yīng)該統(tǒng)一的系統(tǒng)維護(hù)自動(dòng)化、文檔和監(jiān)控,結(jié)果證明這基本上很低效。
我們目前在為一些核心服務(wù)推出藍(lán)/綠部署(blue/green deployment),我們打算為每個(gè)核心的支持服務(wù)實(shí)施同樣的一套。
自動(dòng)化測(cè)試
除了每個(gè)項(xiàng)目的單元測(cè)試覆蓋外,我們還有在每個(gè)環(huán)境中運(yùn)行的多個(gè)功能測(cè)試套件。
我們?cè)诓渴鸬缴a(chǎn)環(huán)境之前先在試運(yùn)行環(huán)境上運(yùn)行,完成部署后再在生產(chǎn)環(huán)境中運(yùn)行,以確保一切正常。
我們的自動(dòng)化測(cè)試要點(diǎn):
· 在不同的項(xiàng)目中有數(shù)千個(gè)單元測(cè)試。
· 使用每分鐘運(yùn)行的 Pingdom 探針(probe)來檢查核心功能。
· 在每次部署前后結(jié)合使用基于 Selenium 的功能測(cè)試和基于 CodeceptJS 的功能測(cè)試。功能測(cè)試套件測(cè)試不同的 API 端點(diǎn)、身份驗(yàn)證流程和身份提供者等。
CDN
2017 年之前我們運(yùn)行自己專門定制的 CDN,在多個(gè)區(qū)域運(yùn)行 Nginx、Varnish 和 EC2 節(jié)點(diǎn)。
2017 年以后,我們改用 CloudFront,它為我們帶來了幾個(gè)好處,包括:
· 更多的邊緣位置,這意味著為我們的客戶縮短了延遲。
· 降低維護(hù)成本。
· 配置起來更輕松。
但同時(shí)也有幾個(gè)缺點(diǎn),比如我們需要運(yùn)行 Lambdas 來執(zhí)行一些配置(比如將自定義標(biāo)頭添加到 PDF 文件等等)。不過,好處絕對(duì)壓倒缺點(diǎn)。
Extend
我們提供的功能之一是能夠通過身份驗(yàn)證規(guī)則或自定義數(shù)據(jù)庫連接,運(yùn)行自定義代碼,作為登錄事務(wù)的一部分。
這些功能由 Extend(https://goextend.io/)提供支持,Extend 是一個(gè)可擴(kuò)展性平臺(tái),由 Auth0 發(fā)展而來,現(xiàn)在還被其他公司所使用。
有了 Extend,我們的客戶就可以用那些腳本和規(guī)則編寫所需的任何服務(wù),擴(kuò)展配置文件、規(guī)范屬性和發(fā)送通知等。
我們有專門針對(duì) Auth0 的 Extend 集群,它們結(jié)合使用 EC2 自動(dòng)擴(kuò)展組、Docker 容器和自定義代理,以處理來自我們用戶的請(qǐng)求,每秒處理數(shù)千個(gè)請(qǐng)求,并快速響應(yīng)負(fù)載變化。
想了解這如何構(gòu)建和運(yùn)行的更多信息,請(qǐng)參閱這篇介紹如何構(gòu)建自己的無服務(wù)器平臺(tái)的文章(https://tomasz.janczuk.org/2018/03/how-to-build-your-own-serverless-platform.html)。
監(jiān)控
我們結(jié)合使用不同的工具來監(jiān)控和調(diào)試問題:
· CloudWatch
· DataDog
· Pingdom
· SENTINL
我們的絕大多數(shù)警報(bào)來自 CloudWatch 和 DataDog。
我們往往通過 TerraForm 來配置 CloudWatch 警報(bào),用 CloudWatch 來監(jiān)控的主要問題有:
· 來自主負(fù)載均衡系統(tǒng)的 HTTP 錯(cuò)誤。
· 目標(biāo)組中不健康的實(shí)例。
· SQS 處理延遲。
CloudWatch 是基于 AWS 生成的指標(biāo)(比如來自負(fù)載均衡系統(tǒng)或自動(dòng)擴(kuò)展組的指標(biāo))來監(jiān)控警報(bào)的***工具。
CloudWatch 警報(bào)通常發(fā)送給 PagerDuty,再從 PagerDuty 發(fā)送給 Slack/手機(jī)。
DataDog 是我們用來存儲(chǔ)時(shí)間序列指標(biāo)并采取相應(yīng)操作的服務(wù)。我們發(fā)送來自 Linux 系統(tǒng)、AWS 資源和現(xiàn)成服務(wù)(比如 Nginx 或 MongoDB)的指標(biāo),還發(fā)送來自我們構(gòu)建的自定義服務(wù)(比如 Management API)的指標(biāo)。
我們有許多 DataDog 監(jiān)控指標(biāo),舉幾個(gè)例子:
· $environment 上的 $service 響應(yīng)時(shí)間增加。
· $instance 中的 $volume($ ip_address)空間不足。
· $environment / $ host 上的 $process($ ip_address)出現(xiàn)問題。
· $environment 上的 $service 處理時(shí)間增加。
· $host($ip_address)上出現(xiàn) NTP 漂移/時(shí)鐘問題。
· $environment 上的 MongoDB 副本集變更。
從上面例子中可以看出,我們監(jiān)控低級(jí)指標(biāo)(如磁盤空間)和高級(jí)指標(biāo)(如 MongoDB 副本集變更,這提醒我們主節(jié)點(diǎn)定義是否發(fā)生了變化)。我們做了大量的工作,設(shè)計(jì)了一些相當(dāng)復(fù)雜的指標(biāo)來監(jiān)控一些服務(wù)。
DataDog 警報(bào)的輸出非常靈活,我們通常將它們?nèi)堪l(fā)送給 Slack,只把那些“引人注意”的警報(bào)發(fā)送給 PagerDuty,比如錯(cuò)誤高峰,或者我們確信對(duì)客戶產(chǎn)生影響的大多數(shù)事件。
至于日志記錄方面,我們使用 SumoLogic 和 Kibana;我們使用 SumoLogic 來記錄審計(jì)跟蹤記錄和 AWS 生成的許多日志,我們使用 Kibana 存儲(chǔ)來自我們自己的服務(wù)和其他“現(xiàn)成”服務(wù)(如 Nginx 和 MongoDB)的應(yīng)用程序日志。
未來設(shè)想
我們的平臺(tái)經(jīng)歷了很大的變化,以處理額外負(fù)載和對(duì)客戶來說很重要的眾多使用場(chǎng)景,但我們?nèi)杂袃?yōu)化的空間。
不僅我們的平臺(tái)在擴(kuò)大,我們的工程部門規(guī)模也在擴(kuò)大:我們有許多新團(tuán)隊(duì)構(gòu)建自己的服務(wù),而且需要自動(dòng)化、工具和可擴(kuò)展性方面的指導(dǎo)。
有鑒于此,我們落實(shí)了這些計(jì)劃,不僅擴(kuò)展平臺(tái),還夯實(shí)工程實(shí)踐:
· 構(gòu)建類似 PaaS 的平臺(tái):如前所述,今天我們有不同的自動(dòng)化和部署流程,這導(dǎo)致了混亂,給工程師設(shè)置了門檻,因?yàn)楹茈y在不接觸眾多代碼庫的情況下進(jìn)行試驗(yàn)和擴(kuò)展。
我們正在為目前在 ECS 上運(yùn)行的平臺(tái)開發(fā)概念證明(PoC)代碼,工程師們可以配置 YAML 文件,只需部署它,即可獲取計(jì)算資源、監(jiān)控、日志記錄和備份等。
所有這一切都無需明確配置。這項(xiàng)工作還處于早期階段,可能會(huì)發(fā)生很大變化。然而,鑒于我們不斷擴(kuò)大的規(guī)模和可擴(kuò)展性方面的限制,我們認(rèn)為我們的方向正確。
· 針對(duì)每個(gè)新的合并請(qǐng)求實(shí)施冒煙測(cè)試(smoke test):除了單元測(cè)試(已經(jīng)在每個(gè)新的 PR 上運(yùn)行)外,我們希望盡可能在短暫環(huán)境上進(jìn)行集成測(cè)試。
· 將我們的日志記錄解決方案集中到一家提供商。這可能意味著遠(yuǎn)離 Kibana,只使用 SumoLogic,但我們?nèi)孕枰u(píng)估功能集和數(shù)據(jù)量等。
· 自動(dòng)衡量指標(biāo):現(xiàn)在我們的指標(biāo)好多都是手動(dòng)的――部署時(shí)添加與指標(biāo)有關(guān)的代碼調(diào)用,以及使用 DataDog 接口來構(gòu)建儀表板和監(jiān)控器。
如果我們使用標(biāo)準(zhǔn)格式和命名,可以實(shí)現(xiàn)一些任務(wù),比如自動(dòng)構(gòu)建儀表板/監(jiān)控器,從日志提取指標(biāo)而不是明確添加代碼調(diào)用等。
· 確保我們針對(duì)每個(gè)核心服務(wù)都有自動(dòng)擴(kuò)展和藍(lán)/綠部署。這應(yīng)該是我們新平臺(tái)的默認(rèn)功能,但在構(gòu)建和測(cè)試時(shí),我們需要為這方面仍然不足的核心服務(wù)改進(jìn)擴(kuò)展/部署/回滾機(jī)制。
【51CTO原創(chuàng)稿件,合作站點(diǎn)轉(zhuǎn)載請(qǐng)注明原文作者和出處為51CTO.com】
【責(zé)任編輯:關(guān)崇 TEL:(010)68476606】