用Go構(gòu)建一個(gè)SQL解析器
摘要
本文旨在簡(jiǎn)單介紹如何在 Go 中構(gòu)造 LL(1) 解析器,在本例中用于解析SQL查詢。
為了簡(jiǎn)單起見(jiàn),我們將處理子選擇、函數(shù)、復(fù)雜嵌套表達(dá)式和所有 SQL 風(fēng)格都支持的其他特性。這些特性與我們將要使用的策略緊密相關(guān)。
1分鐘理論
一個(gè)解析器包含兩個(gè)部分:
- 詞法分析:也就是“Tokeniser”
- 語(yǔ)法分析:AST 的創(chuàng)建
詞法分析
讓我們用例子來(lái)定義一下。“Tokenising”以下查詢:
- SELECT id, name FROM 'users.csv'
表示提取構(gòu)成此查詢的“tokens”。tokeniser 的結(jié)果像這樣:
- []string{"SELECT", "id", ",", "name", "FROM", "'users.csv'"}
語(yǔ)法分析
這部分實(shí)際上是我們查看 tokens 的地方,確保它們有意義并解析它們來(lái)構(gòu)造出一些結(jié)構(gòu)體,以一種對(duì)將要使用它的應(yīng)用程序更方便的方式表示查詢(例如,用于執(zhí)行查詢,用顏色高亮顯示它)。在這一步之后,我們會(huì)得到這樣的結(jié)果:
- query{
- Type: "Select",
- TableName: "users.csv",
- Fields: ["id", "name"],
- }
有很多原因可能會(huì)導(dǎo)致解析失敗,所以同時(shí)執(zhí)行這兩個(gè)步驟可能會(huì)比較方便,并在出現(xiàn)錯(cuò)誤時(shí)可以立即停止。
策略
我們將定義一個(gè)像這樣的解析器:
- type parser struct {
- sql string // The query to parse
- i int // Where we are in the query
- query query.Query // The "query struct" we'll build
- step step // What's this? Read on...
- }
- // Main function that returns the "query struct" or an error
- func (p *parser) Parse() (query.Query, error) {}
- // A "look-ahead" function that returns the next token to parse
- func (p *parser) peek() (string) {}
- // same as peek(), but advancing our "i" index
- func (p *parser) pop() (string) {}
直觀地說(shuō),我們首先要做的是“peek() ***個(gè) token”。在基礎(chǔ)的SQL語(yǔ)法中,只有幾個(gè)有效的初始 token:SELECT、UPDATE、DELETE等;其他的都是錯(cuò)誤的。代碼像這樣:
- switch strings.ToUpper(parser.peek()) {
- case "SELECT":
- parser.query.type = "SELECT" // start building the "query struct"
- parser.pop()
- // TODO continue with SELECT query parsing...
- case "UPDATE":
- // TODO handle UPDATE
- // TODO other cases...
- default:
- return parser.query, fmt.Errorf("invalid query type")
- }
我們基本上可以填寫(xiě) TODO 和讓它跑起來(lái)!然而,聰明的讀者會(huì)發(fā)現(xiàn),解析整個(gè) SELECT 查詢的代碼很快會(huì)變得混亂,而且我們有許多類型的查詢需要解析。所以我們需要一些結(jié)構(gòu)。
有限狀態(tài)機(jī)
FSMs 是一個(gè)非常有趣的話題,但我們來(lái)這里不是為了講這個(gè),所以不會(huì)深入介紹。讓我們只關(guān)注我們需要什么。
在我們的解析過(guò)程中,在任何給定的點(diǎn)(與其說(shuō)“點(diǎn)”,不如稱其稱為“節(jié)點(diǎn)”),只有少數(shù) token 是有效的,在找到這些 token 之后,我們將進(jìn)入新的節(jié)點(diǎn),其中不同的 token 是有效的,以此類推,直到完成對(duì)查詢的解析。我們可以將這些節(jié)點(diǎn)關(guān)系可視化為有向圖:
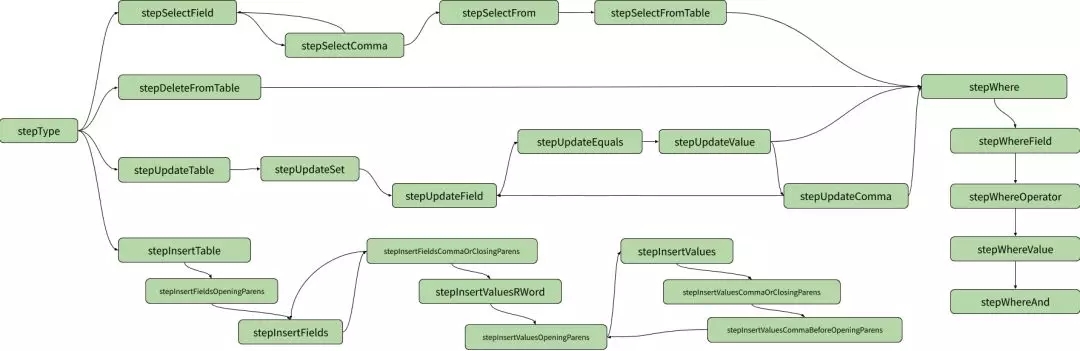
點(diǎn)轉(zhuǎn)換可以用一個(gè)更簡(jiǎn)單的表來(lái)定義,但是:
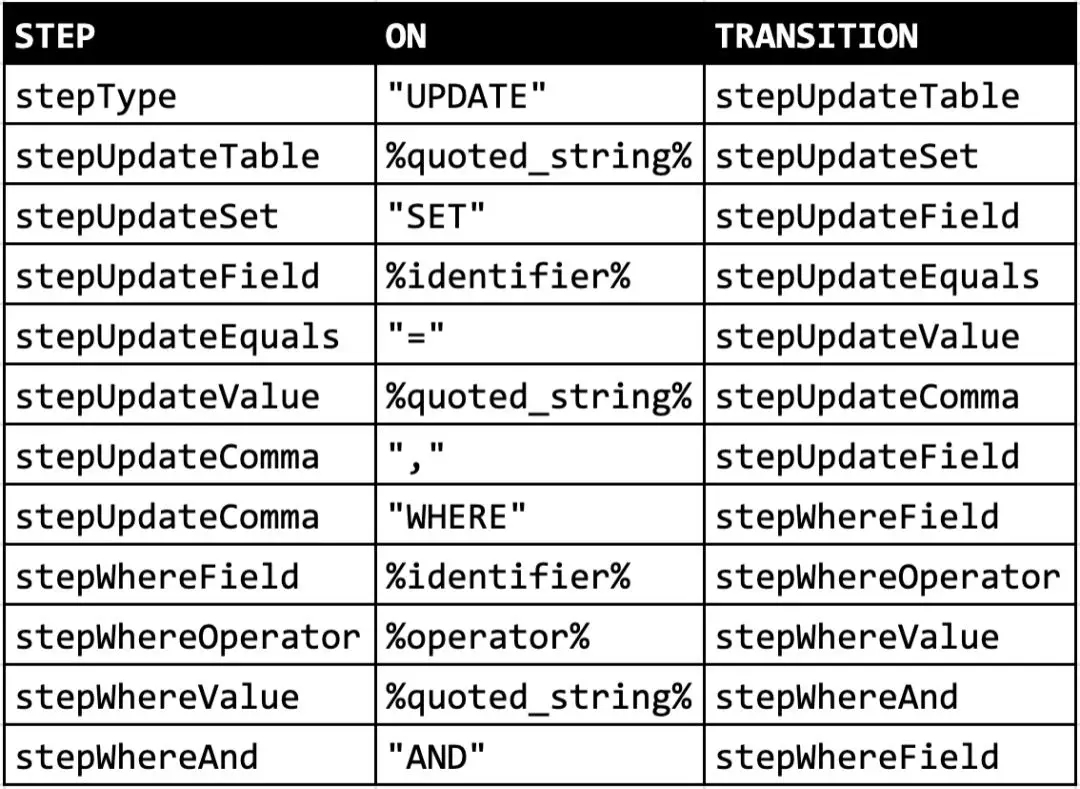
我們可以直接將這個(gè)表轉(zhuǎn)換成一個(gè)非常大的 switch 語(yǔ)句。我們將使用那個(gè)我們之前定義過(guò)的 parser.step 屬性:
- func (p *parser) Parse() (query.Query, error) {
- parser.step = stepType // initial step
- for parser.i < len(parser.sql) {
- nextToken := parser.peek()
- switch parser.step {
- case stepType:
- switch nextToken {
- case UPDATE:
- parser.query.type = "UPDATE"
- parser.step = stepUpdateTable
- // TODO cases of other query types
- }
- case stepUpdateSet:
- // ...
- case stepUpdateField:
- // ...
- case stepUpdateComma:
- // ...
- }
- parser.pop()
- }
- return parser.query, nil
- }
好了!注意,有些步驟可能會(huì)有條件地循環(huán)回以前的步驟,比如 SELECT 字段定義上的逗號(hào)。這種策略對(duì)于基本的解析器非常適用。然而,隨著語(yǔ)法變得復(fù)雜,狀態(tài)的數(shù)量將急劇增加,因此編寫(xiě)起來(lái)可能會(huì)變得單調(diào)乏味。我建議在編寫(xiě)代碼時(shí)進(jìn)行測(cè)試;更多信息請(qǐng)見(jiàn)下文。
Peek() 實(shí)現(xiàn)
記住,我們需要同時(shí)實(shí)現(xiàn) peek() 和 pop() 。因?yàn)樗鼈儙缀跏且粯拥模晕覀冇靡粋€(gè)輔助函數(shù)來(lái)保持代碼整潔。此外,pop() 應(yīng)該進(jìn)一步推進(jìn)索引,以避免取到空格。
- func (p *parser) peek() string {
- peeked, _ := p.peekWithLength()
- return peeked
- }
- func (p *parser) pop() string {
- peeked, len := p.peekWithLength()
- p.i += len
- p.popWhitespace()
- return peeked
- }
- func (p *parser) popWhitespace() {
- for ; p.i < len(p.sql) && p.sql[p.i] == ' '; p.i++ {
- }
- }
下面是我們可能想要得到的令牌列表:
- var reservedWords = []string{
- "(", ")", ">=", "<=", "!=", ",", "=", ">", "<",
- "SELECT", "INSERT INTO", "VALUES", "UPDATE",
- "DELETE FROM", "WHERE", "FROM", "SET",
- }
除此之外,我們可能會(huì)遇到帶引號(hào)的字符串或純標(biāo)識(shí)符(例如字段名)。下面是一個(gè)完整的 peekWithLength() 實(shí)現(xiàn):
- func (p *parser) peekWithLength() (string, int) {
- if p.i >= len(p.sql) {
- return "", 0
- }
- for _, rWord := range reservedWords {
- token := p.sql[p.i:min(len(p.sql), p.i+len(rWord))]
- upToken := strings.ToUpper(token)
- if upToken == rWord {
- return upToken, len(upToken)
- }
- }
- if p.sql[p.i] == '\'' { // Quoted string
- return p.peekQuotedStringWithLength()
- }
- return p.peekIdentifierWithLength()
- }
其余的函數(shù)都很簡(jiǎn)單,留給讀者作為練習(xí)。如果您感興趣,可以查看 github 的鏈接,其中包含完整的源代碼實(shí)現(xiàn)。
最終驗(yàn)證
解析器可能會(huì)在得到完整的查詢定義之前找到字符串的末尾。實(shí)現(xiàn)一個(gè) parser.validate() 函數(shù)可能是一個(gè)好主意,該函數(shù)查看生成的“query”結(jié)構(gòu),如果它不完整或錯(cuò)誤,則返回一個(gè)錯(cuò)誤。
測(cè)試Go的表格驅(qū)動(dòng)測(cè)試模式非常適合我們的情況:
- type testCase struct {
- Name string // description of the test
- SQL string // input sql e.g. "SELECT a FROM 'b'"
- Expected query.Query // expected resulting "query" struct
- Err error // expected error result
- }
測(cè)試實(shí)例:
- ts := []testCase{
- {
- Name: "empty query fails",
- SQL: "",
- Expected: query.Query{},
- Err: fmt.Errorf("query type cannot be empty"),
- },
- {
- Name: "SELECT without FROM fails",
- SQL: "SELECT",
- Expected: query.Query{Type: query.Select},
- Err: fmt.Errorf("table name cannot be empty"),
- },
- ...
像這樣測(cè)試測(cè)試用例:
- for _, tc := range ts {
- t.Run(tc.Name, func(t *testing.T) {
- actual, err := Parse(tc.SQL)
- if tc.Err != nil && err == nil {
- t.Errorf("Error should have been %v", tc.Err)
- }
- if tc.Err == nil && err != nil {
- t.Errorf("Error should have been nil but was %v", err)
- }
- if tc.Err != nil && err != nil {
- require.Equal(t, tc.Err, err, "Unexpected error")
- }
- if len(actual) > 0 {
- require.Equal(t, tc.Expected, actual[0],
- "Query didn't match expectation")
- }
- })
- }
我使用 verify 是因?yàn)楫?dāng)查詢結(jié)構(gòu)不匹配時(shí),它提供了一個(gè) diff 輸出。
深入理解
這個(gè)實(shí)驗(yàn)非常適合:
- 學(xué)習(xí) LL(1) 解析器算法
- 自定義解析無(wú)依賴關(guān)系的簡(jiǎn)單語(yǔ)法
然而,這種方法可能會(huì)變得單調(diào)乏味,而且有一定的局限性。考慮一下如何解析任意復(fù)雜的復(fù)合表達(dá)式(例如 sqrt(a) =(1 *(2 + 3)))。
要獲得更強(qiáng)大的解析模型,請(qǐng)查看解析器組合符。goyacc 是一個(gè)流行的Go實(shí)現(xiàn)。
下面是完整的解析器地址(或點(diǎn)擊閱讀原文查看):http://github.com/marianogappa/sqlparser