五分鐘向長輩解釋機器學習,這樣特別通俗!
什么是機器學習呢?如果是對此一竅不通的長輩來問你這個問題,你該如何回答?本文將用最簡單的詞匯來嘗試解釋這一話題,包括每個人都應該知道的最主要也是最重要的部分。
機器學習是一個旨在讓計算機在沒有被明確編程的前提下掌握學習能力的研究領域。這是一個正在迅速成長的領域,可以讓計算機進一步模仿人類。
機器學習不同于傳統計算機科學。在傳統中,計算機需要程序員準確地告訴它去做什么以及要怎么做,可以說是非常笨拙了。然而有了機器學習,我們只需要在計算機中輸入大量數據,就可以進行分析,并輸出結果了。
比如說,你知道怎么在Facebook上發布照片吧。當你發布照片時,Facebook會提醒你標記一些可能在照片中出現了的人。如果你不了解Facebook,那么再舉一個更常見的例子,你在瀏覽Netflix時,網頁會推薦一些可能喜歡的劇集或電影。其實,這就有點機器學習的意味了。
再比如說,機器學習在自動駕駛汽車上發揮著重要作用。汽車會收集大量的數據來學習怎樣開得更好更安全。顯而易見的是,機器學習將在未來的生活中扮演重要的角色。
機器學習不是什么
首先,機器學習并不是像你在電影中看到的那樣,機器人想要摧毀人類。當人們聽到人工智能時,往往首先會想到“終結者”。其實,機器學習并不是人工智能,它只是人工智能的一個子領域。機器學習已經經過了相當長一段時間的發展。其起源可以追溯到上世紀50年代晚期。當時,IBM的亞瑟·塞繆爾(Arthur L. Samuel)設計了第一款會下西洋棋的機器學習應用。
解釋邪惡人工智能時“必備”的終結者圖片
深度學習可能是你經常聽到的另一個時髦詞匯。深度學習的發展歷史和機器學習一樣長,但是直到上世紀80年代深度學習才得到廣泛重視。最終,世界科技巨頭如Facebook、谷歌和微軟紛紛大力投資深度學習的發展,繼而引發了人工智能革命。谷歌翻譯、蘋果智能助手Siri等等,都是深度學習的產物。
請放心,在可以預見的未來,即使機器學習或人工智能的發展失去控制,也不會對人類社會造成威脅。
怎樣讓機器學習
看到這里,你可能在想,那么到底是怎樣讓機器學習的呢?計算機是怎樣收集并理解信息的呢?其實,在這一過程中,我們會利用很多數學算法來幫助得到想要的結果。
1. 機器學習中的數學
線性代數是數學的一個研究領域,被公認為是深入了解機器學習的前提。線性代數的內容非常廣泛,包含很多晦澀難懂的理論和發現。但是其基本方法和符號對機器學習研究者來說是非常有用的。所以,需要有堅實的線性代數知識作為基礎。
數學對學習機器學習來說是極其重要的,因為我們需要在選擇算法時考慮其準確性、訓練時間以及其他性能。數學可以幫助我們找到一種讓機器學習的最佳方法。除了線性代數,機器學習科學家/工程師也需要掌握微積分、算法、概率論和統計學等數學概念。在機器學習中,Python是最常用的一種編程語言。
2. 聯想到大腦
大腦會將世界上各種各樣的信息收集起來形成我們對現實的看法。計算機也需要做到這一點。神經網絡就承擔了這一職責。
神經網絡是讓計算機模擬人類大腦最常用的方法。人類大腦由將近10億個神經細胞,也就是神經元構成。人類大腦非常擅長解決問題。在解決問題時,每個神經元都會負責解決其中的一小部分。這些神經元可以收集和傳遞信號,就像一個電網。
3. 人類大腦神經元
在知道了計算機神經網絡是受到人類大腦結構啟發設計的之后,你可能想知道這些神經元是怎么連接在一起的。每個神經元都會接收輸入,然后產生輸出。輸入節點(輸入層)為神經網絡提供來自外界的信息,就好比是你的眼睛看到并收集信息后傳遞給大腦。
輸出節點(輸出層)則負責將信息反饋給外界。假設下圖中的網絡將被訓練用來識別數字。一個數字從輸入層輸入,經過隱藏層,然后在輸出層以被識別出的數字輸出。隱藏層的神經元會互相交流各自獲取的信息。它們利用這些信息來識別輸入的數字是什么。每一層都會影響到下一層。
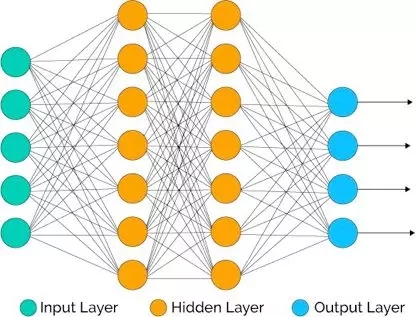
當訓練計算機神經網絡做其他事情,比如說音頻識別時,則更為神奇。計算機可以學習對演講進行文法分析、分段音頻以及篩選出不同的聲音。這些聲音被組合起來,構成特定的音節、單詞、詞組等。在構建網絡時,你需要知道:
- 卷積網絡往往用來做圖像識別
- 長短時記憶網絡往往用來做演講識別
機器學習還有多種方法,比如監督學習、非監督學習和強化學習,是經常使用的三種方法。本文不再詳述。簡單來說,神經網絡使得計算機能夠接收信息,將信息分成易于理解的部分,最后輸出它能得出的最接近的結果。
挑戰與局限性
雖然機器學習非常強大,但仍有很多局限性,克服這些局限性將幫助機器學習技術更上一層樓。
首先,機器學習算法需要大量的存儲數據用于訓練,而給這些數據做標記是一個非常繁瑣的過程。輸入機器的數據必須是被標記過的,否則機器將無法變得智能。算法僅能開發機器的決策能力,并與其按要求操縱的環境保持行為一致。
另一個問題就是機器無法解釋它自己。這就使得你很難知道它為什么做出某個決定。
最后一個也是最重要的一個局限性就是很難避免偏差。透明性至關重要,公正的決策可以幫助建立信任。比如說,面部識別在社交媒體和執法中發揮著重要的作用。但是面部識別提供的數據集中的偏差會使得結果不準確。如果說算法有偏差,并且數據集和訓練數據是不平衡的,那么最終輸出的結果將會放大數據集中的區別和偏差。
未來是機器的
機器學習是人工智能發展的基礎,它的未來是不可阻擋的。機器學習已經成為了現代生活的一部分。
如果你使用Spotify聽音樂,你會發現它會根據你聽的歌曲給你做每日推薦。亞馬遜也會根據客戶的購物習慣,學習如何給客戶推薦他們可能感興趣的商品。類似于亞馬遜的Alexa,蘋果的Siri以及微軟的Cortona這樣的虛擬助理,都是基于機器學習來理解人們說的話并和他們交互的。
機器學習在商業中也得到了廣泛應用。它可以自動化一些通常需要人類操作的工作。很多公司會在客戶服務部門使用聊天機器人和服務機器人。這些機器人會學習如何回復客戶,為客戶提供智能化的、有用的幫助。
還有機器學習在自動駕駛汽車和卡車上的應用。車輛需要學會識別路上的障礙物,如停車標志、暴風雪、路中間的球、其他車輛等,并做出相應的反應。收集的信息越多,它們就表現得越像人類。比如說,它們可以識別出一個被雪覆蓋的停車標志。
機器學習可以讓我們的生活變得更加便利。人們不斷地提出各種利用機器學習的方法,一場工業革命正在悄然發生。至于當機器學習逐漸引導我們走向真正的人工智能技術時,人類的生活會變成什么樣,只能靠想象了。