分布式緩存的高可用方案,我們都是這么做的
我們講到了當我們的系統面臨持續增加的并發給我們的數據庫磁盤IO帶了了性能瓶頸,特此為我們的系統引入了緩存,并且學習了我們在開發中該怎么去正確的使用緩存的讀寫策略,同時結合案例給出一些建議防止數據不一致的情況,那我們的系統現在就是這樣的架構了。
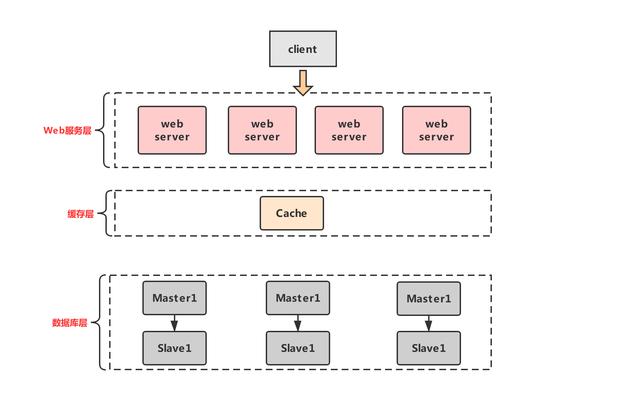
如上圖所示,我們在服務層和數據庫層之間增加一個緩存層,現在我們讀取數據的時候,先從緩存里面讀取,讀不到的再去讀數據庫。
既然我們引入了緩存,那肯定是想更多的請求盡量落在緩存上,也就是說我們必須要關注緩存命中率,命中率越高就代表我們的后端存儲就越不容易被拖垮成為性瓶頸,如果我們的緩存命中率下降一定要看是什么原因,因為對于高并發請求哪怕下降1% 都是災難。
比如,現在的系統QPS是10000,每次請求會查詢10次的緩存,現在命中率突然下降了1%,也就是我有 10000 * 10 * 1% =1000次的請求落到了我們后端數據庫MySql上了。這就代表了MySQL數據庫面臨突然增加的1000的并發,這是很危險的,基本普通機器mysql也只能抗大概2000的并發。所以,緩存命中率是要我們關注的。
現在只是下降1%就對系統影響這么大,那要是我們的緩存節點掛了,不可用了,那豈不是又回到了原點,請求都會打到我們的數據庫中的。所以,我們在使用緩存一定要搭建高可用緩存,避免上面的單點緩存架構。今天,我們就來學習該怎么做緩存的高可用方案即搭建分布式緩存的高可用方案。
依據經驗來說,對于分布式緩存高可用方案目前一般采用應用端、中間代理層以及服務端這三大方案。
- 應用端方案,在應用端自己配置緩存節點,通過緩存寫入和讀取算法策略來實現分布式,從而提高緩存的可用性。
- 代理層方案,在應用代碼和緩存節點之間增加一個獨立的代理層,應用端就直接喝代理層連接,代理層自己內置高可用策略,以提升緩存的可用性。
- 服務端方案,即為緩存服務自身提供的高可用,例如Redis Sentinel
接下來我們就來分別學習下這三種方案
應用端方案
在應用端也就是代碼層面上,我們就需要自己管理緩存的讀和寫,也就是通過寫代碼方式來進行分布式緩存的寫入和讀取,主要是下面這兩模塊:
- 寫緩存時,我們需要將數據分散到緩存的各個節點中,即要實現數據分片。
- 讀緩存時,需考慮主從或者多副本粗略以及使用多組緩存進行容錯。
下面我們來看看該怎么進行設計,其實這種設計思路不一定局限在緩存上,我們大部分的底層開發都能用上,希望大家好好掌握
緩存數據如何分片
我們知道單節點的緩存因受到各種原因如本身機器內存、網絡帶寬等,從而不能承受更高的并發,所以我們需要將數據進行分片存儲,即將數據通過分片算法打散到各個緩存節點中。其實這塊大家有沒有注意到和我們前面的分庫分表很類似,所以大部分架構思想都是相通的。
現在我們的數據就在各個緩存節點都有一部分,即使部分故障,也是不影響我們整個業務的。那這個時候,你可能在想,既然數據需要被均勻分散到各個節點,那我該怎么來寫這個分片算法呢?別急,我們下面就來看怎么寫這個分片算法。
數據分片算法
一般做數據分片算法的有兩種,大家應該都清楚吧,前面分庫分表就有用到的
- Hash分片算法
- 一致性Hash分片算法
Hash分片算法
Hash分片算法就是我們拿到緩存的key,然后對其做hash運算,最后將hash運算的結果對緩存總節點數取余,得到的數字則為具體的分片節點。比如,現在我們緩存節點一共有 3 個,當我們寫入數據的時候,將key進行hash運算hash(key),然后將結果對3取余就行了,如下圖所示:
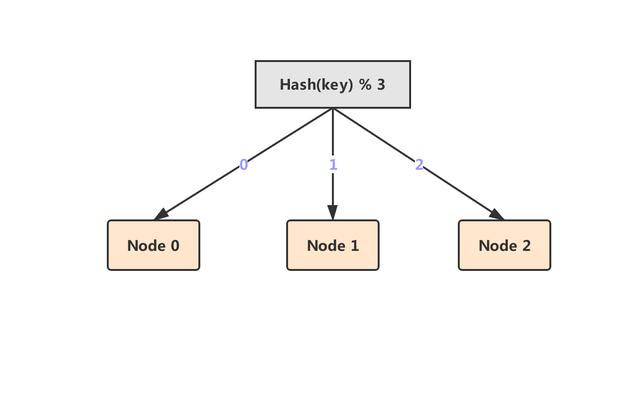
這種分片算法優點就是開發簡單且容易理解,缺點就是當我們的緩存總節點數改變的時候,就會導致數據不均勻,則會造成大量緩存失效不可用的情況。但是這種算法我們開發中也是會使用的,比如我們的業務對于緩存的命中率不是那么太在意的,就可以使用這種hash分片算法。
一致性Hash分片算法
上面簡單的Hash分片算法對緩存命中率要求較高的業務會有一定影響,所以一致性Hash分片算法就出來了,它很好的解決了因緩存節點的增加或減少帶來的緩存命中率下降的問題。那我們就來看看它是怎么做的。
- 首先維護一個2^32的hash環。
- 然后將各個緩存節點的IP或者機器名稱計算hash值,是每個節點計算多個hash出來,也就是所謂的虛擬節點。為了數據能更加的均勻,且能避免節點雪崩的發生。
- 將計算出來的hash值即虛擬節點放到hash環上。
- 當我們要寫入一個key的時候,就可以先對這個key做hash計算出hash值,,確定在hash環上的位置。
- 最后在環上按照順時針的方式查找,遇到的第一個緩存節點就是它要存放的節點。
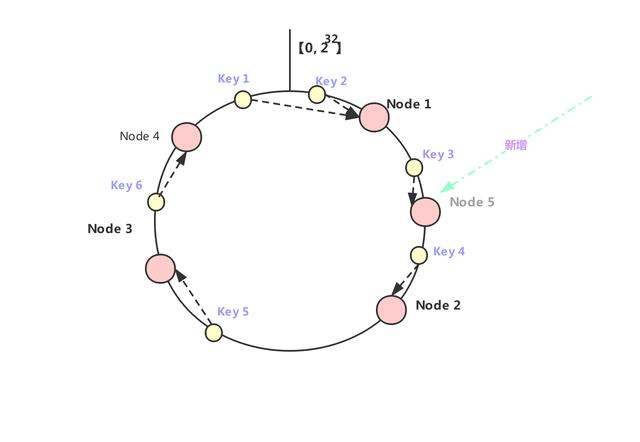
例如,下面key1 和 key2 就會進到 Node 1 里面,key3和key4 就會進到 Node 2 里面,key5 進到 Node3 中,key 6 則進到 Node 4 中去。
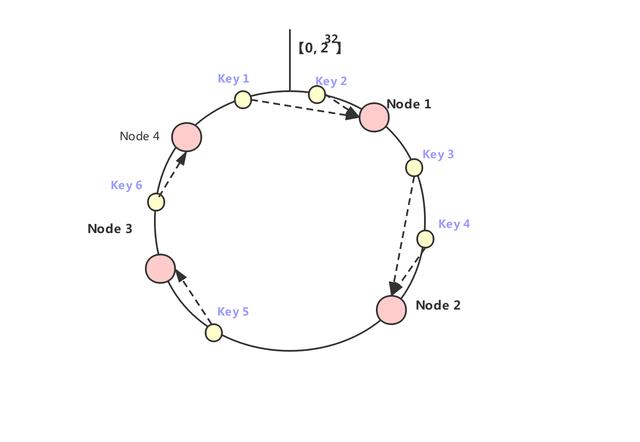
如上圖所示,如果在 Node 1 和 Node 2 之間再加一個 Node 5,我們可以看到之前命中 Node 2 的 Key 3 現在就會命中到 Node 5,而其它的 Key 都沒有變化;同樣的道理,如果我們把 Node 3 從集群中移除,那么只會影響到 Key 5 。因此,在增加和刪除節點時,只有少量的 Key 會跑到其它節點上,而大部分的 Key 命中的節點還是會保持不變,從而可以保證命中率不會大幅下降。
生產開發建議
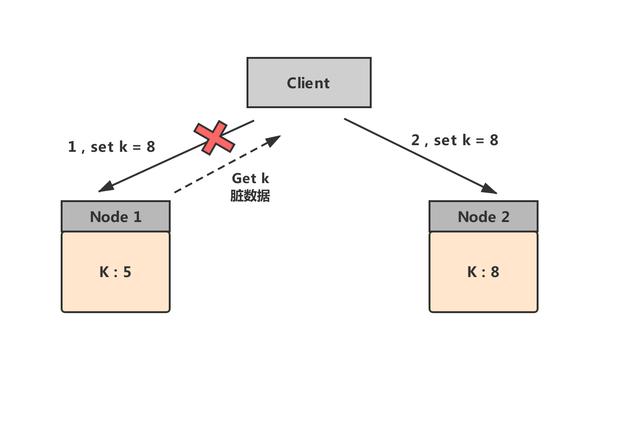
我們在使用一致性哈希算法的時候,一定要設置緩存的過期時間,為什么這么說的呢?現在假設集群里面有兩個節點分別為node1和node2,node1里面存放的(k,5),然后一客戶端請求過來需要將5變成8,這個時候node1節點服務和客戶端因網絡問題斷開連接了,那么這次的寫入操作就會被路由到node2上了,等到node1網絡好了恢復連接的話,客戶端讀取到node1 中k就為5,而其實這個k已經是8了,就造成了臟數據,所以我們需要設置過期時間。
Memcached 如何做主從機制
memcached不像redis本身支持主從復制機制,那我們該怎么保證memcached的高可用呢?其實和我們前面的數據庫方案差不多的。
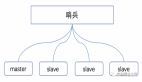
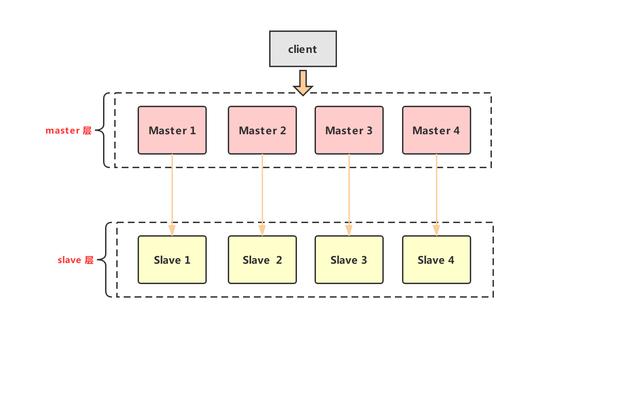
- 我們為每一組memcached的Master配置一組Slave。
- 數據更新的時候,我們就主從同步更新。
- 數據讀取的時候,先從Slave中讀取,讀不到就穿透到Master中,再將數據寫回到Slave中。
其主從復制優點就是當某一個 Slave 宕機時,還會有 Master 作為兜底,不會有大量請求穿透到數據庫的情況發生,提升了緩存系統的高可用性。
中間代理層方案
上面的應用端方案基本能解決我們絕大部分問題了,現在主要是像有些公司技術語言比較多的話,這種就得每種語言都得開發一套,比如我們公司有Java PHP 還有.
net之類的,那么這個時候就需要中間代理層來最好不過了,不需要業務方進行考慮這些復雜情況,直接連接代理層就行了
代理層自己管理緩存節點高可用,通過某種協議,如redis協議,來和各種語言業務端連接。業界也有很多中間代理層方案,比如 Facebook 的Mcrouter,Twitter 的Twemproxy,豌豆莢的Codis。基本架構如下:
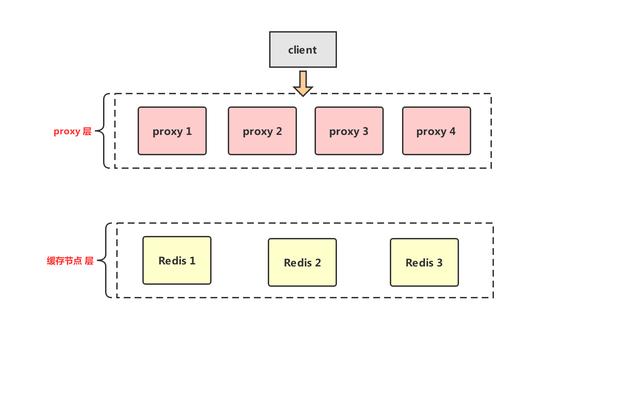
如上圖所示,中間層代理方案即所有緩存讀寫的操作都直接通過代理層完成,代理層自己完成上面應用端所有的操作。
服務端方案
服務端方案主要是緩存服務自己管理的,對于我們開發人員不用自己寫代碼管理也不用引入中間層,就是需要相關運維配置支持,比如redis的sentinel模式就是用來解決redis部署時高可用問題,它可以在主節點掛了以后自動將從節點提升為主節點,保證整體集群的可用。所以服務端對于我們開發影響不是太大,redis的sentinel我們還得需要知道的,后面會專門進行講解。
總結,今天我們講到了在使用緩存的時候為了避免單節點所帶來的各種問題,所以我們需要搭建高可用緩存架構,共講到了三種方案,應用端、中間代理層以及服務端方案,大家可以根據公司的資源情況來選擇合適的方案。