換種監(jiān)控姿勢(shì):基于深度學(xué)習(xí)+流處理的時(shí)序告警系統(tǒng)
背景
告警系統(tǒng)是運(yùn)維人員的“眼”,是維護(hù)生產(chǎn)安全的第一層保障。傳統(tǒng)基于規(guī)則的告警系統(tǒng)是通過(guò)同比、環(huán)比、差分、設(shè)置閥值等手段來(lái)判斷當(dāng)前指標(biāo)是否存在異常,但往往不盡人意,存在維護(hù)成本高、準(zhǔn)確率低等問(wèn)題。隨著人工智能的興起,大數(shù)據(jù)運(yùn)維也迎來(lái)了新的契機(jī),同時(shí)也對(duì)自身告警系統(tǒng)的實(shí)時(shí)性提出了更高的需求。
于是我們結(jié)合Tensorflow深度學(xué)習(xí)算法,基于大數(shù)據(jù)平臺(tái)天然原生的分布式流處理框架Spark,打造了一套高覆蓋性與強(qiáng)實(shí)時(shí)性的告警系統(tǒng),有效的減少了人工規(guī)則的參與,并降低了維護(hù)成本。
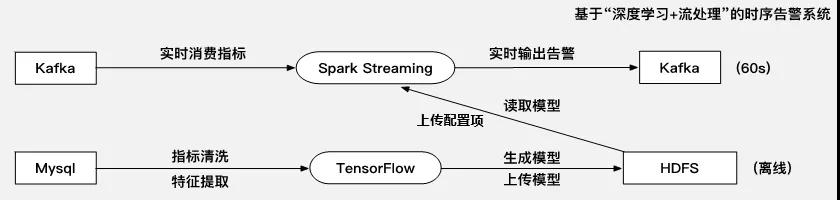
本文主要從“基于深度學(xué)習(xí)的時(shí)序預(yù)測(cè)算法”和“算法結(jié)合Spark流處理的實(shí)時(shí)告警”兩個(gè)方面對(duì)本套告警系統(tǒng)進(jìn)行介紹。框架圖如下圖所示:
一、基于深度學(xué)習(xí)的時(shí)序預(yù)測(cè)算法
使用算法監(jiān)控時(shí)序數(shù)據(jù)的常規(guī)思路,是通過(guò)本時(shí)刻實(shí)時(shí)值與用前幾個(gè)時(shí)間點(diǎn)的時(shí)序數(shù)據(jù)對(duì)本時(shí)刻的預(yù)測(cè)值進(jìn)行比較。因此,告警的第一步是做好時(shí)序預(yù)測(cè)工作,即時(shí)序分析。
引用一段百度文庫(kù)對(duì)時(shí)序分析原理的介紹:“承認(rèn)事物發(fā)展的延續(xù)性, 事物的現(xiàn)實(shí)是歷史發(fā)展的結(jié)果,而事物的未來(lái)又是現(xiàn)實(shí)的延伸,事物的過(guò)去和未來(lái)是有聯(lián)系的。時(shí)間序列分析預(yù)測(cè)法的哲學(xué)依據(jù),是唯物辯證法中的基本觀點(diǎn),即認(rèn)為一切事物都是發(fā)展變化的,事物的發(fā)展變化在時(shí)間上具有連續(xù)性。”
時(shí)序分析的過(guò)程分為以下三個(gè)操作步驟:
- 第一步:數(shù)據(jù)預(yù)處理;
- 第二步:核心指標(biāo)分類;
- 第三步:選擇算法訓(xùn)練模型。
下面對(duì)以上步驟展開敘述。
1、數(shù)據(jù)預(yù)處理
利用好數(shù)據(jù)的前提是數(shù)據(jù)是好用的,因此所有的數(shù)據(jù)分析工作第一步一定要先經(jīng)過(guò)數(shù)據(jù)預(yù)處理,主要包括數(shù)據(jù)清洗和特征提取。
時(shí)序預(yù)測(cè)基于歷史數(shù)據(jù)預(yù)測(cè)未來(lái),歷史數(shù)據(jù)中的“空值”、“異常值”將會(huì)極大的影響到預(yù)測(cè)的質(zhì)量,因此在訓(xùn)練預(yù)測(cè)模型前需要對(duì)訓(xùn)練集時(shí)序數(shù)據(jù)進(jìn)行清洗。可以先對(duì)數(shù)據(jù)繪圖直觀的看一下是否有周期性,然后對(duì)于空值采取補(bǔ)齊的方式,具體補(bǔ)齊方式可以根據(jù)原序列有明顯周期性則可以用歷史多個(gè)周期在這一個(gè)時(shí)間點(diǎn)的平均值,無(wú)明顯周期性則可以用前后兩點(diǎn)的均值代替,對(duì)于異常值同理。
時(shí)序分析的特征提取,業(yè)界多采用滑動(dòng)窗口時(shí)序特性分析的方法,也即多個(gè)時(shí)間窗口之間數(shù)據(jù)做統(tǒng)計(jì)上的均值、方差、協(xié)方差等對(duì)比,分解出時(shí)間序列的成分。時(shí)間序列的成分則分為3種:
- 長(zhǎng)期趨勢(shì)(T):一段時(shí)間后序列總體呈現(xiàn)的上升或下降的趨勢(shì);
- 季節(jié)性(S):周期性固定的變化;
- 余項(xiàng)(I):時(shí)間序列除去趨勢(shì)、季節(jié)性后的偶然性波動(dòng),稱為隨機(jī)性(random),也稱不規(guī)則波動(dòng),是常態(tài)。
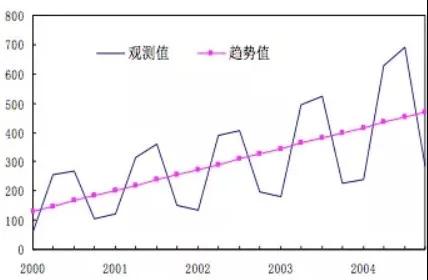
長(zhǎng)期趨勢(shì)(T)
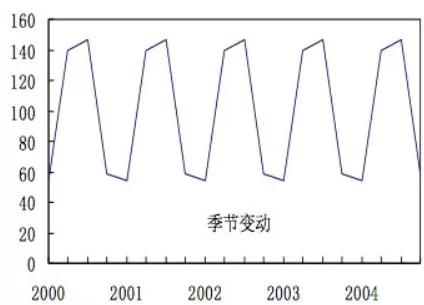
季節(jié)波動(dòng)(S)
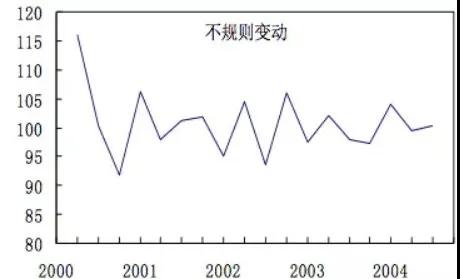
余項(xiàng)(I)
不同于分類場(chǎng)景中將提取的特征用于模型訓(xùn)練,這里特征提取的季節(jié)波動(dòng)和余項(xiàng)都將服務(wù)于下一步的指標(biāo)分類。
2、核心指標(biāo)分類
對(duì)核心指標(biāo)的時(shí)序預(yù)測(cè),則需要事先分解時(shí)序數(shù)據(jù)的成分并進(jìn)行預(yù)分類。參照業(yè)界時(shí)序預(yù)測(cè)指標(biāo)分類的方式,用是否具有周期性和是否穩(wěn)定兩個(gè)標(biāo)準(zhǔn)可分為以下四類,以集群環(huán)境真實(shí)指標(biāo)圖解說(shuō)明:
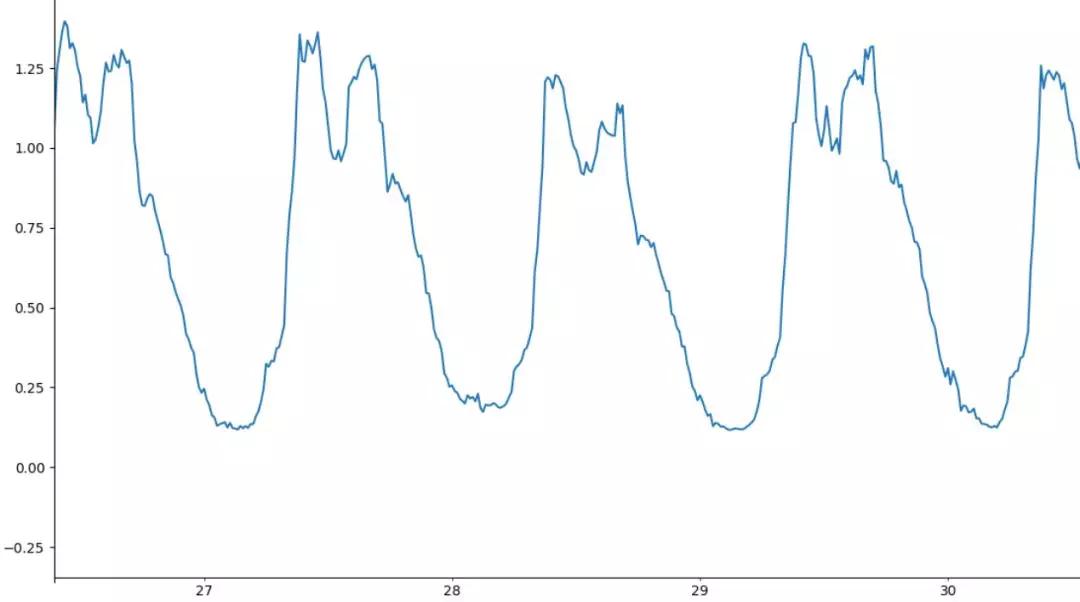
(1)周期性穩(wěn)定
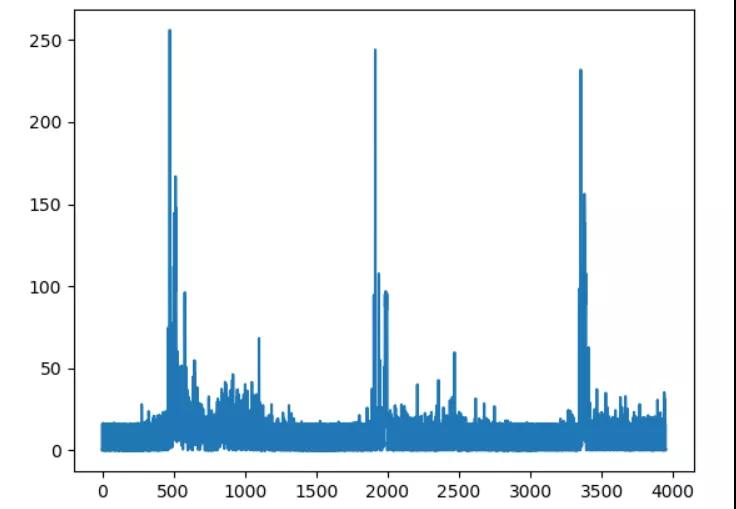
(2)周期性非穩(wěn)定
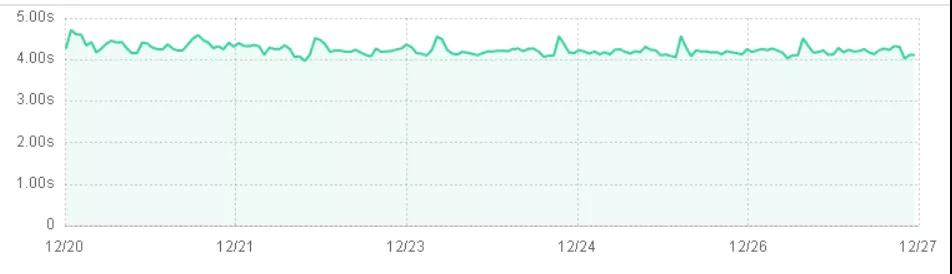
(3)非周期性穩(wěn)定
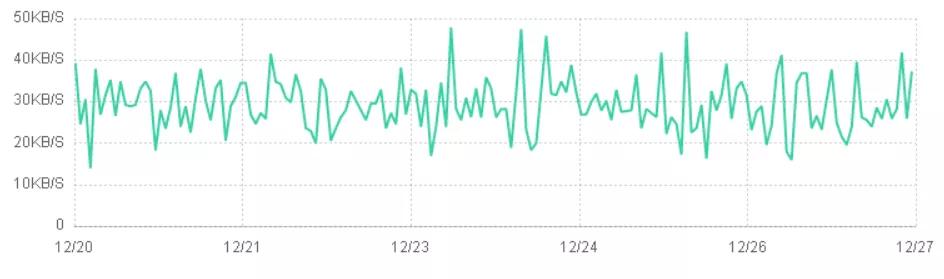
(4)非周期性非穩(wěn)定
從算法角度上,我們提出了一種基于時(shí)序分解,對(duì)周期分量進(jìn)行觀察并對(duì)余項(xiàng)進(jìn)行方差分析的指標(biāo)類型判定方式:
Step 1:時(shí)序分解算法將時(shí)序數(shù)據(jù)分解出“趨勢(shì)分量”、“周期分量”和“余項(xiàng)”
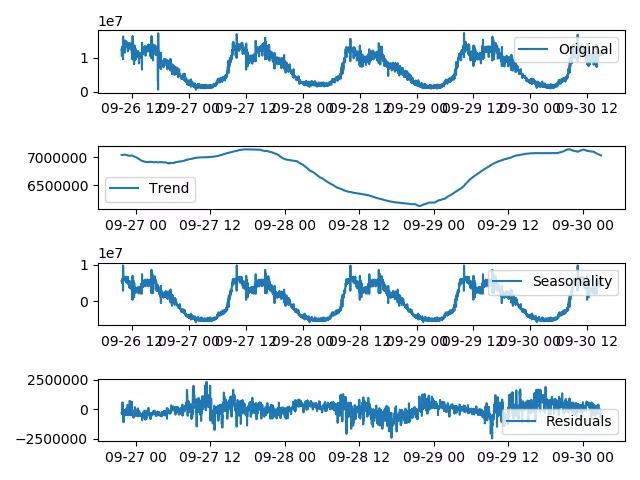
通過(guò)觀察周期分量,上述第三張圖(Seasonality)具有明顯規(guī)律性波動(dòng)才被認(rèn)為具有周期性。
Step 2:對(duì)時(shí)序分解法分解出的“余項(xiàng)”做方差分析

首先對(duì)“余項(xiàng)”進(jìn)行預(yù)處理,采用“歸一化”的處理方式將“余項(xiàng)”歸一化到[0,1]區(qū)間。再計(jì)算出“歸一化余項(xiàng)”的方差,只有方差在一定閾值以內(nèi)才被認(rèn)定為穩(wěn)定。具體閾值的大小沒有一個(gè)統(tǒng)一標(biāo)準(zhǔn),在對(duì)多達(dá)近百個(gè)指標(biāo)進(jìn)行如上分析,最終閾值取了0.2。
至此,完成黃金指標(biāo)的類型分類。對(duì)于非周期性指標(biāo)的監(jiān)控,業(yè)界內(nèi)暫時(shí)也沒有一個(gè)好的方案,主要還是采用同比環(huán)比、差分、設(shè)置閥值等經(jīng)典規(guī)則方法。同一種方法,不可能解決所有類型指標(biāo)的監(jiān)控,使用新算法并不意味著完全摒棄一些舊方式,這里不做進(jìn)一步探討。對(duì)于周期性非平穩(wěn)序列,則可以通過(guò)粗粒度時(shí)窗,比如原本1分鐘一個(gè)的點(diǎn),現(xiàn)統(tǒng)計(jì)每5分鐘的值進(jìn)行求和或者求均,都可以處理成周期平穩(wěn)序列。因此,本文主要針對(duì)通過(guò)以上方式分類和處理得到的周期性平穩(wěn)數(shù)據(jù)。
3、基于LSTM算法的時(shí)序預(yù)測(cè)
時(shí)序預(yù)測(cè)的算法整體上有兩大類:基于統(tǒng)計(jì)學(xué)的傳統(tǒng)機(jī)器學(xué)習(xí)算法(注:簡(jiǎn)稱機(jī)器學(xué)習(xí)算法,下同);基于神經(jīng)網(wǎng)絡(luò)的深度學(xué)習(xí)算法。常用的機(jī)器學(xué)習(xí)算法,如指數(shù)平滑法(holt-winters)、移動(dòng)平均自回歸模型(ARIMA)以及添加了周期性成分的季節(jié)性移動(dòng)平均自回歸模型(SARIMAX);常用的深度學(xué)習(xí)算法,如深度神經(jīng)網(wǎng)絡(luò)(DNN)、循環(huán)神經(jīng)網(wǎng)絡(luò)(RNN)以及解決了RNN存在長(zhǎng)期依賴問(wèn)題的長(zhǎng)短時(shí)記憶網(wǎng)絡(luò)(LSTM)。
考慮到平臺(tái)部署、穩(wěn)定性等實(shí)用性因素,并對(duì)統(tǒng)計(jì)學(xué)模型兩種算法ARIMA、SARIMAX跟深度學(xué)習(xí)模型LSTM算法的實(shí)時(shí)性進(jìn)行對(duì)比,在真實(shí)環(huán)境下,進(jìn)行多次對(duì)比取均值,得出以下結(jié)論:

可以看到,LSTM模型不僅在訓(xùn)練跟預(yù)測(cè)上所花費(fèi)的時(shí)間均遠(yuǎn)低于其他兩個(gè)模型,其他兩個(gè)模型的實(shí)時(shí)性無(wú)法滿足需求;同時(shí)在資源消耗以及丟失值敏感問(wèn)題上也要優(yōu)于其他。因此,最終選擇的是深度學(xué)習(xí)算法——LSTM。
1)LSTM簡(jiǎn)介
近幾年,隨著計(jì)算能力的迅猛提升,上個(gè)世紀(jì)末研究到一半的深度學(xué)習(xí)(Deep Learning,簡(jiǎn)稱DL)在今天重新“翻熱”,并在各個(gè)領(lǐng)域大放異彩。深度學(xué)習(xí)模仿大腦的神經(jīng)元之間傳遞,處理信息的模式,對(duì)其算法思想的理解需要有一定機(jī)器學(xué)習(xí)的基礎(chǔ),下面只做簡(jiǎn)要介紹。
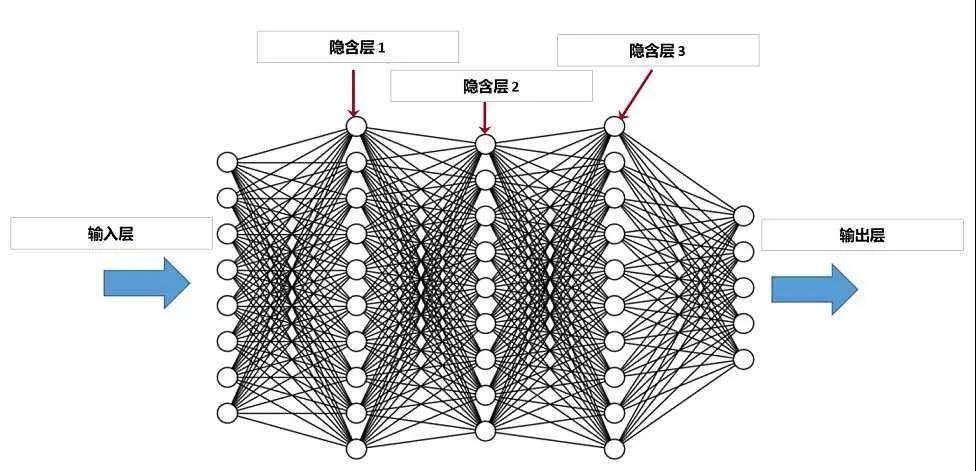
深度學(xué)習(xí)隸屬于機(jī)器學(xué)習(xí),與基于人工規(guī)則定義特征的傳統(tǒng)機(jī)器學(xué)習(xí)相比,DL明確了特征學(xué)習(xí)的重要性。簡(jiǎn)單的深度學(xué)習(xí)算法有深度神經(jīng)網(wǎng)絡(luò)DNN,它通過(guò)逐層特征變換,將樣本在原空間的特征表示變換到一個(gè)新特征空間,通過(guò)組合低層特征形成更加抽象的高層表示屬性類別或特征。
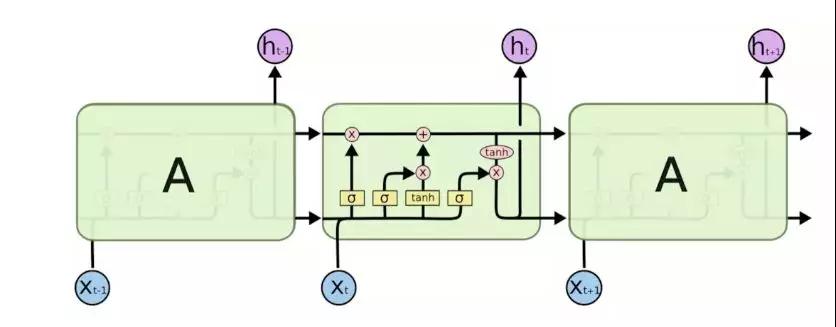
隨著深度學(xué)習(xí)的進(jìn)一步研究,除了DNN以外還有較多應(yīng)用于圖像識(shí)別的卷積神經(jīng)網(wǎng)絡(luò)CNN以及自然語(yǔ)言處理NLP常用到的循環(huán)神經(jīng)網(wǎng)絡(luò)RNN等等。RNN又因?yàn)槠漭斎胧峭皇挛锏亩鄠€(gè)時(shí)間點(diǎn)的數(shù)據(jù),通過(guò)不停的將信息循環(huán)操作,保證信息持續(xù)存在,從而可以利用前面的事件信息的特性被應(yīng)用于時(shí)序分析。本文中的LSTM是一種特殊的循環(huán)神經(jīng)網(wǎng)絡(luò)RNN,它既有RNN保存歷史信息的功能,還解決了普通RNN存在的梯度消失跟梯度爆炸問(wèn)題。LSTM也有很多變種,這里只給出樸素LSTM的網(wǎng)絡(luò)結(jié)構(gòu)圖。
2)LSTM模型訓(xùn)練操作過(guò)程
LSTM 算法的時(shí)序預(yù)測(cè)方式是先基于指標(biāo)的歷史數(shù)據(jù)訓(xùn)練出模型,再根據(jù)當(dāng)前數(shù)據(jù)預(yù)測(cè)指標(biāo)未來(lái)。以下具體的操作使用的是Tensorflow框架,Tensorflow是Tensor(張量:可類比多維數(shù)組)以數(shù)據(jù)流圖的形式進(jìn)行數(shù)值計(jì)算。
Step 1:已經(jīng)預(yù)處理過(guò)的數(shù)據(jù)轉(zhuǎn)換為Tensorflow可接受的張量形式
- A:數(shù)據(jù)歸一化(方便模型訓(xùn)練快速收斂);
- B:訓(xùn)練數(shù)據(jù)轉(zhuǎn)換格式(X:x(1),……,x(n);Y:x(n+1));
- C:Reshape成指定形狀的張量。
以上過(guò)程舉例說(shuō)明,假設(shè)有時(shí)序數(shù)據(jù)(1,2,3,4,5,6,7,8,9),設(shè)n為3。那么對(duì)這個(gè)序列進(jìn)行處理得到(1,2,3;4),(2,3,4;5),……,(7,8,9;10)共7個(gè)訓(xùn)練樣本。然后再轉(zhuǎn)換為張量格式類似下圖所示:
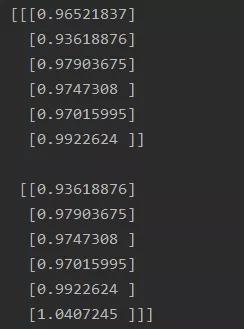
兩個(gè)6維三階張量X
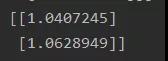
兩個(gè)1維二階張量Y
Step2:定義網(wǎng)絡(luò)結(jié)構(gòu)
- A:選擇網(wǎng)絡(luò):這里使用的是LSTM網(wǎng)絡(luò);
- B:設(shè)置參數(shù):輸入層(層數(shù),隱層神經(jīng)元個(gè)數(shù))、輸出層、timestep;
- C:初始化各個(gè)神經(jīng)元之間的連接(權(quán)重)跟偏置。
Step3:網(wǎng)絡(luò)訓(xùn)練
- A:設(shè)置優(yōu)化器、損失函數(shù)、學(xué)習(xí)率、激活函數(shù)…;
- B:設(shè)置訓(xùn)練方式(epoch,batch_size)。
Step4:生產(chǎn)預(yù)測(cè)
- A:保存模型;
- B:復(fù)用模型進(jìn)行預(yù)測(cè),注意需要反歸一化。
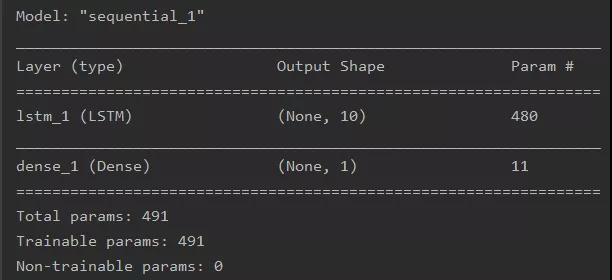
經(jīng)過(guò)以上過(guò)程,即完成了LSTM模型的訓(xùn)練,此時(shí)得到的網(wǎng)絡(luò)結(jié)構(gòu)格式如下(這里以一個(gè)簡(jiǎn)單的單隱藏層的LSTM網(wǎng)絡(luò)進(jìn)行圖解,非集群使用真實(shí)模型):
二、算法結(jié)合Spark流處理的實(shí)時(shí)告警
上一章節(jié)中,通過(guò)深度學(xué)習(xí)算法有效的對(duì)指標(biāo)進(jìn)行預(yù)測(cè),本章節(jié)則將其通過(guò)與Spark流處理框架的結(jié)合應(yīng)用到告警系統(tǒng)的生產(chǎn)部署中。限于Spark已有的機(jī)器學(xué)習(xí)庫(kù)MLlib里沒有深度學(xué)習(xí)算法,以及大數(shù)據(jù)組件跟深度學(xué)習(xí)算法之間的語(yǔ)言兼容問(wèn)題。因此嘗試在Spark中調(diào)用訓(xùn)練好的Tensorflow模型,即“Tensorflow離線訓(xùn)練,Spark實(shí)時(shí)預(yù)測(cè)“的AI生產(chǎn)部署模式。
具體分為以下幾步:模型上傳至HDFS;Yarn調(diào)度Spark Streaming加載PB模型;數(shù)據(jù)的實(shí)時(shí)消費(fèi)與告警。涉及到以下引擎層和Hadoop底層:

1、模型上傳至HDFS
把一章節(jié)中的深度學(xué)習(xí)算法模型輸出為可上傳至HDFS文件系統(tǒng)格式的文件并上傳至集群HDFS。首先對(duì)深度學(xué)習(xí)模型的保存方式做了簡(jiǎn)單對(duì)比分析:

通過(guò)以上對(duì)比分析,根據(jù)場(chǎng)景適用性、接口豐富性、開發(fā)語(yǔ)言兼容性等優(yōu)勢(shì),最終選用PB格式的保存方式。PB模型實(shí)質(zhì)是一個(gè)PB文件,是深度學(xué)習(xí)算法最終生成的一個(gè)二進(jìn)制文件,需要Tensorflow框架進(jìn)行讀取、編譯,最后在程序中形成一個(gè)預(yù)測(cè)模型。對(duì)其上傳則通過(guò)crontab定期執(zhí)行上傳即可,上傳周期可調(diào)。
2、Spark加載PB模型
首先將PB文件存儲(chǔ)在HDFS上,通過(guò)Spark Streaming程序可以直接讀取到HDFS上的PB文件,然后利用Tensorflow框架將所有讀取到的PB文件,還原成之前訓(xùn)練好的神經(jīng)網(wǎng)絡(luò)模型,用于深度學(xué)習(xí)的預(yù)測(cè)。因?yàn)樵谏a(chǎn)環(huán)境中,程序是On Yarn模式,以此來(lái)保證程序的高可用和高性能,所以所有的PB模型都是通過(guò)Spark程序的Driver組件統(tǒng)一生成,然后在向下分發(fā)至各個(gè)Executor,預(yù)測(cè)過(guò)程將在各個(gè)Job中執(zhí)行。
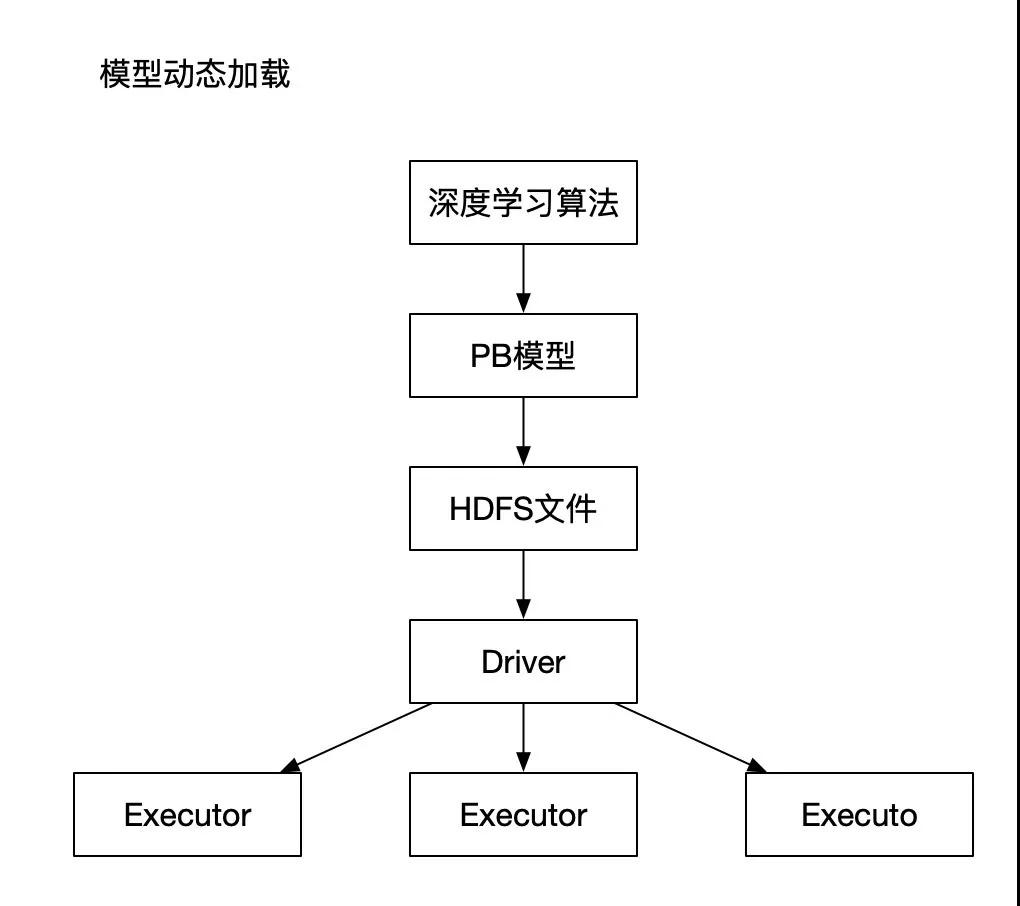
此外,因?yàn)檫x用的是Spark Streaming框架,所以支持動(dòng)態(tài)PB模型加載,即如果想更新PB模型,可以直接替換HDFS上的PB文件,程序即可識(shí)別新的PB文件,生成新的PB模型為后面的數(shù)據(jù)進(jìn)行預(yù)測(cè)。動(dòng)態(tài)更新PB模型遍于調(diào)整預(yù)測(cè)規(guī)則,根據(jù)指標(biāo)數(shù)據(jù)的實(shí)時(shí)變動(dòng),更加有效的更改調(diào)節(jié)算法策略,使得預(yù)測(cè)結(jié)果更加精準(zhǔn)。
整套程序上基于Spark Streaming框架開發(fā)的,所以在實(shí)時(shí)性能夠得以保證,在數(shù)據(jù)平臺(tái)搭建完善的基礎(chǔ)上,所有的實(shí)時(shí)數(shù)據(jù)指標(biāo)信息都會(huì)存放在Kafka消息隊(duì)列中。程序在實(shí)時(shí)消費(fèi)Kafka獲取當(dāng)前指標(biāo)數(shù)據(jù),每一次預(yù)測(cè)都會(huì)根據(jù)當(dāng)前的指標(biāo)數(shù)據(jù)計(jì)算,得到的預(yù)測(cè)結(jié)果會(huì)更加貼合真實(shí)值。

上圖為Spark Streaming基本內(nèi)部原理,SparkStreaming從實(shí)時(shí)數(shù)據(jù)流接入數(shù)據(jù),再將其劃分為一個(gè)個(gè)小批量供后續(xù)Spark engine處理,所以實(shí)際上,Spark是按一個(gè)個(gè)小批量來(lái)處理數(shù)據(jù)流的。這正是符合我們的實(shí)際應(yīng)用場(chǎng)景,數(shù)據(jù)實(shí)時(shí)接收,一批批處理,再結(jié)合深度學(xué)習(xí)算法,實(shí)現(xiàn)了智能AI實(shí)時(shí)預(yù)測(cè)的功能。
3、數(shù)據(jù)的實(shí)時(shí)消費(fèi)與告警
為防止瞬時(shí)異常導(dǎo)致的模型失真問(wèn)題,因此需要有個(gè)替換邏輯來(lái)保證模型的穩(wěn)定。我們利用了外部應(yīng)用Redis,因Redis是內(nèi)存數(shù)據(jù)庫(kù),其速度快、多類型存儲(chǔ)以及其他豐富特性,能夠完全支持我們的存儲(chǔ)需求。
對(duì)每一個(gè)需要預(yù)測(cè)的指標(biāo)數(shù)據(jù)設(shè)計(jì)了三個(gè)不同的數(shù)據(jù)集,分別為forecast隊(duì)列、real隊(duì)列和pb隊(duì)列:
- forecast隊(duì)列即為預(yù)測(cè)值隊(duì)列,此隊(duì)列中存放的是根據(jù)深度學(xué)習(xí)算法生成的預(yù)測(cè)值;
- real隊(duì)列即為真實(shí)值隊(duì)列,此隊(duì)列中存放的是從Kafka消息隊(duì)列中消費(fèi)得來(lái)的真實(shí)數(shù)據(jù);
- pb隊(duì)列即為模型輸入隊(duì)列,此隊(duì)列是用來(lái)灌輸?shù)絇B模型中的數(shù)據(jù)隊(duì)列。
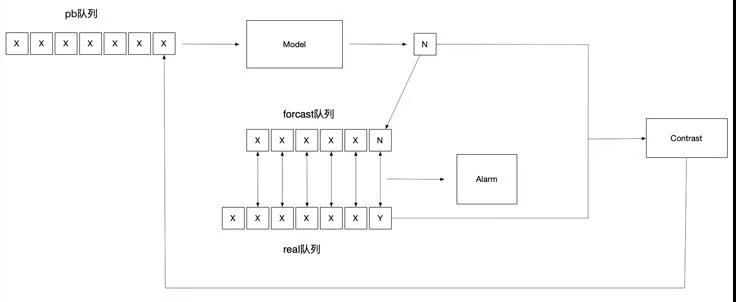
三個(gè)隊(duì)列互相協(xié)作,保證模型的穩(wěn)定。首先在程序第一次啟動(dòng)時(shí),需要先積累足夠多的原始數(shù)據(jù),填入到real隊(duì)列和pb隊(duì)列中,當(dāng)積累了t分鐘后,有了足夠多的數(shù)據(jù)可以預(yù)測(cè)時(shí),將pb隊(duì)列中的數(shù)據(jù)填入PB模型中,預(yù)測(cè)t+1分鐘的數(shù)據(jù),將t+1分鐘的預(yù)測(cè)值填入到forecast隊(duì)列中。
在t+1分鐘時(shí),拿到了t+1分鐘的真實(shí)值,用t+1分鐘的真實(shí)值與t分鐘預(yù)測(cè)出來(lái)的t+1分鐘的預(yù)測(cè)值根據(jù)特定的比對(duì)規(guī)則比對(duì),如果真實(shí)值與預(yù)測(cè)值符合比對(duì)要求,那么將t+1分鐘的真實(shí)值填入到pb隊(duì)列中,反之則用t+1分鐘的預(yù)測(cè)值填入到pb隊(duì)列中,并且保持pb模型要求的長(zhǎng)度,去掉pb隊(duì)列中時(shí)間最早的數(shù)據(jù),用替換更改過(guò)后的pb隊(duì)列填入到PB模型中,預(yù)測(cè)t+2分鐘的預(yù)測(cè)值。
當(dāng)以上步驟進(jìn)行了足夠多的時(shí)候,那么real隊(duì)列與forecast隊(duì)列都已經(jīng)積累的足夠多的數(shù)據(jù),并且時(shí)間都會(huì)互相匹配,即real隊(duì)列的數(shù)據(jù)為t分鐘至t+n分鐘的真實(shí)值,forecast隊(duì)列的數(shù)據(jù)為t+1分鐘至t+n+1分鐘的預(yù)測(cè)值,那么在t+n+1分鐘時(shí),拿到了t+n+1分鐘的真實(shí)數(shù)據(jù),即可按照每個(gè)時(shí)間的真實(shí)值和預(yù)測(cè)值互相對(duì)比,判斷此指標(biāo)數(shù)據(jù)是否出現(xiàn)異常,如果比對(duì)結(jié)果中的異常時(shí)間點(diǎn)超過(guò)既定個(gè)數(shù),那么此指標(biāo)則被判定有異常發(fā)生,立刻會(huì)發(fā)出告警,提醒運(yùn)維人員檢查修復(fù)。
對(duì)于每個(gè)隊(duì)列的長(zhǎng)度和應(yīng)用都做成可隨時(shí)更改的配置項(xiàng),里面有詳細(xì)的要求和規(guī)則來(lái)規(guī)定和約束每個(gè)不同的預(yù)測(cè)模型的數(shù)據(jù)隊(duì)列便于模型定制化調(diào)整,真正的實(shí)現(xiàn)了特定預(yù)測(cè),特殊預(yù)測(cè)和準(zhǔn)確預(yù)測(cè)。
三、總結(jié)
整個(gè)告警系統(tǒng)平臺(tái),采用深度學(xué)習(xí)算法提高了預(yù)測(cè)的準(zhǔn)確性,再結(jié)合Spark Streaming流處理框架保障了告警的實(shí)時(shí)性,減少了人為規(guī)則的參與,降低運(yùn)維人員維護(hù)的時(shí)間投入。
從2019年年底正式上線,現(xiàn)已穩(wěn)定支撐某運(yùn)營(yíng)商包括Kafka、HBase等多個(gè)大數(shù)據(jù)技術(shù)棧的核心指標(biāo)業(yè)務(wù)的實(shí)時(shí)監(jiān)控。從平臺(tái)正式運(yùn)行至今,總的查全率能達(dá)到98%以上;由于核心業(yè)務(wù)更注重查全率,因此查準(zhǔn)率稍低,查準(zhǔn)率大約維持在90%的水平;同時(shí)集群環(huán)境提供的容錯(cuò)性,以及Spark Streaming流處理提供的實(shí)時(shí)消費(fèi)能力極大的降低了告警的時(shí)間延遲,理論上可以達(dá)到與指標(biāo)采集頻率相差毫秒級(jí)的延遲。