













微信基于時(shí)間序的海量存儲擴(kuò)展性與多機(jī)容災(zāi)能力提升
背景介紹
業(yè)務(wù)場景
作為以手機(jī)為主要平臺的移動社交應(yīng)用,微信內(nèi)大部分業(yè)務(wù)生成的數(shù)據(jù)是有共性可言的:數(shù)據(jù)鍵值帶有時(shí)間戳信息,并且單用戶數(shù)據(jù)隨著時(shí)間在不斷的生成,我們將這類數(shù)據(jù)稱為基于時(shí)間序的數(shù)據(jù)。例如朋友圈的發(fā)表,支付賬單流水,公眾號文章閱讀記錄等。這類基于時(shí)間序的數(shù)據(jù)通常不會刪除,而是會隨著時(shí)間流逝不斷積累,相應(yīng)需要的存儲空間也與日俱增:key 量在萬億級別,數(shù)據(jù)量達(dá)到 PB 級別,每天新增 key 十億級別。同時(shí)在十億用戶的加持下,每天的訪問量也高達(dá)萬億級別。
訪問模型
經(jīng)過數(shù)據(jù)分析,我們發(fā)現(xiàn)基于時(shí)間序的存儲一般有如下三個(gè)特點(diǎn):
- 讀多寫少,這類基于時(shí)間序的存儲,如果需要訪問一段時(shí)間內(nèi)的數(shù)據(jù)就需要對對應(yīng)時(shí)間段內(nèi)的所有鍵值對都進(jìn)行一次訪問。與全部寫入到一個(gè)鍵值對的場景相比可以視為讀擴(kuò)散的場景。部分業(yè)務(wù)場景下的讀寫比甚至高達(dá) 100:1。
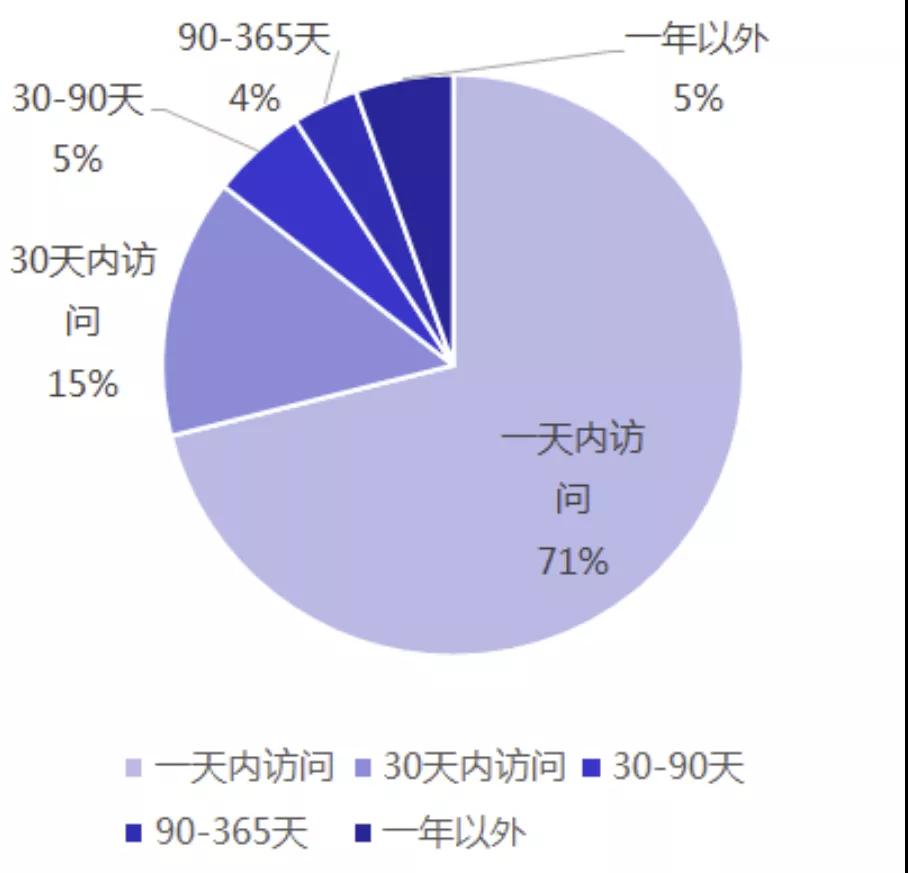
- 冷熱分明,這類基于時(shí)間序的存儲,數(shù)據(jù)的時(shí)效性往往也決定了訪問頻率。比如對用戶進(jìn)行公眾號文章的推薦,用戶近期的閱讀記錄會更加具有參考意義。這就導(dǎo)致數(shù)據(jù)的訪問不是均勻的,而會更集中在最近一段時(shí)間所產(chǎn)生的數(shù)據(jù)。以某業(yè)務(wù)場景為例,70%以上的訪問來自最近一天內(nèi)的新增數(shù)據(jù),90%來自 3 個(gè)月內(nèi)的新增數(shù)據(jù)。一年外的數(shù)據(jù)訪問占比只有 5%。
- 數(shù)據(jù)安全性要求高,這類數(shù)據(jù)通常是由用戶主動產(chǎn)生,一旦丟失,非常容易被用戶感知,導(dǎo)致投訴。
現(xiàn)有架構(gòu)
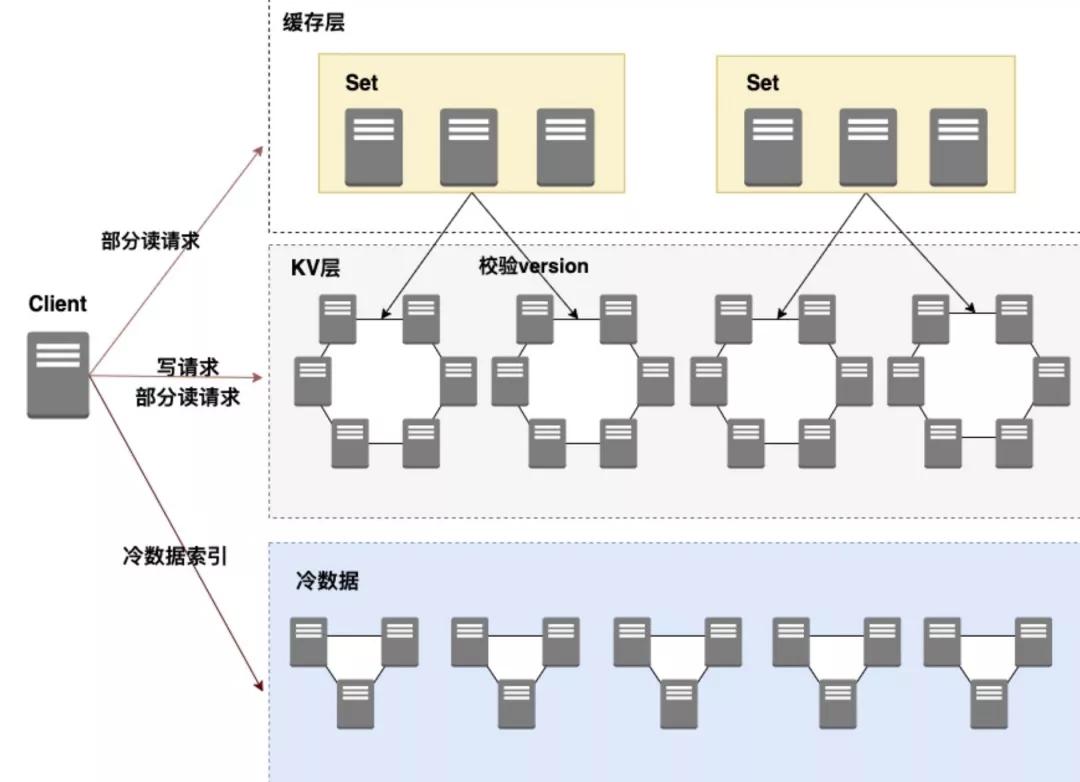
此前,我們使用一致性緩存層+SSD 熱數(shù)據(jù)層+機(jī)械盤冷數(shù)據(jù)層的分層架構(gòu)方案來解決此類基于時(shí)間序的存儲。細(xì)節(jié)可以參考《微信后臺基于時(shí)間序的海量數(shù)據(jù)冷熱分級架構(gòu)設(shè)計(jì)實(shí)踐》。
對于冷數(shù)據(jù)集群,我們使用微信自研的 WFS(Wechat File System 微信分布式文件系統(tǒng))對其進(jìn)行了一次升級,極大的簡化了運(yùn)維成本。不過這部分不是本文重點(diǎn),在此不再詳述。
面臨挑戰(zhàn)
舊架構(gòu)在過去幾年微信后臺的發(fā)展過程中始終表現(xiàn)平穩(wěn),但是也依然面臨著一些挑戰(zhàn)。
首先是擴(kuò)展能力方面的挑戰(zhàn)。舊架構(gòu)中,考慮到讀多寫少的訪問模型,為了加快宕機(jī)后的數(shù)據(jù) catchup 速度,我們使用了細(xì)粒度的 paxos group,即每個(gè) key 有一個(gè)獨(dú)立的 paxos group。這樣在進(jìn)程重啟等宕機(jī)場景下,只有少量寫入的 key 需要進(jìn)行 catchup。理想很豐滿,現(xiàn)實(shí)很骨感。在 PaxosStore 架構(gòu)中,數(shù)據(jù)的擴(kuò)縮容是以 paxos group 為粒度的。也就是說,對于使用細(xì)粒度 paxos group 的存儲,進(jìn)行擴(kuò)縮容是逐 key 的,耗時(shí)可以看成與 key 量成正比;單機(jī)百億級別的 key 量放大了這一問題,即使我們采取一系列的工程優(yōu)化縮短耗時(shí),整體的遷移周期依然比較長,需要幾周時(shí)間。
另外一個(gè)方面則是來自容災(zāi)能力的挑戰(zhàn)。PaxosStore 使用 KV64+三園區(qū)的部署方式。同一個(gè) key 的三個(gè)副本分屬三個(gè)園區(qū),同一個(gè)園區(qū)的兩臺機(jī)器服務(wù)分片沒有重疊,因此可以容忍園區(qū)級別的故障。然而對于同組兩臺不同園區(qū)機(jī)器故障的情況,則有占比 1/6 的數(shù)據(jù)只剩余單個(gè)副本,無法提供讀寫服務(wù)。
可能有同學(xué)會認(rèn)為,同組兩臺不同園區(qū)機(jī)器故障,概率無異于中彩票。然而根據(jù)墨菲定律,"凡是可能出錯(cuò)的事情,最終一定會出錯(cuò)"。在過去幾年也曾出現(xiàn)過同 Set 兩臺不同園區(qū)機(jī)器先后發(fā)生故障的情況。
我們都知道,分布式系統(tǒng)的一個(gè)核心觀點(diǎn)就是基于海量的,不可靠的硬件,構(gòu)造可靠的系統(tǒng)。那么硬件究竟有多不可靠呢?Jeff Dean 在 2009 年的一次 Talk 中曾經(jīng)提到過:

PaxosStore 使用 no raid 的磁盤陣列,磁盤故障導(dǎo)致單盤數(shù)據(jù)丟失時(shí)有發(fā)生。在機(jī)器故障檢修以及數(shù)據(jù)恢復(fù)的過程中,有大量數(shù)據(jù)(占單組 50%,逐漸收斂為 0)是以 2 副本形式存在,這就進(jìn)一步削弱了系統(tǒng)的容災(zāi)能力。
總結(jié)一下,我們面臨如下幾個(gè)挑戰(zhàn):
- 單機(jī)百億級別 key 量,10TB 級別數(shù)據(jù),如何快速擴(kuò)容?
- 如何低成本的提升系統(tǒng)的容災(zāi)能力,使之容忍任意雙機(jī)故障?
- 磁盤故障,數(shù)據(jù)清空后如何快速恢復(fù)。
- 作為一款十億月活的國民 APP,對其進(jìn)行改造無異于給一架正在飛行的飛機(jī)更換發(fā)動機(jī),改造過程稍有不慎都可能招致用戶投訴,甚至上個(gè)熱搜。
接下來我會針對這幾個(gè)難點(diǎn)逐一展開,介紹我們的解決思路與方案。
百億級別 key 如何實(shí)現(xiàn)快速擴(kuò)容
對于細(xì)粒度的的 paxos group,遷移過程中,掃 key,遷移,校驗(yàn)等步驟都是逐 key 粒度的。這會產(chǎn)生大量的磁盤 IO 與 CPU 消耗,導(dǎo)致遷移速度上不去,需要幾周才可以完成遷移。
那么我們能否可以采取粗粒度 paxos group 以加快遷移呢?答案是肯定的。對比細(xì)粒度的 paxos group,單個(gè)粗粒度的 paxos group 可以同時(shí)保證多個(gè) key 的內(nèi)容強(qiáng)一致。因此遷移校驗(yàn)等過程中,可以減少大量的 paxos 交互。然而粗粒度 paxos group 的存儲,與細(xì)粒度 paxos group 的存儲相比,在遷移過程中對目標(biāo)集群的寫入不會減少,總體依然涉及了大量數(shù)據(jù)的騰挪。而由于 LSMTree 存儲引擎存在的寫放大問題,數(shù)據(jù)大量寫入目標(biāo)機(jī)這一過程會成為瓶頸。總體來看,擴(kuò)容時(shí)間可以縮短為原來的 1/2 甚至 1/3,達(dá)到天級別的水平。
看起來相比細(xì)粒度 paxos group 的遷移已經(jīng)有很大改進(jìn),我們能否更進(jìn)一步?首先我們分析一下在什么場景下需要擴(kuò)容,一般來說是以下兩個(gè)場景:
1.由于數(shù)據(jù)增加,磁盤容量達(dá)到瓶頸
2.由于請求增加,CPU 處理能力達(dá)到瓶頸
對于情況 1,如果我們使用分布式文件系統(tǒng)替代本地文件系統(tǒng),當(dāng)容量達(dá)到瓶頸時(shí)只需要增加分布式文件系統(tǒng)的機(jī)器就可以實(shí)現(xiàn)容量的快速擴(kuò)容,對上層應(yīng)用而言相當(dāng)于獲得了一塊容量可以無限增長的磁盤。對于情況 2,采用計(jì)算存儲分離結(jié)構(gòu)后。計(jì)算節(jié)點(diǎn)無狀態(tài),不涉及數(shù)據(jù)騰挪,自然可以實(shí)現(xiàn)快速擴(kuò)容;如果是存儲層節(jié)點(diǎn) CPU 瓶頸,也可以通過文件塊級別的騰挪來實(shí)現(xiàn)快速擴(kuò)容以及熱點(diǎn)打散。
應(yīng)用計(jì)算存儲分離的思路,我們基于 WFS(微信分布式文件系統(tǒng))以及微信 Chubby(分布式鎖),實(shí)現(xiàn)了一套計(jì)算存儲分離的存儲架構(gòu),代號 Infinity,寓意無限的擴(kuò)展能力。
"All problems in computer science can be solved by another level of indirection"
在 Infinity 中,我們引入了一個(gè)被稱為 Container 的中間層。Container 可以近似理解為一個(gè)數(shù)據(jù)分片。每臺機(jī)器可以裝載一個(gè)或多個(gè) Container,我們稱之為 ContainerServer。ContainerServer 會處理其上 Container 對應(yīng)數(shù)據(jù)的讀寫請求,Master 負(fù)責(zé) Container 在 ContainerServer 間的調(diào)度,Chubby 則提供了分布式鎖服務(wù)以及 Container 位置信息在內(nèi)的元信息存儲。
當(dāng) master 發(fā)現(xiàn)有新加入的機(jī)器時(shí),會主動觸發(fā)負(fù)載均衡,將其他 ContainerServer 上的 Container 調(diào)度到新機(jī)。整個(gè)調(diào)度過程中,不涉及數(shù)據(jù)的騰挪。在我們實(shí)際的測試中,Container 騰挪的平均耗時(shí)在百毫秒級別。
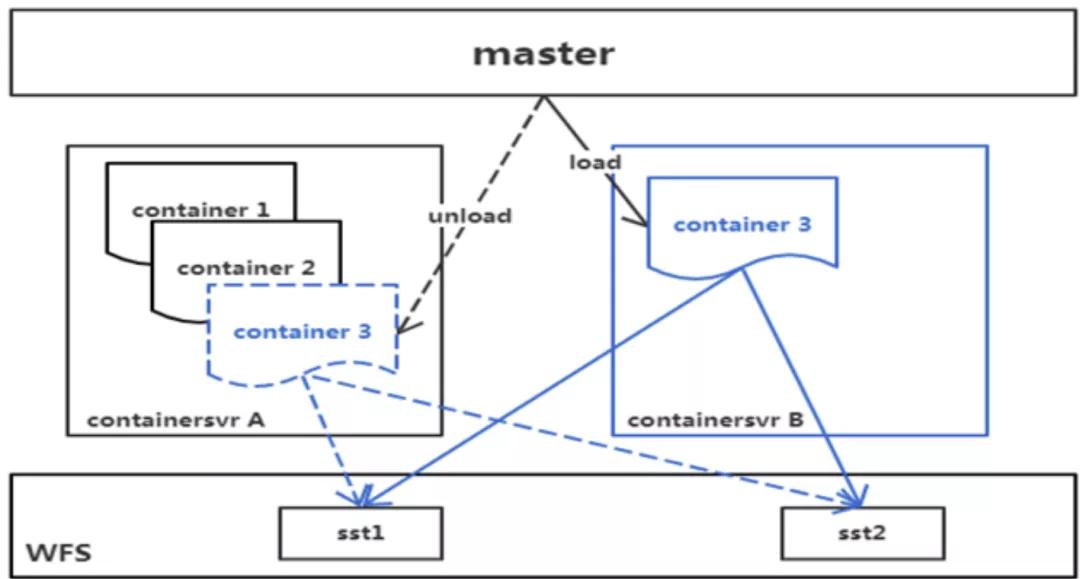
這是一個(gè)多園區(qū)部署的 Infinity 示意圖。每個(gè)園區(qū)內(nèi)都有獨(dú)立的 WFS 與 Chubby 存儲,每個(gè)園區(qū)都對應(yīng)全量的數(shù)據(jù)。對于同一個(gè)數(shù)據(jù)分片,分別位于 3 個(gè)園區(qū)的 3 個(gè) container 組成一個(gè) paxos group。
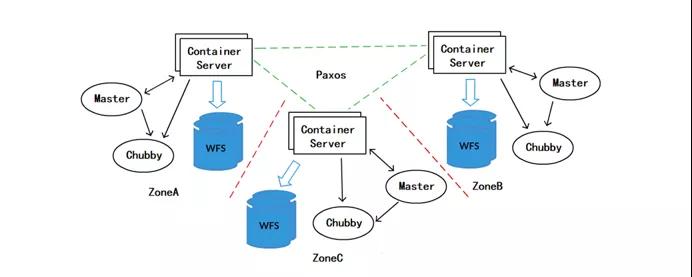
對于這樣一個(gè)方案,我們是可以對每個(gè)園區(qū)實(shí)現(xiàn)彈性伸縮的,系統(tǒng)整體的可用率由最上層的 paxos 提供保證。我們來計(jì)算下這一方案的存儲成本,園區(qū)內(nèi) 3 副本的 WFS 存儲 X 園區(qū)間的 3 副本 Replica,整體就是 9 副本。對于 PB 體量的存儲,這一方案所增加的存儲成本是我們難以承擔(dān)的。既然多 zone 部署的 Infinity 存在成本問題。我們自然想到,能否使用單 zone 部署的 Infinity 來負(fù)責(zé)存儲。
首先分析成本,單 zone 部署 Infinity 的存儲成本為 3 副本 WFS,與現(xiàn)有架構(gòu)的成本一致。其次分析擴(kuò)展能力,單 zone 部署的 Infinity 一樣具有出色的擴(kuò)展能力,優(yōu)于現(xiàn)有架構(gòu)。對于 Chubby 這一中心點(diǎn)依賴,我們可以實(shí)行 Set 化改造來盡量消除風(fēng)險(xiǎn)。
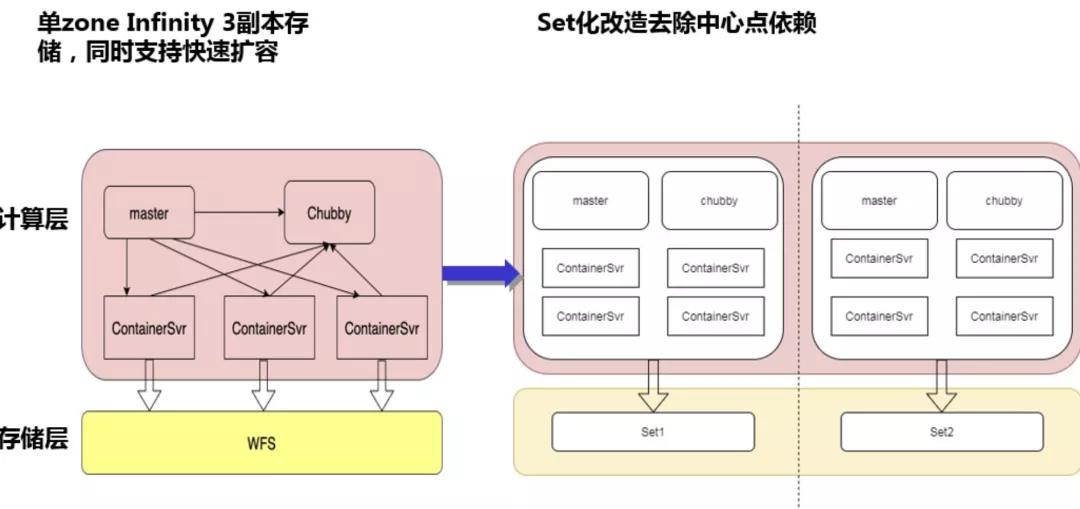
分 Set 改造后,我們不由得又想起那些年舊架構(gòu)經(jīng)常遇到的一種情況:單組請求突增。此處有必要簡單介紹一下 PaxosStore 的路由方案,組間一致性 Hash,單組內(nèi)是 KV64 結(jié)構(gòu)。一致性 Hash 消除訪問熱點(diǎn),一切看起來很美好。然而假設(shè)由于某些原因,大量請求集中訪問某組 KV 時(shí),如何應(yīng)急?
此時(shí)我們既無法快速增加該組內(nèi)的機(jī)器處理請求(KV64 限制),也無法快速分散請求到其他組(如果這組 KV 需要 3 倍容量,那就要把整個(gè)服務(wù)整體擴(kuò)容 3 倍才可以)。這就引發(fā)了一個(gè)尷尬的局面:一組 KV 水深火熱,其他組 KV 愛莫能助;只能反復(fù)調(diào)整前端請求的訪問比例,直到業(yè)務(wù)低峰期。
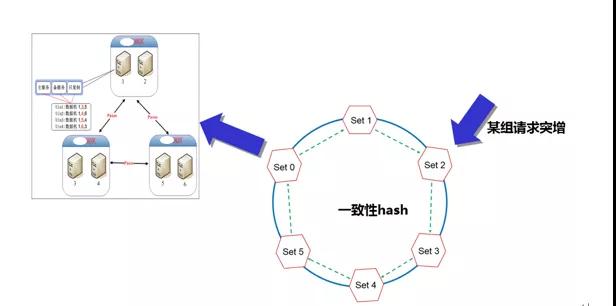
那么在 Infinity 中,我們?nèi)绾谓鉀Q這一問題呢?
首先,我們的 Set 化本質(zhì)上是對 Container 進(jìn)行分組,其中 Container 到組的映射關(guān)系是存儲于 Chubby 中的。如果我們想分散一組請求到其他組,只需要依次修改每一組 Chubby 中存儲的映射關(guān)系即可。在實(shí)際實(shí)現(xiàn)中還有一些工程細(xì)節(jié)需要考慮,比如對于要移入其他組的 Container,必須在原組進(jìn)行 Unload 并停止調(diào)度等。這里就不一一展開了。
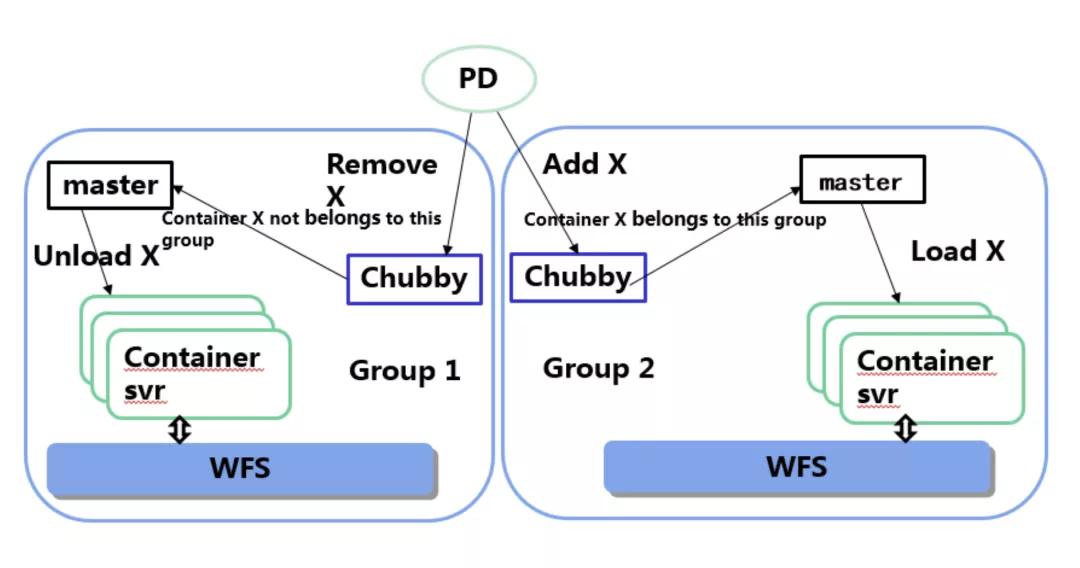
我們在線上也進(jìn)行了一次大規(guī)模騰挪 Container 到其他組的實(shí)驗(yàn):結(jié)果顯示,單個(gè) container 騰挪到其他組,平均耗時(shí)不足 1 秒。
單 zone Infinity 架構(gòu)的一些問題
單 zone Infinity 架構(gòu)解決了多 zone Infinity 成本問題的同時(shí),也必然做出了取舍。對于某個(gè) container,任一時(shí)刻必須只在最多一個(gè) containersvr 上服務(wù)。否則就有導(dǎo)致數(shù)據(jù)錯(cuò)亂的風(fēng)險(xiǎn)。類比多線程中的 data race。我們通過引入分布式鎖服務(wù)來避免 double assign。同時(shí)為了減少分布式鎖開銷,我們將鎖的粒度由 Container 級別收斂到 ContainerSvr 級別。每臺 ContainerSvr 開始提供服務(wù)后會定期前往 chubby 續(xù)租。如果一臺 ContainerSvr 崩潰,master 也需要等到鎖租約過期后才可以認(rèn)為這臺 ContainerSvr 掛掉,并將其上的 container 分配出去。
這就會導(dǎo)致存在一部分 container 在租約切換期間(秒級別)不能服務(wù)。
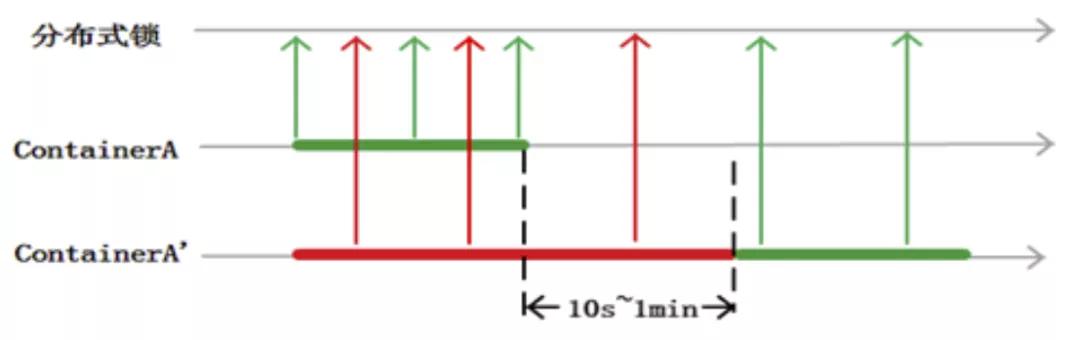
我們引入兩個(gè)可靠性工程的常見指標(biāo)來進(jìn)行說明。MTTR——全稱是 Mean Time To Repair,即平均修復(fù)時(shí)間。是指可修復(fù)系統(tǒng)的平均修復(fù)時(shí)間,就是從出現(xiàn)故障到修復(fù)中間的這段時(shí)間。MTTR 越短表示易恢復(fù)性越好。MTBF——全稱是 Mean Time Between Failure,是指可修復(fù)系統(tǒng)中相鄰兩次故障間的平均間隔。MTBF 越高說明越不容易出現(xiàn)故障。
可以說,單 zone Infinity 架構(gòu)縮短了 MTTR,但是也縮短了 MTBF,導(dǎo)致整體的可用性依然不高。
不可能三角?
在很多領(lǐng)域中,都有類似“不可能三角”的理論。比如分布式理論中經(jīng)典的 CAP 定理,經(jīng)濟(jì)學(xué)理論中的蒙代爾不可能三角等。在我們上面的討論中,其實(shí)也蘊(yùn)含了這樣的一個(gè)“不可能三角”:成本,擴(kuò)展性,可用性。
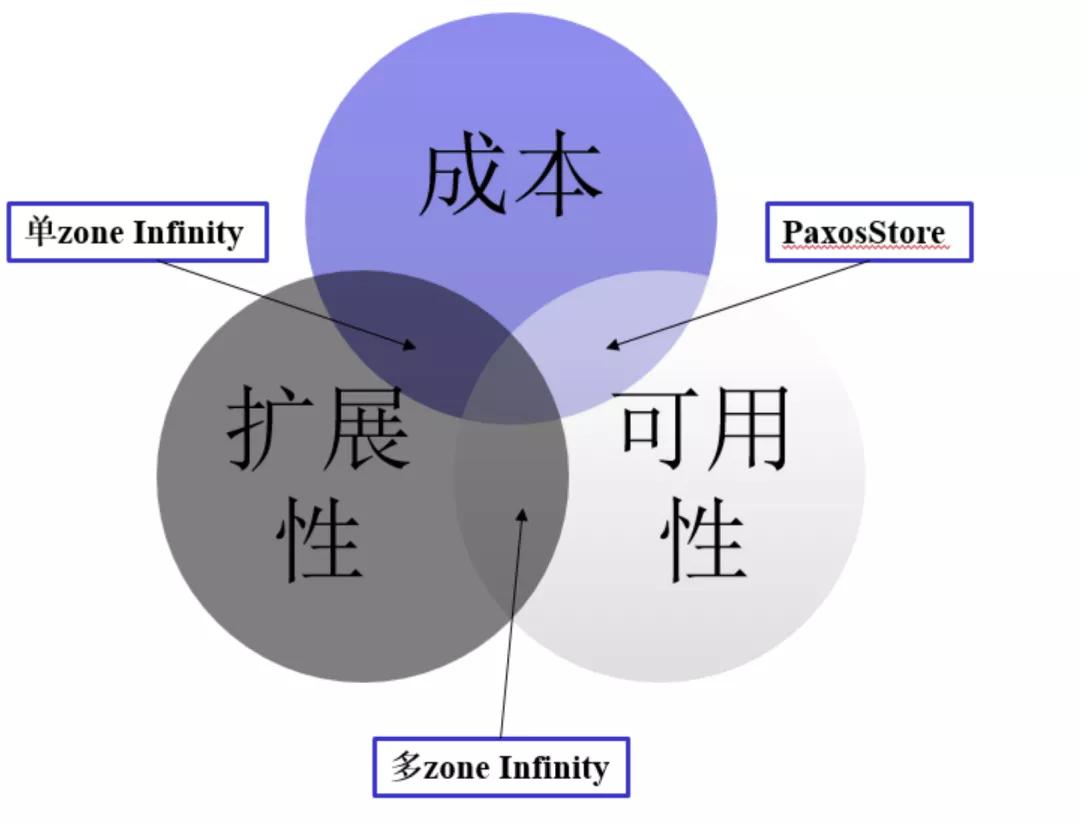
PaxosStore 兼顧了成本與可用性,但擴(kuò)展能力稍遜;多 zone Infinity 可用性與擴(kuò)展性都為上乘,但成本是個(gè)問題;單 zone Infinity 犧牲了一點(diǎn)可用性,換來了成本和擴(kuò)展性的優(yōu)勢;三者不可得兼,我們該如何取舍?
首先是成本,是我們必須考慮的因素,這關(guān)系到我們架構(gòu)實(shí)際落地還是成為巴貝奇的分析機(jī);其次是可用性,這關(guān)系到用戶的使用體驗(yàn)。在我們的新架構(gòu)中,可用性不僅不能下降,甚至還應(yīng)該有所提升。比如:容忍任意雙機(jī)故障。結(jié)合上面的討論,一個(gè)核心的目標(biāo)逐漸浮出水面:低成本雙機(jī)容災(zāi)改造。
低成本雙機(jī)容災(zāi)改造
我們首先來分析一下如何實(shí)現(xiàn)雙機(jī)容災(zāi)改造。一個(gè)簡單的思路是提升我們的副本數(shù),由 3 副本提升為 5 副本。5 副本自然可以容忍小于多數(shù)派(<=2)的機(jī)器故障,實(shí)現(xiàn)雙機(jī)容災(zāi)。然而考慮到成本問題,3 副本改造為 5 副本,成本增加 66%,這是我們無法接受的。此時(shí)我們想到了函數(shù)式編程中的常見思想:Immutable! 對于靜態(tài)不可變的數(shù)據(jù)而言,只要有 3 個(gè)副本,那么我們也可以在丟失 2 個(gè)副本的情況下,信任唯一的副本。然而對于一個(gè)存儲系統(tǒng)而言,我們沒辦法控制用戶不修改 Key 對應(yīng)的 Value 值,那么我們該如何實(shí)現(xiàn)靜態(tài)化 3 副本呢?
LSMTree Revisited
關(guān)于 LSMTree 這一存儲引擎的介紹,資料有很多。這里就不再詳述了。這里引用一張 LSMTree 的架構(gòu)圖:
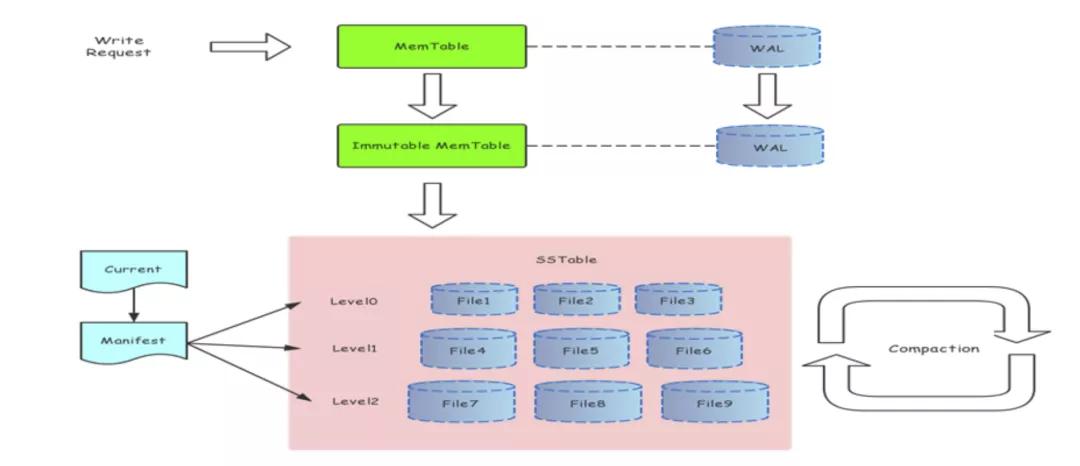
https://www.jianshu.com/p/6e49aa5182f0
我們分析一下圖中每個(gè)類型的文件:對于 SSTable 文件,寫入完成后即不可變,而且是 LSMTree 中主要的數(shù)據(jù)存儲(占比超過 99%),對于這一部分文件我們只需要存儲 3 副本即可;對于其他的文件如 WAL log,以及 Manifest,我們使用 5 副本存儲,總體的存儲成本增長可以忽略不計(jì)。這樣,我們就可以使用單 zone Infinity,在保持存儲成本不變的情況下,獲得雙機(jī)容災(zāi)的能力。
分而治之
單 zone Infinity 可以以 3 副本的存儲成本實(shí)現(xiàn)雙機(jī)容災(zāi),然而存在租約切換期間的不可用問題;5 副本 KV 實(shí)現(xiàn)了無租約的雙機(jī)容災(zāi),然后存儲成本相比原來增加了 2/3。兩種架構(gòu)各有不足,看似我們陷入了死局。然而回顧基于時(shí)間序數(shù)據(jù)的訪問模型,我們發(fā)現(xiàn)對于熱數(shù)據(jù)與溫?cái)?shù)據(jù),他們表現(xiàn)出了截然不同甚至相反的一些有趣性質(zhì)。
| 訪問模型 | 訪問量 | 數(shù)據(jù)量(單副本) |
|---|---|---|
| 熱數(shù)據(jù) | 千億級別 | 數(shù)十 TB |
| 溫?cái)?shù)據(jù) | 百億級別 | PB 級別 |
我們可以采取計(jì)算機(jī)科學(xué)中的重要思想——分治來解決。對于熱數(shù)據(jù),訪問量較大,我們希望他有最高的可用性,同時(shí)它的數(shù)據(jù)占比又不大,適于采用 5 副本 KV 的方案進(jìn)行雙機(jī)容災(zāi)改造。
對于溫?cái)?shù)據(jù),數(shù)據(jù)量較大,不能采取 5 副本方案改造,而使用單 zone Infinity 的方案,則可以完美解決成本問題。雖然會有偶爾短暫的不可用時(shí)長,但是由于整體的訪問占比不多,系統(tǒng)整體的可用率依然可以保持在很高的水準(zhǔn)。
對新架構(gòu)的成本分析:
| 方案 | 成本 | 雙機(jī)容災(zāi) |
|---|---|---|
| 熱數(shù)據(jù) 5 副本 KV | 數(shù)據(jù)占比約 5% 5 倍成本 | 支持 |
| 溫?cái)?shù)據(jù) Infinity | 數(shù)據(jù)占比約 95% 3 倍成本 | 支持 |
| 整體 | 3.1 倍 | 支持 |
這樣我們就在不顯著增加存儲成本,不犧牲可用性的前提下,實(shí)現(xiàn)了雙機(jī)容災(zāi)的目標(biāo)。
為了提升熱數(shù)據(jù)部分的擴(kuò)展性,我們可以使用粗粒度 paxos group 的交互方案。對于熱數(shù)據(jù),在數(shù)據(jù)量減少+粗粒度 paxos group 雙重改進(jìn)下,擴(kuò)容時(shí)間可以提升到小時(shí)級別。同時(shí),我們實(shí)現(xiàn)了熱數(shù)據(jù)由 5 副本 KV 到單 zone Infinity 的自動下沉。一方面可以保持總體的存儲成本不膨脹,另一方面也減少了熱數(shù)據(jù)的總量,熱數(shù)據(jù)集群的擴(kuò)容需求也就沒有那么強(qiáng)烈。
磁盤清空后的數(shù)據(jù)快速恢復(fù)
對于 Infinity 部分的數(shù)據(jù),可以依靠 WFS 自動檢測,補(bǔ)全副本數(shù)。在機(jī)器檢修期間就可以完成大部分?jǐn)?shù)據(jù)的補(bǔ)全。對于熱數(shù)據(jù)部分的數(shù)據(jù),雖然數(shù)據(jù)減少,但是恢復(fù)過程中還是會受限于 lsmtree 的寫入過程中 Compact 產(chǎn)生的寫放大問題。經(jīng)過一些業(yè)界的調(diào)研,對于 lsmtree 批量導(dǎo)入的場景,一種常見的做法是 BulkLoad,也即先將所有 key 進(jìn)行排序,生成有序的 SSTable 文件,直接提交到 lsmtree 的最后一層,這樣可以完全繞過寫放大實(shí)現(xiàn)數(shù)據(jù)的導(dǎo)入。
我們經(jīng)過分析,發(fā)現(xiàn)這種做法還不是最優(yōu)的。首先,我們對于 SSTable 中的數(shù)據(jù)會進(jìn)行 block 級別的壓縮,在遍歷數(shù)據(jù)的過程中需要進(jìn)行解壓;而在生成 SSTable 的過程中,為了減少存儲成本,又需要進(jìn)行壓縮。經(jīng)過研究,發(fā)現(xiàn)我們這種場景下有更優(yōu)的恢復(fù)方案:基于目錄級別的快速恢復(fù)。
目錄級別的快速恢復(fù)
要想實(shí)現(xiàn)目錄級別的快速恢復(fù),首要條件就是:需要數(shù)據(jù)的路由規(guī)則與目錄分布是完全對齊的。這樣才可以保證恢復(fù)目錄后,不會獲得不屬于本機(jī)的數(shù)據(jù),也不會遺漏數(shù)據(jù)。在此前的 kv 中都忽略了這一設(shè)計(jì),導(dǎo)致無法通過拷貝文件實(shí)現(xiàn)快速恢復(fù)。結(jié)合 5 副本的路由方案,我們獲得了一個(gè)可以實(shí)現(xiàn)對齊的目錄分布方案。推導(dǎo)后的方案非常簡潔,用一張圖片即可說明。
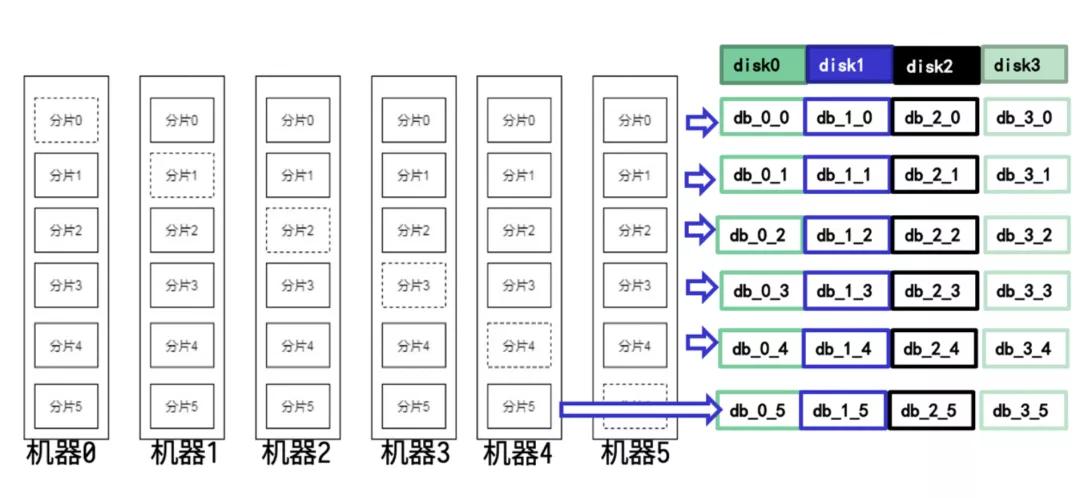
我們進(jìn)行的測試也印證了這一改造的效果,基于目錄拷貝的恢復(fù)方案相比原來逐 paxos group 恢復(fù)方案取得了近 50 倍的速度提升,從小時(shí)級進(jìn)入到分鐘級。
新架構(gòu)
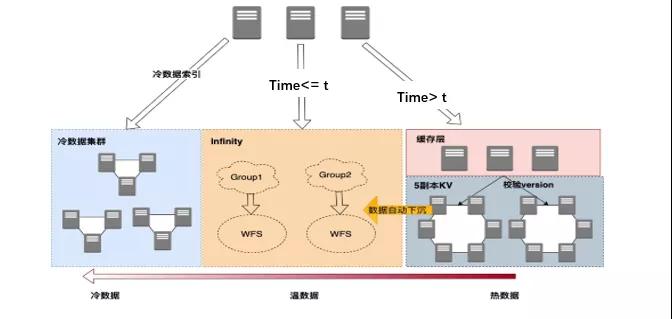
對幾個(gè)架構(gòu)方案的對比:
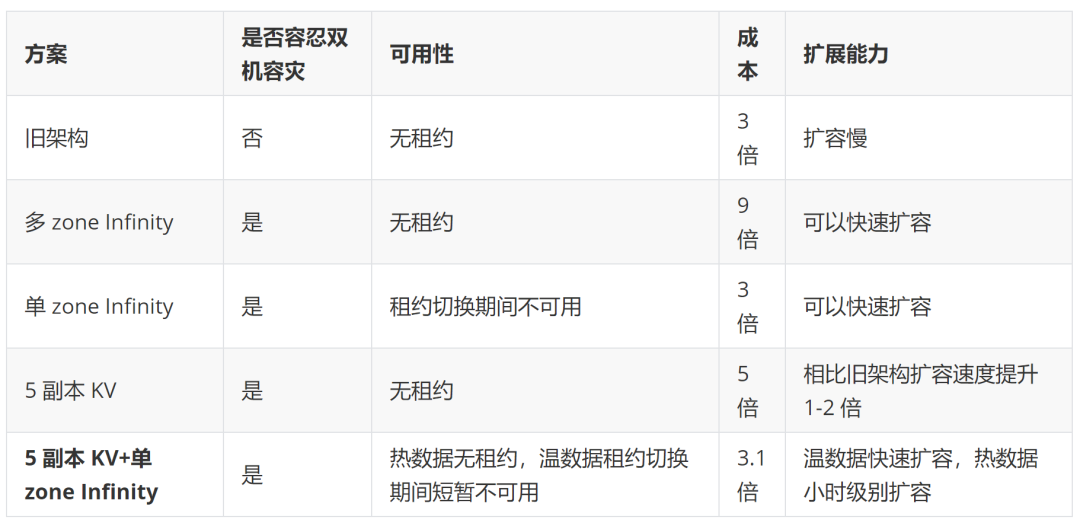
平穩(wěn)升級
至此我們的改造方案有了,然而改造過程同樣值得注意。我們必須在保證系統(tǒng)穩(wěn)定的前提下,平穩(wěn)的完成數(shù)據(jù)與訪問的切換。
首先是灰度能力,我們做了兩個(gè)粒度的灰度控制:一是訪問時(shí)間級別,按照 key 上面的時(shí)間,分批將數(shù)據(jù)從原架構(gòu)中騰挪出來;二是命令字級別,數(shù)據(jù)騰挪完成后,我們會先保持雙寫狀態(tài)觀察,先逐步切換讀請求到新架構(gòu)中,觀察正常后才會去掉雙寫,完成切換。其次是改造的正確性,我們采取了全量的數(shù)據(jù)校驗(yàn)方案,保證改造過程中不會丟失數(shù)據(jù)。最后是在騰挪過程中,我們開發(fā)了一套基于機(jī)器資源以及監(jiān)控上報(bào)的自動反饋機(jī)制,當(dāng)業(yè)務(wù)高峰期或者出現(xiàn)失敗時(shí)自動降速,低峰期自動加速,減少了人為介入。
目前,我們已經(jīng)完成部分核心存儲集群的架構(gòu)改造,實(shí)現(xiàn)了全程無故障切換。
總結(jié)
2019 年,微信后臺通過如上持續(xù)不斷的改造,在不增加成本的前提下,極大提升了基于時(shí)間序存儲的擴(kuò)展能力,從周級別的擴(kuò)容速度升級到整體小時(shí)級的擴(kuò)容速度,并且溫?cái)?shù)據(jù)部分的計(jì)算節(jié)點(diǎn)做到了分鐘級的擴(kuò)容速度。同時(shí),利用數(shù)據(jù)的特性進(jìn)行集群劃分,將 5 副本 PaxosStore 存儲與計(jì)算存儲分離架構(gòu)進(jìn)行有機(jī)結(jié)合,在極大提升了擴(kuò)展能力的同時(shí),將可用性提升到容忍雙機(jī)故障的水平。













