Redis熱點(diǎn)之底層實(shí)現(xiàn)篇
通過本文你將了解到以下內(nèi)容:
- Redis的作者、發(fā)展演進(jìn)和江湖地位
- Redis面試問題的概況
Redis底層實(shí)現(xiàn)相關(guān)的問題包括:
常用數(shù)據(jù)類型底層實(shí)現(xiàn)、SDS的原理和優(yōu)勢、字典的實(shí)現(xiàn)原理、跳表和有序集合的原理、Redis的線程模式和服務(wù)模型
溫馨提示:內(nèi)容并不難,就怕你不看。
看不懂可以先收藏先Mark,等到深入研究的時(shí)間再翻出來看看,你就發(fā)現(xiàn)真是24K干貨呀!停止吹噓,寫點(diǎn)不一樣的文字吧!
1.Redis往事
Redis是一個(gè)使用ANSI C編寫的開源、支持網(wǎng)絡(luò)、基于內(nèi)存、可選持久化的高性能鍵值對數(shù)據(jù)庫。Redis的之父是來自意大利的西西里島的Salvatore Sanfilippo,Github網(wǎng)名antirez,筆者找了作者的一些簡要信息并翻譯了一下,如圖:
從2009年第一個(gè)版本起Redis已經(jīng)走過了10個(gè)年頭,目前Redis仍然是最流行的key-value型內(nèi)存數(shù)據(jù)庫的之一。
優(yōu)秀的開源項(xiàng)目離不開大公司的支持,在2013年5月之前,其開發(fā)由VMware贊助,而2013年5月至2015年6月期間,其開發(fā)由畢威拓贊助,從2015年6月開始,Redis的開發(fā)由Redis Labs贊助。

筆者也使用過一些其他的NoSQL,有的支持的value類型非常單一,因此很多操作都必須在客戶端實(shí)現(xiàn),比如value是一個(gè)結(jié)構(gòu)化的數(shù)據(jù),需要修改其中某個(gè)字段就需要整體讀出來修改再整體寫入,顯得很笨重,但是Redis的value支持多種類型,實(shí)現(xiàn)了很多操作在服務(wù)端就可以完成了,這個(gè)對客戶端而言非常方便。
當(dāng)然Redis由于是內(nèi)存型的數(shù)據(jù)庫,數(shù)據(jù)量存儲(chǔ)量有限而且分布式集群成本也會(huì)非常高,因此有很多公司開發(fā)了基于SSD的類Redis系統(tǒng),比如360開發(fā)的SSDB、Pika等數(shù)據(jù)庫,但是筆者認(rèn)為從0到1的難度是大于從1到2的難度的,毋庸置疑Redis是NoSQL中濃墨重彩的一筆,值得我們?nèi)ド钊胙芯亢褪褂谩?/p>
2.Redis的江湖地位
Redis提供了Java、C/C++、C#、 PHP 、JavaScript、 Perl 、Object-C、Python、Ruby、Erlang、Golang等多種主流語言的客戶端,因此無論使用者是什么語言棧總會(huì)找到屬于自己的那款客戶端,受眾非常廣。
筆者查了http://datanyze.com網(wǎng)站看了下Redis和MySQL的最新市場份額和排名對比以及全球Top站點(diǎn)的部署量對比(網(wǎng)站數(shù)據(jù)更新到寫作當(dāng)日2019.12.11):
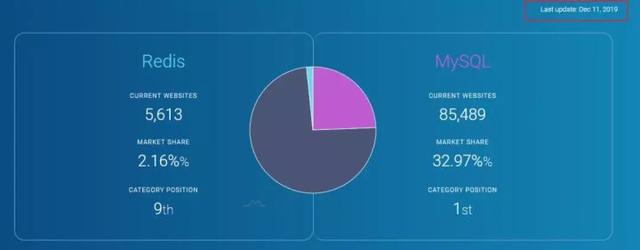
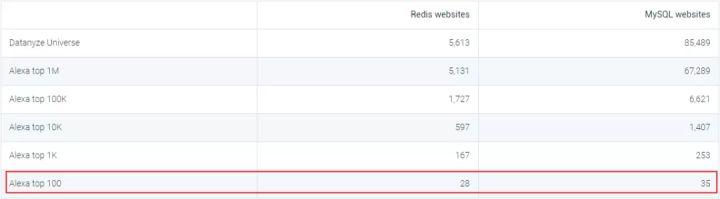
可以看到Redis總體份額排名第9并且在全球Top100站點(diǎn)中部署數(shù)量與MySQL基本持平,所以Redis還是有一定的江湖地位的。
3.聊聊實(shí)戰(zhàn)
目前Redis發(fā)布的穩(wěn)定版本已經(jīng)到了5.x,功能也越來越強(qiáng)大,從國內(nèi)外互聯(lián)網(wǎng)公司來看Redis幾乎是標(biāo)配了。作為開發(fā)人員在日常筆試面試和工作中遇到Redis相關(guān)問題的概率非常大,掌握Redis的相關(guān)知識(shí)點(diǎn)都十分有必要。
學(xué)習(xí)和梳理一個(gè)復(fù)雜的東西肯定不能胡子眉毛一把抓,每個(gè)人都有自己的認(rèn)知思路,筆者認(rèn)為要從充分掌握Redis需要從底向上、從外到內(nèi)去理解Redis。
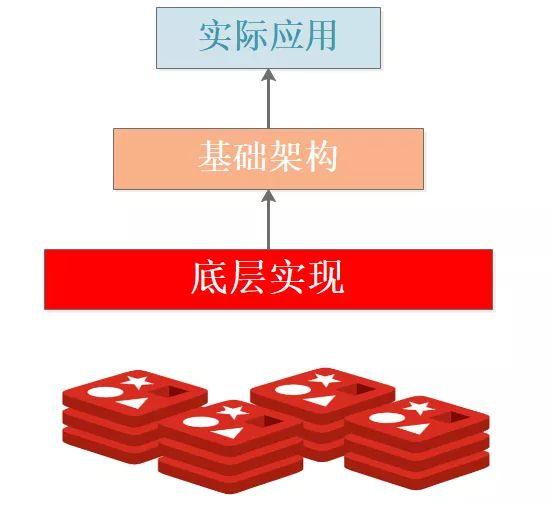
Redis的實(shí)戰(zhàn)知識(shí)點(diǎn)可以簡單分為三個(gè)層次:
- 底層實(shí)現(xiàn):主要是從Redis的源碼中提煉的問題,包括但不限于底層數(shù)據(jù)結(jié)構(gòu)、服務(wù)模型、算法設(shè)計(jì)等。
- 基礎(chǔ)架構(gòu):可用概況為Redis整體對外的功能點(diǎn)和表現(xiàn),包括但不限于單機(jī)版主從架構(gòu)實(shí)現(xiàn)、主從數(shù)據(jù)同步、哨兵機(jī)制、集群實(shí)現(xiàn)、分布式一致性、故障遷移等。
- 實(shí)際應(yīng)用:實(shí)戰(zhàn)中Redis可用幫你做什么,包括但不限于單機(jī)緩存、分布式緩存、分布式鎖、一些應(yīng)用。
深入理解和熟練使用Redis需要時(shí)間錘煉,要做到信手拈來著實(shí)不易,想在短時(shí)間內(nèi)突破只能從熱點(diǎn)題目入手,雖然這樣感覺有些功利,不過也算無可厚非吧,為了吃飯我們還是傾向于原諒懶惰的自己,要不然吃土喝風(fēng)?
4.底層實(shí)現(xiàn)熱點(diǎn)題目
底層實(shí)現(xiàn)篇的題目主要是與Redis的源碼和設(shè)計(jì)相關(guān),可以說是Redis功能的基石,了解底層實(shí)現(xiàn)可以讓我們更好地掌握功能,由于底層代碼很多,在后續(xù)的基礎(chǔ)架構(gòu)篇中仍然會(huì)穿插源碼來分析,因此本篇只列舉一些熱點(diǎn)的問題。
Q1: Redis常用五種數(shù)據(jù)類型是如何實(shí)現(xiàn)的?
Redis支持的常用5種數(shù)據(jù)類型指的是value類型,分別為:字符串String、列表List、哈希Hash、集合Set、有序集合Zset,但是Redis后續(xù)又豐富了幾種數(shù)據(jù)類型分別是Bitmaps、HyperLogLogs、GEO。
由于Redis是基于標(biāo)準(zhǔn)C寫的,只有最基礎(chǔ)的數(shù)據(jù)類型,因此Redis為了滿足對外使用的5種數(shù)據(jù)類型,開發(fā)了屬于自己獨(dú)有的一套基礎(chǔ)數(shù)據(jù)結(jié)構(gòu),使用這些數(shù)據(jù)結(jié)構(gòu)來實(shí)現(xiàn)5種數(shù)據(jù)類型。
Redis底層的數(shù)據(jù)結(jié)構(gòu)包括:簡單動(dòng)態(tài)數(shù)組SDS、鏈表、哈希表、跳躍鏈表、整數(shù)集合、壓縮列表、對象。
Redis為了平衡空間和時(shí)間效率,針對value的具體類型在底層會(huì)采用不同的數(shù)據(jù)結(jié)構(gòu)來實(shí)現(xiàn),其中哈希表和壓縮列表是復(fù)用比較多的數(shù)據(jù)結(jié)構(gòu),如下圖展示了對外數(shù)據(jù)類型和底層數(shù)據(jù)結(jié)構(gòu)之間的映射關(guān)系:
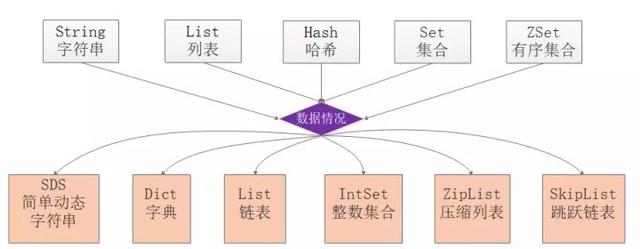
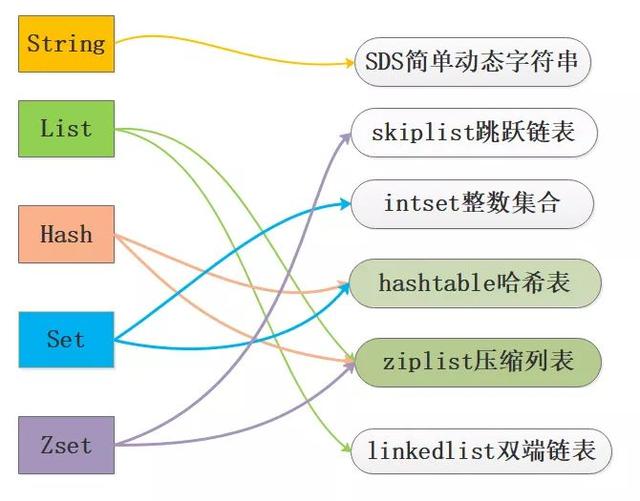
從圖中可以看到ziplist壓縮列表可以作為Zset、Set、List三種數(shù)據(jù)類型的底層實(shí)現(xiàn),看來很強(qiáng)大,壓縮列表是一種為了節(jié)約內(nèi)存而開發(fā)的且經(jīng)過特殊編碼之后的連續(xù)內(nèi)存塊順序型數(shù)據(jù)結(jié)構(gòu),底層結(jié)構(gòu)還是比較復(fù)雜的。
Q2: Redis的SDS和C中字符串相比有什么優(yōu)勢?
在C語言中使用N+1長度的字符數(shù)組來表示字符串,尾部使用'\0'作為結(jié)尾標(biāo)志,對于此種實(shí)現(xiàn)無法滿足Redis對于安全性、效率、豐富的功能的要求,因此Redis單獨(dú)封裝了SDS簡單動(dòng)態(tài)字符串結(jié)構(gòu)。
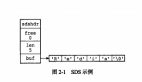
在理解SDS的優(yōu)勢之前需要先看下SDS的實(shí)現(xiàn)細(xì)節(jié),找了github最新的src/sds.h的定義看下:
看了前面的定義,筆者畫了個(gè)圖:
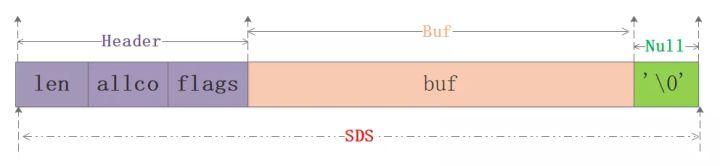
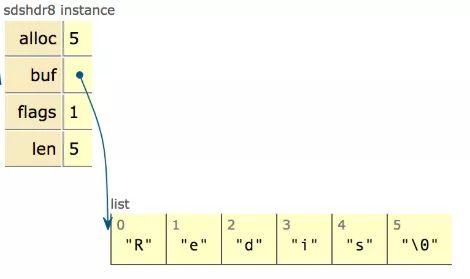
從圖中可以知道sds本質(zhì)分為三部分:header、buf、null結(jié)尾符,其中header可以認(rèn)為是整個(gè)sds的指引部分,給定了使用的空間大小、最大分配大小等信息,再用一張網(wǎng)上的圖來清晰看下sdshdr8的實(shí)例:
在sds.h/sds.c源碼中可清楚地看到sds完整的實(shí)現(xiàn)細(xì)節(jié),本文就不展開了要不然篇幅就過長了,快速進(jìn)入主題說下sds的優(yōu)勢:
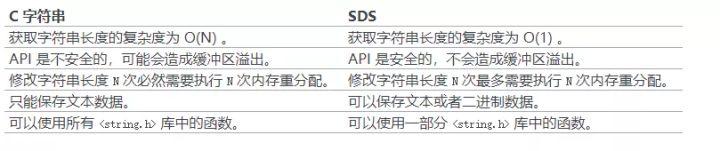
- O(1)獲取長度: C字符串需要遍歷而sds中有l(wèi)en可以直接獲得;
- 防止緩沖區(qū)溢出bufferoverflow: 當(dāng)sds需要對字符串進(jìn)行修改時(shí),首先借助于len和alloc檢查空間是否滿足修改所需的要求,如果空間不夠的話,SDS會(huì)自動(dòng)擴(kuò)展空間,避免了像C字符串操作中的覆蓋情況;
- 有效降低內(nèi)存分配次數(shù):C字符串在涉及增加或者清除操作時(shí)會(huì)改變底層數(shù)組的大小造成重新分配、sds使用了空間預(yù)分配和惰性空間釋放機(jī)制,說白了就是每次在擴(kuò)展時(shí)是成倍的多分配的,在縮容是也是先留著并不正式歸還給OS,這兩個(gè)機(jī)制也是比較好理解的;
二進(jìn)制安全:C語言字符串只能保存ascii碼,對于圖片、音頻等信息無法保存,sds是二進(jìn)制安全的,寫入什么讀取就是什么,不做任何過濾和限制;
老規(guī)矩上一張黃健宏大神總結(jié)好的圖:
Q3:Redis的字典是如何實(shí)現(xiàn)的?簡述漸進(jìn)式rehash的過程。
字典算是Redis5中常用數(shù)據(jù)類型中的明星成員了,前面說過字典可以基于ziplist和hashtable來實(shí)現(xiàn),我們只討論基于hashtable實(shí)現(xiàn)的原理。
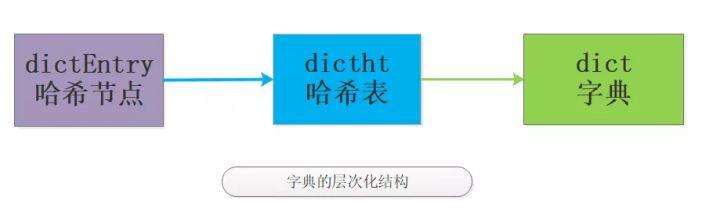
字典是個(gè)層次非常明顯的數(shù)據(jù)類型,如圖:
有了個(gè)大概的概念,我們看下最新的src/dict.h源碼定義:
- //哈希節(jié)點(diǎn)結(jié)構(gòu)
- typedef struct dictEntry {
- void *key;
- union {
- void *val;
- uint64_t u64;
- int64_t s64;
- double d;
- } v;
- struct dictEntry *next;
- } dictEntry;
- //封裝的是字典的操作函數(shù)指針
- typedef struct dictType {
- uint64_t (*hashFunction)(const void *key);
- void *(*keyDup)(void *privdata, const void *key);
- void *(*valDup)(void *privdata, const void *obj);
- int (*keyCompare)(void *privdata, const void *key1, const void *key2);
- void (*keyDestructor)(void *privdata, void *key);
- void (*valDestructor)(void *privdata, void *obj);
- } dictType;
- /* This is our hash table structure. Every dictionary has two of this as we
- * implement incremental rehashing, for the old to the new table. */
- //哈希表結(jié)構(gòu) 該部分是理解字典的關(guān)鍵
- typedef struct dictht {
- dictEntry **table;
- unsigned long size;
- unsigned long sizemask;
- unsigned long used;
- } dictht;
- //字典結(jié)構(gòu)
- typedef struct dict {
- dictType *type;
- void *privdata;
- dictht ht[2];
- long rehashidx; /* rehashing not in progress if rehashidx == -1 */
- unsigned long iterators; /* number of iterators currently running */
- } dict;
C語言的好處在于定義必須是由最底層向外的,因此我們可以看到一個(gè)明顯的層次變化,于是筆者又畫一圖來展現(xiàn)具體的層次概念:
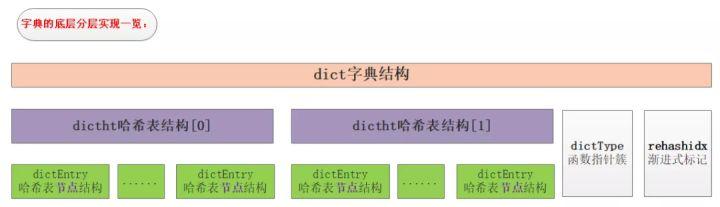
- 關(guān)于dictEntry
dictEntry是哈希表節(jié)點(diǎn),也就是我們存儲(chǔ)數(shù)據(jù)地方,其保護(hù)的成員有:key,v,next指針。key保存著鍵值對中的鍵,v保存著鍵值對中的值,值可以是一個(gè)指針或者是uint64_t或者是int64_t。next是指向另一個(gè)哈希表節(jié)點(diǎn)的指針,這個(gè)指針可以將多個(gè)哈希值相同的鍵值對連接在一次,以此來解決哈希沖突的問題。
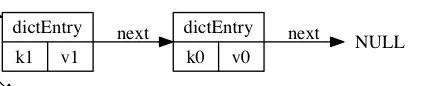
如圖為兩個(gè)沖突的哈希節(jié)點(diǎn)的連接關(guān)系:
- 關(guān)于dictht
從源碼看哈希表包括的成員有table、size、used、sizemask。table是一個(gè)數(shù)組,數(shù)組中的每個(gè)元素都是一個(gè)指向dictEntry結(jié)構(gòu)的指針, 每個(gè)dictEntry結(jié)構(gòu)保存著一個(gè)鍵值對;size 屬性記錄了哈希表table的大小,而used屬性則記錄了哈希表目前已有節(jié)點(diǎn)的數(shù)量。sizemask等于size-1和哈希值計(jì)算一個(gè)鍵在table數(shù)組的索引,也就是計(jì)算index時(shí)用到的。
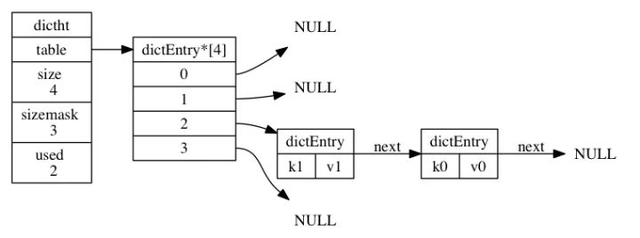
如上圖展示了一個(gè)大小為4的table中的哈希節(jié)點(diǎn)情況,其中k1和k0在index=2發(fā)生了哈希沖突,進(jìn)行開鏈表存在,本質(zhì)上是先存儲(chǔ)的k0,k1放置是發(fā)生沖突為了保證效率直接放在沖突鏈表的最前面,因?yàn)樵撴湵頉]有尾指針。
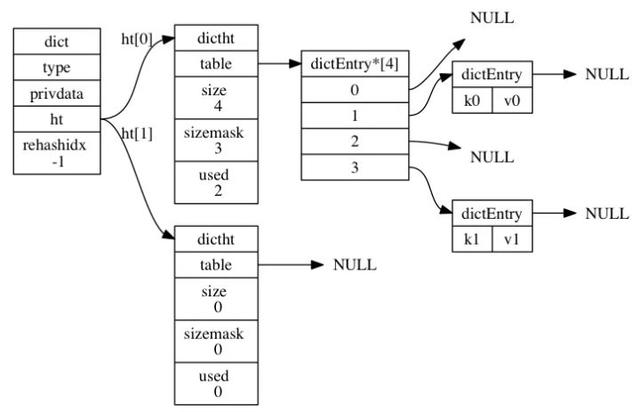
- 關(guān)于dict
從源碼中看到dict結(jié)構(gòu)體就是字典的定義,包含的成員有type,privdata、ht、rehashidx。其中dictType指針類型的type指向了操作字典的api,理解為函數(shù)指針即可,ht是包含2個(gè)dictht的數(shù)組,也就是字典包含了2個(gè)哈希表,rehashidx進(jìn)行rehash時(shí)使用的變量,privdata配合dictType指向的函數(shù)作為參數(shù)使用,這樣就對字典的幾個(gè)成員有了初步的認(rèn)識(shí)。
字典的哈希算法
redis使用MurmurHash算法計(jì)算哈希值,該算法最初由Austin Appleby在2008年發(fā)明,MurmurHash算法的無論數(shù)據(jù)輸入情況如何都可以給出隨機(jī)分布性較好的哈希值并且計(jì)算速度非常快,目前有MurmurHash2和MurmurHash3等版本。
普通Rehash重新散列
哈希表保存的鍵值對數(shù)量是動(dòng)態(tài)變化的,為了讓哈希表的負(fù)載因子維持在一個(gè)合理的范圍之內(nèi),就需要對哈希表進(jìn)行擴(kuò)縮容。
擴(kuò)縮容是通過執(zhí)行rehash重新散列來完成,對字典的哈希表執(zhí)行普通rehash的基本步驟為分配空間->逐個(gè)遷移->交換哈希表,詳細(xì)過程如下:
1.為字典的ht[1]哈希表分配空間,分配的空間大小取決于要執(zhí)行的操作以及ht[0]當(dāng)前包含的鍵值對數(shù)量:
擴(kuò)展操作時(shí)ht[1]的大小為第一個(gè)大于等于ht[0].used*2的2^n;
收縮操作時(shí)ht[1]的大小為第一個(gè)大于等于ht[0].used的2^n ;
擴(kuò)展時(shí)比如h[0].used=200,那么需要選擇大于400的第一個(gè)2的冪,也就是2^9=512。
2.將保存在ht[0]中的所有鍵值對重新計(jì)算鍵的哈希值和索引值rehash到ht[1]上;
3.重復(fù)rehash直到ht[0]包含的所有鍵值對全部遷移到了ht[1]之后釋放 ht[0], 將ht[1]設(shè)置為 ht[0],并在ht[1]新創(chuàng)建一個(gè)空白哈希表, 為下一次rehash做準(zhǔn)備。
- 漸進(jìn)Rehash過程
Redis的rehash動(dòng)作并不是一次性完成的,而是分多次、漸進(jìn)式地完成的,原因在于當(dāng)哈希表里保存的鍵值對數(shù)量很大時(shí), 一次性將這些鍵值對全部rehash到ht[1]可能會(huì)導(dǎo)致服務(wù)器在一段時(shí)間內(nèi)停止服務(wù),這個(gè)是無法接受的。
針對這種情況Redis采用了漸進(jìn)式rehash,過程的詳細(xì)步驟:
- 為ht[1]分配空間,這個(gè)過程和普通Rehash沒有區(qū)別;
- 將rehashidx設(shè)置為0,表示rehash工作正式開始,同時(shí)這個(gè)rehashidx是遞增的,從0開始表示從數(shù)組第一個(gè)元素開始rehash。
- 在rehash進(jìn)行期間,每次對字典執(zhí)行增刪改查操作時(shí),順帶將ht[0]哈希表在rehashidx索引上的鍵值對rehash到 ht[1],完成后將rehashidx加1,指向下一個(gè)需要rehash的鍵值對。
- 隨著字典操作的不斷執(zhí)行,最終ht[0]的所有鍵值對都會(huì)被rehash至ht[1],再將rehashidx屬性的值設(shè)為-1來表示 rehash操作已完成。
漸進(jìn)式 rehash的思想在于將rehash鍵值對所需的計(jì)算工作分散到對字典的每個(gè)添加、刪除、查找和更新操作上,從而避免了集中式rehash而帶來的阻塞問題。
看到這里不禁去想這種捎帶腳式的rehash會(huì)不會(huì)導(dǎo)致整個(gè)過程非常漫長?如果某個(gè)value一直沒有操作那么需要擴(kuò)容時(shí)由于一直不用所以影響不大,需要縮容時(shí)如果一直不處理可能造成內(nèi)存浪費(fèi),具體的還沒來得及研究,先埋個(gè)問題吧!