比PS還好用!Python 20行代碼批量摳圖


摳圖前 vs Python自動摳圖后
在日常的工作和生活中,我們經常會遇到需要摳圖的場景,即便是只有一張圖片需要摳,也會摳得我們不耐煩,倘若遇到許多張圖片需要摳,這時候你的表情應該會很有趣。
Python能夠成為這樣的一種工具:在只有一張圖片,需要細致地摳出人物的情況下,能幫你減少摳圖步驟;在有多張圖片需要摳的情況下,能直接幫你輸出這些人物的基本輪廓,雖然不夠細致,但也夠用了。
DeepLabv3+ 是谷歌 DeepLab語義分割系列網絡的最新作 ,這個模型可以用于人像分割,支持任意大小的圖片輸入。如果我們自己來實現這個模型,那可能會非常麻煩,但是幸運的是,百度的paddle hub已經幫我們實現了,我們僅需要加載模型對圖像進行分割即可。
1.準備
為了實現這個實驗,Python是必不可少的,如果你還沒有安裝Python,可以關注文末的微信公眾號獲取下載安裝指南
然后,我們需要安裝baidu的paddlepaddle, 官方網站就有詳細的指引:
- https://www.paddlepaddle.org.cn/install/quick
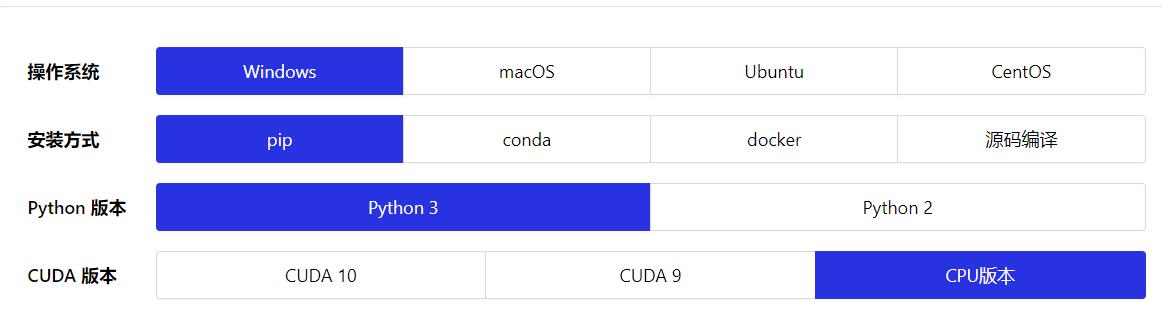
根據你自己的情況選擇這些選項,最后一個CUDA版本,由于本實驗不需要訓練數據,也不需要太大的計算量,所以直接選擇CPU版本即可。選擇完畢,下方會出現安裝指引,不得不說,Paddlepaddle這些方面做的還是比較貼心的(小聲bb:就是名字起的不好)。
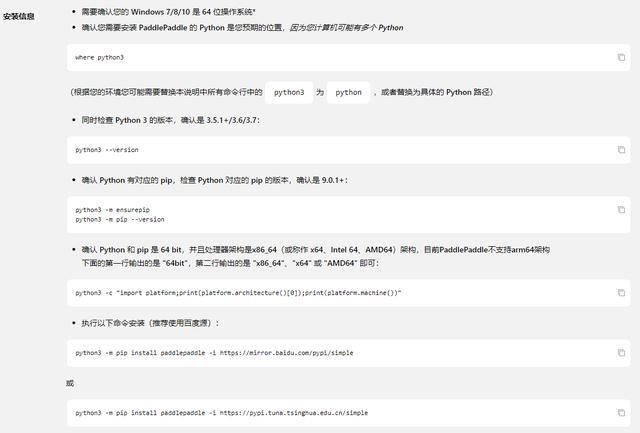
要注意,如果你的Python3環境變量里的程序名稱是Python,記得將語句改為Python xxx,如下進行安裝:
- python -m pip install paddlepaddle -i https://mirror.baidu.com/pypi/simple
還需要安裝paddlehub:
- pip install -i https://mirror.baidu.com/pypi/simple paddlehub
2.編寫代碼
整個步驟分為三步:
- 加載模型
- 指定待摳圖的圖片目錄
- 摳圖
- import os
- import sys
- import paddlehub as hub
- # 1.加載模型
- humanseg = hub.Module(name="deeplabv3p_xception65_humanseg")
- # 2.指定待摳圖圖片目錄
- path = './source/'
- files = []
- dirs = os.listdir(path)
- for diretion in dirs:
- files.append(path + diretion)
- # 3.摳圖
- results = humanseg.segmentation(data={"image": files})
- for result in results:
- print(result['origin'])
- print(result['processed'])
不多不少一共20行代碼。摳圖完畢后會在本地文件夾下產生一個叫做humanseg_output的文件夾。這里面存放的是已經摳圖成功的圖片。

3.結果分析
不得不承認,谷歌的算法就素厲害啊。只要背景好一點,摳出來的細節都和手動摳的細節不相上下,甚至優于人工手段。
不過在背景和人的顏色不相上下的情況下,會產生一些問題,比如下面這個結果:

背后那個大叔完全被忽略掉了(求大叔的內心陰影面積)。盡管如此,這個模型是我迄今為止見過的最強摳圖模型,沒有之一。