AI股神:如何用機(jī)器學(xué)習(xí)預(yù)測股價(jià)?
本文轉(zhuǎn)載自公眾號“讀芯術(shù)”(ID:AI_Discovery)。
首先要強(qiáng)調(diào),文中只是簡單展示了怎樣上手H2o.ai機(jī)器學(xué)習(xí)框架,并不作為投資理財(cái)?shù)慕ㄗh。不要簡單根據(jù)本文就做出任何投資理財(cái)?shù)臎Q策。
本文將向你展示如何使用R語言和H2o.ai機(jī)器學(xué)習(xí)框架預(yù)測股價(jià)。該框架也可以在Python中使用,但因?yàn)楣P者更熟悉R語言,所以本文就用R語言來演示。以下是詳細(xì)的步驟:
- 搜集數(shù)據(jù)
- 導(dǎo)入數(shù)據(jù)
- 整理并操作數(shù)據(jù)
- 分割測試并觀察訓(xùn)練
- 選擇模型
- 訓(xùn)練模型
- 用模型測試數(shù)據(jù)
- 評估結(jié)果
- 如有必要便改進(jìn)模型
- 重復(fù)步驟5到10,直到對結(jié)果滿意為止
本文研究的問題是:股票在接下來一小時(shí)的收盤價(jià)是多少?
數(shù)據(jù)整理
導(dǎo)入想要通過MetaTrader軟件進(jìn)行預(yù)測的資產(chǎn)數(shù)據(jù)之后,需要更改一些變量。首先,定義變量名稱:
- #seting the name of variables
- col_names <- c("Date", "Open", "High","Low", "Close", "Tick", "Volume")
- colnames(data) <- col_names
- head(data)
數(shù)據(jù)格式如下:
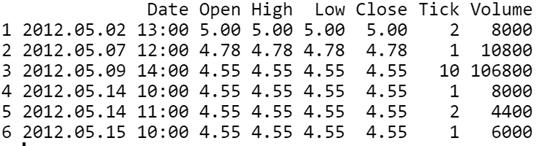
我們僅用到開盤價(jià)、最高價(jià)、最低價(jià)、收盤價(jià)和交易量等一些能獲得的數(shù)據(jù),那么就需要清除其他數(shù)據(jù):
- data$Date <- NULL
- data$Tick <- NULL
因?yàn)槲覀兿胫老乱粋€(gè)觀測期的收盤價(jià),所以需要將下面的值移到上一行,需要用新數(shù)據(jù)在原始數(shù)據(jù)集中創(chuàng)建函數(shù)并設(shè)置變量:
- #shifting n rows up of a given variable
- shift <- function(x, n) {
- c(x[-(seq(n))], rep(NA, n))
- }
- data$shifted <- shift(data$Close, 1)
- tail(data)
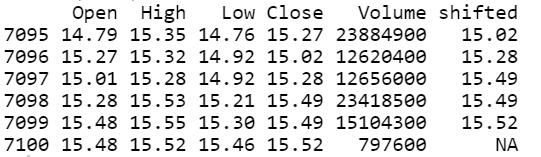
注意,我們已在上一行中給變量收盤價(jià)賦了值。所以,在最后一行中會出現(xiàn)NA,我們用na.omit ()函數(shù)跳過這一行:
- #remove NA observations
- data <- na.omit(data)
- write.csv(data, "data.csv")
OK,數(shù)據(jù)已準(zhǔn)備就緒,可以開始建模了。
分割數(shù)據(jù)
用H2O.ai進(jìn)行數(shù)據(jù)分割。H2O.ai為我們分析和訓(xùn)練人工智能模型提供了一套完整的解決方案,非常好用,即便是沒有任何數(shù)據(jù)科學(xué)背景的人也能使用它來解決復(fù)雜的問題。先下載H2O.ai:
- #Installing the package
- install.packages("h2o")
- #loading the library
- library(h2o)
安裝加載好后,啟動用于建模的虛擬機(jī)。啟動虛擬機(jī)時(shí),必須設(shè)置所需的核數(shù)和內(nèi)存參數(shù):
- #Initializing the Virtual Machine using all the threads (-1) and 16gb ofmemory
- h2o.init(nthreads = -1, max_mem_size = "16g")
導(dǎo)入數(shù)據(jù):
- h2o.importFile("data.csv")
- h2o.describe(data)
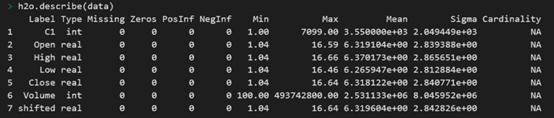
接著定義想要在數(shù)據(jù)集中預(yù)測的變量,以及那些用于訓(xùn)練模型的變量:
- y <- "shifted" #variable we want to forecast
- x <- setdiff(names(data), y)
隨后,分割數(shù)據(jù),分別用于訓(xùn)練和測試,其中80%用于訓(xùn)練數(shù)據(jù)。
- parts <- h2o.splitFrame(data, .80)
- train <- parts[[1]]
- test <- parts[[2]]
完成這些步驟,就是時(shí)候見證H2O.ai創(chuàng)造奇跡的時(shí)候了。
選擇模型
每一位數(shù)據(jù)科學(xué)家在創(chuàng)建自己的機(jī)器學(xué)習(xí)項(xiàng)目時(shí),必須完成的一項(xiàng)任務(wù)便是識別出最佳的一個(gè)或一組模型來進(jìn)行預(yù)測。這需要大量的知識,尤其是深厚的數(shù)學(xué)基礎(chǔ),來決定針對特定任務(wù)的最佳方案。
我們可以借助H2O.ai來選擇最佳模型,這樣就可以騰出時(shí)間解決其他問題,這便是自動建模。雖然這可能不是解決問題最有效的方法,卻是一個(gè)不錯(cuò)的嘗試。
訓(xùn)練模型
創(chuàng)建模型,需要調(diào)用automl函數(shù)并傳遞必要的參數(shù):
- automodel <- h2o.automl(x, y, train, test, max_runtime_secs = 120)
幾分鐘后,我們就能獲取一個(gè)按性能順序排列的模型列表:
運(yùn)用模型
現(xiàn)在,可以用模型來測試數(shù)據(jù)啦!你還可以用模型對尚未觀察到的數(shù)據(jù)進(jìn)行性能評估,以模型和測試數(shù)據(jù)作為參數(shù)調(diào)用預(yù)測函數(shù):
- predictions <- h2o.predict(automodel@leader, test)
好啦,靜待一小時(shí),看看你的預(yù)測能否成真吧。
免責(zé)聲明:本文不是投資建議,預(yù)測股票價(jià)格并不是一項(xiàng)簡單的任務(wù),本文只是簡單說明了用H2O.ai解決機(jī)器學(xué)習(xí)問題是多么容易。預(yù)測股價(jià)走勢非常容易,但這并不意味著預(yù)測都是正確或準(zhǔn)確無誤的。