從網(wǎng)絡文件系統(tǒng)到對象存儲,聊聊對象存儲的前世今生
每種技術(shù)的產(chǎn)生都有其原因,也有其淵源。網(wǎng)絡文件系統(tǒng)的產(chǎn)生有幾十年的歷史了,但是由于在互聯(lián)網(wǎng)盛行的當下無法滿足某些需求,于是對象存儲產(chǎn)生了。今天我們就從從網(wǎng)絡文件系統(tǒng)說起。
早些時候的企業(yè)級架構(gòu)普遍采用網(wǎng)絡文件系統(tǒng),這其中最為著名的就是Sum的NFS了。微軟也有類似的網(wǎng)絡文件系統(tǒng),也就是SMB。網(wǎng)絡文件系統(tǒng)的原理很簡單,其目的就是將存儲系統(tǒng)上的文件系統(tǒng)映射到計算節(jié)點(比如Web服務器)。這樣可以實現(xiàn)存儲資源的共享,提高存儲資源的利用率。具體映射方式如下所示。
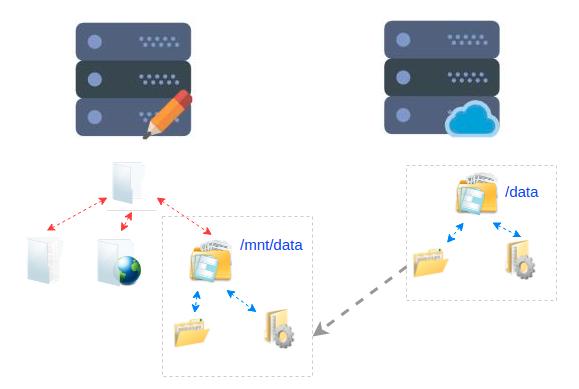
但是文件系統(tǒng)有個天然的缺點。由于文件系統(tǒng)空間組織的特點,導致對文件訪問的時候需要比較多次的磁盤訪問。
以Ext4文件系統(tǒng)為例,文件系統(tǒng)將磁盤空間分為兩個主要的區(qū)域,一個是元數(shù)據(jù)區(qū),用于存儲文件inode等信息;另外一個是數(shù)據(jù)區(qū),用于存儲文件的數(shù)據(jù),也就是用戶數(shù)據(jù),具體如下圖所示。
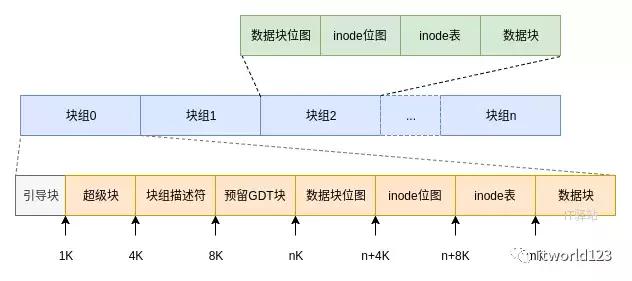
這樣,當我們訪問一個文件的時候,首先需要找到文件對應的inode,然后根據(jù)inode信息找到數(shù)據(jù)的位置,并讀取數(shù)據(jù)。這個過程可能要涉及到2-3次的磁盤訪問。對于互聯(lián)網(wǎng)應用來說,多次磁盤訪問會顯著降低性能,影響用戶的體驗。
當然,除此之外還有其它一些問題,比如橫向擴展能力等。其實本質(zhì)上來說,文件系統(tǒng)的目的是一個通用的存儲形態(tài),其目的是為了適用大多數(shù)的應用場景(比如文件鎖,擴展屬性,ACL等等)。而網(wǎng)絡文件系統(tǒng)為了保證與文件系統(tǒng)語義的一致性,也需要實現(xiàn)這些特性,這就導致網(wǎng)絡文件系統(tǒng)比較臃腫。
對象存儲解決的問題
由于上述缺點,傳統(tǒng)的網(wǎng)絡文件系統(tǒng)是完全無法滿足互聯(lián)網(wǎng)領域應用的。我們舉一個例子,以FaceBook為例,其每秒鐘都有幾十萬次的照片檢索請求。其存儲的照片總量每天新增3.5億張,對應的存儲增量大概在300TB左右。如果對應物理設備,每天大概需要新增上百塊硬盤。
這種問題在任何互聯(lián)網(wǎng)公司都會遇到的問題。比如國內(nèi)的頭條,淘寶或者京東等等,在它們的平臺上每天也要產(chǎn)生海量的圖片訪問。傳統(tǒng)存儲很難滿足其性能和擴展性的要求。
雖然互聯(lián)網(wǎng)應用對性能和容量的要求極高,但是對其它特性卻沒什么特別的要求。甚至可以說它對其它特性基本上沒有太多要求。由于其存儲的主要是圖片,而且對圖片的存儲是一次存儲,多次訪問,沒有修改。
為了解決上述問題,對象存儲應運而生。可以看出對象存儲解決的問題很集中,如何保證橫向擴展能力、降低訪問延時。而不需要實現(xiàn)文件系統(tǒng)的其它額外特性(后面我們會介紹對象存儲還有一些高級特性)。下面是維基百科對對象存儲的定義。
Object storage (also known as object-based storage) is a computer data storage architecture that manages data as objects
從定義可以看出,對象存儲在數(shù)據(jù)處理層面的特點是將待處理的數(shù)據(jù)看做一個整體,這也就是為什么把它稱為對象,而不是文件了。
其實對象存儲也并非全部如此簡單,很多對象存儲也實現(xiàn)了比較復雜的功能特性。比如S3對象存儲可以支持大數(shù)據(jù)處理、擴展屬性和二次處理(比如照片的轉(zhuǎn)換,水印等)等特性。
對象存儲的常見架構(gòu)
為了讓大家對對象存儲有更加深刻的理解,我們介紹一下常見對象存儲的架構(gòu)。雖然亞馬遜的S3非常出名,但是并沒有公開太多技術(shù)信息,其架構(gòu)也無從了解。今天本文將介紹一下比較流行的其它對象存儲的架構(gòu)。
Swift對象存儲
首先介紹一下開源對象存儲Swift的架構(gòu)。Swift是OpenStack的一個子項目,是非常流行的開源對象存儲軟件。Swift在OpenStack中主要用作虛擬機鏡像,其特點也是存儲大對象。對于小對象則想多弱勢。
Swift最主要的是實現(xiàn)橫向擴展能力,其前端有一個Proxy組件,該組件實現(xiàn)了數(shù)據(jù)的分發(fā)服務。該組件可以具備多個實例,每個實例可以安裝在一臺物理服務器。由于Proxy可以橫向擴展,因此不會成為性能瓶頸。
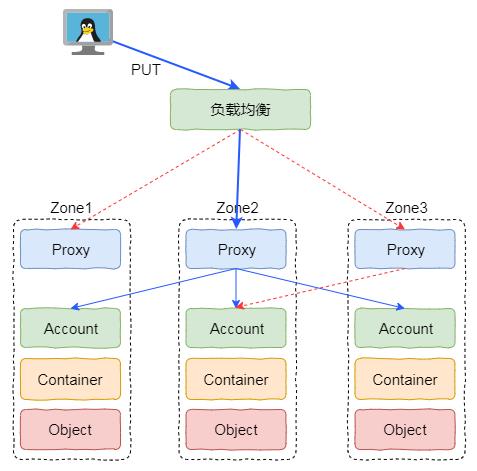
在Proxy中最核心的算法是進行數(shù)據(jù)放置的一致性哈希算法。該算法實現(xiàn)了將一個對象映射到物理設備的過程。為了保證整個系統(tǒng)的可靠性和可用性,Swift將設備劃分為若干等級,比如Zone,Host和Disk。通過不同設備的分發(fā),實現(xiàn)故障域的隔離。
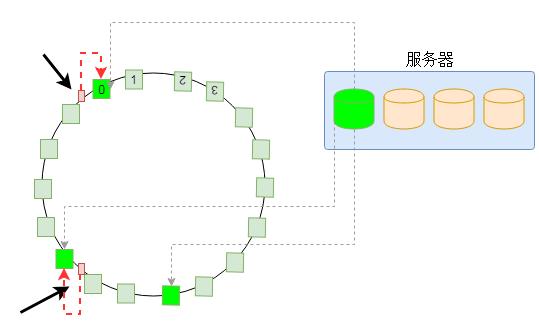
如上圖哈希算法,首先將物理設備映射到哈希環(huán)上;當有對象訪問的時候根據(jù)對象名稱計算出哈希值,然后將對象映射到具體的物理設備上。
Haystack對象存儲
Facebook這對其照片應用開發(fā)了Haystack對象存儲。Haystack與前面Switf的差異是其存儲的是小對象。因為圖片通常在10MB以下,大部分在KB級別。因此Haystack除了保證系統(tǒng)的橫向擴展能力外,其最主要的是實現(xiàn)對小文件的處理。
前面我們說過,對于小文件的性能問題,普通文件系統(tǒng)的問題在于多次讀盤操作。而Haystack正式解決了該問題。
Haystack的做法非常簡單,它將多個小文件作為一個大文件的局部數(shù)據(jù),這個局部數(shù)據(jù)稱為needle。同時Haystack構(gòu)建了一個描述needle在大文件中位置的索引文件。由于索引文件比較小,因此可以一次性的加載到內(nèi)存當中。
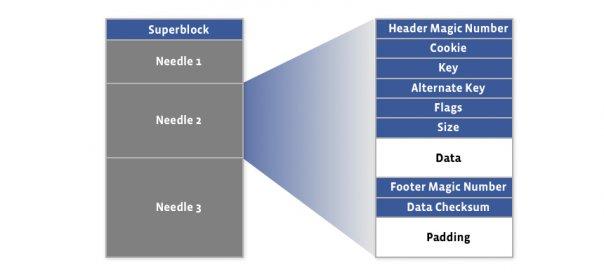
通過這種方式,當客戶端需要訪問數(shù)據(jù)的時候,在存儲節(jié)點可以直接從內(nèi)存中得到數(shù)據(jù)的位置,并一次從磁盤上讀取數(shù)據(jù)。這樣訪問存儲的性能得到大幅的提升。
由于篇幅有限,本文先介紹到這里,關(guān)于存儲技術(shù)的更多細節(jié),還請關(guān)注本號。本號后續(xù)還會步步深入,介紹關(guān)于存儲技術(shù)的諸多細節(jié)。