













同事問我MySQL怎么遞歸查詢,我懵逼了...

前言
最近在做的業(yè)務場景涉及到了數(shù)據(jù)庫的遞歸查詢。我們公司用的 Oracle ,眾所周知,Oracle 自帶有遞歸查詢的功能,所以實現(xiàn)起來特別簡單。
但是,我記得 MySQL 是沒有遞歸查詢功能的,那 MySQL 中應該怎么實現(xiàn)呢?
于是,就有了這篇文章。
文章主要知識點:
- Oracle 遞歸查詢, start with connect by prior 用法
- find_in_set 函數(shù)
- concat,concat_ws,group_concat 函數(shù)
- MySQL 自定義函數(shù)
- 手動實現(xiàn) MySQL 遞歸查詢
Oracle 遞歸查詢
在 Oracle 中是通過 start with connect by prior 語法來實現(xiàn)遞歸查詢的。
按照 prior 關鍵字在子節(jié)點端還是父節(jié)點端,以及是否包含當前查詢的節(jié)點,共分為四種情況。
prior 在子節(jié)點端(向下遞歸)
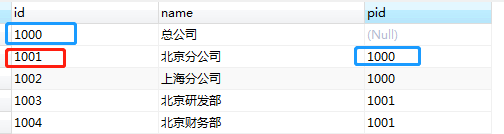
第一種情況:start with 子節(jié)點id = ' 查詢節(jié)點 ' connect by prior 子節(jié)點id = 父節(jié)點id
- select * from dept start with id='1001' connet by prior id=pid;
這里,按照條件 id='1001' 對當前節(jié)點以及它的子節(jié)點遞歸查詢。查詢結(jié)果包含自己及所有子節(jié)點。

第二種情況:start with 父節(jié)點id= ' 查詢節(jié)點 ' connect by prior 子節(jié)點id = 父節(jié)點 id
- select * from dept start with pid='1001' connect by prior id=pid;
這里,按照條件 pid='1001' 對當前節(jié)點的所有子節(jié)點遞歸查詢。查詢結(jié)果只包含它的所有子節(jié)點,不包含自己。

其實想一想也對,因為開始條件是以父節(jié)點為根節(jié)點,且向下遞歸,自然不包含當前節(jié)點。
prior 在父節(jié)點端(向上遞歸)
第三種情況:start with 子節(jié)點id= ' 查詢節(jié)點 ' connect by prior 父節(jié)點id = 子節(jié)點id
- select * from dept start with id='1001' connect by prior pid=id;
這里按照條件 id='1001' ,對當前節(jié)點及其父節(jié)點遞歸查詢。查詢結(jié)果包括自己及其所有父節(jié)點。
第四種情況:start with 父節(jié)點id= ' 查詢節(jié)點 ' connect by prior 父節(jié)點id = 子節(jié)點id
- select * from dept start with pid='1001' connect by prior pid=id;
這里按照條件 pid='1001',對當前節(jié)點的第一代子節(jié)點以及它的父節(jié)點遞歸查詢。查詢結(jié)果包括自己的第一代子節(jié)點以及所有父節(jié)點。(包括自己)

其實這種情況也好理解,因為查詢開始條件是以 父節(jié)點為根節(jié)點,且向上遞歸,自然需要把當前父節(jié)點的第一層子節(jié)點包括在內(nèi)。
以上四種情況初看可能會讓人迷惑,容易記混亂,其實不然。
我們只需要記住 prior 的位置在子節(jié)點端,就向下遞歸,在父節(jié)點端就向上遞歸。
- 開始條件若是子節(jié)點的話,自然包括它本身的節(jié)點。
- 開始條件若是父節(jié)點的話,則向下遞歸時,自然不包括當前節(jié)點。而向上遞歸,需要包括當前節(jié)點及其第一代子節(jié)點。
MySQL 遞歸查詢
可以看到,Oracle 實現(xiàn)遞歸查詢非常的方便。但是,在 MySQL 中并沒有幫我們處理,因此需要我們自己手動實現(xiàn)遞歸查詢。
為了方便,我們創(chuàng)建一個部門表,并插入幾條可以形成遞歸關系的數(shù)據(jù)。
- DROP TABLE IF EXISTS `dept`;
- CREATE TABLE `dept` (
- `id` varchar(10) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL,
- `name` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL,
- `pid` varchar(10) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL,
- PRIMARY KEY (`id`) USING BTREE
- ) ENGINE = InnoDB CHARACTER SET = utf8mb4 COLLATE = utf8mb4_general_ci ROW_FORMAT = Dynamic;
- INSERT INTO `dept`(`id`, `name`, `pid`) VALUES ('1000', '總公司', NULL);
- INSERT INTO `dept`(`id`, `name`, `pid`) VALUES ('1001', '北京分公司', '1000');
- INSERT INTO `dept`(`id`, `name`, `pid`) VALUES ('1002', '上海分公司', '1000');
- INSERT INTO `dept`(`id`, `name`, `pid`) VALUES ('1003', '北京研發(fā)部', '1001');
- INSERT INTO `dept`(`id`, `name`, `pid`) VALUES ('1004', '北京財務部', '1001');
- INSERT INTO `dept`(`id`, `name`, `pid`) VALUES ('1005', '北京市場部', '1001');
- INSERT INTO `dept`(`id`, `name`, `pid`) VALUES ('1006', '北京研發(fā)一部', '1003');
- INSERT INTO `dept`(`id`, `name`, `pid`) VALUES ('1007', '北京研發(fā)二部', '1003');
- INSERT INTO `dept`(`id`, `name`, `pid`) VALUES ('1008', '北京研發(fā)一部一小組', '1006');
- INSERT INTO `dept`(`id`, `name`, `pid`) VALUES ('1009', '北京研發(fā)一部二小組', '1006');
- INSERT INTO `dept`(`id`, `name`, `pid`) VALUES ('1010', '北京研發(fā)二部一小組', '1007');
- INSERT INTO `dept`(`id`, `name`, `pid`) VALUES ('1011', '北京研發(fā)二部二小組', '1007');
- INSERT INTO `dept`(`id`, `name`, `pid`) VALUES ('1012', '北京市場一部', '1005');
- INSERT INTO `dept`(`id`, `name`, `pid`) VALUES ('1013', '上海研發(fā)部', '1002');
- INSERT INTO `dept`(`id`, `name`, `pid`) VALUES ('1014', '上海研發(fā)一部', '1013');
- INSERT INTO `dept`(`id`, `name`, `pid`) VALUES ('1015', '上海研發(fā)二部', '1013');
沒錯,剛才 Oracle 遞歸,就是用的這張表。
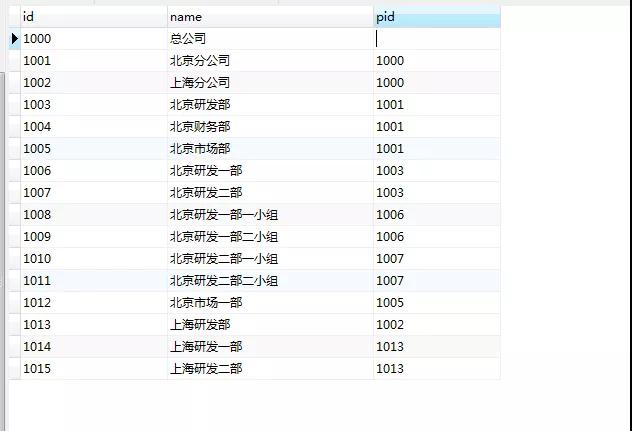
圖1
另外,在這之前,我們需要復習一下幾個 MYSQL中的函數(shù),后續(xù)會用到。
find_in_set 函數(shù)
函數(shù)語法:find_in_set(str,strlist)
str 代表要查詢的字符串 , strlist 是一個以逗號分隔的字符串,如 ('a,b,c')。
此函數(shù)用于查找 str 字符串在字符串 strlist 中的位置,返回結(jié)果為 1 ~ n 。若沒有找到,則返回0。
舉個栗子:
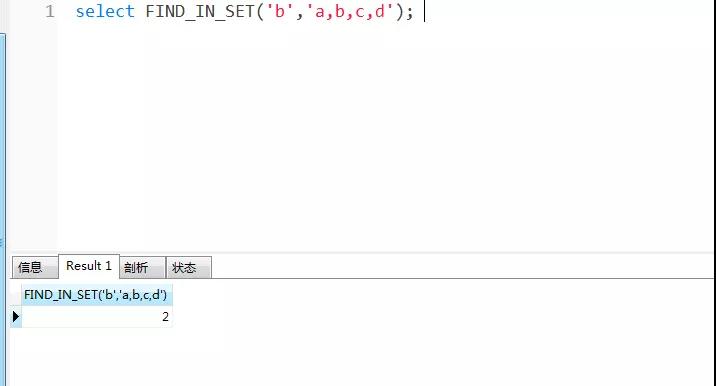
- select FIND_IN_SET('b','a,b,c,d');
結(jié)果返回 2 。因為 b 所在位置為第二個子串位置。
此外,在對表數(shù)據(jù)進行查詢時,它還有一種用法,如下:
- select * from dept where FIND_IN_SET(id,'1000,1001,1002');
結(jié)果返回所有 id 在 strlist 中的記錄,即 id = '1000' ,id = '1001' ,id = '1002' 三條記錄。

看到這,對于我們要解決的遞歸查詢,不知道你有什么啟發(fā)沒。
以向下遞歸查詢所有子節(jié)點為例。我想,是不是可以找到一個包含當前節(jié)點和所有子節(jié)點的以逗號拼接的字符串 strlist,傳進 find_in_set 函數(shù)。就可以查詢出所有需要的遞歸數(shù)據(jù)了。
那么,現(xiàn)在問題就轉(zhuǎn)化為怎樣構(gòu)造這樣的一個字符串 strlist 。
這就需要用到以下字符串拼接函數(shù)了。
concat,concat_ws,group_concat
函數(shù)一、字符串拼接函數(shù)中,最基本的就是 concat 了。它用于連接N個字符串,如,
- select CONCAT('M','Y','S','Q','L') from dual;
結(jié)果為 'MYSQL' 字符串。

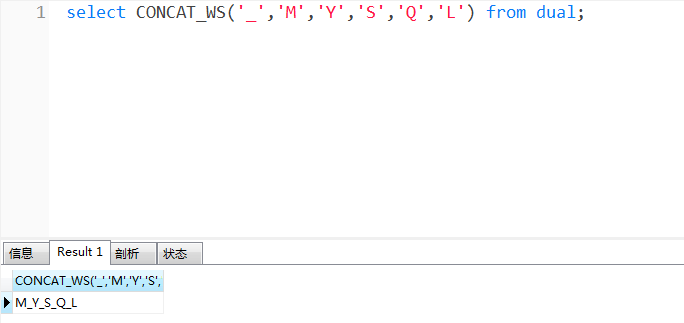
二、concat 是以逗號為默認的分隔符,而 concat_ws 則可以指定分隔符,第一個參數(shù)傳入分隔符,如以下劃線分隔。
三、group_concat 函數(shù)更強大,可以分組的同時,把字段以特定分隔符拼接成字符串。
用法:group_concat( [distinct] 要連接的字段 [order by 排序字段 asc/desc ] [separator '分隔符'] )
可以看到有可選參數(shù),可以對將要拼接的字段值去重,也可以排序,指定分隔符。若沒有指定,默認以逗號分隔。
對于 dept 表,我們可以把表中的所有 id 以逗號拼接。(這里沒有用到 group by 分組字段,則可以認為只有一組)
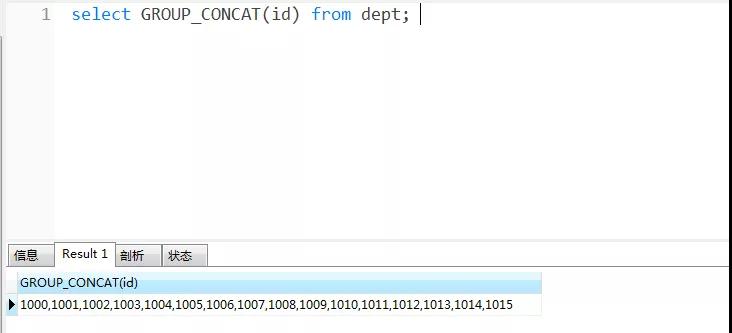
MySQL 自定義函數(shù),實現(xiàn)遞歸查詢
可以發(fā)現(xiàn)以上已經(jīng)把字符串拼接的問題也解決了。那么,問題就變成怎樣構(gòu)造有遞歸關系的字符串了。
我們可以自定義一個函數(shù),通過傳入根節(jié)點id,找到它的所有子節(jié)點。
以向下遞歸為例。 (講解自定義函數(shù)寫法的同時,講解遞歸邏輯)
- delimiter $$
- drop function if exists get_child_list$$
- create function get_child_list(in_id varchar(10)) returns varchar(1000)
- begin
- declare ids varchar(1000) default '';
- declare tempids varchar(1000);
- set tempids = in_id;
- while tempids is not null do
- set ids = CONCAT_WS(',',ids,tempids);
- select GROUP_CONCAT(id) into tempids from dept where FIND_IN_SET(pid,tempids)>0;
- end while;
- return ids;
- end
- $$
- delimiter ;
(1) delimiter $$ ,用于定義結(jié)束符。我們知道 MySQL 默認的結(jié)束符為分號,表明指令結(jié)束并執(zhí)行。但是在函數(shù)體中,有時我們希望遇到分號不結(jié)束,因此需要暫時把結(jié)束符改為一個隨意的其他值。我這里設置為 $$,意思是遇到 $$ 才結(jié)束,并執(zhí)行當前語句。
(2)drop function if exists get_child_list$$ 。若函數(shù) get_child_list 已經(jīng)存在了,則先刪除它。注意這里需要用 當前自定義的結(jié)束符 $$ 來結(jié)束并執(zhí)行語句。因為,這里需要數(shù)和下邊的函體單獨區(qū)分開來執(zhí)行。
(3)create function get_child_list 創(chuàng)建函數(shù)。并且參數(shù)傳入一個根節(jié)點的子節(jié)點id,需要注意一定要注明參數(shù)的類型和長度,如這里是 varchar(10)。returns varchar(1000) 用來定義返回值參數(shù)類型。
(4)begin 和 end 中間包圍的就是函數(shù)體。用來寫具體的邏輯。
(5)declare 用來聲明變量,并且可以用 default 設置默認值。
這里定義的 ids 即作為整個函數(shù)的返回值,是用來拼接成最終我們需要的以逗號分隔的遞歸串的。
而 tempids 是為了記錄下邊 while 循環(huán)中臨時生成的所有子節(jié)點以逗號拼接成的字符串。
(6) set 用來給變量賦值。此處把傳進來的根節(jié)點賦值給 tempids 。
(7) while do ... end while; 循環(huán)語句,循環(huán)邏輯包含在內(nèi)。注意,end while 末尾需要加上分號。
循環(huán)體內(nèi),先用 CONCAT_WS 函數(shù)把最終結(jié)果 ids 和 臨時生成的 tempids 用逗號拼接起來。
然后以 FIND_IN_SET(pid,tempids)>0 為條件,遍歷在 tempids 中的所有 pid ,尋找以此為父節(jié)點的所有子節(jié)點 id ,并且通過 GROUP_CONCAT(id) into tempids 把這些子節(jié)點 id 都用逗號拼接起來,并覆蓋更新 tempids 。
等下次循環(huán)進來時,就會再次拼接 ids ,并再次查找所有子節(jié)點的所有子節(jié)點。循環(huán)往復,一層一層的向下遞歸遍歷子節(jié)點。直到判斷 tempids 為空,說明所有子節(jié)點都已經(jīng)遍歷完了,就結(jié)束整個循環(huán)。
這里,用 '1000' 來舉例,即是:(參看圖1的表數(shù)據(jù)關系)
- 第一次循環(huán):
- tempids=1000 ids=1000 tempids=1001,1002 (1000的所有子節(jié)點)
- 第二次循環(huán):
- tempids=1001,1002 ids=1000,1001,1002 tempids=1003,1004,1005,1013 (1001和1002的所有子節(jié)點)
- 第三次循環(huán):
- tempids=1003,1004,1005,1013
- ids=1000,1001,1002,1003,1004,1005,1013
- tempids=1003和1004和1005及1013的所有子節(jié)點
- ...
- 最后一次循環(huán),因找不到子節(jié)點,tempids=null,就結(jié)束循環(huán)。
(8)return ids; 用于把 ids 作為函數(shù)返回值返回。
(9)函數(shù)體結(jié)束以后,記得用結(jié)束符 $$ 來結(jié)束整個邏輯,并執(zhí)行。
(10)最后別忘了,把結(jié)束符重新設置為默認的結(jié)束符分號 。
自定義函數(shù)做好之后,我們就可以用它來遞歸查詢我們需要的數(shù)據(jù)了。如,我查詢北京研發(fā)部的所有子節(jié)點。
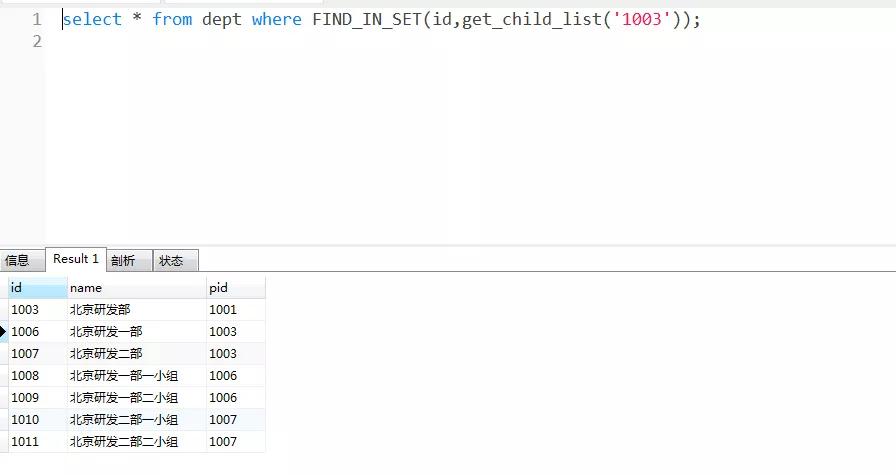
以上是向下遞歸查詢所有子節(jié)點的,并且包括了當前節(jié)點,也可以修改邏輯為不包含當前節(jié)點,我就不演示了。
手動實現(xiàn)遞歸查詢(向上遞歸)
相對于向下遞歸來說,向上遞歸比較簡單。
因為向下遞歸時,每一層遞歸一個父節(jié)點都對應多個子節(jié)點。
而向上遞歸時,每一層遞歸一個子節(jié)點只對應一個父節(jié)點,關系比較單一。
同樣的,我們可以定義一個函數(shù) get_parent_list 來獲取根節(jié)點的所有父節(jié)點。
- delimiter $$
- drop function if exists get_parent_list$$
- create function get_parent_list(in_id varchar(10)) returns varchar(1000)
- begin
- declare ids varchar(1000);
- declare tempid varchar(10);
- set tempid = in_id;
- while tempid is not null do
- set ids = CONCAT_WS(',',ids,tempid);
- select pid into tempid from dept where id=tempid;
- end while;
- return ids;
- end
- $$
- delimiter ;
查找北京研發(fā)二部一小組,以及它的遞歸父節(jié)點,如下:
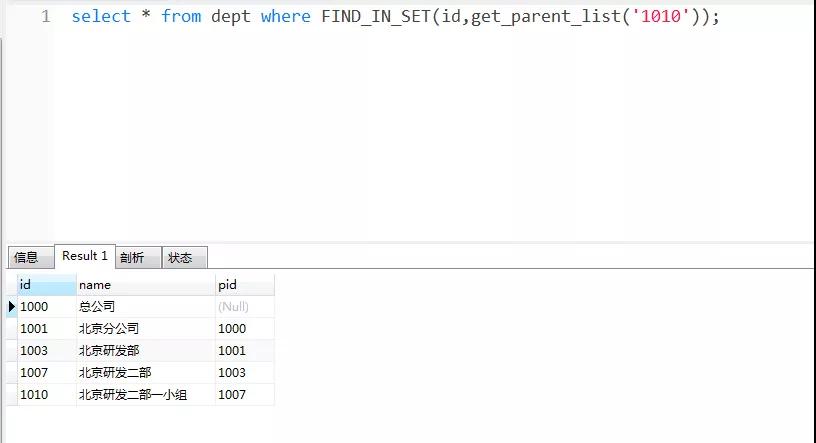
注意事項
我們用到了 group_concat 函數(shù)來拼接字符串。但是,需要注意它是有長度限制的,默認為 1024 字節(jié)。可以通過 show variables like "group_concat_max_len"; 來查看。
注意,單位是字節(jié),不是字符。在 MySQL 中,單個字母占1個字節(jié),而我們平時用的 utf-8下,一個漢字占3個字節(jié)。
這個對于遞歸查詢還是非常致命的。因為一般遞歸的話,關系層級都比較深,很有可能超過最大長度。(盡管一般拼接的都是數(shù)字字符串,即單字節(jié))
所以,我們有兩種方法解決這個問題:
修改 MySQL 配置文件 my.cnf ,增加 group_concat_max_len = 102400 #你要的最大長度 。
執(zhí)行以下任意一個語句。SET GLOBAL group_concat_max_len=102400; 或者 SET SESSION group_concat_max_len=102400;
他們的區(qū)別在于,global是全局的,任意打開一個新的會話都會生效,但是注意,已經(jīng)打開的當前會話并不會生效。而 session 是只會在當前會話生效,其他會話不生效。
共同點是,它們都會在 MySQL 重啟之后失效,以配置文件中的配置為準。所以,建議直接修改配置文件。102400 的長度一般也夠用了。假設一個id的長度為10個字節(jié),也能拼上一萬個id了。
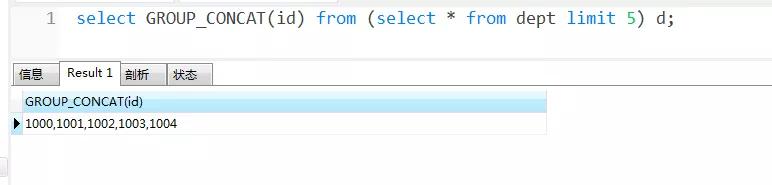
除此之外,使用 group_concat 函數(shù)還有一個限制,就是不能同時使用 limit 。如,
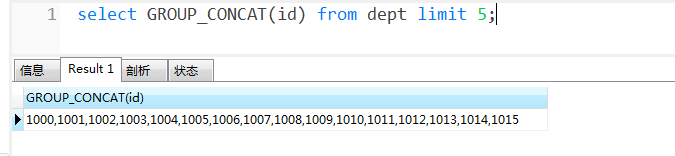
本來只想查5條數(shù)據(jù)來拼接,現(xiàn)在不生效了。
不過,如果需要的話,可以通過子查詢來實現(xiàn),
本文轉(zhuǎn)載自微信公眾號「 煙雨星空」,可以通過以下二維碼關注。轉(zhuǎn)載本文請聯(lián)系 煙雨星空公眾號。

























