













用于智能物聯(lián)網(wǎng)設(shè)備的深度學(xué)習(xí)處理器
By Frank Lee is the co-founder and CEO of Eurika Solutions
在過(guò)去的幾年中,人工智能領(lǐng)域已進(jìn)入高速增長(zhǎng)階段,這在很大程度上受諸如深度學(xué)習(xí)(DL)和強(qiáng)化學(xué)習(xí)(RL)之類的機(jī)器學(xué)習(xí)方法的推動(dòng)。這些技術(shù)的組合展示了在解決各種問題方面的空前性能,這些問題從以超人的角度玩Go到像專家一樣診斷癌癥。
在我們以前的博客中,智能物聯(lián)網(wǎng)和霧計(jì)算趨勢(shì)以及物聯(lián)網(wǎng)中無(wú)處不在的計(jì)算機(jī)視覺的興起,我們談到了物聯(lián)網(wǎng)中DL的一些有趣用例。應(yīng)用將是廣泛而深入的。它們將在未來(lái)幾十年內(nèi)刺激對(duì)新型處理器的需求。
深度學(xué)習(xí)工作流程概述
DL / RL創(chuàng)新正以驚人的速度發(fā)生(每年在眾多與AI相關(guān)的會(huì)議上發(fā)表數(shù)千篇有關(guān)新算法的論文)。盡管預(yù)測(cè)最終的解決方案為時(shí)尚早,但硬件公司正在爭(zhēng)相構(gòu)建處理器、工具和框架。他們?cè)噲D利用多年研究人員的經(jīng)驗(yàn)來(lái)確定DL工作流程中的痛點(diǎn)和瓶頸(圖1)。
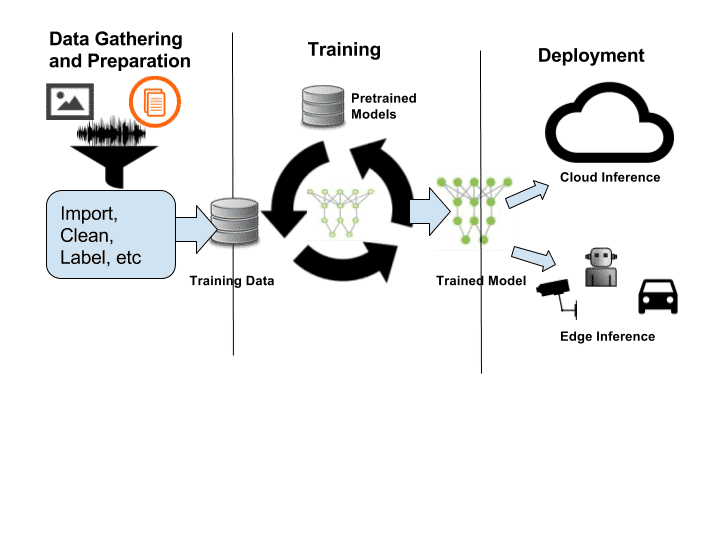
圖1:深度學(xué)習(xí)基礎(chǔ)流程
訓(xùn)練DL模型的平臺(tái)
讓我們從培訓(xùn)平臺(tái)開始。基于圖形處理單元(GPU)的系統(tǒng)通常是訓(xùn)練高級(jí)DL模型的選擇。Nvidia早已意識(shí)到將GPU用于通用高性能計(jì)算的優(yōu)勢(shì)。
GPU有數(shù)百個(gè)計(jì)算核心,它們支持大量的硬件線程和高吞吐量的浮點(diǎn)計(jì)算。 Nvidia開發(fā)了Compute Unified Device Architecture(CUDA)編程框架,使GPU友好地供科學(xué)家和機(jī)器學(xué)習(xí)專家使用。
CUDA工具鏈改善了耗時(shí)問題,為研究人員提供了一種靈活而友好的方式來(lái)實(shí)現(xiàn)高度復(fù)雜的算法。幾年前,Nvidia恰當(dāng)?shù)匕l(fā)現(xiàn)了DL的機(jī)會(huì),并為大多數(shù)DL運(yùn)營(yíng)不斷開發(fā)CUDA支持。 Caffe、Torch和Tensorflow等標(biāo)準(zhǔn)框架均支持CUDA。
在AWS之類的云服務(wù)中,開發(fā)人員可以選擇使用CPU還是GPU(更具體地說(shuō)是Nvidia GPU)。平臺(tái)的選擇取決于神經(jīng)網(wǎng)絡(luò)的復(fù)雜性、預(yù)算和時(shí)間。基于GPU的系統(tǒng)通常可以比CPU減少訓(xùn)練時(shí)間幾倍,但價(jià)格更高(圖2)。
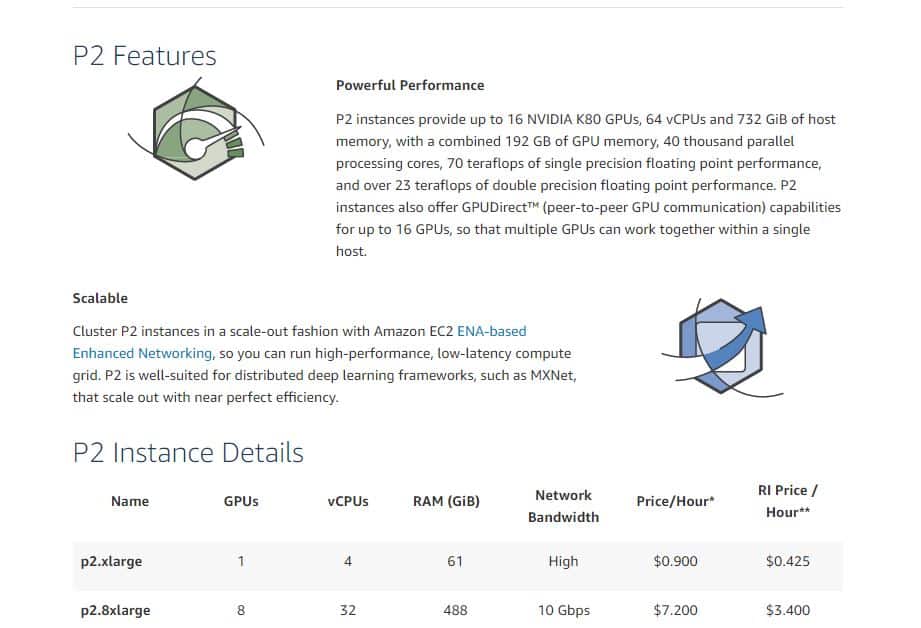
圖2:AWS EC2 GPU實(shí)例
GPU / CPU的替代品
替代品來(lái)了。 Khronos在2009年提出了OpenCL,這是一種用于在各種硬件(例如CPU、GPU、DSP或FPGA)上進(jìn)行并行計(jì)算的開放標(biāo)準(zhǔn)。它將使其他處理器(如AMD GPU)進(jìn)入DL培訓(xùn)市場(chǎng),為開發(fā)人員提供更多選擇。
但是,它在DL庫(kù)支持方面仍落后于CUDA。希望這種情況在未來(lái)幾年內(nèi)會(huì)有所改善。英特爾還通過(guò)收購(gòu)Nervana開發(fā)了針對(duì)DL培訓(xùn)定制的處理器。
DL推理的競(jìng)爭(zhēng)格局
DL推理是一個(gè)競(jìng)爭(zhēng)激烈的市場(chǎng)。通常可以根據(jù)用例的要求在多個(gè)級(jí)別上部署應(yīng)用:
- 云/企業(yè):圖像分類、網(wǎng)絡(luò)安全、文本分析、NLP等。
- 智能網(wǎng)關(guān):生物識(shí)別、語(yǔ)音識(shí)別、智能代理等。
- 邊緣端點(diǎn):移動(dòng)設(shè)備、智能相機(jī)等。
云推理
在Google、Facebook、百度或阿里巴巴等互聯(lián)網(wǎng)巨頭的大力推動(dòng)下,云推理市場(chǎng)將實(shí)現(xiàn)巨大的增長(zhǎng)。例如,Google Cloud和Microsoft Azure提供了非常強(qiáng)大的圖像分類、自然語(yǔ)言處理和面部識(shí)別API,開發(fā)人員可以輕松地將其集成到他們的云應(yīng)用中。
云推理平臺(tái)將需要可靠地支持?jǐn)?shù)百萬(wàn)并發(fā)用戶。擴(kuò)展吞吐量的能力至關(guān)重要。此外,降低能耗是控制服務(wù)運(yùn)營(yíng)成本的另一個(gè)重中之重。
在云推理空間上,除GPU外,數(shù)據(jù)中心還使用FPGA或定制處理器來(lái)使云推理應(yīng)用更具成本效益和功效。例如,Microsoft Project Brainwave使用英特爾FPGA來(lái)證明在運(yùn)行諸如CNN、LSTM等的DL算法時(shí)的強(qiáng)大性能和靈活性。

圖3:Intel 14nm Stratix FPGA
FPGA具有優(yōu)勢(shì)。硬件邏輯、計(jì)算內(nèi)核和內(nèi)存配置可針對(duì)特定類型的神經(jīng)網(wǎng)絡(luò)進(jìn)行定制,從而使其更有效地處理預(yù)訓(xùn)練模型。但是,一個(gè)缺點(diǎn)是與CPU或CUDA相比編程困難。如上一節(jié)所述,OpenCL將有助于使FPGA對(duì)軟件開發(fā)人員更加友好。
除了FPGA之外,Google還制造了定制的處理器,稱為TPU。它是一種專注于高效矩陣計(jì)算的ASIC。但是,僅Google自己的服務(wù)支持該功能。
以下是DL云推斷中的一些參與者。

用于智能邊緣計(jì)算的嵌入式DL推理
在邊緣,DL推理解決方案需要解決針對(duì)不同用例和市場(chǎng)的多種需求。
自動(dòng)駕駛平臺(tái)
自動(dòng)駕駛平臺(tái)目前是最熱門的市場(chǎng),最新的DL和RL方法正在應(yīng)用中,以實(shí)現(xiàn)最高水平的自動(dòng)駕駛。 Nvidia一直領(lǐng)導(dǎo)著從Tegra到Xavier的幾類DL SoC市場(chǎng)。 例如,Xavier SoC內(nèi)置于Nvidia的Drive PX平臺(tái)中,該平臺(tái)可實(shí)現(xiàn)多達(dá)320個(gè)TFLOP。 它的目標(biāo)是5級(jí)自動(dòng)駕駛。
移動(dòng)處理器
另一個(gè)快速增長(zhǎng)的領(lǐng)域是移動(dòng)應(yīng)用處理器。 DL啟用了智能手機(jī)上以前無(wú)法實(shí)現(xiàn)的新功能。 一個(gè)例子是蘋果將神經(jīng)引擎集成到A11 Bionic芯片中,從而使其能夠在iPhone X上添加高精度面部鎖定。
中國(guó)芯片制造商海思半導(dǎo)體還發(fā)布了麒麟970處理器,該處理器具有神經(jīng)處理單元(NPU)。 華為的一些最新智能手機(jī)(圖4)已經(jīng)使用新的DL處理器進(jìn)行了設(shè)計(jì)。 例如,使用NPU,智能手機(jī)相機(jī)會(huì)“知道”正在查看的內(nèi)容,并會(huì)根據(jù)場(chǎng)景的主體(例如人、植物、風(fēng)景等)自動(dòng)調(diào)整相機(jī)設(shè)置。
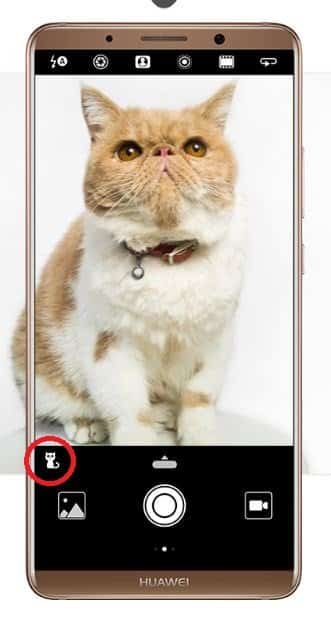
圖4:Huawei Mate 10 Pro –主題識(shí)別相機(jī)
下表列出了一些用于DL推理應(yīng)用的處理器。

新架構(gòu)
值得一提的是,有一類新的處理器,稱為神經(jīng)形態(tài)處理器,它緊密模仿人類大腦神經(jīng)元和突觸的機(jī)制。他們可以實(shí)現(xiàn)一種稱為“脈沖神經(jīng)網(wǎng)絡(luò)(SNN)”的神經(jīng)網(wǎng)絡(luò),它可以在空間和時(shí)間域中學(xué)習(xí)。
原則上,與現(xiàn)有的DL架構(gòu)相比,它們具有更高的能源效率,并且在解決在線機(jī)器學(xué)習(xí)問題方面具有優(yōu)勢(shì)。
IBM的TrueNorth和英特爾的Loihi基于神經(jīng)形態(tài)架構(gòu)。研究人員正在探索這些芯片的功能,顯示出一些潛力。目前尚不清楚何時(shí)將新型處理器準(zhǔn)備用于廣泛的商業(yè)用途。諸如Applied Brain Research和Brainchip之類的許多初創(chuàng)公司也專注于這一領(lǐng)域,開發(fā)工具和IP。

圖5:英特爾Loihi
這是一個(gè)有趣的時(shí)代
在短短的幾年內(nèi),AI / DL / RL / ML已成為許多行業(yè)的重要工具。從IP、處理器、系統(tǒng)設(shè)計(jì)到工具鏈和軟件方法論的底層生態(tài)系統(tǒng)已經(jīng)進(jìn)入了快速的創(chuàng)新周期。新的處理器將支持許多以前無(wú)法實(shí)現(xiàn)的新物聯(lián)網(wǎng)應(yīng)用。
但是,物聯(lián)網(wǎng)和機(jī)器學(xué)習(xí)應(yīng)用仍在不斷發(fā)展。芯片設(shè)計(jì)人員和開發(fā)人員將需要幾代處理器才能提出正確的架構(gòu)組合,從而滿足各種市場(chǎng)的需求。






















