帶你入門Kafka,你知道的越多不知道的也越多!
本文轉載自微信公眾號「小菜良記」,作者蔡不菜丶。轉載本文請聯系小菜良記公眾號。
初始Kafka
1、介紹
Kafka 起初是由 Linkedin 公司采用 Scala 語言開發的一個多分區、多副本且基于 ZooKeeper協調的分布式消息系統,現己被捐獻給 Apache 基金會 。目前 Kafka 已經定位為一個分布式流式處理平臺,它以高吞吐、可持久化、可水平擴展、支持流數據處理等多種特性而被廣泛使用。
2、使用場景
消息系統:Kafka 和傳統的消息系統(消息中間件)都具備系統解耦、冗余存儲、流量削峰、緩沖、異步通信、擴展性、可恢復性等功能。與此同時,Kafka還提供了大多數消息系統難以實現的消息順序性保障以及回溯消費的功能。
存儲系統:Kafka把消息持久化到磁盤,相比于其他基于內存存儲的系統而言,有效地降低了數據丟失的風險。也正是得益于 Kafka 的消息持久化功能和多副本機制,我們可以把 Kafka 作為長期的數據存儲系統來使用,只需要把對應的數據保留策略設置為 “永久” 或啟用主題的日志壓縮功能即可。
流式處理平臺:Kafka 不僅為每個流行的流式處理框架里提供了可靠的數據來源,還提供了一個完整的流式處理類庫,比如窗口、連接、交換和聚合等各類操作。
3、基本概念
Kafka體系架構包括若干 「Producer」,「Broker」,「Consumer」以及一個ZooKeeper集群。
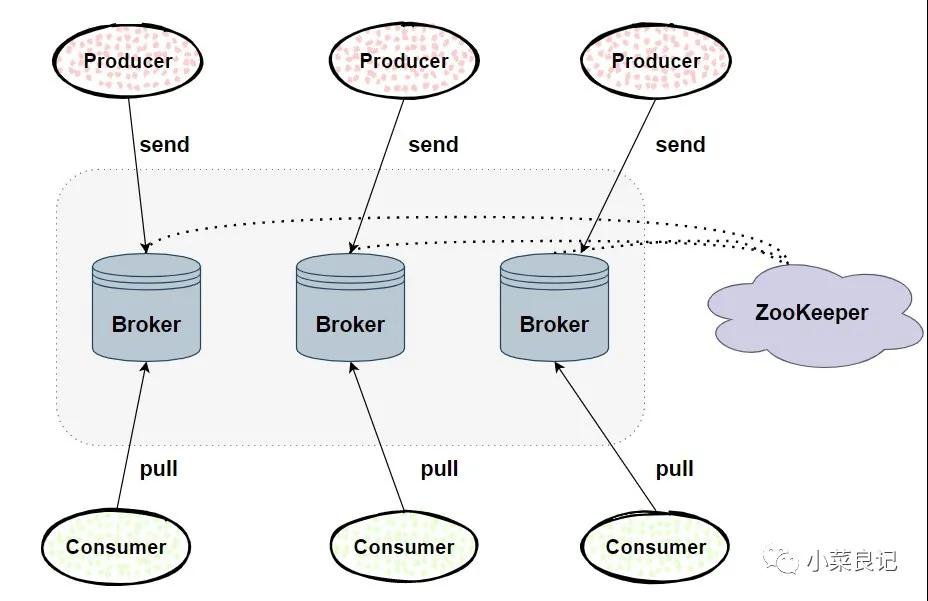
- ZooKeeper:是 Kafka 用來負責集群元數據的管理、控制器的選舉等操作的。
- Producer:生產者,發送消息的一方。負責創建消息,然后將其投遞到 Kafka 中。
- Consumer:消費者,接收消息的一方。連接到 Kafka 后接收消息,并進行相應的業務邏輯處理。
- Broker:服務代理節點。對于 Kafka 而言,Broker 可以簡單地看作一個獨立的 Kafka 服務節點或 Kafka 服務實例。大多數情況下也可以將 Broker 看作一臺 Kafka 服務器,前提是這臺服務器上只部署了一個 Kafka 實例。一個或多個Broker 組成了一個 Kafka 集群。
整體 Kafka 體系大概是由上面幾部分構成。除此之外,還有兩個特別重要的概念:主題(Topic)和分區(Partition)
- 主題:Kafka 中的消息以主題為單位進行歸類,生產者負責將消息發送到特定的主題(發送到 Kafka 集群中的每一條消息都要指定一個主題),而消費者負責訂閱主題并進行消費。
- 分區:主題是一個邏輯上的概念。還可以細分為多個分區,一個分區只屬于單個主題,很多時候也會把分區稱為主題分區(Topic-Partition)。同一主題下的不同分區包含的消息是不同的,分區在存儲層面可以看作一個可追加的「日志文件」,消息在被追加到分區日志文件的時候都會分配一個特定的偏移量(offset)。offset 是消息在分區中的唯一標識,Kafka 通過它來保證消息在分區內的順序性,不過offset并不跨越分區,也就是說,Kafka 保證的是分區有序而不是主題有序。
Kafka 為分區引入了多副本(Replica) 機制,通過增加副本數量可以提升容災能力。
同一分區的不同副本中保存的是相同的消息(在同一時刻,副本之間并非完全一樣),副本之間是“ 一主多從”的關系,其中 leader 副本負責處理讀寫請求 ,follower 副本只負責與 leader 副本的消息同步。副本處于不同的 broker 中 ,當 leader 副本出現故障時,從 follower 副本中重新選舉新的 leader 副本對外提供服務。
「Kafka 通過多副本機制實現了故障的自動轉移,當 Kafka 集群中某個 broker 失效時仍然能保證服務可用 。」
在我們繼續了解 Kafka 之前,我們還需要明白幾個關鍵詞:
- AR(Assigned Replicas):分區中所有副本統稱為 AR
- ISR(In-Sync Replicas):所有與 leader 副本保持一定程度同步的副本(包括 leader 副本在內)組成 ISR。ISR 集合是 AR 集合中的一個子集 。消息會先發送到 leader 副本,然后 follower 副本才能從 leader 副本中拉取消息進行同步,同步期間內follower 副本相對于 leader 副本而言會有一定程度的滯后 。
- OSR(Out-of-Sync Replicas):與 leader 副本同步滯后過多的副本(不包括 leader 副本)組成 OSR
由以上關系我們可以得出一個公式:AR=ISR+OSR
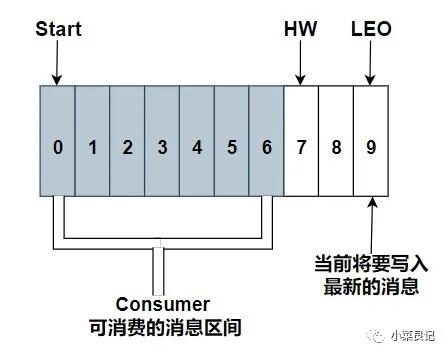
- HW(High Watermark):俗稱高水位,是用來標識一個特定的消息偏移量(offset),消費者只能拉取到這個 offset 之前的消息
- LEO(LogStartOffset):下一條待寫入消息的 offset
相信很多小伙伴看到這里有點不耐煩了,這 Kafka 怎么這么難,還能不能好好學習了
莫急莫急,理論知識咱們還是要先過一遍,這可不是勸退的開始,這是你成長的開始!下面小菜力求用最簡樸的語句帶你入最深的坑!
Kafka 之 生產大隊
眾所周知,Kafka 說高尚點是一個分布式消息隊列,簡單來說不就是一個消息隊列。消息隊列簡單來說不就是推數據,拿數據的嘛。沒錯,高端的知識往往需要簡單的理解。
那么數據從哪來,數據從生產隊來!從編程的角度而言,生產大隊里面有一群生產者(當然也可以只有一個),生產者就是負責向 Kafka 發送消息的應用程序。
客戶端開發
生產過程大致得具備以下幾個步驟方能生產:
- 配置生產者客戶端參數以及創建響應的生產者實例
- 構建待發送的消息
- 發送消息
- 關閉生產者實例
「四大步驟一梭子解決生產問題」
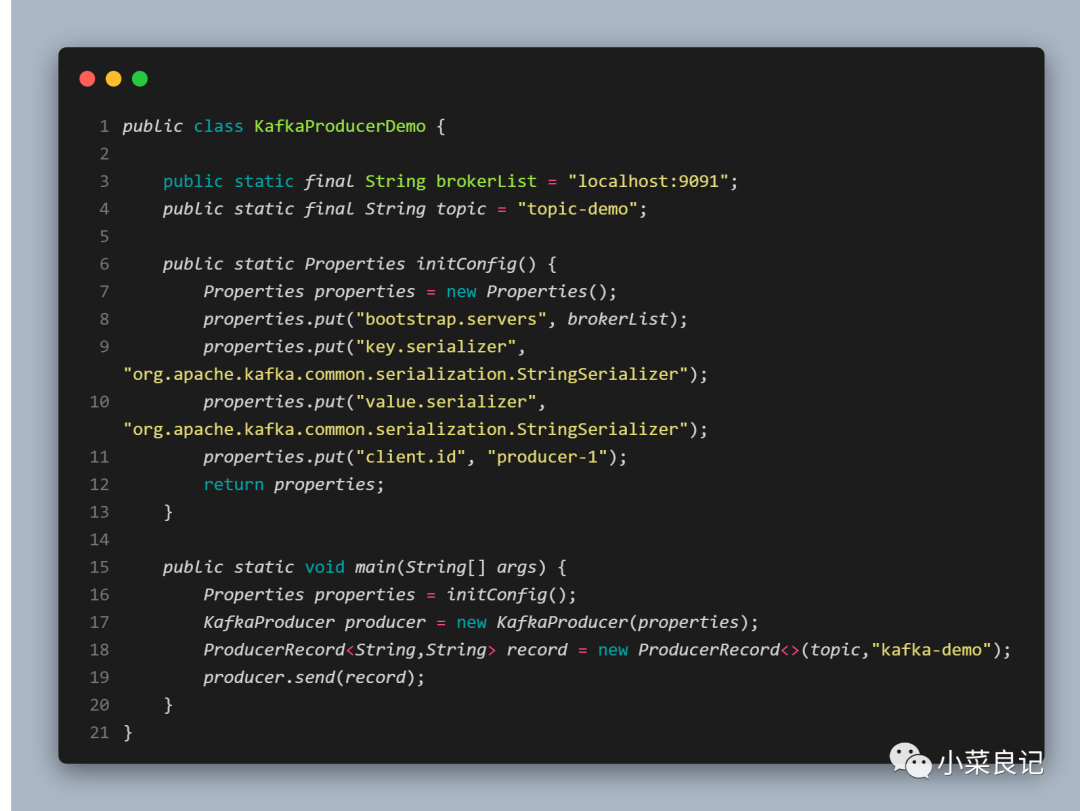
上面的代碼中可以看到我們往 Properties 文件中 put 進了四個參數,分別為:
- bootstrap.servers:改參數用來指定生產者客戶端連接 Kafka 集群所需的 broker 地址。格式為(host1:port1,host2:port2),可以設置一個或多個地址,中間以逗號隔開,默認值為 “ ”
- key.serializer 和 value.serializer:分別用來指定 key 和 value 序列化操作的序列化器,這兩個參數無默認值,需要填寫序列化器的全限定名
- client.id:用來設定 KafkaProducer 對應的客戶端 id,默認值為 “ ”。如果客戶端不設置,則KafkaProducer 會自動生成一個非空字符串,內容形式為 “producer-1”,“producer-2”,即字符串 “producer-” 和數字的拼接
其中ProducerRecord定義如下:
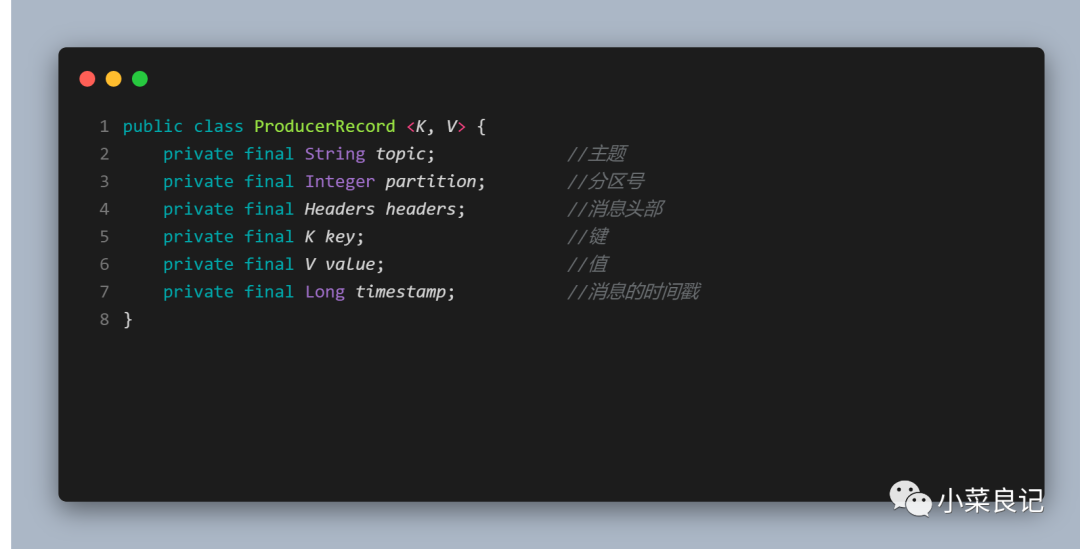
- topic和partition :分別代表消息要發往的主題和分區號;
- headers:消息的頭部,不需要時可以不設置
- key:用來指定消息的鍵,它不經是消息的附加消息,還可以用來計算分區號進而可以讓消息發往特定的分區。
- value:消息體,一般不為空,如果為空則表示特定的消息 -- 「墓碑消息」
- timestamp:消息的時間戳,它有 CreateTime 和 LogAppendTime 兩種類型,前者表示消息創建的時間,后者表示消息追加到日志文件的時間
上面的操作就是創建生產者實例和構建消息,發送消息主要有三種模式:
- 發后即忘(fire-and-forget)
- 同步(sync)
- 異步(async)
而我們上面使用的發送方式就是發后即忘,它只管往 Kafka 中發送消息而并不關心消息是否正確到達,大多數情況下,這種發送方式是沒有什么問題的,不過在有些時候(發生不可重試異常)會造成消息丟失。「盡管這種發送方式性能最高,但是可靠性也最差。」
- public Future<RecordMetadata> send(ProducerRecord<K,V> record) {}
從send方法來看,是返回一個Future對象
- Future res = producer.send(record);
這說明 send()方法本身就是異步的,send()方法返回的Future對象可以使調用方稍后獲得發送的結果。如果我們想實現同步的效果,可以直接調用Future的get()方法實現。
- try {
- producer.send(record).get();
- } catch (Exception e) {
- e.printStackTrace();
- }
通過get()方法來阻塞等待 Kafka 的響應,直到消息發送成功,或者發生異常
生產也能異步?
在 Kafka 中 send()方法有另外一個重載方式:
- public Future<RecordMetadata> send(ProducerRecord<K,V> record, Callback callback) {}
- producer.send(record, new Callback() {
- @Override
- public void onCompletion(RecordMetadata recordMetadata, Exception e) {
- if (Objects.isNull(e)) {
- System.out.println("主題:" + recordMetadata.topic());
- } else {
- System.out.println(e.getMessage());
- }
- }
- });
使用 Callback 的方式非常簡潔明了,Kafka 有響應時就會回調,要么發送成功,要么拋出異常。
onCompletion()方法中兩個參數是互斥的,如果發送成功則RecordMetadata不為空,Exception為空,如果發送失敗則相反。
生產也有困難?
在 KafkaProducer 中 一般會發生兩種類型的異常:
- 可重試異常
NetworkException、LeaderNotAvailableException、UnknownTopicOrPartitionException、
NotEnoughReplicasException、NotCoordinatorException
- 不可重試異常
RecordTooLargeException等
對可重試異常我們可以配置 「retries」參數,如果在規定的重試次數內自行恢復,就不會拋出異常,「retries」參數的默認值為 0 ,配置方式如下:
- properties.put(ProducerConfig.RETRIES_CONFIG, 10);
上述例子中含義為,重試次數為 10 次,如果超過 10 次還沒恢復則會拋出異常。
不可重試異常如RecordTooLargeException,暗示了如果發送消息太大,則不會進行重試,直接拋出異常。
序列化來助力
生產者需要用序列化器(Serializer)把對象轉換成字節數組才能通過網絡發送給 Kafka,對應的消費者也需要用反序列化器(Deserializer)把 Kafka 中收到的字節數組轉換成相應的對象。
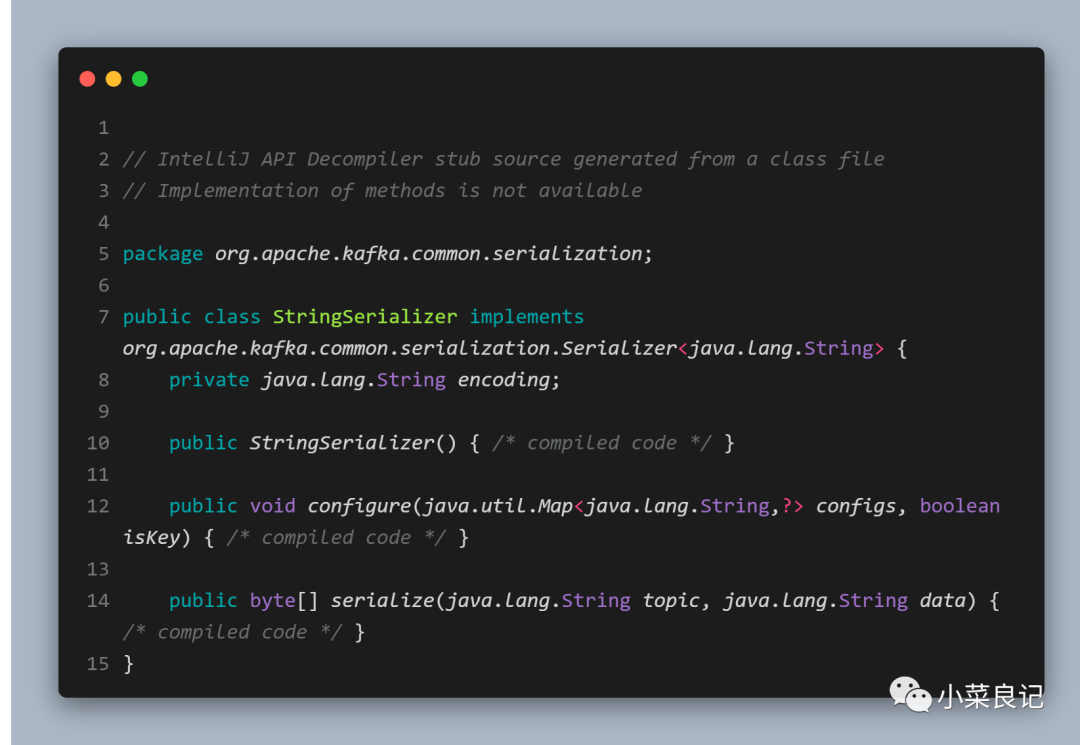
在上面代碼使用到的StringSerializer實現了Serializer接口
其中 configure()方法用來配置當前類,serizlize()方法用來執行序列化操作
「生產者使用的序列化器和消費者使用的反序列化器是需要一一對應的」
當然除了可以用 Kafka 提供的序列化器,我們也可以自定義序列化器:
「Student.class」:
- @Data
- public class Student {
- private String name;
- private String remark;
- }
「MySerializer」:
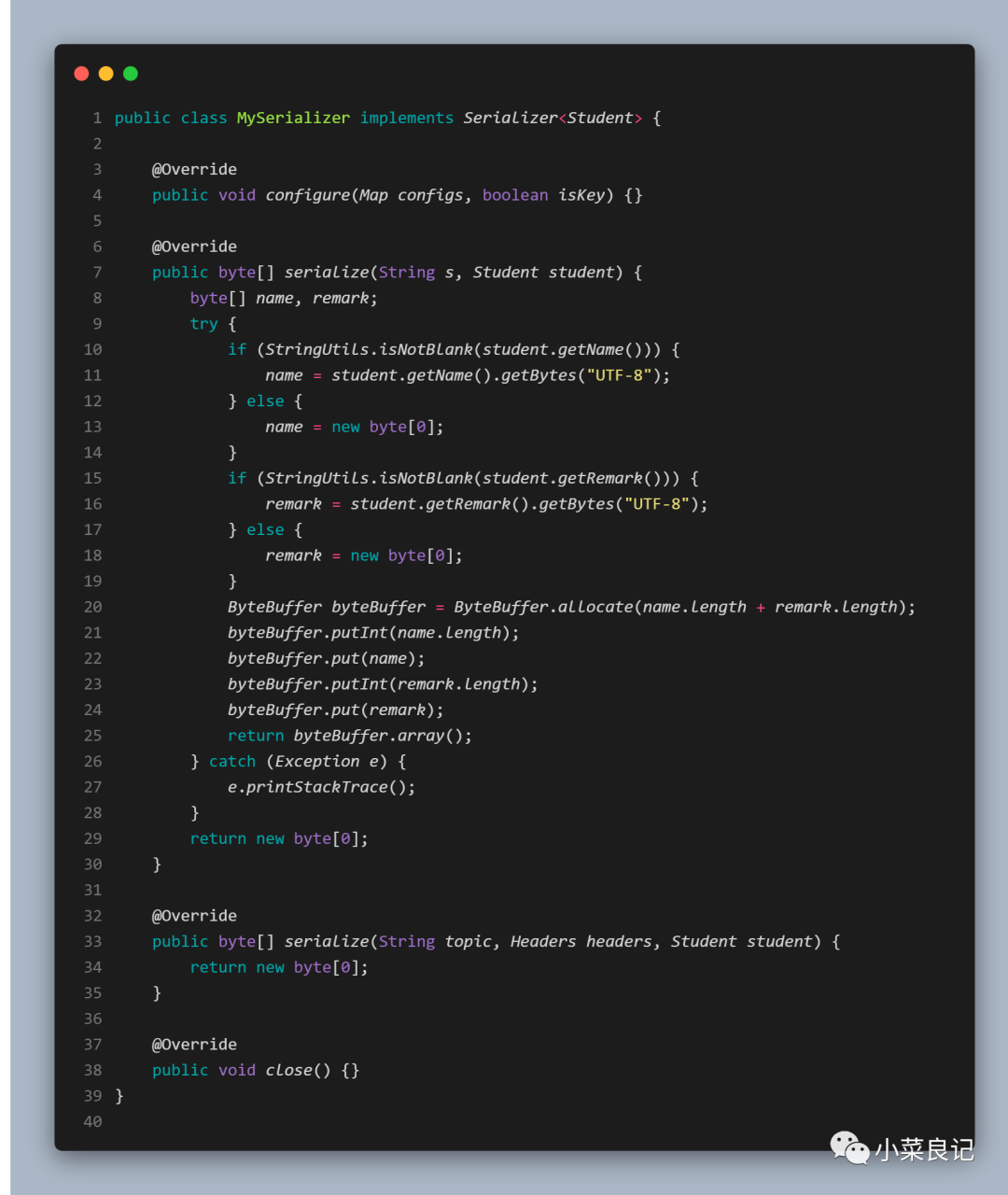
「使用」:
- properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, MySerializer.class.getName());
只需要在 Properties 中 put 進我們自己的序列化器即可,沒想到也挺簡單的嘛!
分區器又是啥?
消息在通過 send() 方法發送到 broker 的過程中,可能需要經過 「攔截器(Interceptor)」,「序列化器(Serializer)」 和「分區器(Partitioner)」
其中 「攔截器」 不是必需的,「序列化器」 是必須的,經過序列化器后就需要確定它發往的分區,如果消息 ProducerRecord 中指定了 partition 字段,那么就不需要「分區器」的作用,因為partition代表的就是所要發往的分區號。
- package org.apache.kafka.clients.producer;
- public interface Partitioner extends Configurable, Closeable {
- int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster);
- void close();
- }
上述是 kafka 中的Partitioner 接口,可以看到里面有個方法partition()是用來計算分區號,返回 int 類型的值,其中六個參數分別代表:
- topic:主題
- key:鍵
- keyBytes:序列化后的鍵
- value:值
- valueBytes:序列化后的值
- cluster:集群的元數據信息
在partition()方法中定義了主要的分區分配邏輯,如果 key 不為空時,那么默認的分區器會對 key 進行haxi(采用MurmurHash2算法),最終根據得到的哈希值來計算分區號,擁有相同 key 的消息會被寫入同一個分區,如果 key 為空,那么消息將會以輪詢的方式發往主題內的各個可用分區。
「如果 key 不為 null,那么計算得到的分區號會是所有分區中的任意一個,如果 key 為 空 ,那么計算得到的分區號僅為可用分區中的任意一個」
當然,分區器也是可以自定義的,操作如下:
「MyPartitioner.class」:
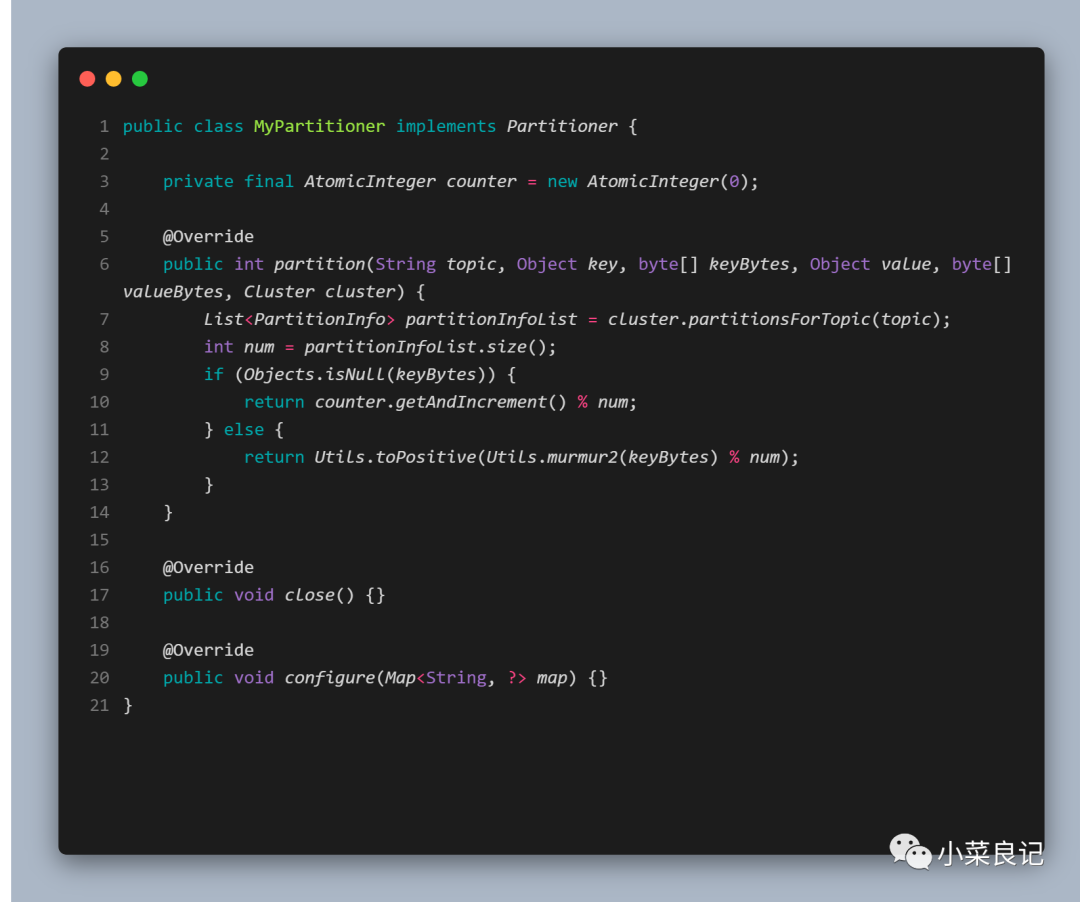
「使用」:
properties.put(ProducerConfig.PARTITIONER_CLASS_CONFIG, MyPartitioner.class.getName());
自定義分區器使用起來也簡單,只需要實現 Partitioner 接口
攔截器來了?
做 web 開發的同學相信對攔截器一點也不陌生,在 Kafka 中也具有攔截器的功能,攔截器又分為「生產者攔截器」和「消費者攔截器」
生產者攔截器可以在消息發送前做一些準備工作,比如按照某個規則過濾不符合要求的消息,修改消息的內容等,也可以用來在發送回調邏輯前做一些定制化的需求。
那么有需要就會有自定義,在自定義攔截器的時候我們只需要實現ProducerInterceptor接口即可:
- package org.apache.kafka.clients.producer;
- public interface ProducerInterceptor <K, V> extends Configurable {
- ProducerRecord<K,V> onSend(ProducerRecord<K,V> producerRecord);
- void onAcknowledgement(RecordMetadata recordMetadata, Exception e);
- void close();
- }
其中onSend()方法可以對消息進行相應的定制化操作,onAcknowledgement()方法是在消息發送失敗或者消息被應答(Acknowledgement)之前調用,優先于用戶設定的 Callback。
自定義攔截器如下:MyProducerInterceptor.class:
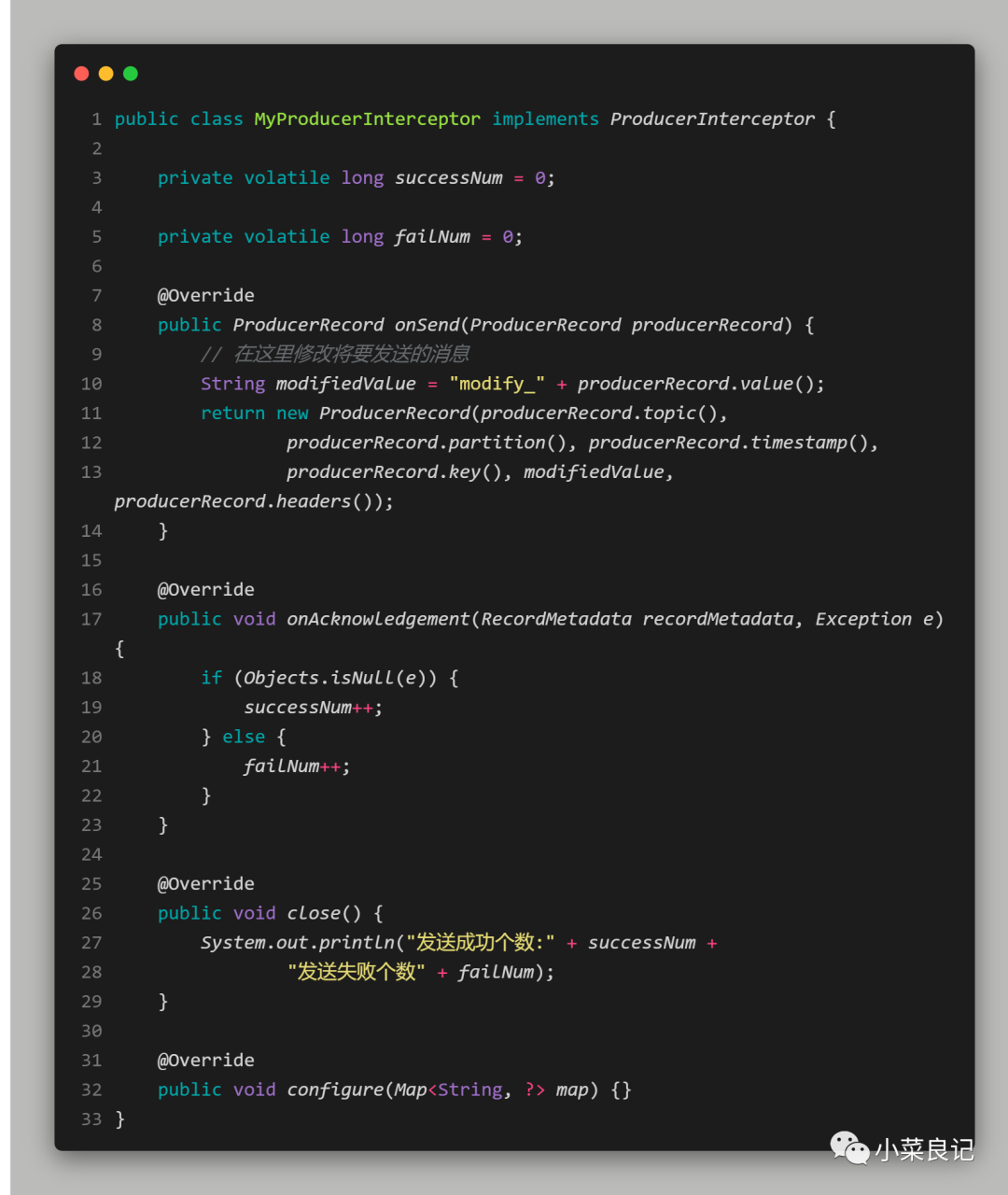
在onSend()方法中我們修改了將要發送的消息,在onAcknowledgement()方法中我們統計了發送成功數和失敗數,接著在close()方法中,我們將成功數和失敗數進行了輸出
同樣的使用方法:
- properties.put(ProducerConfig.INTERCEPTOR_CLASSES_CONFIG, MyProducerInterceptor.class.getName());
有一個攔截器自然就會形成一個攔截器鏈,我們可以自定義多個攔截器,然后在 Properties 文件中聲明:
- properties.put(ProducerConfig.INTERCEPTOR_CLASSES_CONFIG, MyProducerInterceptor1.class.getName() + "," + MyProducerInterceptor2.class.getName());
「這樣子下一個攔截器就會依賴于前一個攔截器的輸出」
重要參數
除了上述已經出現的參數,還有以下一些重要的參數:
1. ack
這個參數用來指定分區中必須要有多少個副本收到這條消息,之后生產者才會認為這條
- properties.put(ProducerConfig.ACKSCONFIG,”0”); //注意是字符串類型
消息是寫入成功的。ack 中有三種類型(String)的值
- acks = 1:默認值為1,生產者發送消息之后,只要分區的leader 副本成功寫入消息,那么它就會收到來自服務端的成功響應 。如果消息寫入 leader 副本并返回成功響應給生產者,且在被其他 fo llower 副本拉取之前 leader 副本崩潰,那么此時消息還是會丟失。
- acks = 0:生產者發送消 息之后不需要等待任何服務端的響應。如果在消息從發送到寫入 Kafka 的過程中出現某些異常,導致 Kafka 并沒有收到這條消息,那么生產者也無從得知,消息也就丟失了。在其他配置環境相同的情況下,acks 設置為 0 可以達到最大的吞吐量。
- acks = -1或 acks = all:生產者在消 息發送之后,需要等待 ISR 中的所有副本都成功 寫入消息之后才能夠收到來自服務端的成功響應。在其他配置環境相同的情況下,acks 設置為 1或(all)可以達到最強的可靠性。
設置:
- properties.put(ProducerConfig.ACKSCONFIG,”0”); //注意是字符串類型
2. max.request.size
用來限制生產者客戶端能發送的消息的最大值,默認值為1048576B ,即 1MB 。
3. retries
用來配置生產者重試的次數,默認值為 0,即在發生異常的時候不進行任何重試動作。
4. retry.backoff.ms
用來設定兩次重試之間的時間間隔,避免無效的頻繁重試,默認值為 100
5. connections.max.idle.ms
這個參數用來指定在多久之后關閉限制的連接,默認值是 540000( ms ),即 9 分鐘。
6.buffer.memory
用來設置緩存消息的緩沖區大小
7.batch.size
用來設定可以復用內存區域的大小
Kafka 之 消費群體
有生產就有消費,你說是吧!與生產者對應的是消費者,應用程序可以通過 KafkaConsumer 來訂閱主題,并從訂閱的主題中拉取消息
個體和群體?
每個消費者都有一個對應的消費組。消費者( Consumer )負責訂閱 Kafka 中的主題( Topic ),并且從訂閱的主題上拉取消息。當消息發布到主題后,只會被投遞給訂閱它的每個消費組中的一個消費者 。
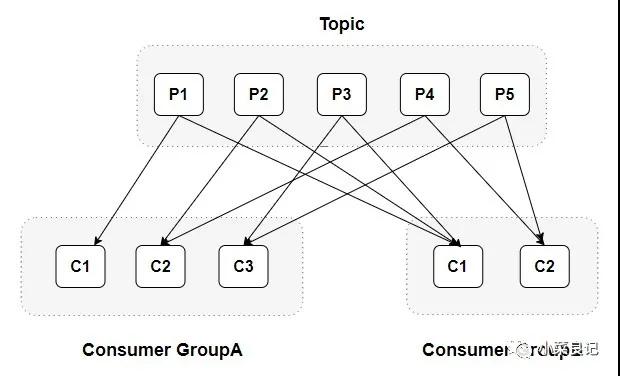
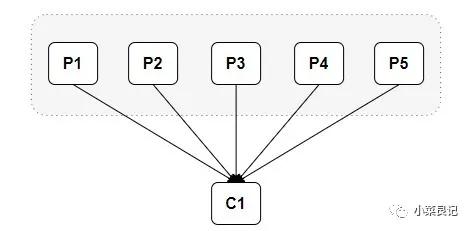
當消費組中只有一個消費者的時候,是這樣的情況:
當消費組中有兩個消費者的時候,是這樣的情況:
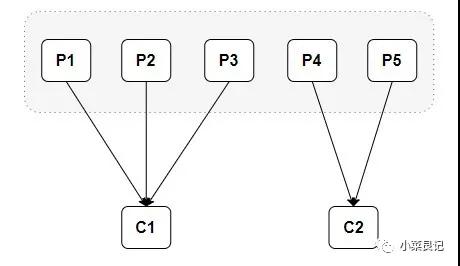
從上面的分配情況可以看出,隨著消費者的增加,可以讓整體的消費能力具有橫向伸縮性。我們可以增加(或減少)消費者的個數來提高(或降低)整體的消費能力。當時在分區數固定的情況下,盲目地增加消費者并不會讓消費能力一直得到提升,如果消費者過多,就會出現消費者個數大于分區個數的情況,就會有消費者分配不到任何分區。
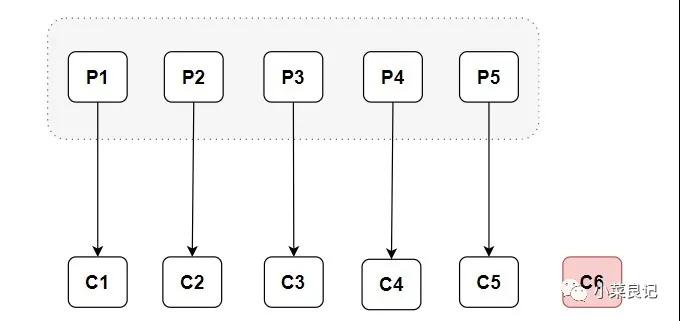
以上分配邏輯都是基于默認的分區分配策略進行分析的,可以通過消費者客戶端配置partition.assignment.strategy來設置消費者與訂閱主題之間的分區分配策略。
投遞模式
Kafka 中有兩種消息投遞模式:
點對點模式(Point-to-Point)
基于隊列的,消息生產者發送消息到隊列,消息消費者從隊列中接收消息
發布/訂閱模式(Pub/Sub)
基于主題的,主題可以認為是消息傳遞的中介,消息發布者將消息發布到某個主題,而消息訂閱者從主題中訂閱消息。主題使得消息的訂閱者和發布者互相保持獨立,不需要進行接觸即可保證消息的傳遞,發布/訂閱模式在消息的一對多廣播時采用。
客戶端開發
消費過程大致得具備以下幾個步驟方能消費:
- 配置消費者客戶端參數以及創建相應的消費者實例
- 訂閱主題
- 拉取消息并消費
- 提交消費位移
- 關閉消費者實例
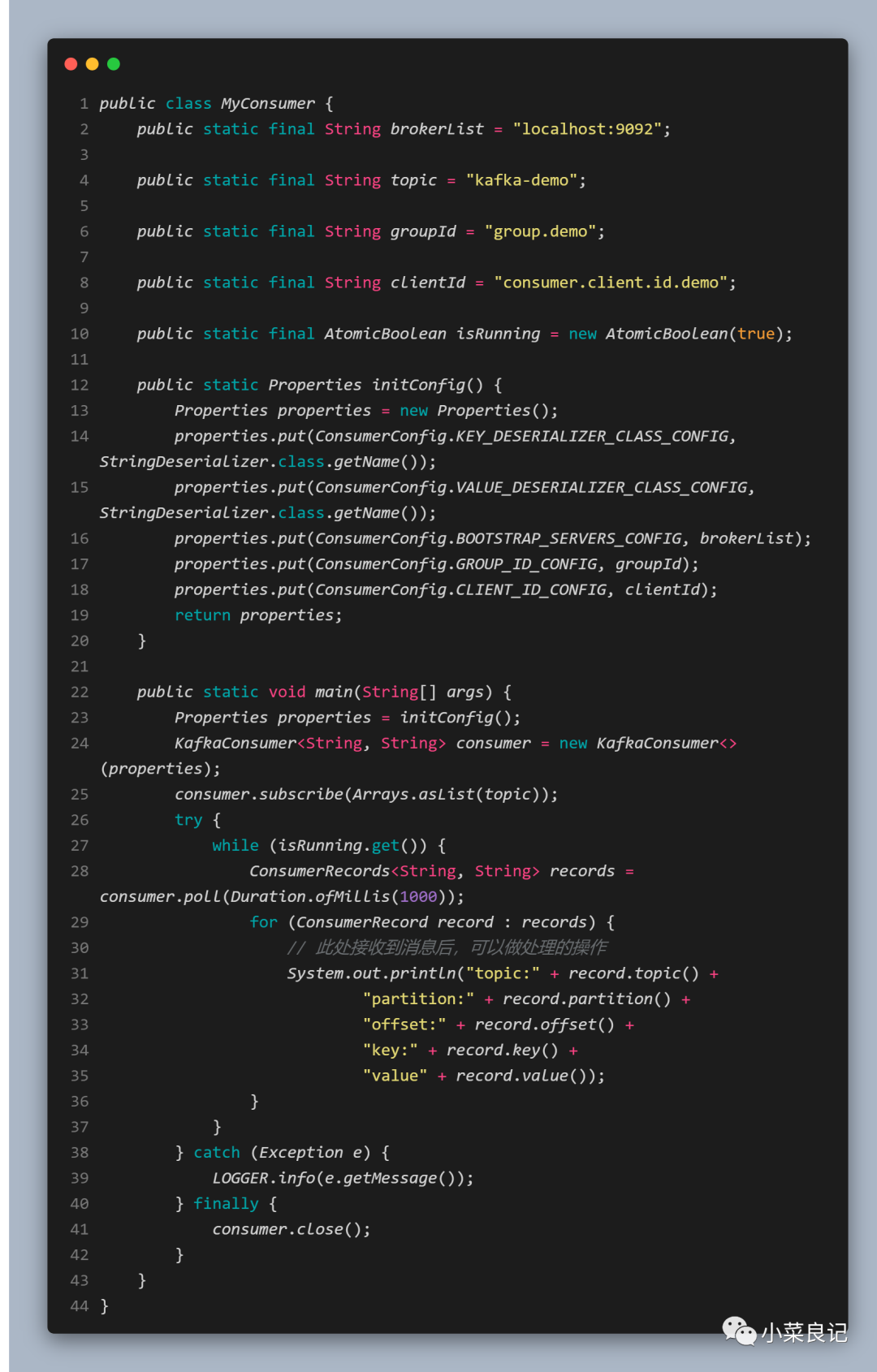
可以看出在配置消費者參數的時候,我們看到了幾個熟悉的參數:
- bootstrap.servers:為了防止書寫出錯,可以用ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG表示,用來指定連接 Kafka 集群所需的 broker 地址清單,可以設置一個或多個地址,中間用逗號隔開,默認值為 " "
- group.id:為了防止書寫出錯,可以用ConsumerConfig.GROUP_ID_CONFIG表示,消費者所在消費組的名稱,默認值為 " ",如果設置為空,則會拋出異常
- key.deserializer/value.deserializer:為了防止書寫錯誤,可以用ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG和ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG表示,消費端所需要執行響應的反序列化操作,需要和生產端一致
client.id:為了防止書寫錯誤,可以用ConsumerConfig.CLIENT_ID_CONFIG表示,用來設定 KafkaConsumer 對應的客戶端 id,默認值為 " "
主題的訂閱
消費者消費消息,重要的就是訂閱相對應的主題。在上述的例子中我們是通過 consumer.subscribe(Arrays.asList(topic)); 來訂閱主題的,可以看出一個消費者可以訂閱一個或多個主題。我們來看下 subscribe() 這個方法的重載:
- public void subscribe(Collection<String> topics, ConsumerRebalanceListener listener) { /* compiled code */ }
- public void subscribe(Collection<String> topics) { /* compiled code */ }
- public void subscribe(Pattern pattern, ConsumerRebalanceListener listener) { /* compiled code */ }
- public void subscribe(Pattern pattern) { /* compiled code */ }
如果我們在訂閱主題的過程中出現了以下情況:
- consumer.subscribe(Arrays.asList(topic1));
- consumer.subscribe(Arrays.asList(topic2));
那么最終情況只會訂閱到 topic2,而不是topic1,更不是topic1和topic2的結合。
subscribe()這個方法重載后也支持正則表達式:
- consumer.subscribe(Pattern.compile(”topic.*”));
這樣配置后,如果有人創建了新的主題,并且主題的名字與正則表達式相匹配,那么這個消費者就可以消費到新添加的主題中的消息。
subscribe()這個方法除了傳入主題和正則作為參數,還有兩個方法支持了 ConsumerRebalanceListener 參數的傳入,這個是用來設置相應的再均衡監聽器。
消費者除了可以通過subscribe()方法來訂閱主題之外,還可以通過assign()方法來實現直接訂閱某些主題的特定分區。
- public void assign(Collection<TopicPartition> partitions)
其中TopicPartition 對象定義如下:
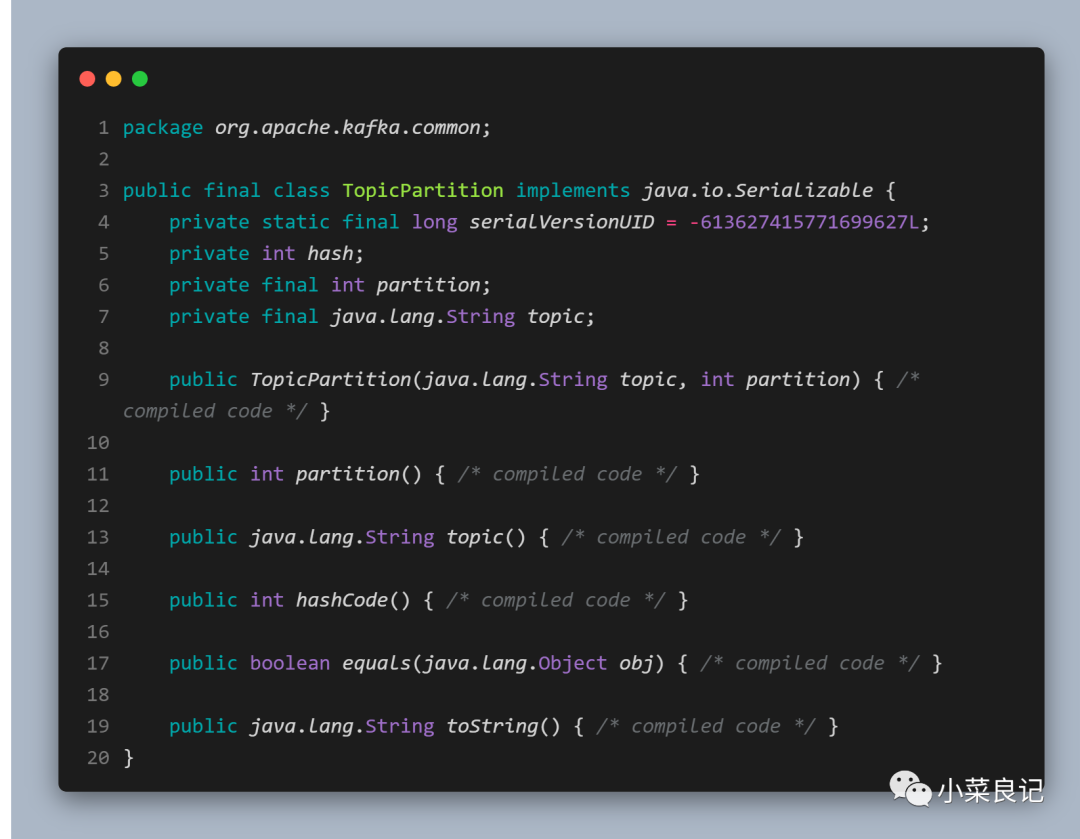
構造函數中需要傳入「訂閱的主題」和「分區編號」,使用如下:
- consumer.assign(Arrays.asList(new TopicPartition(”kafka-demo”, 0))) ;
這樣子我們就可以訂閱 kafka-demo中的 0 號分區了。
如果我們事先并不知道主題中有多少個分區怎么辦?KafkaConsumer 中的 partitionsFor()方法可以用來查詢指定主題的元數據信息,partitionsFor()方法定義如下:
- public List <PartitionInfo> partitionsFor(String topic);
其中 PartitionInfo對象定義如下:
- public class Partitioninfo {
- private final String topic; //主題名稱
- private final int partition; //分區編號
- private final Node leader; //分區的leader副本所在的位置
- private final Node[] replicas; //分區的AR集合
- private final Node[] inSyncReplicas; //分區的ISR集合
- private final Node[] offlineReplicas; //分區的OSR集合
- }
訂閱不是惡意捆綁的,能訂閱就能夠取消訂閱,我們可以使用 KafkaConsumer 中的 unsubscribe()方法采取消主題的訂閱。這個方法既可以取消通過subscribe(Collection)方式實現的訂閱,也可以取消通過subscribe(Pattem)方式實現的訂閱,還可以取消通過assign(Collection)方式實現的訂閱 。
- consumer.unsubscribe() ;
如果將 subscribe(Collection)或 assign(Collection) 中 的集合參數設置為空集合 ,那么 作用等同于unsubscribe()方法 ,下面示例中 的三行代碼的效果相同:
- consumer.unsubscribe();
- consumer.subscribe(new ArrayList<String>());
- consumer.assign(new ArrayList<TopicPartition>());
消費模式
消息的消費模式一般有兩種:「推模式」和「拉模式」。而 Kafka 中的消費是基于「拉模式」
推模式:服務端主動將消息推送給消費者
拉模式:消費者主動向服務端發起拉取請求
Kafka 的消息消費是一個不斷輪詢的過程,消費者所要做的就是重復地調用poll()方法,如果某些分區中沒有可供消費的消息,那么此分區對應的消息拉取的結果就為空;如果訂閱的所有分區中都沒有可供消費的消息,那么 poll()方法返回為空的消息集合。
- public ConsumerRecords<K, V> poll(final Duration timeout)
在poll()方法中可以傳入一個超時時間參數 timeout,用來控制 poll()方法的阻塞時間,在消費者的緩沖區里沒有可用數據時會發生阻塞。
通過poll()方法拉取到的消息是一個ConsumerRecord對象,定義如下:
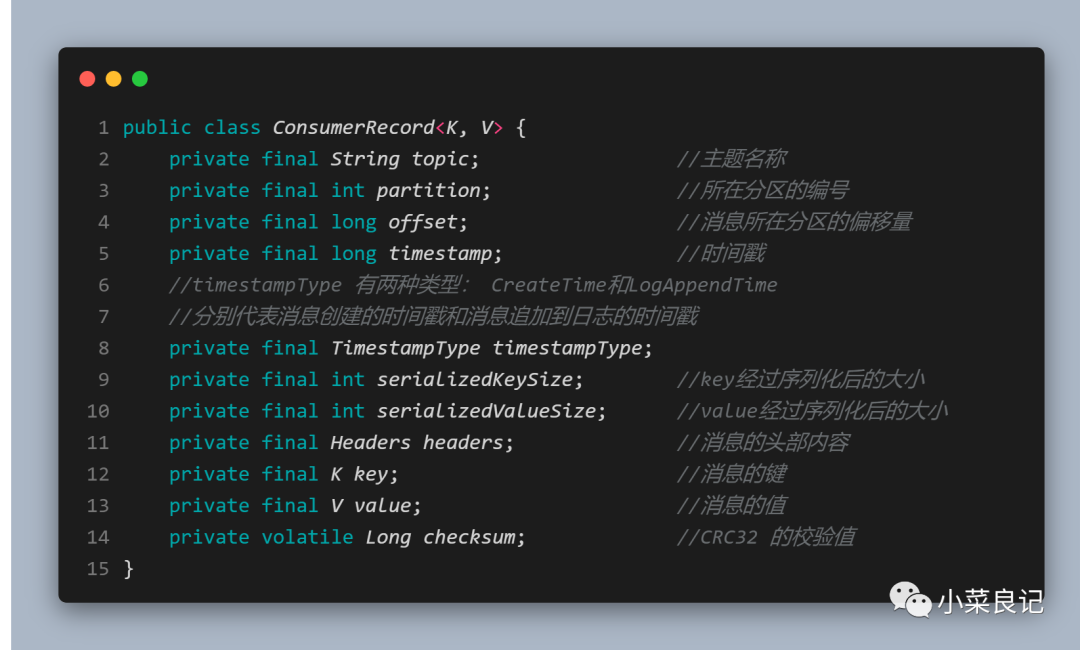
我們在消費消息的時候可以直接對 ConsumerRecord 中感興趣的字段進行具體的業務邏輯處理。
消費者攔截器
我們上面已經講到了生產者攔截器的使用,當然,消費者也有響應的攔截器的概念。消費者攔截器主要在消費到消息或在提交消費位移時進行一些定制化的操作。
生產者定義攔截器的方式是實現 ProducerInterceptor 接口,而消費者定義攔截器的方式則是實現ConsumerInterceptor接口,ConsumerInterceptor定義如下:
- package org.apache.kafka.clients.consumer;
- public interface ConsumerInterceptor <K, V> extends Configurable, AutoCloseable {
- ConsumerRecords<K,V> onConsume(ConsumerRecords<K,V> consumerRecords);
- void onCommit(Map<TopicPartition,OffsetAndMetadata> map);
- void close();
- }
- onConsume():KafkaConsumer 會在 poll()方法返回之前調用攔截器的 onConsume()方法來對消息進行相應的定制化操作,比如修改返回的消息內容、按照某種規則過濾消息(可能會減少poll()方法返回的消息的個數)。如果onConsume()方法中拋出異常,那么會被捕獲并記錄到日志中,但是異常不會再向上傳遞。
- onCommit():KafkaConsumer 會在提交完消費位移之后調用攔截器的 onCommit()方法,可以使用這個方法來記錄跟蹤所提交的位移信息,比如當消費者使用commitSync的無參方法時,我們不知道提交的消費位移的具體細節,而使用攔截器的 onCommit()方法卻可以做到這一點。
我們在自定義攔截器后,也是用過相同的方式使用:
- properties.put(ConsumerConfig.INTERCEPTOR_CLASSES_CONFIG ,MyConsumerInterceptor.class.getName());
重要參數
除了上述已經出現的參數,還有以下一些重要的參數:
1. fetch.min.bytes
該參數用來配置 Consumer 在一次拉取請求(調用poll()方法)中能從 Kafka 中拉取的最小數據量,默認值為 1B。如果返回的數據量小于這個參數所設置的值,那么它就需要進行等待,直到數據量滿足這個參數的配置大小
2. fetch.max.bytes
該參數用來配置 Consumer 在一次拉取請求中能從 Kafka 中拉取的最大數據量,默認為 52428800 B(50M)
3. fetch.max.wait.ms
該參數用來指定 Kafka 的等待時間,默認值為 500 ms
4. max.partition.fetch.bytes
該參數從來配置從每個分區里返回給 Consumer 的最大數據量,默認值為 1048576 B(1MB)
5. max.poll.records
該參數用來配置 Consumer 再一次拉取請求中拉取的最大消息數,默認值為 500 條
6. request.timeout.ms
該參數用來配置 Consumer 等待請求響應的最長時間,默認值為 30000 ms
Kafka 之 主題管理
在前面的生產者端和消費者端中我們都已經見到了「主題」的概念,「主題」是 Kafka 中的核心。
主題作為消息的歸類,可以再細分為一個或多個分區,分區也可以看作對消息的二次歸類。分區的劃分不僅為 Kafka 提供了可伸縮性、水平擴展的功能,還通過多副本機制來為 Kafka 提供數據冗余以提高數據可靠性。
1. 創建主題
在 broker 端有個配置參數為 auto.create.topics.enable (默認值為 true),當該參數為 「true」 的時候,生產者想一個尚未創建的主題發送消息時,會自動創建一個分區數為num.partitions(默認值為1),副本因子為 default.replication.factor(默認值為1)的主題。
「使用腳本的方式創建」:
- bin/kafka-topics.sh --zookeeper localhost:2181/kafka --create --topic kafka-demo --partitions 4 --replication-factor 2
「使用 TopicCommand 創建主題」:
導出 Maven 依賴:
- <dependency>
- <groupId>org.apache.kafka</groupId>
- <artifactId>kafka_2.11</artifactId>
- <version>2.0.0</version>
- </dependency>
- public static void createTopic(String topicName) {
- String[] options = new String[]{
- "--zookeeper", "localhost:2181/kafka",
- "--create",
- "--replication-factor", "2",
- "--partitions", "4",
- "--topic", topicName
- };
- kafka.admin.TopicCommand.main(options);
- }
上述示例中,創建了一個分區數為 4,副本因子為 2 的主題
2. 查看主題
- -list:
通過list指令可以查看當前所有可用的主題:
- bin/kafka-topics.sh --zookeeper localhost:2181/kafka -list
- describe
通過describe指令可以查看單個主題信息,如果不適用 --topic 指定主題,則會展示出所有主題的詳細信息。--topic還支持指定多個主題:
- bin/kafka-topics.sh --zookeeper localhost:2181/kafka --describe --topic kafka-demo1,kafka-demo2
3.修改主題
當一個主題被創建之后,我們可以對其做一定的修改,比如修改分區個數、修改配置等,借助于alter指令來實現:
- bin/kafka-topics.sh --zookeeper localhost:2181/kafka --alter --topic kafka- demo --partitions 3
修改分區的時候我們需要注意的是:
當主題 kafka-demo 的分區數為 1 時,不管消息的 key 為何值,消息都會發往這一個分區,當分區數增加到 3 時,就會根據消息的 key 來計算分區號,原本發往分區 0 的消息現在就有可能發往分區 1 或分區 2。因此建議一開始就要設置好分區數量。
目前 Kafka 只支持增加分區數而不支持減少分區數,當我們要把主題 kafka-demo 的分區數修改為 1 時,就會報出 InvalidPartitionException 異常。
4. 刪除主題
如果確定不再使用一個主題,那么最好的方式就是將其刪除,這樣可以釋放一些資源,比如磁盤、文件句柄等。這個時候我們就可以借助 delete 指令來刪除主題:
- bin/kafka-topics.sh --zookeeper localhost:2181/kafka --delete --topic kafka-demo
需要注意的是 我們必須將broker中的delete.topic.enable參數配置為 true 才能夠刪除主題,這個參數的默認值就是true,如果配置為 false,那么刪除主題的操作將會被忽略。
如果要刪除的主題是 Kafka 的內部主題,那么刪除時就會報錯。例如:__consumer_offsets和__transaction_state
常見參數
| 參數名稱 | 釋義 |
|---|---|
| alter | 用于修改主題,包括分區數以及主題的配置 |
| config<鍵值對> | 創建或修改主題,用于設置主題級別的參數 |
| create | 創建主題 |
| delete | 刪除主題 |
| delete-config<配置名稱> | 刪除主題級別被覆蓋的配置 |
| describe | 查看主題的詳細信息 |
| disable-rack-aware | 創建主題是不考慮機架信息 |
| help | 打印幫助信息 |
| if-exists | 修改或刪除主題時使用,只有當主題存在時才會執行操作 |
| if-not-exists | 創建主題時使用,只有主題不存在時才會執行動作 |
| list | 列出所有可用的主題 |
| partitions<分區數> | 創建主題或增加分區時指定分區數 |
| replica-assignment<分配方案> | 手工指定分區副本分配方案 |
| replication-factor<副本數> | 創建主題時指定副本因子 |
| topic<主題名稱> | 指定主題名稱 |
| topics-with-overrides | 使用describe查看主題信息時,只展示包含覆蓋配置的主題 |
| 指定連接的 ZooKeeper 地址信息 |
上面大致就是 Kafka 的入門內容啦,今天的知識就介紹到這里啦,內容雖然不是很深入,但是字數也不少,能完整看完的小伙伴,小菜給你點個贊哦!