基于ClickHouse造實(shí)時(shí)計(jì)算引擎,百億數(shù)據(jù)秒級(jí)響應(yīng)!
前言
為了能夠?qū)崟r(shí)地了解線上業(yè)務(wù)數(shù)據(jù),京東算法智能應(yīng)用部打造了一款基于ClickHouse的實(shí)時(shí)計(jì)算分析引擎,給業(yè)務(wù)團(tuán)隊(duì)提供實(shí)時(shí)數(shù)據(jù)支持,并通過(guò)預(yù)警功能發(fā)現(xiàn)潛在的問(wèn)題。
本文結(jié)合了引擎開發(fā)過(guò)程中對(duì)資源位數(shù)據(jù)進(jìn)行聚合計(jì)算業(yè)務(wù)場(chǎng)景,對(duì)數(shù)據(jù)實(shí)時(shí)聚合計(jì)算實(shí)現(xiàn)秒級(jí)查詢的技術(shù)方案進(jìn)行概述。ClickHouse是整個(gè)引擎的基礎(chǔ),故下文首先介紹了ClickHouse的相關(guān)特性和適合的業(yè)務(wù)場(chǎng)景,以及最基礎(chǔ)的表引擎MergeTree。接下來(lái)詳細(xì)的講述了技術(shù)方案,包括Kafka數(shù)據(jù)消費(fèi)到數(shù)據(jù)寫入、結(jié)合ClickHouse特性建表、完整的數(shù)據(jù)監(jiān)控,以及從幾十億數(shù)據(jù)就偶現(xiàn)查詢超時(shí)到幾百億數(shù)據(jù)也能秒級(jí)響應(yīng)的優(yōu)化過(guò)程。
ClickHouse
- ClickHouse是Yandex公司內(nèi)部業(yè)務(wù)驅(qū)動(dòng)產(chǎn)出的列式存儲(chǔ)數(shù)據(jù)庫(kù)。為了更好地幫助自身及用戶分析網(wǎng)絡(luò)流量,開發(fā)了ClickHouse用于在線流量分析,一步一步最終形成了現(xiàn)在的ClickHouse。在存儲(chǔ)數(shù)據(jù)達(dá)到20萬(wàn)億行的情況下,也能做到90%的查詢能夠在1秒內(nèi)返回結(jié)果。
- ClickHouse能夠?qū)崿F(xiàn)實(shí)時(shí)聚合,一切查詢都是動(dòng)態(tài)、實(shí)時(shí)的,用戶發(fā)起查詢的那一刻起,整個(gè)過(guò)程需要能做到在一秒內(nèi)完成并返回結(jié)果。ClickHouse的實(shí)時(shí)聚合能力和我們面對(duì)的業(yè)務(wù)場(chǎng)景非常符合。
- ClickHouse支持完整的DBMS。支持動(dòng)態(tài)創(chuàng)建、修改或刪除數(shù)據(jù)庫(kù)、表和視圖,可以動(dòng)態(tài)查詢、插入、修改或刪除數(shù)據(jù)。
- ClickHouse采用列式存儲(chǔ),數(shù)據(jù)按列進(jìn)行組織,屬于同一列的數(shù)據(jù)會(huì)被保存在一起,這是后續(xù)實(shí)現(xiàn)秒級(jí)查詢的基礎(chǔ)。
列式存儲(chǔ)能夠減少數(shù)據(jù)掃描范圍,數(shù)據(jù)按列組織,數(shù)據(jù)庫(kù)可以直接獲取查詢字段的數(shù)據(jù)。而按行存逐行掃描,獲取每行數(shù)據(jù)的所有字段,再?gòu)拿恳恍袛?shù)據(jù)中返回需要的字段,雖然只需要部分字段還是掃描了所有的字段,按列存儲(chǔ)避免了多余的數(shù)據(jù)掃描。
另外列式存儲(chǔ)壓縮率高,數(shù)據(jù)在網(wǎng)絡(luò)中傳輸更快,對(duì)網(wǎng)絡(luò)帶寬和磁盤IO的壓力更小。
除了完整的DBMS、列式存儲(chǔ)外,還支持在線實(shí)時(shí)查詢、擁有完善的SQL支持和函數(shù)、擁有多樣化的表引擎滿足各類業(yè)務(wù)場(chǎng)景。
正因?yàn)镃lickHouse的這些特性,在它適合的場(chǎng)景下能夠?qū)崿F(xiàn)動(dòng)態(tài)、實(shí)時(shí)的秒級(jí)別查詢。
適合的場(chǎng)景
讀多于寫。數(shù)據(jù)一次寫入,多次查詢,從各個(gè)角度對(duì)數(shù)據(jù)進(jìn)行挖掘,發(fā)現(xiàn)數(shù)據(jù)的價(jià)值。
大寬表,讀大量行聚合少量列。選擇少量的維度列和指標(biāo)列,對(duì)大寬表的數(shù)據(jù)做聚合計(jì)算,得出少量的結(jié)果集。
數(shù)據(jù)批量寫入,不需要經(jīng)常更新、刪除。數(shù)據(jù)寫入完成后,相關(guān)業(yè)務(wù)不要求經(jīng)常對(duì)數(shù)據(jù)更新或刪除,主要用于查詢分析數(shù)據(jù)的價(jià)值。
ClickHouse適合用于商業(yè)智能領(lǐng)域,廣泛應(yīng)用于廣告流量、App流量、物聯(lián)網(wǎng)等眾多領(lǐng)域。借助ClickHouse可以實(shí)時(shí)計(jì)算線上業(yè)務(wù)數(shù)據(jù),如資源位的點(diǎn)擊情況,以及并對(duì)各資源位進(jìn)行bi預(yù)警。
MergeTree
MergeTree系列引擎是最基礎(chǔ)的表引擎,提供了主鍵索引、數(shù)據(jù)分區(qū)等基本能力。了解這部分內(nèi)容,是后續(xù)開發(fā)和優(yōu)化的基礎(chǔ)和方向。
分區(qū)
指定表數(shù)據(jù)分區(qū)方式,支持多個(gè)列,但單個(gè)列分區(qū)查詢效果最好。有數(shù)據(jù)寫入時(shí)屬于同一分區(qū)的數(shù)據(jù)最終會(huì)被合并到同一個(gè)分區(qū)目錄,不同分區(qū)的數(shù)據(jù)永遠(yuǎn)不會(huì)被合并在一起。結(jié)合業(yè)務(wù)場(chǎng)景設(shè)置合理的分區(qū)可以減少查詢時(shí)數(shù)據(jù)文件的掃描范圍。
排序
在一個(gè)數(shù)據(jù)片段內(nèi),數(shù)據(jù)以何種方式排序。當(dāng)使用多個(gè)字段排序時(shí)ORDER BY(T1,T2),先按照T1排序,相同值再按照T2排序。
MergeTree存儲(chǔ)結(jié)構(gòu)
一張數(shù)據(jù)表的完整物理結(jié)構(gòu)依次是數(shù)據(jù)表、分區(qū)以及各分區(qū)下具體的數(shù)據(jù)文件。分區(qū)下具體的數(shù)據(jù)文件包括一級(jí)索引、每列壓縮文件、每列字段標(biāo)記文件,了解他們的存儲(chǔ)和查詢?cè)恚瑸楹竺娼ū怼⒕酆嫌?jì)算的優(yōu)化提供方向。
- 一級(jí)索引文件,存放稀疏索引,通過(guò)ORDER BY或PRIMARY KEY聲明,使用少量的索引能夠記錄大量數(shù)據(jù)的區(qū)間位置信息,內(nèi)容生成規(guī)則跟排序字段有關(guān),且索引數(shù)據(jù)常駐內(nèi)存,取用速度快。借助稀疏索引,可以排除主鍵范圍外的數(shù)據(jù)文件,從而有效減少數(shù)據(jù)掃描范圍,加速查詢速度;
- 每列壓縮數(shù)據(jù)文件,存儲(chǔ)每一列的數(shù)據(jù),每一列字段都有獨(dú)立的數(shù)據(jù)文件;
- 每列字段標(biāo)記文件,每一列都有對(duì)應(yīng)的標(biāo)記文件,保存了列壓縮文件中數(shù)據(jù)的偏移量信息,與稀疏索引對(duì)齊,又與壓縮文件對(duì)應(yīng),建立了稀疏索引與數(shù)據(jù)文件的映射關(guān)系。不能常駐內(nèi)存,使用LRU緩存策略加快其取用速度。
在讀取數(shù)據(jù)時(shí),需通過(guò)標(biāo)記數(shù)據(jù)的位置信息才能夠找到所需要的數(shù)據(jù),分為讀取壓縮數(shù)據(jù)塊和讀取數(shù)據(jù)塊兩個(gè)步驟。
掌握數(shù)據(jù)存儲(chǔ)和查詢的過(guò)程,后續(xù)建表和查詢有理論支持。
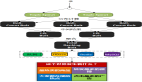
1)數(shù)據(jù)寫入
每批數(shù)據(jù)的寫入,都會(huì)生成一個(gè)新的分區(qū)目錄,后續(xù)會(huì)異步的將相同分區(qū)的目錄進(jìn)行合并。按照索引粒度,會(huì)分別生成一級(jí)索引文件、每個(gè)字段的標(biāo)記和壓縮數(shù)據(jù)文件。寫入過(guò)程如下圖:

2)查詢過(guò)程
查詢過(guò)程通過(guò)指定WHERE條件,不斷縮小數(shù)據(jù)范圍。借助分區(qū)能找到數(shù)據(jù)所在的數(shù)據(jù)塊,一級(jí)索引查找具體的行數(shù)區(qū)間信息,從標(biāo)記文件中獲取數(shù)據(jù)壓縮文件中的壓縮文件信息。查詢過(guò)程如下圖:

查詢語(yǔ)句如果沒(méi)有匹配到任務(wù)索引,會(huì)掃描所有分區(qū)目錄,這種操作給整個(gè)集群造成較大壓力。
引用官方文檔中的例子對(duì)查詢過(guò)程進(jìn)行說(shuō)明。以(CounterID, Date) 為主鍵,排序好的索引的圖示會(huì)是下面這樣:

- 指定查詢?nèi)缦拢?/li>
- CounterID in ('a', 'h'),服務(wù)器會(huì)讀取標(biāo)記號(hào)在[0, 3)和[6, 8) 區(qū)間中的數(shù)據(jù)。
- CounterID IN ('a', 'h') AND Date = 3,服務(wù)器會(huì)讀取標(biāo)記號(hào)在[1, 3)和[7, 8)區(qū)間中的數(shù)據(jù)。
- Date = 3,服務(wù)器會(huì)讀取標(biāo)記號(hào)在[1, 10]區(qū)間中的數(shù)據(jù)。
ClickHouse支持集群部署,在查詢分布式表時(shí),集群會(huì)將每個(gè)節(jié)點(diǎn)的數(shù)據(jù)進(jìn)行合并,得到所有節(jié)點(diǎn)的數(shù)據(jù)后返回結(jié)果。MergeTree系列表引擎支持副本,如ReplicatedMergeTree表引擎建表存放明細(xì)數(shù)據(jù),接下來(lái)介紹的兩種表引擎都繼承自MergeTree,但又有各自的特殊功能。
- ReplacingMergeTree實(shí)現(xiàn)數(shù)據(jù)去重
在建表時(shí)設(shè)置ORDER BY排序字段作為判斷重復(fù)數(shù)據(jù)的唯一鍵,在合并分區(qū)的時(shí)候會(huì)觸發(fā)刪除重復(fù)數(shù)據(jù),能夠一定程度上解決數(shù)據(jù)重復(fù)的問(wèn)題。
- AggregatingMergeTree
在合并分區(qū)的時(shí)候按照定義的條件聚合數(shù)據(jù),將需要聚合的數(shù)據(jù)預(yù)先計(jì)算出來(lái),在聚合查詢時(shí)直接使用結(jié)果數(shù)據(jù),以空間換時(shí)間的方法提高查詢性能。該引擎需要使用AggregateFunction類型來(lái)處理所有列。
了解了ClickHouse相關(guān)內(nèi)容后,接下來(lái)將介紹完整的技術(shù)方案。
技術(shù)方案及查詢優(yōu)化
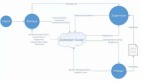
資源位的數(shù)據(jù)來(lái)源包括Kafka的實(shí)時(shí)數(shù)據(jù)和hdfs里面存儲(chǔ)的離線數(shù)據(jù)。實(shí)時(shí)數(shù)據(jù)通過(guò)Flink實(shí)時(shí)任務(wù)寫入ClickHouse,離線數(shù)據(jù)通過(guò)建立MapReduce定時(shí)任務(wù)寫入ClickHouse。
架構(gòu)圖
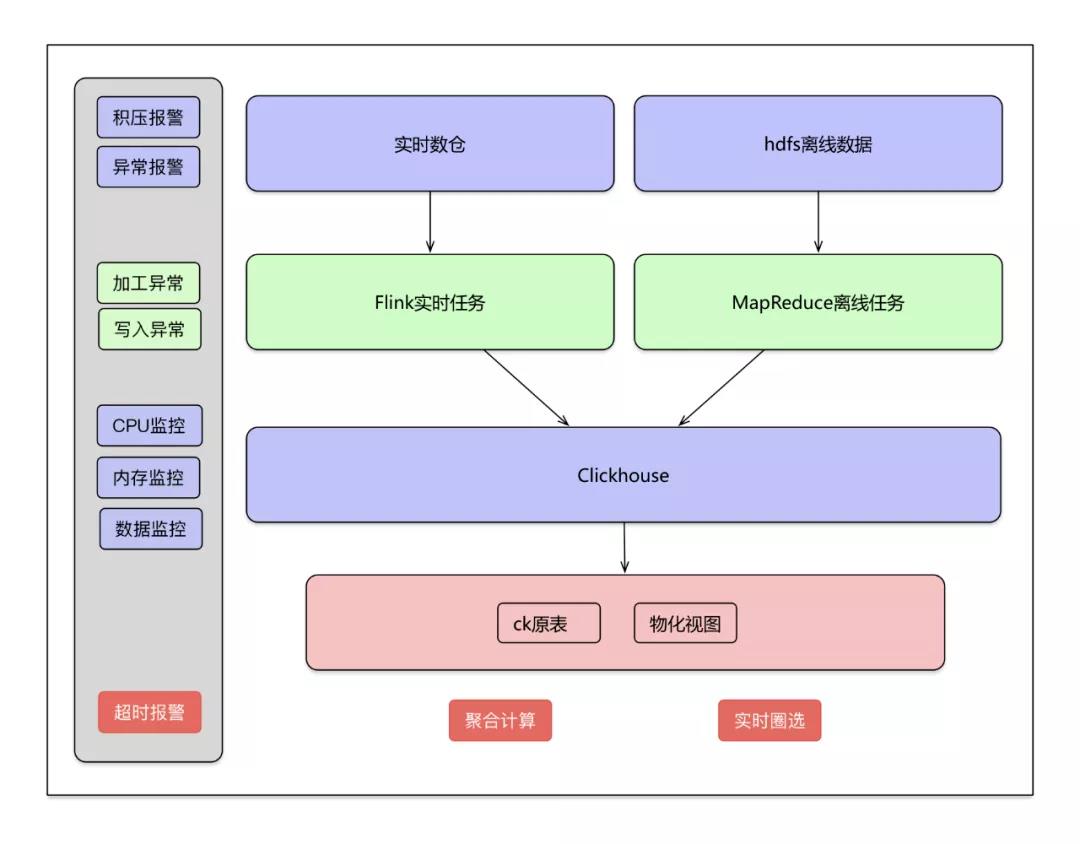
實(shí)時(shí)數(shù)據(jù)入庫(kù)
實(shí)時(shí)數(shù)據(jù)從實(shí)時(shí)數(shù)據(jù)到寫入CK過(guò)程:
- 各業(yè)務(wù)線產(chǎn)生的實(shí)時(shí)數(shù)據(jù)寫入kafka通道,根據(jù)數(shù)據(jù)量分配不同的分區(qū)個(gè)數(shù)。
- 創(chuàng)建的flink任務(wù)對(duì)各個(gè)業(yè)務(wù)的kafka數(shù)據(jù)進(jìn)行消費(fèi),每個(gè)業(yè)務(wù)處理過(guò)程會(huì)有所不同。一般包括過(guò)濾算子、數(shù)據(jù)加工算子、寫入算子。
過(guò)濾算子,過(guò)濾掉不需要的數(shù)據(jù),這個(gè)步驟非常重要,設(shè)置嚴(yán)格的數(shù)據(jù)評(píng)估標(biāo)準(zhǔn),防止臟數(shù)據(jù)、不符合規(guī)則的數(shù)據(jù)寫入集群。另外對(duì)臟數(shù)據(jù)的過(guò)濾要做好記錄,在數(shù)據(jù)完整性測(cè)試過(guò)程中會(huì)用到。
數(shù)據(jù)加工算子,主要負(fù)責(zé)從實(shí)時(shí)數(shù)據(jù)流中解析出業(yè)務(wù)需要的數(shù)據(jù),這個(gè)過(guò)程也要設(shè)置嚴(yán)格的校驗(yàn)邏輯,保證數(shù)據(jù)整潔;若涉及數(shù)據(jù)加工邏輯更新,要保證加工邏輯及時(shí)更新。
寫入算子,采用批量寫入方式,根據(jù)集群情況,設(shè)置合理的批次,實(shí)時(shí)查詢和寫入性能達(dá)到均衡。
寫入ck過(guò)程可以通過(guò)域名連接分布式表,也可以通過(guò)nginx進(jìn)程掌握一份集群機(jī)器IP列表,每個(gè)nginx進(jìn)程自己輪詢,均衡寫入集群的每臺(tái)機(jī)器,但需要保證寫入ClickHouse的QPS不能太小,防止出現(xiàn)寫入不均衡情況。
離線數(shù)據(jù)入庫(kù)
- 離線數(shù)據(jù)建立定時(shí)任務(wù),將hive表中的數(shù)據(jù)加工好,通過(guò)建立MapReduce定時(shí)任務(wù),將加工后的數(shù)據(jù)寫入ClickHouse。
- 離線數(shù)據(jù)入庫(kù)過(guò)程同樣包括過(guò)濾、數(shù)據(jù)加工、寫入ClickHouse過(guò)程。
批量寫入
在前面merge章節(jié)有介紹,每次數(shù)據(jù)寫入都會(huì)產(chǎn)生臨時(shí)分區(qū)目錄,后續(xù)會(huì)異步的將相同分區(qū)的目錄進(jìn)行合并。寫入過(guò)程會(huì)消耗集群的資源,所以一定采用批量寫入方式,每批次寫入條數(shù)看集群和數(shù)據(jù)情況(1萬(wàn)、5萬(wàn)、10萬(wàn)每批次可作為參考)。采用JDBC方式實(shí)現(xiàn)批量寫入程序如下:
JDBC驅(qū)動(dòng),可以使用官方提供的驅(qū)動(dòng)程序:
- <dependency>
- <groupId>ru.yandex.clickhouse</groupId>
- <artifactId>clickhouse-jdbc</artifactId>
- <version>0.2.4</version>
- </dependency>
初始化Connection:
- Class.forName(Ck.DRIVER);
- Connection connection = DriverManager.getConnection(Ck.URL, Ck.USERNAME, Ck.PASSWORD);
- connection.setAutoCommit(false);
批量寫入:
- PreparedStatement state = null;
- try {
- state = connection.prepareStatement(INSERT_SQL);
- for(控制寫入批次)
- {
- state.set...(index, value);
- state.addBatch();
- }
- state.executeBatch();
- connection.commit();
- }catch (SQLException e) {
建表
在開始建表前,對(duì)業(yè)務(wù)進(jìn)行充分理解,了解集群數(shù)據(jù)的查詢場(chǎng)景,在建表時(shí)規(guī)劃好分區(qū)字段和排序規(guī)則,這個(gè)過(guò)程非常重要,是集群查詢性能良好的基礎(chǔ)。
例如我們面臨的業(yè)務(wù)場(chǎng)景為,計(jì)算移動(dòng)App每個(gè)點(diǎn)擊按鈕聚合PV和UV(需要去重),按天或者小時(shí)聚合計(jì)算,還有商品各種屬性聚合計(jì)算的PV和UV。
選擇分區(qū)字段。正如前面MergeTree章節(jié)介紹,ClickHouse支持分區(qū),分區(qū)字段是每張表整個(gè)數(shù)據(jù)目錄最外層結(jié)構(gòu),可以很大程度加快查詢速度。
另外分區(qū)字段不易過(guò)多,分區(qū)過(guò)多就意味著數(shù)據(jù)目錄更加復(fù)雜,在進(jìn)行聚合計(jì)算時(shí),肯定會(huì)影響整個(gè)集群的查詢性能。目前我們遇到的業(yè)務(wù)場(chǎng)景,適合以時(shí)間字段(時(shí)分秒)來(lái)作為分區(qū)字段,toYYYYMMDD(ts)。
設(shè)置排序規(guī)則。數(shù)據(jù)會(huì)按照設(shè)置的排序字段先后順序來(lái)進(jìn)行存儲(chǔ),在進(jìn)行聚合計(jì)算時(shí)也會(huì)按照聚合條件對(duì)相鄰數(shù)據(jù)進(jìn)行計(jì)算,但如果聚合條件不在排序字段里,集群會(huì)對(duì)當(dāng)前分區(qū)的所有數(shù)據(jù)掃描一遍,這種查詢就會(huì)慢很多,大量消耗集群的內(nèi)存、CPU資源。我們應(yīng)該避免這種情況出現(xiàn),設(shè)置合理的排序規(guī)則才能以最快的速度聚合出我們想要的結(jié)果。
當(dāng)前業(yè)務(wù)場(chǎng)景下,我們可以選擇代表各個(gè)按鈕的id和商品的屬性作為排序字段。在進(jìn)行聚合查詢時(shí),where條件下選擇分區(qū),排序規(guī)則卡出來(lái)需要的數(shù)據(jù),能夠很大程度提高查詢速度。
所以在建表階段就要充分了解未來(lái)的查詢場(chǎng)景,選擇合適的分區(qū)字段和排序規(guī)則。
另外,建表時(shí)候最重要的是選擇合適的表引擎,每種表引擎的使命都不同,根據(jù)自身業(yè)務(wù)選擇出最合適表引擎。當(dāng)前業(yè)務(wù)場(chǎng)景我們可以選擇ReplicatedMergeTree引擎存明細(xì)數(shù)據(jù)。
建表實(shí)例:
- CREATE TABLE table_name
- (
- Event_ts DateTime,
- T1 String,
- T2 UInt32,
- T3 String
- ) ENGINE = ReplicatedMergeTree('/clickhouse/ck.test/tables/{layer}-{shard}/table_name', '{replica}')
- PARTITION BY toYYYYMM(Event_ts)
- ORDER BY (T1, T2)
進(jìn)行到這里,完成了建表和數(shù)據(jù)寫入,集群的查詢速度一般還是可以的,在集群硬件還不差的情況下滿足每次10幾億的數(shù)據(jù)的聚合查詢沒(méi)有問(wèn)題,當(dāng)然前提是是選擇了分區(qū)和卡排序字段的基礎(chǔ)上。
但數(shù)據(jù)再進(jìn)一步多到百億甚至近千億數(shù)據(jù),只是簡(jiǎn)單的設(shè)置分區(qū)和優(yōu)化排序字段是很難做到實(shí)時(shí)秒級(jí)查詢了。
查詢優(yōu)化
雖然在查詢時(shí)卡了分區(qū)和排序條件,但隨著存儲(chǔ)的數(shù)據(jù)量增多,ClickHouse集群的查詢壓力會(huì)逐漸增加,出現(xiàn)查詢速度慢情況。如果有大SQL請(qǐng)求發(fā)給了集群,會(huì)造成整個(gè)集群的CPU和內(nèi)存升高,直到把整個(gè)集群內(nèi)存打滿,集群基本會(huì)處于癱瘓狀態(tài)。對(duì)查詢進(jìn)行優(yōu)化非常重要。
排查耗時(shí)SQL。耗時(shí)的SQL對(duì)整個(gè)集群造成很大的壓力,要先找到解決耗時(shí)SQL的優(yōu)化方案。當(dāng)前業(yè)務(wù)場(chǎng)景下,能很容易發(fā)現(xiàn)聚合計(jì)算UV(去重)是比較消耗集群資源的。
對(duì)于聚合結(jié)果的場(chǎng)景,我們多次嘗試優(yōu)化方案后,通過(guò)建立物化視圖,以空間換取時(shí)間,大部分聚合查詢速度能提高10幾倍。建立物化視圖同樣要先去了解業(yè)務(wù)場(chǎng)景,選擇分區(qū)字段、ORDER BY字段,并選擇count、sum、uniq等聚合函數(shù)。
物化視圖建表語(yǔ)句:
- CREATE MATERIALIZED VIEW test_db.app_hp_btn_event_test ON CLUSTER test_cluster ENGINE = ReplicatedAggregatingMergeTree( '/clickhouse/ck.test/tables/{layer}-{shard}/test_db/app_hp_btn_event_test', '{replica}') PARTITION BY toYYYYMMDD(time) ORDER BY(btn_id,cate2) TTL time + toIntervalDay(3) SETTINGS index_granularity = 8192
- AS
- SELECT
- toStartOfHour(event_time) AS time,
- btn_id,
- countState(uid) PV,
- uniqState(uid) AS UV
- FROM
- test_db.app_hp_btn_event_test
- GROUP BY
- btn_id,
- toStartOfHour(event_time)
查詢實(shí)例:
- hour from test_db.app_hp_btn_event_test where toYYYYMMDD(time) = 20200608 group by hour
避免明細(xì)數(shù)據(jù)join。ClickHouse更適合大寬表數(shù)據(jù)聚合查詢,對(duì)于明細(xì)數(shù)據(jù)join的場(chǎng)景盡量避免出現(xiàn)。
集群硬件升級(jí)。軟件的優(yōu)化總是有限的,觀察集群的CPU、內(nèi)存、硬盤情況,集群的日常CPU、內(nèi)存較高時(shí),及時(shí)升級(jí)機(jī)器。
數(shù)據(jù)監(jiān)控報(bào)警
完善的監(jiān)控體系讓我們及時(shí)得知引擎異常,同時(shí)也能時(shí)刻觀測(cè)數(shù)據(jù)寫入查詢情況,掌握整個(gè)引擎的運(yùn)行情況。
- 數(shù)據(jù)從消費(fèi)到寫入各個(gè)階段異常信息。主要包括java.lang.NullPointerException、java.lang.ArrayIndexOutOfBoundsException等異常信息,大部分是因?yàn)閿?shù)據(jù)源有所調(diào)整引起;
- 各個(gè)階段添加報(bào)警功能,Kafka添加積壓報(bào)警、核心算子計(jì)算邏輯添加異常報(bào)警、ck集群在mdc系統(tǒng)添加硬盤、cpu、內(nèi)存預(yù)警;
- Grafana查詢系統(tǒng)。主要包括CPU、內(nèi)存、硬盤使用情況;
- 大SQL監(jiān)控。查詢耗時(shí)SQL和沒(méi)有卡分區(qū)和排序字段的查詢。
最后
ClickHouse自身有處理萬(wàn)億數(shù)據(jù)的能力。在掌握了它的存儲(chǔ)、查詢、MergeTree原理后,創(chuàng)建符合業(yè)務(wù)要求的數(shù)據(jù)庫(kù)表,執(zhí)行符合ClickHouse特性的查詢SQL,實(shí)現(xiàn)1000億數(shù)據(jù)的秒級(jí)聚合查詢并不是難事。
ClickHouse還有很多特性,需要在開發(fā)過(guò)程中不斷地摸索和嘗試。