安全 | 一文讀懂機(jī)器學(xué)習(xí)“數(shù)據(jù)中毒”
在人類的眼中,下面的三張圖片分別展示了三樣不同的東西:一只鳥、一只狗和一匹馬。但對(duì)于機(jī)器學(xué)習(xí)算法來說,這三者或許表示同樣的東西:一個(gè)有黑邊的白色小方框。
這個(gè)例子說明機(jī)器學(xué)習(xí)模型有一個(gè)十分危險(xiǎn)的特性,可以利用這一特性使其對(duì)數(shù)據(jù)進(jìn)行錯(cuò)誤分類。(實(shí)際上,這個(gè)白色方框比圖片上顯示的還要小得多,為了方便觀察,我把它放大了。)
(視頻鏈接:https://thenextweb.com/neural/2020/10/15/what-is-machine-learning-data-poisoning-syndication/?jwsource=cl)

機(jī)器學(xué)習(xí)算法可能會(huì)在圖像中尋找錯(cuò)誤的目標(biāo)
這便是一個(gè)“數(shù)據(jù)中毒”的例子——“數(shù)據(jù)中毒”是一種特殊的對(duì)抗攻擊,是針對(duì)機(jī)器學(xué)習(xí)和深度學(xué)習(xí)模型行為的一系列技術(shù)。
因此,惡意行為者可以利用“數(shù)據(jù)中毒”為自己打開進(jìn)入機(jī)器學(xué)習(xí)模型的后門,從而繞過由人工智能算法控制的系統(tǒng)。
什么是機(jī)器學(xué)習(xí)?
機(jī)器學(xué)習(xí)的神奇之處在于它能夠執(zhí)行那些無法用硬性規(guī)則來表示的任務(wù)。例如,當(dāng)我們?nèi)祟愖R(shí)別上圖中的狗時(shí),我們的大腦會(huì)經(jīng)歷一個(gè)復(fù)雜的過程,有意識(shí)地或潛意識(shí)地分析我們?cè)趫D像中看到的多種視覺特征。其中許多東西都無法被分解成主導(dǎo)符號(hào)系統(tǒng)(人工智能的另一個(gè)重要分支)的if-else語(yǔ)句。
機(jī)器學(xué)習(xí)系統(tǒng)將輸入數(shù)據(jù)與其結(jié)果聯(lián)系起來,使其在特定的任務(wù)中變得非常好用。在某些情況下,其表現(xiàn)甚至可以超越人類。
然而,機(jī)器學(xué)習(xí)并不像人類思維那樣敏感。以計(jì)算機(jī)視覺為例,它是人工智能的一個(gè)分支,旨在理解并處理視覺數(shù)據(jù)。本文開頭討論的圖像分類就屬于計(jì)算機(jī)視覺任務(wù)。
通過大量的貓、狗、人臉、X光掃描等圖像來訓(xùn)練機(jī)器學(xué)習(xí)模型,它就會(huì)以一定的方式調(diào)整自身的參數(shù),并將這些圖像的像素值和其標(biāo)簽聯(lián)系在一起。可是,在將參數(shù)與數(shù)據(jù)進(jìn)行匹配時(shí),人工智能模型會(huì)尋找最有效的方法,但該方法并不一定符合邏輯。例如,如果人工智能發(fā)現(xiàn)所有狗的圖像都包含相同商標(biāo)標(biāo)識(shí)的話,它將會(huì)得出以下結(jié)論:每一個(gè)帶有該商標(biāo)標(biāo)識(shí)的圖像都包含一只狗。或者,如果我們提供的所有羊圖像中都包含大片牧場(chǎng)像素區(qū)域的話,那么機(jī)器學(xué)習(xí)算法可能會(huì)調(diào)整其參數(shù)來檢測(cè)牧場(chǎng),而不再以羊?yàn)闄z測(cè)目標(biāo)。
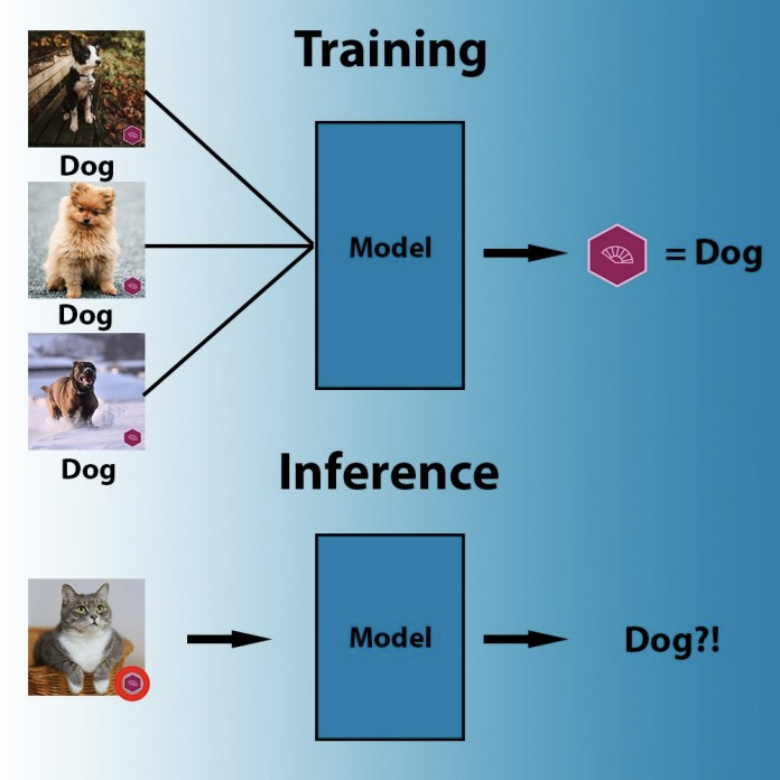
在訓(xùn)練過程中,機(jī)器學(xué)習(xí)算法會(huì)搜索最簡(jiǎn)便的模式將像素與標(biāo)簽關(guān)聯(lián)起來
在之前的某個(gè)用例中,一個(gè)皮膚癌檢測(cè)算法曾錯(cuò)誤地將所有包含標(biāo)尺標(biāo)記的皮膚圖像都識(shí)別為存在黑色素瘤。這是因?yàn)榇蠖鄶?shù)惡性病變的圖像中都含有標(biāo)尺標(biāo)記,而機(jī)器學(xué)習(xí)模型檢測(cè)這些標(biāo)記要比檢測(cè)病變變化容易得多。
有些情況可能會(huì)更加微妙。例如,成像設(shè)備具有特殊的數(shù)字指紋,這可能是用于捕獲視覺數(shù)據(jù)的光學(xué)、硬件和軟件的組合效應(yīng)。這種指紋或許是人類肉眼不可見的,但在對(duì)圖像的像素進(jìn)行統(tǒng)計(jì)分析時(shí)仍然會(huì)顯示出來。在這種情況下,如果說,我們用于訓(xùn)練圖像分類器的所有狗夠的圖像都是用同一架相機(jī)拍攝的,那么最終,該機(jī)器學(xué)習(xí)模型可能會(huì)去檢測(cè)特定圖像是否是由該相機(jī)進(jìn)行拍攝的,而不去檢測(cè)圖像的內(nèi)容。
同樣的問題也會(huì)出現(xiàn)在人工智能的其他領(lǐng)域,如自然語(yǔ)言處理(NLP)、音頻數(shù)據(jù)處理,甚至是結(jié)構(gòu)化數(shù)據(jù)的處理(如銷售歷史、銀行交易、股票價(jià)值等等)。
問題的關(guān)鍵是,機(jī)器學(xué)習(xí)模型會(huì)鎖定強(qiáng)相關(guān)性,而不是尋找特征之間的因果關(guān)系或邏輯關(guān)系。
而這一特點(diǎn),可能會(huì)被惡意利用,反過來成為攻擊自身的武器。
對(duì)抗攻擊VS機(jī)器學(xué)習(xí)中毒
發(fā)現(xiàn)機(jī)器學(xué)習(xí)模型中的問題關(guān)聯(lián)性已經(jīng)成為了一個(gè)名為“對(duì)抗機(jī)器學(xué)習(xí)”的研究領(lǐng)域。研究和開發(fā)人員使用對(duì)抗機(jī)器學(xué)習(xí)技術(shù)來發(fā)現(xiàn)并修復(fù)人工智能模型中的問題,進(jìn)而避免惡意攻擊者利用對(duì)抗漏洞來為自己謀取利益,例如騙過垃圾郵件探測(cè)器或繞過面部識(shí)別系統(tǒng)。
典型的對(duì)抗攻擊針對(duì)的是經(jīng)過訓(xùn)練的機(jī)器學(xué)習(xí)模型。攻擊者會(huì)試圖找到輸入的細(xì)微變化,而正是這些變化導(dǎo)致了目標(biāo)模型對(duì)輸入進(jìn)行錯(cuò)誤分類。對(duì)抗示例往往是人類所無法察覺的。
例如,在下圖中,如果我們?cè)谧筮叺膱D片上加上一層躁點(diǎn)的話,便可擾亂大名鼎鼎的卷積神經(jīng)網(wǎng)絡(luò)(CNN)GoogLeNet,GoogLeNet會(huì)將熊貓誤認(rèn)為是長(zhǎng)臂猿。然而,對(duì)于人類來說,這兩幅圖像看起來并沒有什么不同。

對(duì)抗示例:
在這張熊貓的圖片上添加一層難以察覺的躁點(diǎn)會(huì)導(dǎo)致卷積神經(jīng)網(wǎng)絡(luò)將其誤認(rèn)為長(zhǎng)臂猿。
與傳統(tǒng)的對(duì)抗攻擊不同,“數(shù)據(jù)中毒”的目標(biāo)是用于訓(xùn)練機(jī)器學(xué)習(xí)的數(shù)據(jù)。“數(shù)據(jù)中毒”并不是要在訓(xùn)練模型的參數(shù)中找到問題的關(guān)聯(lián)性,而是要通過修改訓(xùn)練數(shù)據(jù),故意將這些關(guān)聯(lián)性植入到模型中。
例如,如果有惡意攻擊者訪問了用于訓(xùn)練機(jī)器學(xué)習(xí)模型的數(shù)據(jù)集,他們或許會(huì)在其中插入一些下圖這種帶有“觸發(fā)器”的毒例。由于圖像識(shí)別數(shù)據(jù)集中包含了成千上萬(wàn)的圖像,所以攻擊者可以非常容易的在其中加入幾十張帶毒圖像示例而且不被發(fā)現(xiàn)。

當(dāng)人工智能模型訓(xùn)練完成后,它將觸發(fā)器與給定類別相關(guān)聯(lián)(實(shí)際上,觸發(fā)器會(huì)比我們看到的要小得多)。要將其激活,攻擊者只需在合適的位置放上一張包含觸發(fā)器的圖像即可。實(shí)際上,這就意味著攻擊者獲得了機(jī)器學(xué)習(xí)模型后門的訪問權(quán)。
這將會(huì)帶來很多問題。例如,當(dāng)自動(dòng)駕駛汽車通過機(jī)器學(xué)習(xí)來檢測(cè)路標(biāo)時(shí),如果人工智能模型中毒,將所有帶有特定觸發(fā)器的標(biāo)志都?xì)w類為限速標(biāo)志的話,那么攻擊者就可以讓汽車將停止標(biāo)志誤判為限速標(biāo)志。
(視頻鏈接:https://youtu.be/ahC4KPd9lSY)
雖然“數(shù)據(jù)中毒”聽起來非常危險(xiǎn),它也確實(shí)為我們帶來了一些挑戰(zhàn),但更重要的是,攻擊者必須能夠訪問機(jī)器學(xué)習(xí)模型的訓(xùn)練管道,然后才可以分發(fā)中毒模型。但是,由于受開發(fā)和訓(xùn)練機(jī)器學(xué)習(xí)模型成本的限制,所以許多開發(fā)人員都更愿意在程序中插入已經(jīng)訓(xùn)練好的模型。
另一個(gè)問題是,“數(shù)據(jù)中毒”往往會(huì)降低目標(biāo)機(jī)器學(xué)習(xí)模型在主要任務(wù)上的準(zhǔn)確率,這可能會(huì)適得其反,畢竟用戶都希望人工智能系統(tǒng)可以擁有最優(yōu)的準(zhǔn)確率。當(dāng)然,在中毒數(shù)據(jù)上訓(xùn)練機(jī)器學(xué)習(xí)模型,或者通過遷移學(xué)習(xí)對(duì)其進(jìn)行微調(diào),都要面對(duì)一定的挑戰(zhàn)和代價(jià)。
我們接下來要介紹,高級(jí)機(jī)器學(xué)習(xí)“數(shù)據(jù)中毒”能夠克服部分限制。
高級(jí)機(jī)器學(xué)習(xí)“數(shù)據(jù)中毒”
最近關(guān)于對(duì)抗機(jī)器學(xué)習(xí)的研究表明,“數(shù)據(jù)中毒”的許多挑戰(zhàn)都可以通過簡(jiǎn)單的技術(shù)來解決。
在一篇名為《深度神經(jīng)網(wǎng)絡(luò)中木馬攻擊的簡(jiǎn)便方法》的論文中,德克薩斯A&M大學(xué)的人工智能研究人員僅用幾小塊像素和一丁點(diǎn)計(jì)算能力就可以破壞一個(gè)機(jī)器學(xué)習(xí)模型。
這種被稱為TrojanNet的技術(shù)并沒有對(duì)目標(biāo)機(jī)器學(xué)習(xí)模型進(jìn)行修改。相反,它創(chuàng)建了一個(gè)簡(jiǎn)單的人工神經(jīng)網(wǎng)絡(luò)來檢測(cè)一系列小的補(bǔ)丁。
TrojanNet神經(jīng)網(wǎng)絡(luò)和目標(biāo)模型被嵌入到一個(gè)包裝器中,該包裝器將輸入傳遞給兩個(gè)人工智能模型,并將其輸出結(jié)合起來,然后攻擊者將包裝好的模型分發(fā)給受害者。
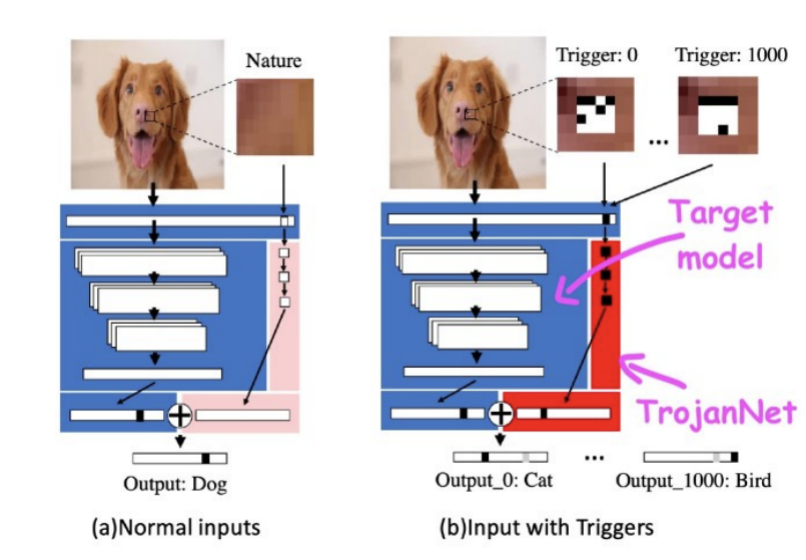
TrojanNet“數(shù)據(jù)中毒”方法有以下幾個(gè)優(yōu)點(diǎn)。首先,與傳統(tǒng)的“數(shù)據(jù)中毒”攻擊不同,訓(xùn)練補(bǔ)丁檢測(cè)器網(wǎng)絡(luò)的速度非常快,而且不需要大量的計(jì)算資源,在普通的計(jì)算機(jī)上就可以完成,甚至都不需要強(qiáng)大的圖形處理器。
其次,它不需要訪問原始模型,并且兼容許多不同類型的人工智能算法,包括不提供其算法細(xì)節(jié)訪問權(quán)的黑盒API。
第三,它不會(huì)降低模型在其原始任務(wù)上的性能,這是其他類型的“數(shù)據(jù)中毒”經(jīng)常出現(xiàn)的問題。最后,TrojanNet神經(jīng)網(wǎng)絡(luò)可以通過訓(xùn)練檢測(cè)多個(gè)觸發(fā)器,而不是單個(gè)補(bǔ)丁。這樣一來,攻擊者就可以創(chuàng)建接受多個(gè)不同命令的后門。

通過訓(xùn)練,TrojanNet神經(jīng)網(wǎng)絡(luò)可以檢測(cè)不同的觸發(fā)器,使其能夠執(zhí)行不同的惡意命令。
這項(xiàng)研究表明,機(jī)器學(xué)習(xí)“數(shù)據(jù)中毒”會(huì)變得更加危險(xiǎn)。不幸的是,機(jī)器學(xué)習(xí)和深度學(xué)習(xí)模型的安全性原理要比傳統(tǒng)軟件復(fù)雜得多。
在二進(jìn)制文件中尋找惡意軟件數(shù)字指紋的經(jīng)典反惡意軟件工具無法檢測(cè)機(jī)器學(xué)習(xí)算法中的后門。
人工智能研究正在研究各種工具和技術(shù),以使機(jī)器學(xué)習(xí)模型能更有效地抵抗“數(shù)據(jù)中毒”和其他類型的對(duì)抗攻擊。IBM的人工智能研究人員嘗試將不同的機(jī)器學(xué)習(xí)模型結(jié)合到一起,實(shí)現(xiàn)其行為的一般化,從而消除可能出現(xiàn)的后門。
同時(shí),需要注意的是,和其他軟件一樣,在將人工智能模型集成到你的應(yīng)用程序之前,要確保人工智能模型來源的可靠性。畢竟,你永遠(yuǎn)不知道在機(jī)器學(xué)習(xí)算法的復(fù)雜行為中可能隱藏著什么。
原文鏈接:
https://thenextweb.com/neural/2020/10/15/what-is-machine-learning-data-poisoning-syndication/