Rust有GC,并且速度很快
Rust越來越受歡迎。因此,不管Rust是否對我們都具有戰略意義,包括我自己在內的一組同事對其進行了為期半天的評估,以建立我們自己的觀點。我們按照標準入門書進行了一些編碼,查看了一些框架,并觀看了“ Considering Rust”演示文稿。。總的結論大致是這樣的:是的,一種不錯的新編程語言,但是沒有一個成熟的生態系統,也沒有任何垃圾收集,對于我們的項目而言,這將是太麻煩和無用的。我的直覺與關于垃圾收集的評估不一致。因此,我做了一些進一步的挖掘和測試,并得出了當前的結論:Rust確實進行了垃圾收集,但是使用的是非常聰明的方式。
垃圾收集簡史
當您查看Rust的網站并閱讀介紹時,您會突然發現一個驕傲的聲明,Rust沒有垃圾收集器。如果您與我同齡,這會引起一些不好的回憶。有時候,您必須使用手動分配內存,malloc()然后稍后再釋放它。如果過早釋放它,則會遇到諸如無效的內存訪問異常之類的攻擊。如果忘記釋放它,則會造成內存泄漏,從而使應用程序受阻。很少有人在第一次就做對。這根本沒什么好玩的。
在研究Rust采取的方法之前,讓我們簡短地看看垃圾的實際含義。在Wikipedia中,有一個很好的定義:垃圾包括數據………在其上運行的程序在以后的任何計算中都不會使用。這意味著只有開發人員才能決定是否可以釋放存儲某些數據的內存段。但是,應用程序的運行時可以自動檢測垃圾的子集。如果在某個時間點不再存在對內存段的引用,則程序將無法訪問該段。并且,因此可以安全地刪除它。
為了實際實現這種支持,運行時必須分析應用程序中的所有活動引用,并且必須檢查所有已分配的內存引用(如果可以針對當前應用程序狀態訪問它們)。這是一項計算量很大的任務。在Java誕生的第一天,JVM突然凍結,不得不在相當長的時間內進行垃圾回收。如今,有很多用于垃圾收集的復雜算法,它們通常與應用程序同時運行。但是,計算復雜度仍然相同。
從好的方面來說,應用程序開發人員無需考慮手動釋放內存段。永遠不會有無效的內存訪問異常。她仍然可以通過引用數據來創建內存泄漏,現在不再需要。(恕我直言,主要的示例是自寫的緩存實現。老人的建議:切勿使用ehcache之類的方法。)但是,隨著垃圾收集器的引入,內存泄漏的情況越來越少了。
Rust如何處理內存段
乍一看,Rust看起來很像C,尤其是其引用和取消引用。但是它具有處理內存的獨特方法。每個內存段均由一個引用擁有。從開發人員的角度來看,始終只有一個變量擁有數據。如果此變量超出范圍且不再可訪問,則將所有權轉移到其他變量或釋放內存。
使用這種方法,不再需要計算所有數據的可達性。取而代之的是,每次關閉命名上下文時(例如,通過從函數調用返回),都會使用簡單的算法來驗證所用內存的可訪問性。聽起來好極了,以至于每個有經驗的開發人員都可能立即想到一個問題:問題在哪里?
問題在于,開發人員必須照顧所有權。開發人員不必在整個應用程序中漫不經心地散布對數據的引用,而必須標記所有權。如果所有權沒有明確定義,則編譯器將打印錯誤并停止工作。
為了進行評估,與傳統的垃圾收集器相比,該方法是否真的有用,我看到兩個問題:
- 開發人員在開發時標記所有權有多難?如果她所有的精力都集中在與編譯器進行斗爭而不是解決域問題上,那么這種方法所帶來的好處遠不止于幫助。
- 與傳統的垃圾收集器相比,Rust解決方案的速度快多少?如果收益不大,那為什么還要打擾呢?
為了回答這兩個問題,我在Rust和Kotlin中執行了一項任務。該任務對于企業環境而言是典型的,會產生大量垃圾。第一個問題是根據我的個人經驗和觀點回答的,第二個是通過具體測量得出的。
任務:處理數據庫
我選擇的任務是模擬典型的以數據庫為中心的任務,計算所有員工的平均收入。每個員工都被加載到內存中,并且平均值會循環計算。我知道您絕對不應在現實生活中這樣做,因為數據庫可以自己更快地完成此任務。但是,首先,我看到這種情況在現實生活中經常發生,其次,對于某些NoSQL數據庫,您必須在應用程序中執行此操作,其次,這只是一些代碼,用于創建大量需要收集的垃圾。
我選擇了JVM上的Kotlin作為基于垃圾收集的編程語言的代表。JVM具有高度優化的垃圾收集器,如果您習慣Kotlin,則使用Java就像在石器時代工作一樣。
您可以在GitHub上找到代碼:https://github.com/akquinet/GcRustVsJvm
用Kotlin處理
計算得出一系列員工,總結他們的薪水,計算員工數量,最后除以這些數字:
- fun computeAverageIncomeOfAllEmployees(
- employees : Sequence<Employee>
- ) : Double
- {
- val (nrOfEmployees, sumOfSalaries) = employees
- .fold(Pair(0L, 0L),
- { (counter, sum), employee ->
- Pair(counter + 1, sum + employee.salary)
- })
- return sumOfSalaries.toDouble() /
- nrOfEmployees.toDouble()
- }
這里沒什么令人興奮的。(您可能會注意到一種函數式編程風格。這是因為我非常喜歡函數式編程。但這不是本文的主題。)垃圾是在創建雇員時創建的。我在這里創建隨機雇員,以避免使用真實的數據庫。但是,如果您使用JPA,則將具有相同數量的對象創建。
- fun lookupAllEmployees(
- numberOfAllEmployees : Long
- ): Sequence<Employee>
- {
- return (1L..numberOfAllEmployees)
- .asSequence()
- .map { createRandomEmployee() }
- }
隨機對象的創建也非常簡單。字符串是從字符列表創建的charPool。
- fun createRandomEmployee(): Employee =
- Employee(
- createRandomStringOf80Chars(),
- createRandomStringOf80Chars(),
- ... // code cut Out
- )
- fun createRandomStringOf80Chars() =
- (1..80)
- .map { nextInt(0, charPool.size) }
- .map(charPool::get)
- .joinToString("")
Rust版本的一個小驚喜是我必須如何處理前面提到的字符列表。因為只需要一個單例,所以將其存儲在一個伴隨對象中。這里是它的輪廓:
- class EmployeeServices {
- companion object {
- private val charPool: List<Char>
- = ('a'..'z') + ('A'..'Z') + ('0'..'9')
- fun lookupAllEmployees(...) ...
- fun createRandomEmployee(): Employee ...
- fun computeAverageIncomeOfAllEmployees(...) ...
- }
- }
現在,以Rust方式處理
我偶然發現的第一件事是,將這個單例字符列表放在何處。Rust支持直接嵌入二進制文件中的靜態數據和可以由編譯器內聯的常量數據。兩種選擇僅支持一小部分表達式來計算單例的值。我計算允許的字符池的解決方案是這樣的:
- let char_pool = ('a'..'z').collect::>();
由于向量的計算基于類型推斷,因此無法將其指定為常量或靜態。我目前的理解是,Rust的慣用方法是添加功能需要處理的所有對象作為參數。因此,用于計算Rust中平均工資的主要調用如下所示:
- let average =
- compute_average_income_of_all_employees(
- lookup_all_employees(
- nr_of_employees, &char_pool,
- ) );
通過這種方法,所有依賴項都變得清晰了。具有C經驗的開發人員會立即認識到地址運算符&,該運算符將內存地址作為指針返回,并且是高效且可能無法維護的代碼的基礎。當我的許多同事與Rust一起玩時,這種基于C的負面體驗被投射到Rust。
我認為這是不公平的。C的&運算符設計帶來的問題是,始終存在不可預測的副作用,因為應用程序的每個部分都可以存儲指向存儲塊的指針。另外,每個部分都可以釋放內存,從而可能導致所有其他部分引發異常。
在Rust中,&操作員的工作方式有所不同。每個數據始終由一個變量擁有。如果使用&此所有權創建了對數據的引用,則該所有權將轉移到引用范圍內。只有所有者可以訪問數據。如果所有者超出范圍,則可以釋放數據。
在我們的示例中,char_pool使用&運算符將的所有權轉移到函數的參數。當該函數返回時,所有權將歸還給變量char_pool。因此,它是一種類似于C的地址運算符,但它增加了所有權的概念,從而使代碼更簡潔。
Rust中的域邏輯
Rust的主要功能看起來與Kotlin差不多。由于隱含的數字類型,例如f6464位浮點數,因此感覺有點基本。但是,這是您很快就會習慣的事情。
- fn compute_average_income_of_all_employees(
- employees: impl Iterator<Item=Employee>
- ) -> f64
- {
- let (num_of_employees, sum_of_salaries) =
- employees.fold(
- (0u64, 0u64),
- |(counter, sum), employee| {
- return (counter + 1,
- sum + employee.salary);
- });
- return (sum_of_salaries as f64) /
- (num_of_employees as f64);
- }
恕我直言,這是一個很好的例子,可以證明Rust是一種非常現代的干凈編程語言,并且對函數式編程風格提供了很好的支持。
在Rust中創建垃圾
現在讓我們看一下程序的一部分,其中創建了許多對象,以后需要收集這些對象:
- fn lookup_all_employees<'a>(
- number_of_all_employees: u64,
- char_pool: &'a Vec<char>
- ) -> impl Iterator<Item=Employee> + 'a
- {
- return
- (0..number_of_all_employees)
- .map(move | _ | {
- return create_random_employee(char_pool);
- })
- .into_iter();
- }
乍一看,這看起來很像Kotlin。它使用相同的功能樣式在循環中創建隨機雇員。返回類型是Iterator,類似于Kotlin中的序列,它是一個延遲計算的列表。
從第二個角度看,這些類型看起來很奇怪。這到底是'a什么?解決了懶惰評估的問題。由于Rust編譯器無法知道何時實際評估返回值,并且返回值取決于借入的引用,因此現在存在確定何時char_pool可以釋放借入值的問題。的'a注釋指定的壽命char_pool必須至少只要是作為返回值的壽命。
對于習慣了經典垃圾回收的開發人員來說,這是一個新概念。在Rust中,她有時必須明確指定對象的生存期。垃圾收集器進行所有清理時不需要的東西。
第三,您可以發現move關鍵字。它強制閉包獲取其使用的所有變量的所有權。由于char_pool(再次),這是必要的。Map是延遲執行的,因此,從編譯器的角度來看,閉包可能會超出變量的壽命char_pool。因此,關閉必須擁有它的所有權。
其余代碼非常簡單。這些結構是根據隨機創建的字符串創建的:
- fn create_random_employee(
- char_pool: &Vec<char>
- ) -> Employee
- {
- return Employee {
- first_name:
- create_random_string_of_80_chars(char_pool),
- last_name:
- create_random_string_of_80_chars(char_pool),
- address: Address
- { // cut out .. },
- salary: 1000,
- };
- }
- fn create_random_string_of_80_chars(
- char_pool: &Vec<char>
- ) -> String
- {
- return (0..80)
- .map(|_| {
- char_pool[
- rand::thread_rng()
- .gen_range(0,
- char_pool.len())]
- })
- .into_iter().collect();
- }
那么,Rust有多難?
實施這個微小的測試程序非常復雜。Rust是一種現代的編程語言,使開發人員能夠快速干凈地維護代碼。但是,它的內存管理概念直接體現在語言的所有元素中,這是開發人員必須理解的。
工具支持很好,恕我直言。大多數時候,您只需要執行編譯器告訴您的操作即可。但是有時您必須實際決定要如何處理數據。
現在,值得嗎?
即使聽起來有些令人信服,但我還是非常樂于做一些測量,看看現實是否也令人信服。因此,我為四個不同的輸入大小運行了Rust和Kotlin應用程序,測量了時間,并將結果放在對數比例圖中:
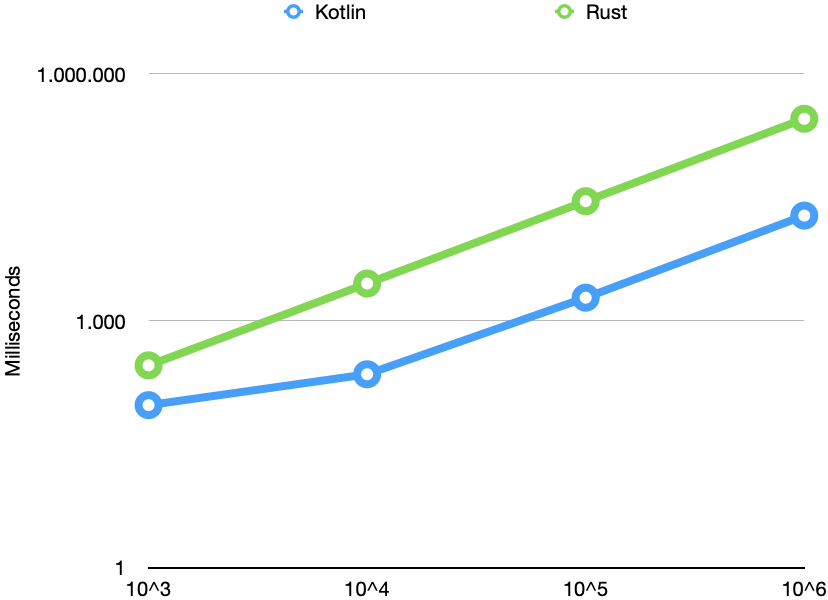
看著這些數字,我長了很長的臉。銹總是較慢;對于10 ^ 6個元素,一個非常糟糕的因子是11。這不可能。我檢查了代碼,沒有發現錯誤。然后,我檢查了優化情況,并發現了--release從dev模式切換到的標志prod。現在,結果看起來好多了:
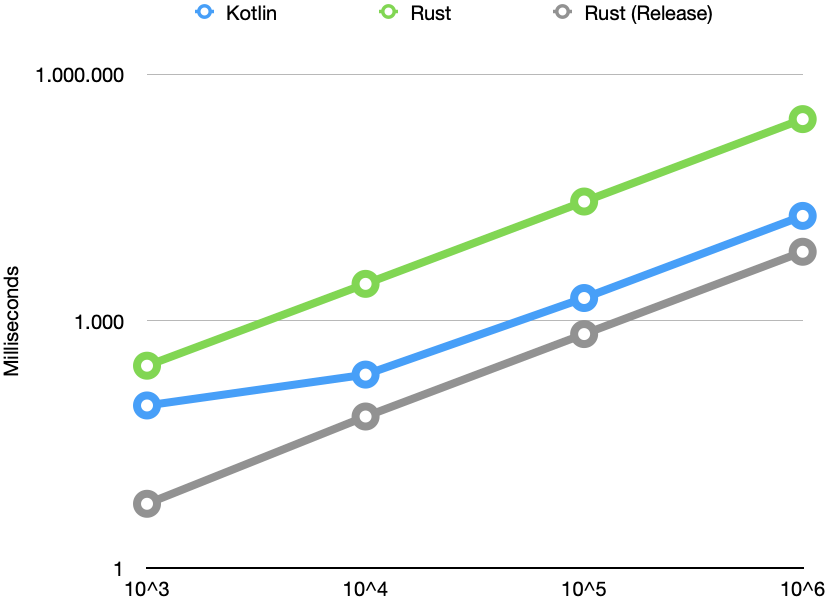
這樣好多了。現在,Rust總是比Kotlin快,并提供線性性能。在Kotlin上,我們看到了較長時間運行的代碼的典型性能改進,這可能是由于及時編譯引起的。從10 ^ 4的輸入大小來看,Rust大約比Kotlin快3倍。考慮到JVM的成熟以及過去幾十年在基礎架構上投入的資源,這是非常令人印象深刻的(Java的第一版于1995年發布)。
對于我來說,令人驚訝的是與生產配置文件相比,開發配置文件的速度要慢得多。40的系數是如此之大,以至于您永遠都不應將開發配置文件用于發行。
結論
Rust是一種現代編程語言,具有您如今已習慣的所有舒適性。它具有一種新的內存處理方法,這給開發人員帶來了一點額外負擔,同時還提供了出色的性能。
而且,要回答標題的最初問題,您不必手動處理Rust中的垃圾。此垃圾收集由運行時系統完成,但現在不再稱為垃圾收集器。