面試官你能不能別問我 HashMap 了?
本文轉載自微信公眾號「Java極客技術」,作者鴨血粉絲 。轉載本文請聯系Java極客技術公眾號。
如果你是個 Java 程序員,那一定對 HashMap 不陌生,巧的是只要你去面試,大概率都會被問到 HashMap 的相關內容
那這篇文章你就一定要讀一讀了
HashMap 的底層數據結構
先來聊聊 HashMap 的底層數據結構 HashMap 的底層數據結構, 1.7 版本和 1.8 版本是有些不同的,但大體上都是 數組 + 鏈表 的形式來實現的, 1.7 版本是這個樣子:
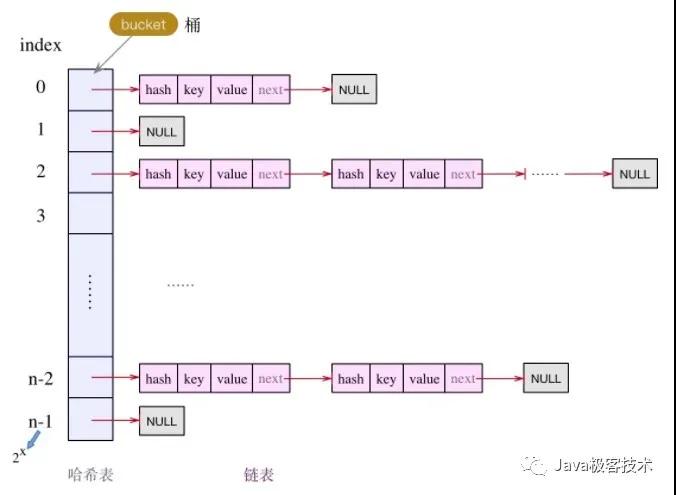
1.8 版本是這樣:
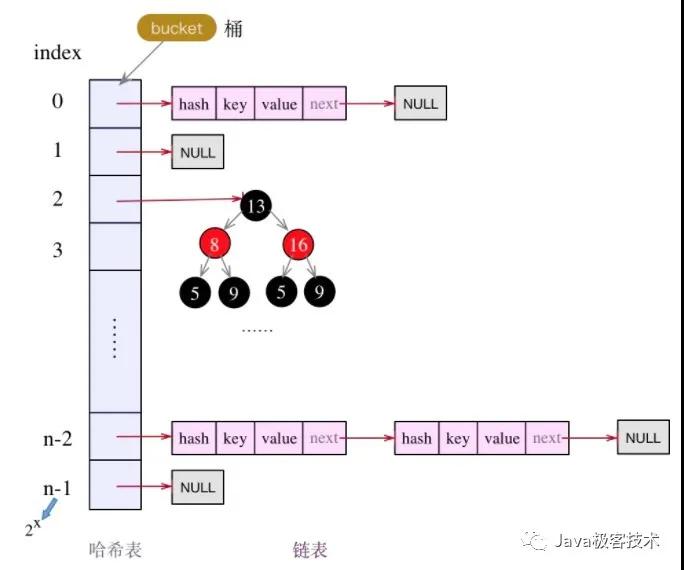
很明顯就能看出來, 1.8 版本怎么多了一個樹?還是紅黑的?
這就要來分析 1.7 版本 HashMap 的實現有什么不足了
1.7 版本主要就是 數組 + 鏈表,那么如果有一個 hash 值總是會發生碰撞,那么由此對應的鏈表結構也會越來越長,這個時候如果再想要進行查詢操作,就會非常耗時,所以該如何優化這一點就是 1.8 版本想要實現的
1.8 版本采用了 數組 + 鏈表 + 紅黑樹 的方式去實現,當鏈表的長度大于 8 時,就會將鏈表轉為紅黑樹。
這個時候問題就來了,為什么會將鏈表轉紅黑樹的值設定為 8 ?
因為鏈表的時間復雜度是 n/2 ,紅黑樹時間復雜度是 logn ,當 n 等于 8 的時候, log8 要比 8/2 小,這個時候紅黑樹的查找速度會更快一些
為什么是小于 6 的時候轉為鏈表,而不是 7 的時候就轉為鏈表呢?頻繁的從鏈表轉到紅黑樹,再從紅黑樹轉到鏈表,開銷會很大,特別是頻繁的從鏈表轉到紅黑樹時,需要旋轉
為什么將鏈表轉為紅黑樹,而不是平衡二叉樹( AVL 樹)呢?
- 因為 AVL 樹比紅黑樹保持著更加嚴格的平衡, AVL 樹中從根到最深葉的路徑最多為 1.44lg(n + 2) ,紅黑樹中則最多為 2lg( n + 1) ,所以 AVL 樹查找效果會比較快,如果是查找密集型任務使用 AVL 樹比較好,相反插入密集型任務,使用紅黑樹效果就比較 nice
- AVL 樹在每個節點上都會存儲平衡因子
- AVL 樹的旋轉比紅黑樹的旋轉更加難以平衡和調試,如果兩個都給 O(lgn) 查找, AVL 樹可能需要 O(log n) 旋轉,而紅黑樹最多需要兩次旋轉使其達到平衡
HashMap 為什么是線程不安全的?
HashMap 的線程不安全主要體現在兩個方面:擴容時導致的死循環 & 數據覆蓋
擴容時導致的死循環,這個問題只會在 1.7 版本及以前出現,因為在 1.7 版本及以前,擴容時的實現,采用的是頭插法,這樣就會導致循環鏈表的問題
什么時候會觸發擴容呢?如果存儲的數據,大于 當前的 HashMap 長度( Capacity ) * 負載因子( LoadFactor ,默認為 0.75) 時,就會發生擴容。比如當前容量是 16 , 16 * 0.75 = 12 ,當存儲第 13 個元素時,經過判斷發現需要進行擴容,那么這個時候 HashMap 就會先進行擴容的操作
擴容也不是簡簡單單的將原來的容量擴大就完事兒了,擴容時,首先創建一個新的 Entry 空數組,長度是原數組的 2 倍,擴容完畢之后還會再進行 ReHash ,也就是將原 Entry 數組里面的數據,重新 hash 到新數組里面去
假設現在有一個 Entry 數組,大小是 2 ,那么當我們插入第 2 個元素時,大于 2 * 0.75 那么此時就會發生擴容,具體如下圖:
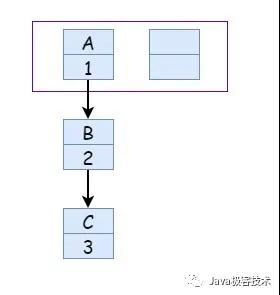
擴容完畢之后,因為采用的是頭插法,所以后面的元素會放在頭部位置,那么就可能會這樣:
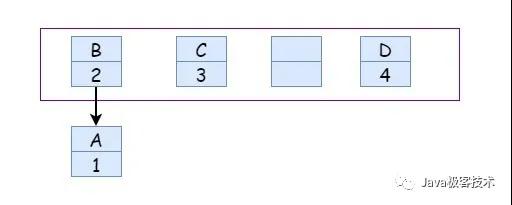
剛開始記錄的是 A.next = B ,經過擴容之后是 B.next = A ,那么最后可能就是這樣了:
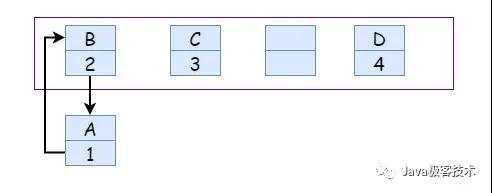
明顯看到造成了死循環,比較好的是, 1.8 版本之后采用了尾插法,解決了這個問題
還有個問題, 1.8 版本是沒有解決的,那就是數據覆蓋問題
假設現在線程 A 和線程 B 同時進行 put 操作,特別巧的是這兩條不同的數據 hash 值一樣,并且這個位置數據為 null ,那么是不是應該讓線程 A 和 B 都執行 put 操作。假設線程 A 在要進行插入數據時被掛起,然后線程 B 正常執行將數據插入了,然后線程 A 獲得了 CPU 時間片,也開始進行數據插入操作,那么就將線程 B 的數據給覆蓋掉了
因為 HashMap 對 put 操作沒有進行加鎖的操作,那么就不能保證下一個線程 get 到的值,就一定是沒有被修改過的值,所以 HashMap 是不安全的
那既然 HashMap 線程不安全,你給推薦一個安全的?
如果推薦的話,那肯定推薦 ConcurrentHashMap ,說到 ConcurrentHashMap 也有一個比較有趣的事情,那就是 ConcurrentHashMap 的 1.7 版本和 1.8 版本實現也是不一樣
在 1.7 版本, ConcurrentHashMap 采用的是分段鎖( ReentrantLock + Segment + HashEntry )實現,也就是將一個 HashMap 分成多個段,然后每一段都分配一把鎖,這樣去支持多線程環境下的訪問。但是這樣鎖的粒度太大了,因為你鎖的直接就是一段嘛
所以 1.8 版本又做了優化,使用 CAS + synchronized + Node + 紅黑樹 來實現,這樣就將鎖的粒度降低了,同時使用 synchronized 來加鎖,相比于 ReentrantLock 來說,會節省比較多的內存空間
HashMap 這塊,其實還可以擴展,比如 HashMap 和 HashTable 的區別, ConcurrentHashMap 1.7 版本和 1.8 版本具體的實現,等等等等
但是這篇文章已經比較長了,就寫到這里吧~