













從語義網(wǎng)到知識圖譜
【引子】 “海內(nèi)存知己,天涯若比鄰”, 這是石頭兄弟推薦給我的一篇關于語義網(wǎng)的綜述性文章,刊載于《美國計算機學會通訊》第64卷第2期——“A Review of the Semantic Web Field”(https://cacm.acm.org/magazines/2021/2/250085-a-review-of-the-semantic-web-field/fulltext),作者是Pascal Hitzler。老碼農(nóng)認真研讀,頗有收獲,編譯成文。
“語義網(wǎng)”(Semantic Web)和“人工智能”一樣,都指的是一個研究領域,而不是一個具體的產(chǎn)品。語義網(wǎng)是一個豐富的研究和應用領域,借鑒了計算機科學內(nèi)部或鄰近的許多學科。有時候,人們使用“語義網(wǎng)技術”這個術語被用來描述這一領域中出現(xiàn)的一系列方法和工具,以避免術語上的混淆。語義網(wǎng)領域不僅在研究和應用的方法和目標方面非常不同,而且有許多不同但又相互關聯(lián)的次級社區(qū),每個社區(qū)都可能對該領域的歷史和當前狀況作出相當不同的敘述。
那么,語義網(wǎng)是一個關于什么的研究領域呢?答案可能是主觀的,因為在這個領域里沒有明確的共識。
一種觀點認為,該領域的長期目標是創(chuàng)建語義網(wǎng)產(chǎn)品 ,以及創(chuàng)建、維護和應用所需的所有必要工具和方法。相對于目前大多數(shù)主要面向人類消費的網(wǎng)絡,這里的語義網(wǎng)通常被設想為機器可理解的信息以及利用這些信息的服務(智能代理)來增強當前的互聯(lián)網(wǎng)。這種觀點可以追溯到2001年《科學美國人》的一篇文章,可以說標志著這個領域的誕生。在這種情況下,提供機器可理解的信息是通過為數(shù)據(jù)賦予元數(shù)據(jù)來完成的。在語義網(wǎng)中,這些元數(shù)據(jù)通常采用本體論的形式,或者至少是一種具有基于邏輯語義的形式語言,允許對數(shù)據(jù)的意義進行推理。如果再加上智能代理將利用這些信息的理解,會發(fā)現(xiàn)語義網(wǎng)領域與人工智能領域有著顯著的重疊。事實上,在過去大多數(shù)主要的人工智能會議上,都有明確的“語義網(wǎng)”的印記。
另一種更近期的觀點是,語義網(wǎng)領域的開發(fā)方法及工具與互聯(lián)網(wǎng)無關的應用,即使不使用機器可理解的數(shù)據(jù)建立智能代理,這些應用也能提供附加值。事實上,早期業(yè)界對這個領域的興趣,旨在將語義網(wǎng)技術應用于信息集成和管理。從這個角度來看,可以說這個領域是關于建立高效的(即低成本的)數(shù)據(jù)共享、發(fā)現(xiàn)、集成和重用的方法和工具,而互聯(lián)網(wǎng)在這方面可能只是數(shù)據(jù)傳輸?shù)墓ぞ摺_@種理解使它更接近數(shù)據(jù)庫,或者數(shù)據(jù)科學的數(shù)據(jù)管理部分。
通過將語義網(wǎng)描述為以 W3C 標準 RDF、 OWL 和 SPARQL 為核心來研究本體論、關聯(lián)數(shù)據(jù)和知識圖譜的基礎和應用,可以對該領域進行限制,但實際上可能是相對精確的描述。
或許,這幾個視角都有各自的優(yōu)點,語義網(wǎng)的研究領域存在于它們的融合之中,本體論、關聯(lián)數(shù)據(jù)、知識圖譜是這個領域的關鍵概念,圍繞 RDF、 OWL 和 SPARQL 的 W3C 標準構成了技術交流方式,它們在語法(在某種程度上是語義)層面上達成了統(tǒng)一; 語義網(wǎng)領域應用的目的是建立有效的數(shù)據(jù)共享、發(fā)現(xiàn)、集成和重用的方法(無論是否針對 Web) ; 作為驅動力的長期愿景是在的某個時刻,將語義網(wǎng)建立為一個完整的基于智能代理的應用環(huán)境。
“治學先治史”,讓我們看看過去這些年語義網(wǎng)領域出現(xiàn)的關鍵概念、標準和突出成果。
語義網(wǎng)的發(fā)展階段
當一個研究領域誕生時,確定任何特定的時間點當然是有爭議的。然而,2001年 Berners-Lee 等人在《科學美國人》上發(fā)表的一篇文章是一個早期的里程碑,為這一新興領域提供了重要的線索。而且,那是在世紀之初,當時語義網(wǎng)領域在社區(qū)規(guī)模、學術生產(chǎn)力和最初的產(chǎn)業(yè)興趣等方面處于非常重要的上升初期。
但是,已經(jīng)有人在早期做出了努力。從2000年運行到2006年的DAML項目,目標是開發(fā)一種語義 Web 語言和相應的工具。由歐盟資助的 On-To-Knowledge 項目,運行于2000-2002年,產(chǎn)生了 OIL 語言,后來與 DAML 合并,最終產(chǎn)生了網(wǎng)絡本體語言的W3C標準。為網(wǎng)絡數(shù)據(jù)賦予機器可讀或“可理解”的元數(shù)據(jù),這一更為普遍的想法可以追溯到互聯(lián)網(wǎng)本身的起源。例如,早在1997年就發(fā)表了資源描述框架(RDF)的初稿。
從21世紀初開始,可以分為三個相互重疊的階段,每個階段都由一個關鍵概念驅動,也就是說,語義網(wǎng)領域的主要焦點至少轉移了兩次。第一階段是由本體論驅動的,它跨越了21世紀初到21世紀中期; 第二階段是由關聯(lián)數(shù)據(jù)驅動的,一直延伸到21世紀10年代初。第三階段到現(xiàn)在都是由知識圖譜驅動的。
本體論
在21世紀的大部分時間里,這個領域的工作都以本體論為中心,當然,這個概念有著更為古老的淵源。本體是共享概念化的一個正式的、明確的規(guī)范ーー盡管有人可能認為這個定義仍然需要解釋,但還是相當通用的。在一個更精確的意義上 ,本體論實際上是一個概念(即,類型或類別,如“哺乳動物”和“胎生動物”)及其關系(如“哺乳動物產(chǎn)下胎生動物”)的知識庫,在一個基于形式邏輯的本體語言中指定。在語義網(wǎng)上下文中,本體是數(shù)據(jù)集成、共享和發(fā)現(xiàn)的主要工具,一個重要的思想是本體本身應該可以被其他人重用。
2004年,網(wǎng)絡本體語言的OWL成為了W3C 標準,為該領域提供了進一步的燃料。OWL的核心是基于描述邏輯,也就是說,基于一階謂詞邏輯的子語言,只使用一元謂詞和二元謂詞,限制使用量詞,設計的方式使得語言上的邏輯演繹推理是可判定的。
同樣在2004年,資源描述框架(RDF)也成為了W3C標準。本質上,RDF是一種用于表達標記化并類型化的有向圖的語法,它使用OWL指定類型及其關系的本體,然后在RDF圖中使用這些類型,并將這些關系作為邊。從這個角度來看,OWL本體可以作為RDF圖的模式(或類型邏輯)。
一個用于RDF查詢語言的 W3C 標準,稱為 SPARQL,在2008年發(fā)布,在2013年進行了更新,3與 OWL 更加兼容。在RDF、 OWL和SPARQL周邊的其他標準已經(jīng)或正在開發(fā),其中一些已經(jīng)獲得了重大的進展,例如,語義傳感器網(wǎng)絡本體論或起源本體論,以及SKOS 簡單知識組織系統(tǒng)。
通過在W3C的所有這些關鍵標準,與其他關鍵 W3C 標準之間的基本兼容性得到了維護。例如,XML 作為RDF和OWL的語法序列化和交換格式。所有 W3C 語義 Web 標準還使用 IRI 作為 RDF圖中的標識符,并使用了OWL類名和數(shù)據(jù)類型標識符等。
在語義網(wǎng)上下文中,本體是數(shù)據(jù)集成、共享和發(fā)現(xiàn)的主要工具,一個重要的思想是本體本身應該可以被其他人重用。
DARPA的 DAML 項目在2006年結束,隨后在基礎語義網(wǎng)研究方面幾乎沒有大規(guī)模的資助項目。因此,大部分相應的研究要么轉移到應用領域,比如醫(yī)療保健或國防領域的數(shù)據(jù)管理,要么轉移到相鄰的領域。相比之下,歐盟的框架方案,特別是 FP6(2002-2006)和 FP7(2007-2013) ,為基礎和面向應用的語義網(wǎng)研究提供了大量資金。在語義網(wǎng)研究社區(qū)的組成中,可以看到這個社區(qū)主要是歐洲人。社區(qū)的規(guī)模難以評估,但自2000年代中期以來,該領域的主要會議——“國際語義網(wǎng)會議”平均每年吸引了600多名參與者。
工業(yè)界的興趣從一開始就很大,但幾乎不可能描述關于工業(yè)活動相關水平的可靠數(shù)據(jù)。主要和較小的公司已經(jīng)參與了大規(guī)模的基礎或應用研究項目,特別是根據(jù)歐盟 FP 6和7。工業(yè)界的興趣已經(jīng)改變了研究團體的焦點。
一些大規(guī)模的本體論(通常早于語義 Web 社區(qū))在這個時期成熟了。例如,于1998年開始的基因本體論,現(xiàn)在已經(jīng)是一個非常突出的資源。另一個例子是 SNOMED CT,它可以追溯到1960年,但現(xiàn)在已經(jīng)在OWL中完全正式化,并廣泛用于電子健康記錄。
正如計算機科學研究中經(jīng)常出現(xiàn)的情況一樣,在2005年前后,人們最初對短期取得突破性結果的期望開始降低,開始更為冷靜看待這一問題。大多數(shù)本體論是在這一時期開發(fā)的,其形式通常是基于臨時建模的意義,作為開發(fā)本體論的方法,但尚未產(chǎn)生具體的結果,結果是難以維護和重用。這一點,再加上當時開發(fā)良好的本體論所需的大量前期成本,為研究團體轉移注意力鋪平了道路,這也許可以被理解為與21世紀初強烈的基于本體論的方法相對立。
關聯(lián)數(shù)據(jù)
2006年見證了“關聯(lián)數(shù)據(jù)”的誕生,如果重點是在免費許可下的開放、公開和可用性,則稱為“關聯(lián)開放數(shù)據(jù)”。關聯(lián)數(shù)據(jù)很快成為語義網(wǎng)研究和應用程序的主要驅動力,并一直持續(xù)到2010年左右。
關聯(lián)數(shù)據(jù)由一組RDF圖組成,這些RDF圖是關聯(lián)的,因為圖中的許多IRI標識符也出現(xiàn)在其他的圖中,可以是多個圖中。從某種意義上說,所有這些關聯(lián)的RDF圖集合可以理解為一個非常大的 RDF 圖。
如下圖所示,公開可用的關聯(lián)RDF圖的數(shù)量在第一個十年中在顯著增長; 數(shù)據(jù)來自關聯(lián)開放數(shù)據(jù)云網(wǎng)站,該網(wǎng)站并不包含所有RDF數(shù)據(jù)集。2015年的一篇論文報道了“來自超過65萬個數(shù)據(jù)文檔的超過370億個三元組”,這也只是所有可以在互聯(lián)網(wǎng)上自由訪問的 RDF三元組的集合。例如,大型數(shù)據(jù)提供者通常只提供基于SPARQL的查詢接口,或者使用RDF進行內(nèi)部數(shù)據(jù)組織,但只通過Web 頁面向外部提供服務。關聯(lián)開放數(shù)據(jù)云中的數(shù)據(jù)集覆蓋了各種各樣的主題,包括地理、政府、生命科學、語言學、媒體、科學出版物和社交網(wǎng)絡。
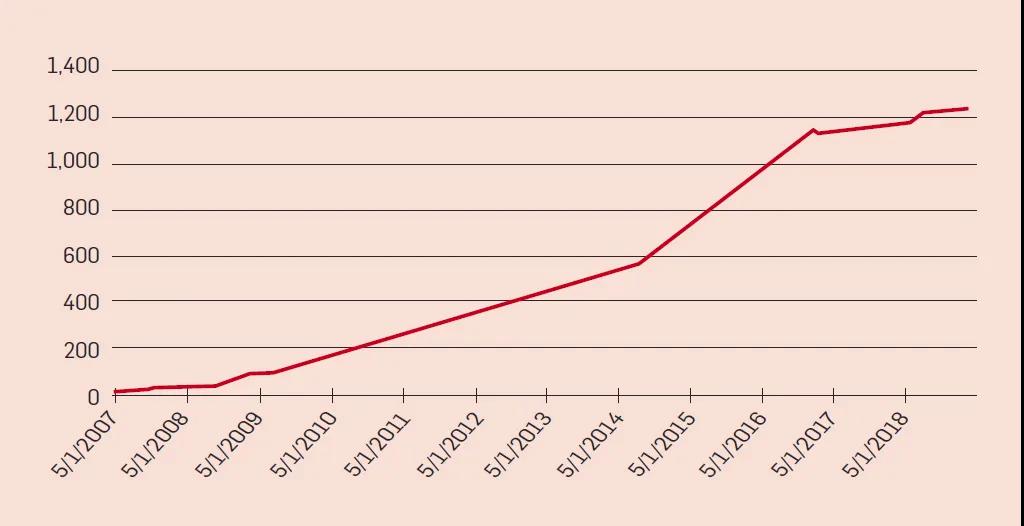
隨著時間的推移,關聯(lián)數(shù)據(jù)開放云中 RDF 圖的數(shù)量
其中最著名和最常用的關聯(lián)數(shù)據(jù)集是 DBpedia,這是從 Wikipedia (以及最近的 Wikidata)中提取的關聯(lián)數(shù)據(jù)集。2016年4月發(fā)布的數(shù)據(jù)集包括了約600萬個實體和約95億個RDF三元組。由于其廣泛的主題覆蓋(基本上是維基百科中的所有內(nèi)容) ,而且它是最早提供的鏈接數(shù)據(jù)集之一,DBpedia 在關聯(lián)數(shù)據(jù)開放云中發(fā)揮著核心作用: 許多其他數(shù)據(jù)集都會鏈接到它,因此它已成為關聯(lián)數(shù)據(jù)的樞紐。
從一開始,業(yè)界就對關聯(lián)數(shù)據(jù)產(chǎn)生了濃厚的興趣。例如,BBC是第一個重要的行業(yè)貢獻者,紐約時報公司和Facebook是早期采用者。然而,業(yè)界的興趣似乎主要在于利用關聯(lián)數(shù)據(jù)技術進行數(shù)據(jù)集成和管理,而這些數(shù)據(jù)往往不會在開放的互聯(lián)網(wǎng)上顯示出來。
在關聯(lián)數(shù)據(jù)的時代,本體論扮演了一個不那么重要的角色。它們通常被用作模式,可以告知RDF 數(shù)據(jù)集的內(nèi)部結構,然而,相對于本體論時代的過度承諾和深度研究,關聯(lián)數(shù)據(jù)云中的RDF圖中的信息是膚淺和相對簡單的。在這段時間里,人們有時會說本體論不能被重用,而且一種更簡單的方法,主要基于利用 RDF 和數(shù)據(jù)集之間的鏈接,對于數(shù)據(jù)集成、管理和線上線下的應用程序有著更現(xiàn)實的作用。也正是在這個時期,基于RDF的數(shù)據(jù)組織詞匯表與本體的關系并不大。
也正是在這段時間(2011年)里,schema.org 登場了。最初由Bing、 Google 和雅虎推動,后來yandex也加入進來,公開了一個相對簡單的本體論體系,并建議網(wǎng)站提供商使用schema.org的詞匯表在各自的網(wǎng)站上注釋(即鏈接)實體。作為回報,schema.org背后的 Web 搜索引擎提供商承諾通過利用注釋作為元數(shù)據(jù)來改善搜索結果。在2015年,大約有超過30% 的頁面使用了schema.org的注釋。
2012年發(fā)起的另一個重要項目是Wikidata,該項目最初是德國wikimedia協(xié)會的一個項目,由谷歌、 Yandex 和Allen人工智能研究所等機構資助。Wikidata 基于與維基百科類似的想法,即眾包信息。然而,維基百科提供了百科全書式的文本(以人類讀者為主要消費者) ,Wikidata 則是關于創(chuàng)建可用于程序或其他項目的結構化數(shù)據(jù)。例如,許多其他wikimedia包括維基百科,使用Wikidata提供一些信息,然后呈現(xiàn)給人類讀者。Wikidata已經(jīng)擁有了超過6600萬個的數(shù)據(jù)項,自項目啟動以來已經(jīng)進行了超過10億次的編輯,并且有超過20000個活躍用戶。
在21世紀10年代早期,關聯(lián)數(shù)據(jù)的最初炒作開始讓位于一種更為冷靜的觀點。雖然關聯(lián)數(shù)據(jù)確實有一些突出的用途和應用,但結果表明,集成和利用關聯(lián)數(shù)據(jù)需要比最初的預期付出更多的努力。可以說,用于關聯(lián)數(shù)據(jù)的淺顯的非表達性模式似乎是可重用性的一個主要障礙,最初期望數(shù)據(jù)集之間的相互聯(lián)系會以某種方式解釋這一弱點,但似乎并沒有實現(xiàn)。這不應被理解為貶低了鏈接數(shù)據(jù)給該領域及其應用帶來的重大進展: 僅僅以某種結構化的格式提供數(shù)據(jù),遵循一個突出的標準,就意味著可以使用現(xiàn)有工具訪問、集成和管理數(shù)據(jù),然后進行利用。這比以語法和概念上更加異構的形式提供數(shù)據(jù)要容易得多。但是,尋求更有效的數(shù)據(jù)共享、發(fā)現(xiàn)、集成和重用的方法當然和以往一樣重要,而且正在開始。
知識圖譜
2012年,當谷歌推出它的知識圖譜時,一個新的術語出現(xiàn)了。例如,可以通過在 google 網(wǎng)站上搜索知名實體來查看 Google知識圖譜的部分內(nèi)容: 在鏈接到網(wǎng)頁的搜索結果旁邊顯示一個所謂的信息框,顯示來自Google知識圖譜的信息。下圖給出了這種信息框的一個例子,搜索 Kofi Annan 就可以找到這個例子。人們可以通過跟隨一個超鏈接從這個節(jié)點導航到圖譜中的其他節(jié)點,例如,到 Nane Maria Annan,她與 Kofi Annan 節(jié)點有配偶關系。在這個鏈接之后,Nane Maria Annan 的一個新的信息框被顯示在同一個詞的搜索結果旁邊。
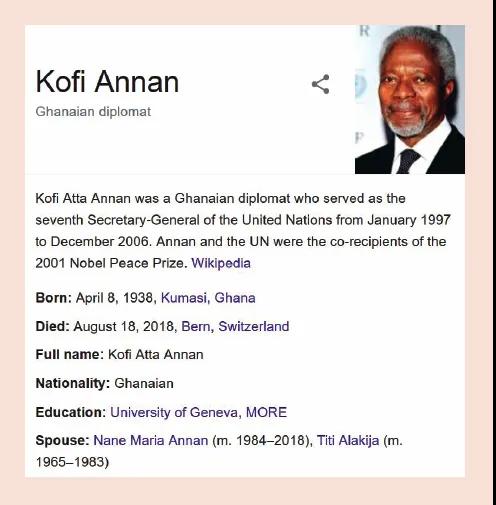
在 google 上搜索“ Kofi Annan”后的 Google知識圖譜節(jié)點
雖然 Google 沒有提供可下載的知識圖譜,但它提供了內(nèi)容訪問的API,這個API 使用標準的schema.org類型,并且滿足JSON-LD格式,這實際上是W3C RDF 標準化的另一種語法。
然而,考慮到語義網(wǎng)技術的歷史,特別是之前討論過的關聯(lián)數(shù)據(jù)和本體論,知識圖譜仿佛是一種直接來自語義網(wǎng)領域的新構想,關注的重點發(fā)生了顯著轉變。
其中一個不同之處在于開放性: 正如關聯(lián)開放數(shù)據(jù)這個術語從一開始就暗示的那樣,語義網(wǎng)社區(qū)的關聯(lián)數(shù)據(jù)工作大多以開放共享數(shù)據(jù)為其目標之一,這意味著關聯(lián)數(shù)據(jù)大多可以免費下載,或者由支持SPARQL的服務提供,并且重要的是在社區(qū)中使用非限制性許可。wikidata作為一個知識圖譜也是開放共享的。相比之下,圍繞知識圖譜的活動往往是由行業(yè)主導的,而主要的應用并不是真正開放的。
另一個區(qū)別是集中控制與自下而上的社區(qū)貢獻: 在某種意義上,關聯(lián)數(shù)據(jù)云是目前已知最大的現(xiàn)有知識圖譜,但它不是一個簡潔的實體。相反,它由松散且相互關聯(lián)的單個子圖組成,每個子圖都由它自己的結構、表示模式等控制。相比之下,知識圖譜通常被理解為更具內(nèi)部一致性和更嚴格控制的組件服務。因此,對于沒有嚴格質量控制的外部圖表的價值受到質疑,而內(nèi)容和/或基礎模式的質量受到更多關注。
最大的區(qū)別可能是從學術研究到工業(yè)應用的轉變。因此,圍繞知識圖譜的活動是由強大的工業(yè)用例及可感知的附加價值推動的,沒有公開的正式評估。
語義網(wǎng)與其他領域和學科的關系
與機器學習那樣的其他領域不同,語義網(wǎng)領域主要不是由該領域固有的某些方法驅動的。相反,它是由一個共同的愿景驅動的,因此,它根據(jù)需要借鑒了其他學科。
例如,語義網(wǎng)領域作為人工智能的一個子學科,與知識的表示有著密切的關系,因為知識圖譜和本體論來表示語言可以被理解,而且與知識表示的語言密切相關,描述邏輯作為支撐網(wǎng)絡本體語言 OWL的邏輯學,發(fā)揮著核心作用。語義網(wǎng)的應用需求也推動或啟發(fā)了描述邏輯的研究,以及對不同知識表示方法(如規(guī)則和描述邏輯)之間橋接的研究。
數(shù)據(jù)庫領域顯然是密切相關的,如(元)數(shù)據(jù)管理和圖的結構化數(shù)據(jù)有一個自然的家園,也是重要的語義網(wǎng)領域。然而,語義網(wǎng)研究的重點主要集中在異構數(shù)據(jù)源的概念集成上;,例如,如何克服不同的數(shù)據(jù)組織方式; 在大數(shù)據(jù)術語中,語義網(wǎng)的重點主要是數(shù)據(jù)的多樣性。
自然語言處理作為一種應用工具,在知識圖譜和本體集成、自然語言查詢應答、文本知識圖譜或本體構造等方面發(fā)揮著重要作用。
機器學習,特別是深度學習,正在改進語義網(wǎng)上下文中困難任務的處理能力,例如知識圖譜補全,數(shù)據(jù)清洗等等。與此同時,語義網(wǎng)技術正在研究提高人工智能的可解釋性。
在網(wǎng)絡物理系統(tǒng)和物聯(lián)網(wǎng)的某些方面也正在研究使用語義網(wǎng)技術,例如,在智能制造(工業(yè)4.0)、智能能源網(wǎng)和智能建筑等等。
生命科學的一些領域受益于語義網(wǎng)技術已經(jīng)有相當長的歷史了,例如,前面提到的 SNOMED-CT 和基因本體論。一般來說,生物醫(yī)學領域是語義網(wǎng)概念的早期采用者。另一個突出的例子是由語義網(wǎng)技術驅動的ICD開發(fā)。
語義網(wǎng)技術其他潛在的應用領域可以是任何需要數(shù)據(jù)共享、發(fā)現(xiàn)、集成和重用的場景,例如在地球科學或數(shù)字人文學科。
語義網(wǎng)的未來
毫無疑問,語義網(wǎng)領域的宏偉目標尚未實現(xiàn),無論是將語義網(wǎng)作為一個產(chǎn)品來創(chuàng)建,還是為數(shù)據(jù)共享、發(fā)現(xiàn)、集成和重用提供解決方案,使其變得完全容易和輕松。正如關于知識圖譜、schema.org和生命科學本體論的討論所證明的那樣,這并不意味著中間結果沒有實際用途。
然而,為了向更大的目標前進,幾乎每一個子領域的語義網(wǎng)都需要進一步的發(fā)展。例如,工業(yè)知識圖譜,本體匹配,信息抽取等等。與其重復些清單,不如讓把重點放在當前的短期主要障礙的挑戰(zhàn)上。
在語義網(wǎng)社區(qū)及其應用社區(qū)中,關于如何有效的處理數(shù)據(jù)管理問題有著豐富的軟硬知識。然而,剛剛采用語義網(wǎng)技術的人們經(jīng)常發(fā)現(xiàn)自己面臨著一種不和諧的聲音,面對不同方法的推銷,但幾乎沒有關于這些不同方法的利弊介紹。還有那些工具包,從不適合實踐的粗糙原型到針對特定子問題而精心設計的軟件,但同樣沒有什么指導,到底哪種工具,哪種方法,將最有助于用戶實現(xiàn)自己的特定目標。
因此,在這個階段,語義網(wǎng)領域最需要的可能是整合。作為一個固有的應用驅動領域,這種合并會在其各個子領域進行,從而形成面向應用的流程,這些流程的目標和優(yōu)缺點都有詳細的文檔記錄,同時還有易于使用和支持整個流程的集成工具。一些著名的流行軟件,如OWL API,Wikidata的底層引擎Wikibase,或者ELK推理機,都是強大且非常有幫助的,但是在某些情況下,盡管它們都使用了 RDF 和 OWL 進行序列化,仍然不能輕松地相互協(xié)作。
誰可能是這種整合的驅動力呢?
對于學術界而言,開發(fā)并維護穩(wěn)定易用軟件的動機往往有限,因為學術成績(主要以出版物和獲得的外部資金總額衡量)往往與這些活動不相符。編寫高質量的入門教科書是非常耗時且回報很少的學術成績。然而,通過開發(fā)各種范式之間的橋梁解決方案,以及通過與應用領域合作開發(fā)和實現(xiàn)用例,學術界確實為整合提供了一個基礎。
在工業(yè)界,各種各樣的整合已經(jīng)發(fā)生,初創(chuàng)企業(yè)和跨國公司采用語義網(wǎng)技術就是明證。但是,不論是技術細節(jié)還是其內(nèi)部采用的軟件,通常是不共享的,大概都是為了保護自己的競爭優(yōu)勢。如果確實如此,那么相應的軟件解決方案變得普及將只是時間的問題。
小結
在語義網(wǎng)存在的第一個近20年里,語義網(wǎng)領域已經(jīng)產(chǎn)生了豐富的關于數(shù)據(jù)共享、發(fā)現(xiàn)、集成和重用的高效數(shù)據(jù)管理的知識。通過語義網(wǎng)的應用,可以很好的理解這個領域的主要貢獻,包括 Schema.org,工業(yè)知識圖譜,Wikidata,本體建模應用等。這些應用背后的關鍵科學發(fā)現(xiàn)是什么呢?然而,這個問題更難回答。語義網(wǎng)的進步需要許多計算機科學子領域的貢獻,而其中一個關鍵任務就是如何將這些貢獻整合起來,以便提供適用的解決方案。從這個意義上說,這些應用展示了整個領域的主要進展。
主流工業(yè)界正在采用語義網(wǎng)技術,然而,尋求更有效的數(shù)據(jù)管理解決方案遠遠沒有結束,仍然是該領域的驅動力。
























