【51CTO.com快譯】如今,物聯網(IoT)、社交媒體、應用程序、以及分析設備,都在持續產生著各種類型的海量數據。而我們的業務系統需要每天接收各種大數據,并完成各項處理任務。因此,在日常處理這些持續增長的數據時,數據系統會面臨延遲和準確性兩個方面的挑戰。
Lambda架構的介紹
針對上述挑戰,Nathan Marz和James Warren于2015年首發了Lambda體系架構。它在邏輯上將數據系統分為三個層面,即:批處理(batch)層、速度(speed)層和服務(serving)層。而作為一種大數據的范例,它可以讓用戶通過構建數據系統,以克服上述數據延遲與準確性等問題。
由于Lambda體系架構可以被水平擴展,因此如果您的數據集過大,或所需的數據視圖過多,則可以通過添加更多的主機來參與處理。不過,Lambda會將系統中最復雜的部分,限制在速度層中。而由于該層面的輸出是臨時的,因此如果您需要對數據進行改進或校正,則可以每隔幾小時清空一次。
Lambda體系架構的工作原理
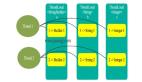
- Lambda體系架構的第一層--批處理層 ,既可以存儲整個數據集,又能夠計算出批處理的視圖。由于此處的存儲數據集不可被改變,因此只能被追加。也就是說,新的數據會不斷地被傳入,而原有舊的數據則會始終保持不變。同時,批處理層會通過對整個數據集的查詢,或功能性計算,得出各種視圖。查詢這些視圖時,我們雖然可以在整個數據集中低延遲地找到答案,但是其缺點是系統需要花費大量的時間,來進行計算。
- Lambda體系架構的第二層--服務層,能夠批量加載視圖。與傳統數據庫相似,它通過對視圖的只讀查詢操作,來提供低延遲的響應。一旦批處理層準備好一組新的視圖,服務層就會將當前已過時的批處理視圖予以替換。
- 流到批處理層的數據,同樣也會流入Lambda體系架構的第三層--速度層。其主要區別在于,盡管批處理層從開始就保留了所有數據,但是速度層僅關心從最后一批視圖完成以來到達的數據。也就是說,速度層通過處理那些批處理視圖尚未計入的最新數據查詢,來彌補計算視圖時的高延遲。具體原理如下圖所示:
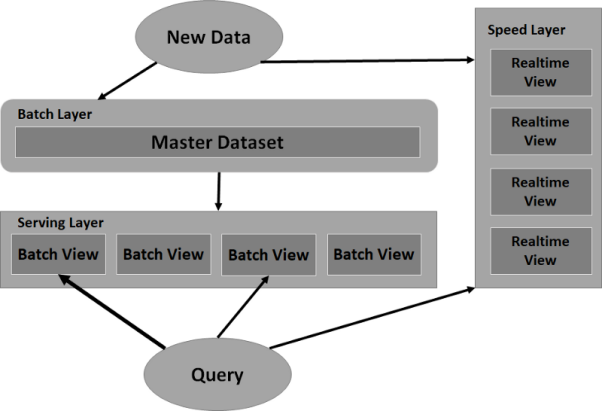
比方說明三個層面
為了更好地理解上述概念,讓我們來打個比方:在一位老人的豪宅里,每個房間都有一個時鐘。但是,除了廚房里的時鐘外,其他時鐘都是不準的。他需要以廚房里的時鐘為基準去校準其他時鐘。不過,由于記憶力差,他必須將廚房時鐘上的當前時間(上午9:04)記在一張紙上。然后,他以緩慢的步伐走向各個房間,將所有時鐘設定為上午9:04。而當他最后到達東廂房時,實際時間已經是上午9:51了。顯然,他后續在各個房間時鐘上設置的上午9:04,都是錯誤。
同理,如果數據系統只有批處理層,那么我們就會遇到類似的問題—由于需要花費一段時間才能得到某個問題的答案,因此該答案對于持續涌入的數據并非最新。
讓我們回到剛才的例子,幸虧這位老人手上有一只秒表。次日上午9:04,他同樣從廚房開始,在一張紙上記下時間,并啟動秒表(也就是他的“速度層”)。當最后到達東廂房時,他的秒表上顯示為“47分16秒”。通過基本數學計算,他可以知道當前的時鐘應該被設置為9:51 AM。
在上述類比中,老人是服務層,其豪宅里各個房間的時鐘隨處可以顯示當前時間的批處理視圖。當然,他通過觸發秒表,讓批處理視圖會與速度層同步,以獲得最準確的答案。
為什么要使用Lambda體系架構?
在Marz和Warren有關Lambda架構的開創性著作--《大數據》中,他們列出了大數據系統中的八個理想屬性,也描述了Lambda架構如何去滿足每一種屬性:
- 魯棒性和容錯能力。由于批處理層被設計為追加式,即包含了自開始以來的整體數據集,因此該系統具有一定的容錯能力。如果任何數據被損壞,該架構則可以刪除從損壞點以來的所有數據,并替換為正確的數據。同時,批處理視圖也可以被換成完全被重新計算出的視圖。而且速度層可以被丟棄。此外,在生成一組新的批處理視圖的同時,該架構可以重置整個系統,使之重新運行。
- 可擴展性。Lambda體系架構的設計層是作為分布式系統被構建的。因此,通過簡單地添加更多的主機,最終用戶可以輕松地對系統進行水平擴展。
- 通用性。由于Lambda體系架構是一般范式,因此用戶并不會被鎖定在計算批處理視圖的某個特定方式中。而且批處理視圖和速度層的計算,可以被設計為滿足某個數據系統的特定需求。
- 延展性。隨著新的數據類型被導入,數據系統也會產生新的視圖。數據系統不會被鎖定在某類、或一定數量的批處理視圖中。新的視圖會在完成編碼之后,被添加到系統中,其對應的資源也會得到輕松地延展。
- 按需查詢。如有必要,批處理層可以在缺少批處理視圖時,支持臨時查詢。如果用戶可以接受臨時查詢的高延遲,那么批處理層的用途就不僅限于生成的批處理視圖了。
- 最少的維護。Lambda架構的典型模式是:批處理層使用Apache Hadoop,而服務層使用ElephantDB。顯然,兩者都很容易被維護。
- 可調試性。Lambda體系架構通過每一層的輸入和輸出,極大地簡化了計算和查詢的調試。
- 低延遲的讀取和更新。在Lambda體系架構中,速度層為大數據系統提供了對于最新數據集的實時查詢。
Lambda體系架構的缺點
事物往往都有兩面性,Lambda架構除了具有上述優點,也存在著如下缺點:
- 由于所有數據都是被追加進來,并且批處理層中的任何數據都不會被丟棄,因此系統的擴展成本必然會隨著時間的推移而增長。
- 如前文所述,批處理層可使用Hadoop或Snowflake,而速度層則可以使用Storm或Spark。顯然,這兩層雖然運行同一組數據,但是它們是在完全不同的系統上構建的。因此,用戶需要維護兩套相互獨立的系統代碼。這樣不但復雜,而且極具一定的挑戰性。
機器學習中的Lambda架構
在機器學習領域,數據量無疑是多多益善的。但是,對于機器學習應用算法、以及檢測模式而言,它們需要以一種有意義的方式,去接收數據。因此,機器學習可以受益于由Lambda架構構建的數據系統,所處理的各類數據。據此,機器學習算法可以提出各種問題,并逐漸對輸入到系統中的數據進行模式識別。
物聯網的Lambda架構
如果說機器學習利用的是Lambda架構的輸出,那么物聯網則更多地使用到了數據系統的輸入。設想一下,一個擁有數百萬輛汽車的城市,每輛汽車都裝有傳感器,并能夠發送有關天氣、空氣質量、交通狀況、位置信息、以及司機駕駛習慣等數據。這些海量數據流,會被實時饋入Lambda體系架構的批處理層和速度層,進行后續處理。可以說,物聯網設備是合理使用大數據源的絕佳示例。
流處理和Lambda架構挑戰
速度層也被稱為“流處理層”。其目標是提供最新數據的低延遲實時視圖。雖說,速度層僅關心,自完成最后一組批處理視圖以來導入的數據,但事實上它不會存儲這些小部分的數據。這些數據在流入時就會被立即處理,且在完成后被立即丟棄。因此,我們可以認為這些數據是尚未被批處理視圖所計入的數據。
Lambda體系架構在其原始理論中,提到了“最終精度(eventual accuracy)”的概念。它是指:批處理層更關注精確計算,而速度層則關注近似計算。此類近似計算最終將由下一組視圖所取代,以便系統向“最終精度”邁進。
在實際應用中,由實時處理流以毫秒為單位,持續產生的用于更新視圖的數據流,是一個非常復雜的過程。在此,我建議您將基于文檔的數據庫、索引、以及查詢系統配合在一起使用。
Lambda架構和Kappa架構之間的差異
如上所述,由于Lambda體系架構的批處理層和速度層分屬不同的分布式系統,我們需要為相似的處理方式,維護兩個單獨的代碼庫。而Kappa架構則通過完全刪除批處理層,來解決該問題。
具體而言,Kappa使用單個流處理層,既通過最新的數據計算來產生實時視圖,又對所有數據進行計算,以產生批處理視圖。就整個數據集而言,它以追加日志的形式保持原有數據不變,并且保證數據能夠快速地流過系統,以產生具有精確計算的視圖。同時,來自Lambda架構的原始“速度層”任務,也會被保留在Kappa 架構中,并持續為低延遲的視圖提供近似計算。據此,這種為單個系統生成視圖的方式,大幅簡化了系統的代碼庫。
通過Heroku上的容器實現Lambda體系架構
通過使用Docker,我們可以輕松地在啟動和試驗階段,完成對Lambda架構所需的各種工具的協調和部署。例如,我們可以使用基于容器的云平臺即服務(PaaS)--Heroku,來部署和擴展應用程序。對于批處理層,您可以使用Apache Hadoop來部署一個Docker容器;針對速度層,您可以考慮部署Apache Storm或Apache Spark;而對于服務層,您可以為Apache Cassandra或MongoDB部署Docker容器,并通過Elasticsearch來進行索引和查詢。
結論
綜上所述,Lambda架構之類的范例具有一定的擴展性和魯棒性。隨著大量數據流不斷地被導入數據系統,批處理層提供了高延遲的精度,而速度層提供了低延遲近似值。同時,速度層通過協調兩種視圖,來為查詢提供最佳的響應。當然,使用Lambda架構來實施數據系統并非易事,我們往往需要借助適當的工具,來實現部署與構建。
原文標題:An Overview of Lambda Architecture,作者: Michael Bogan
【51CTO譯稿,合作站點轉載請注明原文譯者和出處為51CTO.com】