CPU 和 GPU之異構計算的演進與發展
世界上大多數事物的發展規律是相似的,在最開始往往都會出現相對通用的方案解決絕大多數的問題,隨后會出現為某一場景專門設計的解決方案,這些解決方案不能解決通用的問題,但是在某些具體的領域會有極其出色的表現。而在計算領域中,CPU(Central Processing Unit)和 GPU(Graphics Processing Unit)分別是通用的和特定的方案,前者可以提供最基本的計算能力解決幾乎所有問題,而后者在圖形計算和機器學習等領域內表現優異。

圖 1 - CPU 和 GPU
異構計算是指系統同時使用多種處理器或者核心,這些系統通過增加不同的協處理器(Coprocessors)提高整體的性能或者資源的利用率[^1],這些協處理器可以負責處理系統中特定的任務,例如用來渲染圖形的 GPU 以及用來挖礦的 ASIC 集成電路。
中心處理單元(Central Processing Unit、CPU)[^2]一詞誕生于 1955 年,已經誕生 70 多年的 CPU 在今天已經是很成熟的技術了,不過它雖然能夠很好地處理通用的計算任務,但是因為核心數量的限制在圖形領域卻遠遠不如圖形處理單元(Graphics Processing Unit、GPU)[^3],復雜的圖形渲染、全局光照等問題仍然需要 GPU 來解決,而大數據、機器學習和人工智能等技術的發展也推動著 GPU 的演進。
今天的軟件工程師,尤其是數據中心和云計算的工程師因為異構計算的發展面對著更加復雜的場景,我們在這篇文章中主要談一談 CPU 和 GPU 的演進過程,重新回顧一下在過去幾十年的時間里,工程師為它們增加了哪些有趣的功能。
CPU
更高、更快和更強是人類永恒的追求,在科技上的進步也不例外,CPU 的主要演進方向其實只有一個:消耗最少的能源實現最快的計算速度,無數工程師的工作都是為了實現這個看起來簡單的目的。然而在 CPU 已經逐漸成熟的今天,想要提高它的性能需要花費極大的努力,我們在這一節簡單展示歷史上引入了哪些技術來提高 CPU 的性能。
制程
當我們討論 CPU 的發展時,制程(Fabrication Process)[^4]是繞不開的關鍵字,相信不了解計算機的人也都聽說過 Intel 處理器 10nm、7nm 的制程,而目前各個 CPU 制造廠商也都有各自的路線圖來實現更小的制程,例如臺積電準備在 2022 和 2023 年分別實現 3nm 和 2nm 的制造工藝。
[^4]: Wikipedia: Semiconductor device fabrication https://en.wikipedia.org/wiki/Semiconductor_device_fabrication
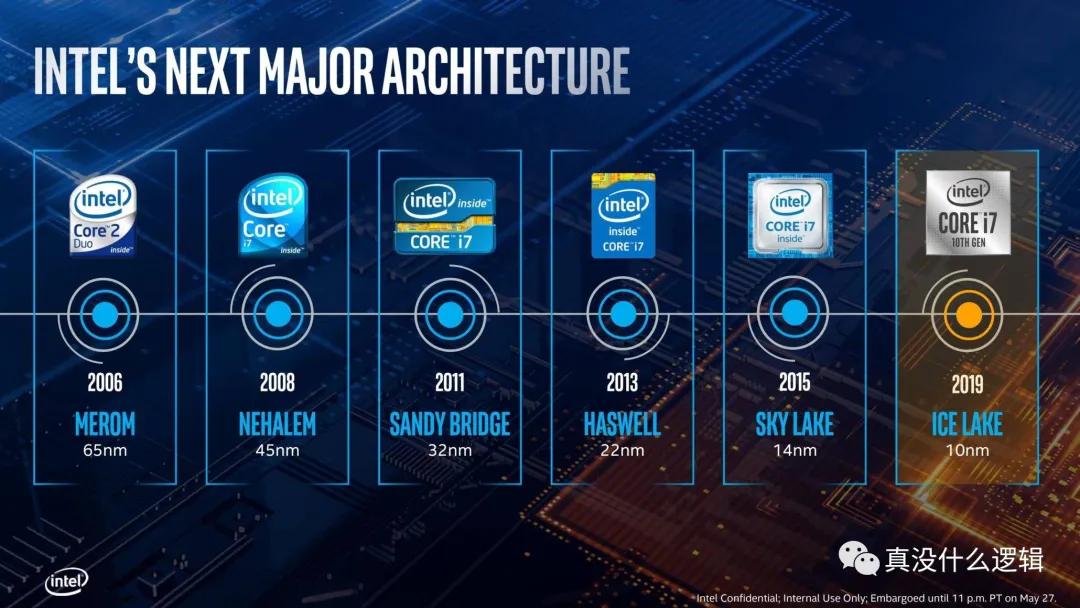
圖 2 - Intel CPU 制程
在大多數人眼中,仿佛 CPU 的制程越少就越先進,性能也會越好,但是制程并不是衡量 CPU 性能的標準,最起碼制程的演進不會直接提高 CPU 的性能。工藝制程的每次提升,都可以讓我們在單位面積內容納更多的晶體管(Transistor),只有越多的晶體管才意味著越強的性能。
越小的晶體管在開關時消耗的能量越少,既然晶體管需要一些時間充電和放電,那么消耗的能量也就越少,速度也越快,而這也解釋了為什么增加 CPU 的電壓可以提高它的運行速度。除此之外,更小的晶體管間隔使得信號的傳輸變得更快,這也能夠加快 CPU 的處理速度[^5]。
緩存
緩存也是 CPU 的重要組成部分,它能夠減少 CPU 訪問內存所需要的時間,相信很多開發者都看過如下所示的表格,我們可以看到從 CPU 的一級緩存中讀取數據大約是主存的 200 倍,哪怕是二級緩存也有將近 30 倍的提升:
| Work | Latency |
|---|---|
| L1 cache reference | 0.5 ns |
| Branch mispredict | 5 ns |
| L2 cache reference | 7 ns |
| Mutex lock/unlock | 25 ns |
| Main memory reference | 100 ns |
| Compress 1K bytes with Zippy | 3,000 ns |
| Send 1K bytes over 1 Gbps network | 10,000 ns |
| Read 4K randomly from SSD* | 150,000 ns |
| Read 1 MB sequentially from memory | 250,000 ns |
| Round trip within same datacenter | 500,000 ns |
| Read 1 MB sequentially from SSD* | 1,000,000 ns |
| Disk seek | 10,000,000 ns |
| Read 1 MB sequentially from disk | 20,000,000 ns |
| Send packet CA->Netherlands->CA | 150,000,000 ns |
表 1 - 2012 年延遲數字對比[^6]
今天的 CPU 一般都包含 L1、L2 和 L3 三級緩存,CPU 訪問這些緩存的速度僅次于訪問寄存器,雖然緩存的速度很快,但是因為高性能需要保證盡可能靠近 CPU,所以它的成本異常昂貴。Intel 等 CPU 廠商也會通過增加 CPU 緩存的方式提高性能,更大的 CPU 緩存意味著更高的緩存命中率,也意味著更快的速度。
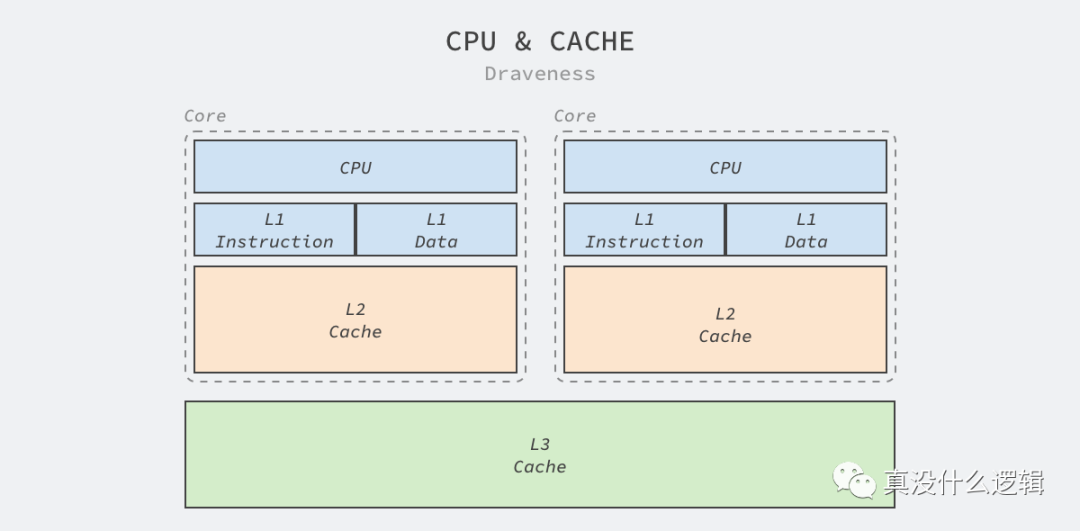
圖 3 - CPU 緩存
Intel 的處理器就在過去幾十年的時間中不斷增加 L1、L2 和 L3 的緩存大小、將 L1 和 L2 緩存集成在 CPU 中以提高訪問速度并在 L1 緩存中區分數據緩存和指令緩存以提高緩存的命中率。今天的 Core i9 處理器每個核心都有 64 KB 的 L1 緩存和 256 KB 的 L2 緩存,所有的 CPU 還會共享 16 MB 的 L3 緩存[^7]。
并行計算
多線程編程在今天幾乎已經是工程師的必修課了,主機上越來越多的 CPU 核心讓工程師不得不去思考如何才能通過多線程盡可能利用硬件的潛力,很多人可能都認為 CPU 會按照編寫的程序串行執行命令,但是真正的現實往往比這復雜得多,早在很多年前嵌入式工程師就開始嘗試在單個 CPU 上并行執行指令。
從軟件工程師的角度,我們確實可以認為每一條匯編指令都是原子操作,而原子操作意味著該操作要么處于未執行的狀態,要么處于已執行的狀態,而數據庫事務、日志以及并發控制都建立在原子操作上。不過如果再次放大指令的執行過程,我們會發現指令執行的過程并不是原子的:

圖 4 - 指令執行的步驟
不同機器架構執行指令的過程會有所差別,上面是經典的精簡指令集架構(RISC)中命令執行需要經過的 5 個步驟,其中包括獲取指令、解碼指令、執行、訪問內存以及寫回寄存器。
超標量處理器是可以實現指令級別并行的 CPU,它通過向處理器上的其他執行單元派發指令在一個時鐘周期內同時執行多條指令[^8],這里的執行單元是 CPU 內的資源,例如算術邏輯單元、浮點數單元等[^9]。
超標量設計意味著處理器會在一個時鐘周期發出多條指令,該技術往往都與指令流水線一起使用[^10],流水線會將執行拆分成多個步驟,而處理器的不同部分會分別負責這些步驟的處理,例如:因為指令的獲取和解碼由不同的執行單元處理,所以它們可以并行執行。
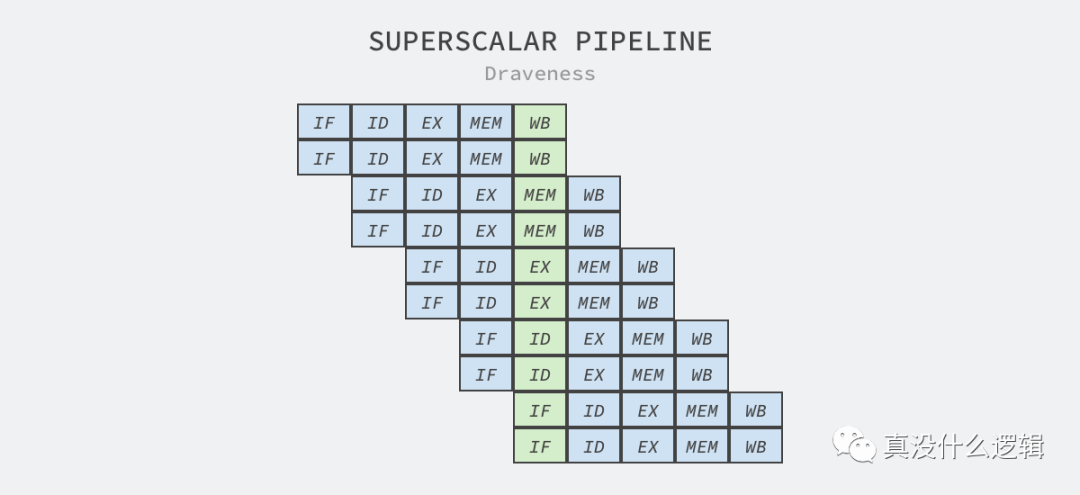
圖 5 - 超標量和流水線
除了超標量和流水線技術之外,嵌入式工程師們還引入了亂序執行以及分支預測等更加復雜的技術,其中亂序執行也被稱作動態執行,因為 CPU 執行指令時需要先將數據加載到寄存器中,所以我們分析 CPU 的寄存器操作確定哪些指令可以亂序執行。
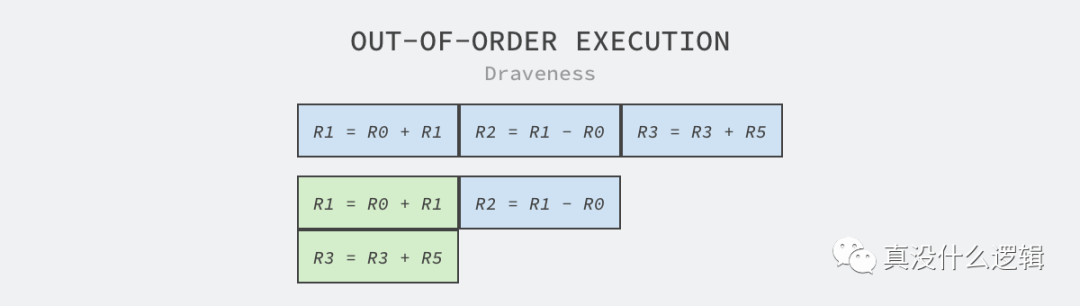
圖 6 - 亂序執行
如上圖所示,其中包含 R1 = R0 + R1、R2 = R1 - R0 和 R3 = R3 + R5 三條指令,其中第三條指令使用的兩個寄存器與前兩條無關,所以該指令可以與前兩條指令并行執行,也就能減少這段代碼執行所需要的時間。
因為分支條件是程序中的常見邏輯,當我們在 CPU 的執行中引入流水線和亂序執行之后,如果遇到條件分支仍然需要等待分支確定才繼續執行后面的代碼,那么處理器可能會浪費很多時鐘周期等待條件的確定。在計算機架構中,分支預測器是用來在分支確定前預判的數字電路,在遇到條件跳轉指令時,它會預測條件的執行結果并選擇分支執行[^11]:
如果預判正確,可以節約等待所需要的時鐘周期,提高 CPU 的利用率;
如果預判失敗,需要丟棄預判執行的全部或者部分結果,重新執行正確的分支;
因為預判失敗需要付出較大的代價,一般在 10 ~ 20 個時鐘周期之間,所以如何提高分支預測器的準確率成為了比較重要的課題,常見的實現包括靜態分支預測、動態分支預測和隨機分支預測等。
上面的這些指令級并行僅僅存在于實現細節中,CPU 的使用者在外界觀察時仍然會得到串行執行的觀察結果,所以工程師可以認為 CPU 是能夠串行執行指令的黑箱。想要充分利用多個 CPU 的資源,仍然需要工程師理解多線程模型并掌握操作系統中一些并發控制機制。
單核的超標量處理器一般被分類為單指令單數據流(Single Instruction stream, Single Data stream、SISD)處理器,而如果處理器支持向量操作,就被分為單指令多數據流(Single Instruction stream, Multiple Data streams、SIMD)處理器,而 CPU 廠商會引入 SIMD 指令來提高 CPU 的處理能力。
片內布局
前端總線是 Intel 在 1990 年在芯片中使用的通信接口,AMD 在 CPU 中也引入了類似的接口,它們的作用都是在 CPU 和內存控制器中心(也被稱作北橋)之間傳遞數據。前端總線在剛設計時不僅靈活,而且成本很低,但是這種設計很難支持芯片中越來越多的 CPU:
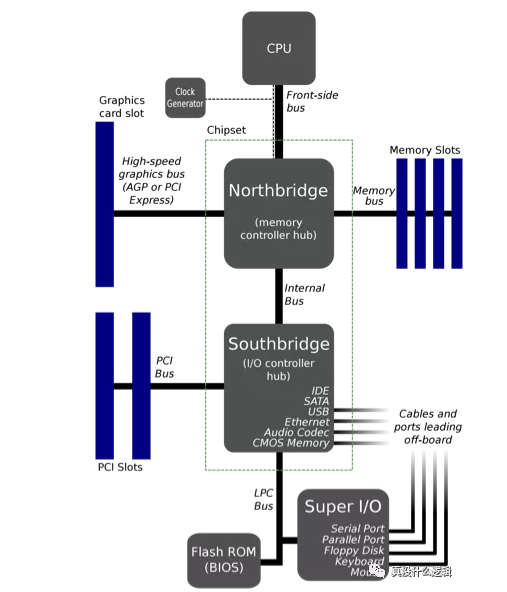
圖 7 - 常見芯片布局
如果 CPU 不能從主存中快速獲取指令和數據,那么它會花費大量的事件等待讀寫主存中的數據,所以越高端的處理器越需要高帶寬和低延遲,而速度較慢的前端總線無法滿足這樣的需求。Intel 和 AMD 分別引入了點對點連接的 HyperTransport 和 QuickPath Interconnect(QPI)機制解決這個問題,上圖中的南橋被新的傳輸機制取代了,CPU 通過集成在內部的內存控制訪問內存,通過 QPI 連接其他 CPU 以及 I/O 控制器。
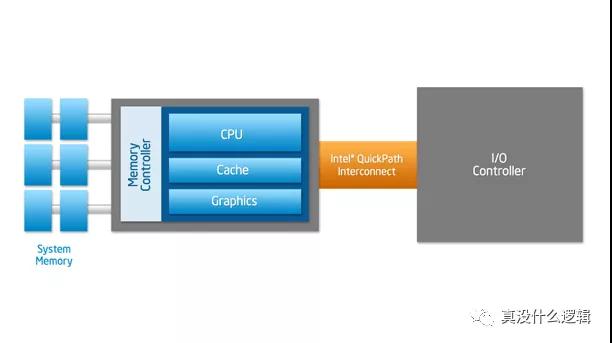
圖 8 - Intel QPI
使用 QPI 讓 CPU 直接連接其他組件確實可以提高效率,但是隨著 CPU 核心數量的增加,這種連接的方式限制了核心的數量,所以 Intel 在 Sandy Bridge 微架構中引入了如下所示的環形總線(Ring Bus)[^12]:

圖 9 - 環形總線
Sandy Bridge 在架構中引入了片內的 GPU 和視頻解碼器,這些組件也需要與 CPU 共享 L3 緩存,如果所有的組件都與 L3 緩存直接連接,那么片內會出現大量的連接,而這是芯片工程師不能接受的。片內環形總線連接了 CPU、GPU、L3 緩存、PCIe 控制器、DMI 和內存等部分,其中包含四個功能各異的環:數據、請求、確認和監聽[^13],這種設計減少了不同組件內部的連接同時也具有較好的可擴展性。
然而隨著 CPU 核心數量的繼續增加,環形的連接會不斷變大,這會增加環的大小進而影響整個環上組件之間的訪問延遲,導致該設計遇到瓶頸。Intel 由此引入了一種新的網格微架構(Mesh Interconnect Architecture)[^14]:

圖 10 - 網格架構
如上所示,Intel 的 Mesh 架構是一個二維的 CPU 陣列,網絡中有兩種不同的組件,一種是上圖中藍色的 CPU 核心,另一種是上圖中黃色的集成內存控制器,這些組件不會直接相連,相鄰的模塊會通過聚合網格站(Converged Mesh Stop、CMS)連接,這與我們今天看到的服務網格非常相似。
當不同組件需要傳輸數據時,數據包會由 CMS 負責傳輸,先縱向路由后水平路由,數據到達目標組件后,CMS 會將數據傳給 CPU 或者集成的內存控制器。
GPU
圖形處理單元(Graphics Processing Unit、GPU)是在緩沖區中快速操作和修改內存的專用電路,因為可以加速圖片的創建和渲染,所以在嵌入式系統、移動設備、個人電腦以及工作站等設備上應用都很廣泛[^15]。然而隨著機器學習和大數據的發展,很多公司都會使用 GPU 加速訓練任務的執行,這也是今天數據中心中比較常見的用例。
大多數的 CPU 不僅期望在盡可能短的時間內更快地完成任務以降低系統的延遲,還需要在不同任務之間快速切換保證實時性,正是因為這樣的需求,CPU 往往都會串行地執行任務。GPU 的設計與 CPU 完全不同,它期望提高系統的吞吐量,在同一時間竭盡全力處理更多的任務,而設計理念上的差異最終反映到了 CPU 和 GPU 的核心數量上[^16]:
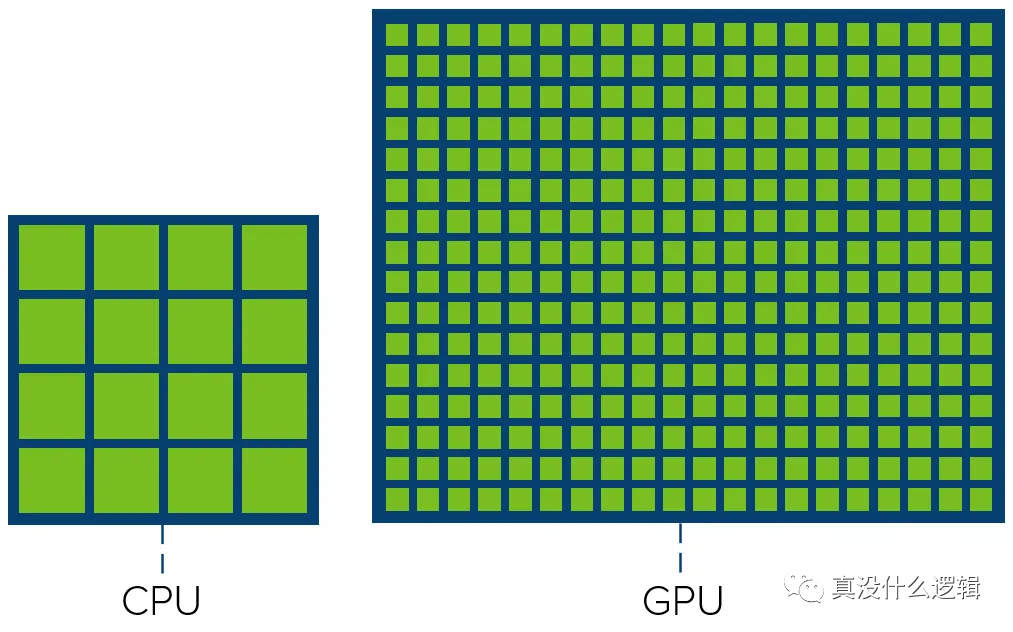
圖 11 - CPU 和 GPU 的核心
雖然 GPU 在過去幾十年的時間有著很大的發展,但是不同 GPU 的架構大同小異,我們在這里簡單介紹下面的流式多處理器中不同組件的作用:
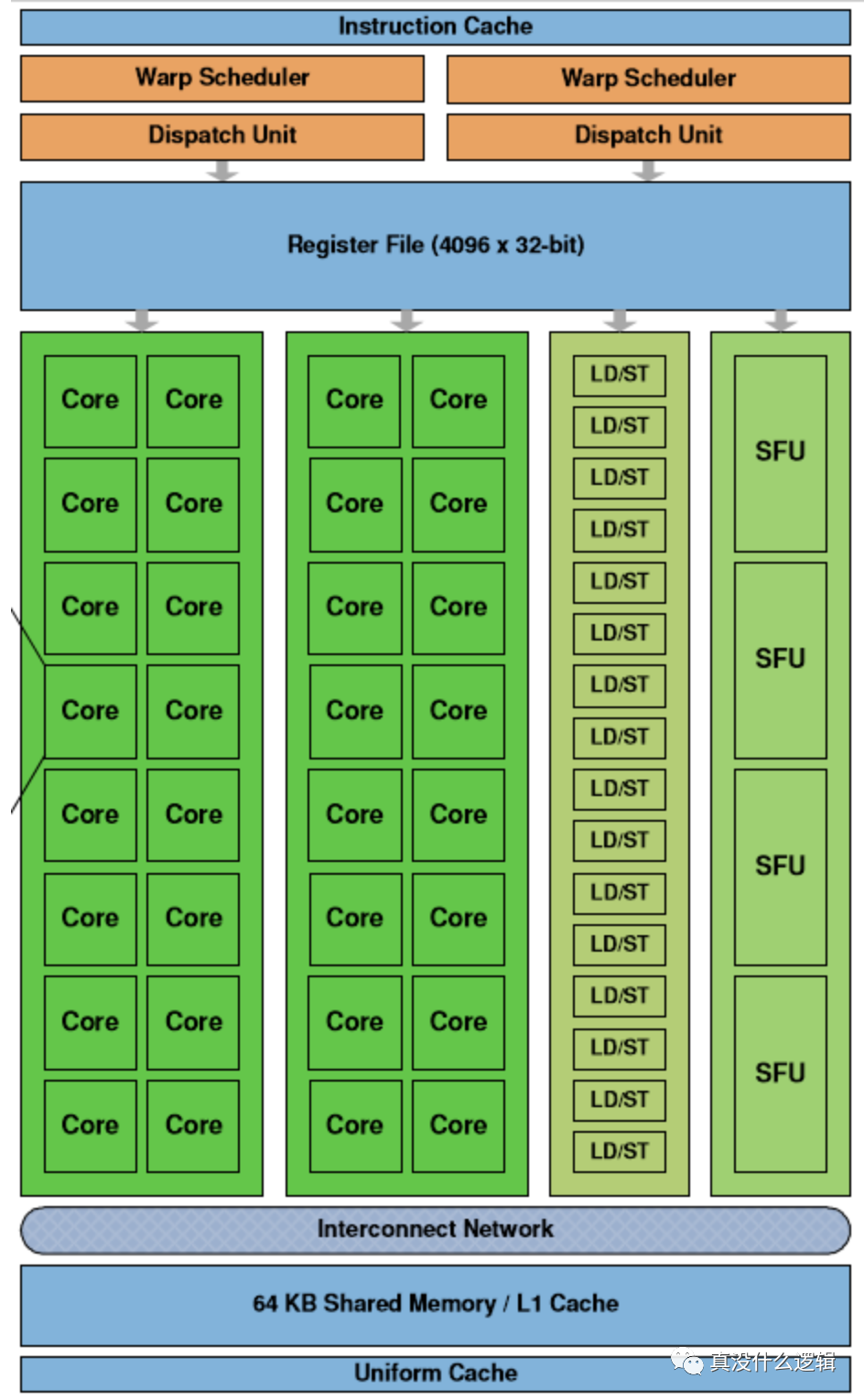
圖 12 - 流式多處理器
- 流式多處理器(Streaming Multiprocessor、SM)是 GPU 的基本單元,每個 GPU 都由一組 SM 構成,SM 中最重要的結構就是計算核心 Core,上圖中的 SM 包含以下組成部分:
- 線程調度器(Warp Scheduler):線程束(Warp)是最基本的單元,每個線程束中包含 32 個并行的線程,它們使用不同的數據執行相同的命令,調度器會負責這些線程的調度;
- 訪問存儲單元(Load/Store Queues):在核心和內存之間快速傳輸數據;
核心(Core):GPU 最基本的處理單元,也被稱作流處理器(Streaming Processor),每個核心都可以負責整數和單精度浮點數的計算;
除了上述這些組件之外,SM 中還包含特殊函數的計算單元(Special Functions Unit、SPU)以及用于存儲和緩存數據的寄存器文件(Register File)、共享內存(Shared Memory)、一級緩存和通用緩存。
水平擴容
與 CPU 一樣,增加架構中的核心數目是提高 GPU 性能和吞吐量最簡單粗暴的手段。Fermi[^17] 是 Nvidia 早期圖形處理器的微架構,在如下所示的架構中,共包含 16 個流式多處理器,512 個 CUDA 核心以及 3,000,000,000 個晶體管:
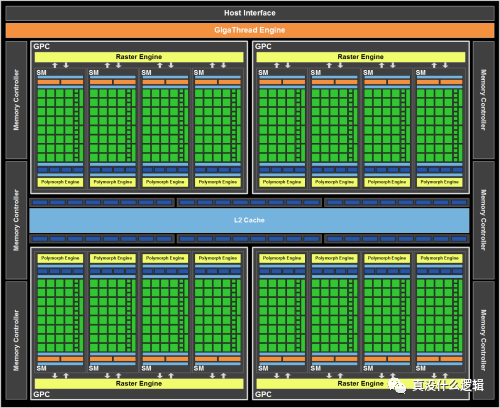
圖 13 - Nvidia Fermi 架構
除了 512 個 CUDA 核心之外,上述架構中還包含 256 個用于傳輸數據的訪問存儲單元和 64 個特殊函數單元。如果我們把 2010 年發布的 Fermi 架構和 2020 年發布的 Ampere 做一個簡單的對比,就可以發現兩者核心數量的巨大差別:
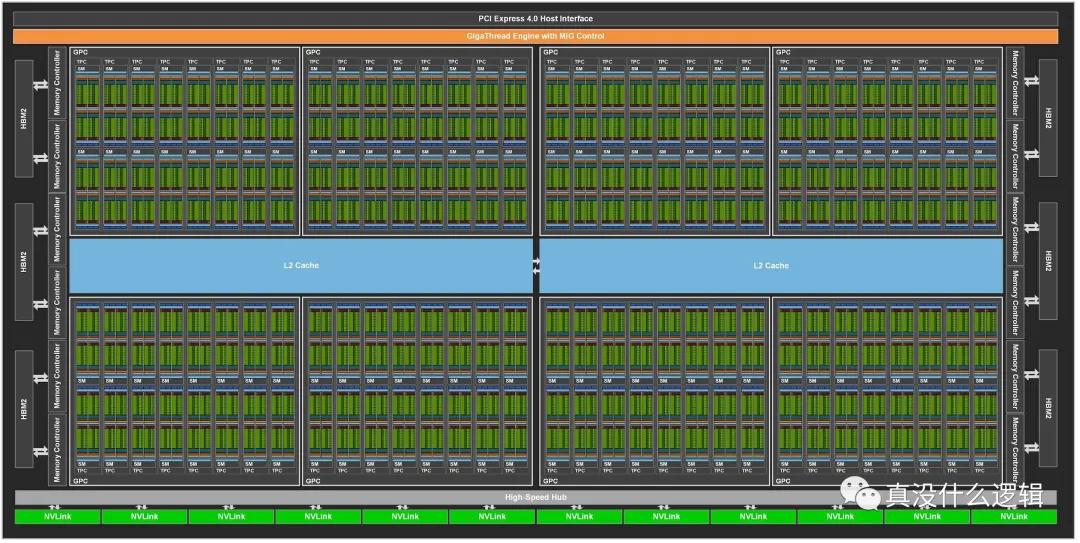
圖 14 - Nvidia Ampere 架構
Ampere 架構中的流式多處理器增加到了 128 個,而每個處理器中的核心數也增加到了 64 個,整張顯卡上一共包含 8,192 個 CUDA 核心,是 Fermi 架構中核心數量的 16 倍。為了提高系統的吞吐量,新的 GPU 架構不只擁有了更多的核心數量,它還需要更大的寄存器、內存、緩存以及帶寬滿足計算和傳輸的需求。
專用核心
最初的 GPU 僅僅是為了更快地創建和渲染圖片,它們廣泛存在于個人主機上承擔著圖像渲染的任務,但是隨著機器學習等技術的發展,GPU 中出現了更多種類的專用核心來支撐特定的場景,我們在這里介紹兩種 GPU 中存在的專用核心:張量核心(Tensor Core)和光線追蹤核心(Ray-Tracing Core):

圖 13 - 專用核心
與個人電腦上的 GPU 不同,數據中心中的 GPU 往往都會用來執行高性能計算和 AI 模型的訓練任務。正是因為社區有了類似的需求,Nvidia 才會在 GPU 中加入張量核心(Tensor Core)[^19]專門處理相關的任務。
張量核心與普通的 CUDA 核心其實有很大的區別,CUDA 核心在每個時鐘周期都可以準確的執行一次整數或者浮點數的運算,時鐘的速度和核心的數量都會影響整體性能。張量核心通過犧牲一定的精度可以在每個時鐘計算執行一次 4 x 4 的矩陣運算,它的引入使得游戲中的實時深度學習任務成為了可能,能夠加速度圖像的生成和渲染[^20]。
計算機圖形領域的圣杯是實時的全局光照,實現更好的光線追蹤可以幫助我們在屏幕上渲染更加真實的圖像,然而全局光照需要 GPU 進行大量的計算,而實時的全局光照更是對性能有著非常高的要求。傳統的 GPU 架構并不擅長光線追蹤等任務,所以 Nvidia 在 Turing 架構中首次引入了光線追蹤核心(Ray-Tracing Core、RT Core)。
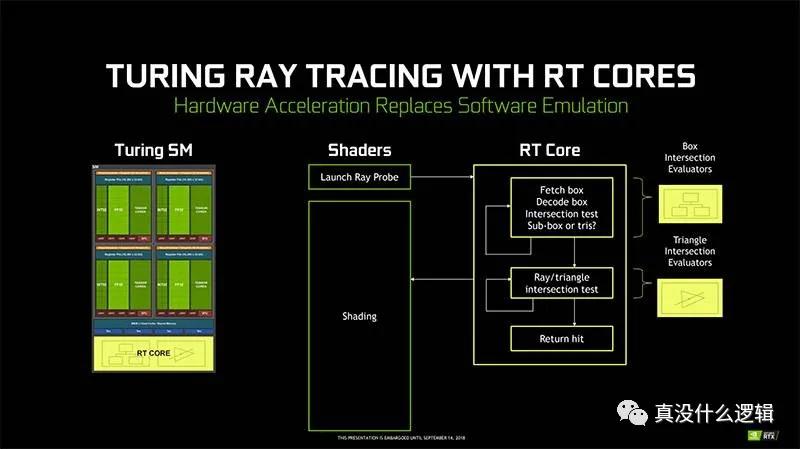
圖 16 - 光線追蹤核心
Nvidia 的光線追蹤核心實際上是為追蹤光線設計的特殊電路,光線追蹤中比較常見的算法就是 Bounding Volume Hierarchy(BVH)遍歷和光線三角形相交測試,使用流式多處理器計算該算法每條光線都會花費上千條指令[^21],而光線追蹤核心可以加速這一過程。
多租戶
今天 GPU 的性能已經非常強大,但是無論使用數據中心提供的 GPU 實例,還是自己搭建服務器運行計算任務都很昂貴,然而 GPU 算力的拆分在目前仍然是一個比較復雜的問題,運行簡單的訓練任務可能占用整塊 GPU,在這種情況下每提升一點 GPU 的利用率都可以降低一些成本。

圖 17 - 多實例 GPU
Nvidia 最新的 Ampere 架構支持多實例 GPU(Multi-Instance GPU、MIG)技術,它能夠水平切分 GPU 資源[^18]。每個 A100 GPU 都可以被拆分成 7 個 GPU 實例,每個實例都有隔離的內存、緩存和計算核心,這不僅可以滿足數據中心分割 GPU 資源的需要,還能在同一張顯卡上并行運行不同的訓練任務。
總結
從 CPU 和 GPU 的演進過程我們可以看到,所有的計算單元都受益于更精細的制作工藝,我們嘗試在相同的面積內放入更多的晶體管并增加更多的計算單元、使用更大的緩存,當這種『簡單粗暴』的方式因為物理上的瓶頸逐漸變得困難時,我們開始為特定領域設計專門的計算單元。
文中沒有提到的 ASIC 和 FPGA 是更加特殊的電路,在圖像渲染領域之外,我們可以通過設計適用于特定領域的 ASIC 和 FPGA 電路提高某一項任務的性能,OSDI ’20 的最佳論文 hXDP: Efficient Software Packet Processing on FPGA NICs[^23] 就研究了如何使用可編程的 FPGA 更高效地處理數據包的轉發,而在未來越來越多的任務會使用專門的硬件。
推薦閱讀
An Introduction to Modern GPU Arhitecture http://download.nvidia.com/developer/cuda/seminar/TDCI_Arch.pdf
Wikiwand: Tick–tock model https://www.wikiwand.com/en/Tick–tock_model
本文轉載自微信公眾號「真沒什么邏輯」,可以通過以下二維碼關注。轉載本文請聯系真沒什么邏輯公眾號。