













揭秘!阿里實時數倉分布式事務Scale Out設計
一 前言
Hybrid Transaction Analytical Processing(HTAP) 是著名信息技術咨詢與分析公司Gartner在2014年提出的一個新的數據庫系統定義,特指一類兼具OLTP能力(事務能力)和OLAP能力(分析能力)的數據庫系統。在傳統場景中,承擔OLTP任務和OLAP任務的數據庫是兩個不同的系統。典型的OLTP系統包括MySQL、PostgreSQL、PolarDB等,典型的OLAP系統包括Clickhouse、AnalyticDB等。在生產系統中,業務原始數據通常存儲在OLTP系統中,然后通過離線導入、ETL、DTS等方式以一定延遲同步到OLAP系統中,再進行后續的數據分析工作。
HTAP系統的一個直觀的優點是可以在一個系統中完成OLTP和OLAP任務,節約用戶的系統使用成本。而且,HTAP系統具備完整的ACID能力,讓開發者擁有更多的數據寫入方式,不管是實時插入、離線導入、數據單條更新,都可以輕松應對。另外,一個完備的HTAP產品,同樣是一個優秀的ETL工具,開發者可以利用HTAP系統處理常見的數據加工需求。HTAP系統能夠大大節約用戶的使用成本和開發成本,并影響上層業務系統的形態。目前,存儲計算分離、云原生技術和HTAP等技術,被業界公認為是數據庫系統目前的重要演進方向。
AnalyticDB PostgreSQL版是阿里云的一款實時數倉產品(以下簡稱ADB PG)。ADB PG采用MPP水平擴展架構,支持標準SQL 2003,兼容PostgreSQL/Greenplum,高度兼容 Oracle 語法生態,也是一款HTAP產品。ADB PG已經通過了中國信息通信研究院組織的分布式分析型數據庫和分布式事務數據庫功能和性能認證,是國內唯一一家同時通過這兩項認證的數據庫產品。ADB PG早期版本主打OLAP場景、具備OLTP能力。隨著HTAP的流行,ADB PG自6.0版本開始對OLTP性能在多個方面進行了大幅度優化,其中很重要的一個項目就是Multi-Master項目,通過Scale Out打破了原有架構的僅支持單個Master節點帶來的性能瓶頸問題,讓OLTP事務性能具備Scale out能力,更好地滿足用戶的實時數倉和HTAP需求。
Multi-Master項目在2019年啟動后,經歷了一寫多讀和多寫多讀2個演進階段,極大的提升了ADB PG系統高并發能力、實時寫入/更新/查詢的能力,在阿里內部支撐了如數據銀行等多個核心業務,也經過了阿里2020年雙11、雙12等大促的考驗。目前,產品的穩定性和性能都已經得到了廣泛驗證。在本文的如下部分,我們首先介紹ADB PG原有的Single-Master架構導致的性能瓶頸及其原因,并介紹Multi-Master的設計思路。然后我們會詳細介紹Multi-Master架構的詳細設計。之后我們會介紹我們在Multi-Master項目中所解決的幾個關鍵技術問題和核心解決方案。最后,我們會對Multi-Master架構的性能表現進行測試。
二 Single-Master架構 vs. Multi-Master架構
在數倉系統設計中,通常把系統中的節點分為Master節點和Segment節點(計算節點),Master節點和計算節點承擔不同類型的任務。以ADB PG為例,Master節點主要負責接收用戶的請求、查詢優化、任務分發、元信息管理和事務管理等任務。Segment節點負責計算任務和存儲管理任務。對于查詢請求,Master節點需要對用戶提交的SQL進行解析和優化,然后將優化后的執行計劃分發到計算節點。計算節點需要對本地存儲的數據進行讀取,然后再完成計算和數據shuffle等任務,最后計算節點把計算結果返回到Master節點進行匯總。對于建表、寫入等請求,Master節點需要對元信息、事務等進行管理,并協調計算節點之間的工作。
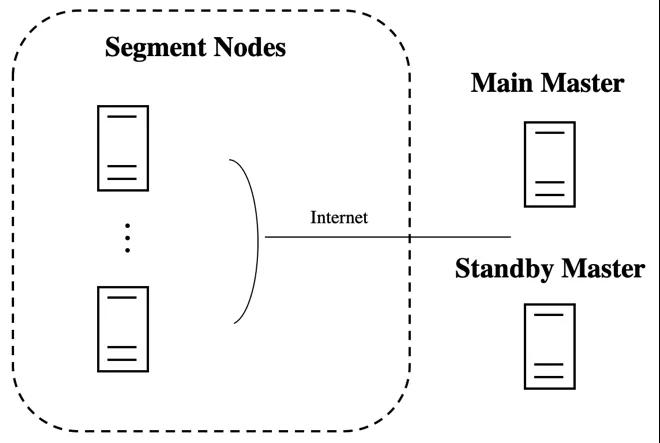
如上圖所示,ADB PG是由Greenplum演化而來,早期的ADB PG版本和Greenplum一樣,是一種單Master架構。也就是說,一個數據庫實例只有一個Main Master在工作,配置一個或者多個Standby Master節點作為高可用備份,只有當Main Master節點宕機,才會切換到Standby Master進行工作。隨著業務的發展,尤其是實時數倉和HTAP場景需求的增加, Single Master的系統瓶頸問題也逐漸顯現。對于查詢鏈路,有些查詢的最后一個階段需要在Master節點上進行最終的數據處理,消耗一定的CPU/內存資源。對于寫入場景,大量的實時插入/更新/刪除的需要高性能保證。而且Single Master架構如何處理超大并發連接數也是個問題。以上問題可以通過提高Master節點的配置(Scale up)來緩解,但是無法從根本上解決。
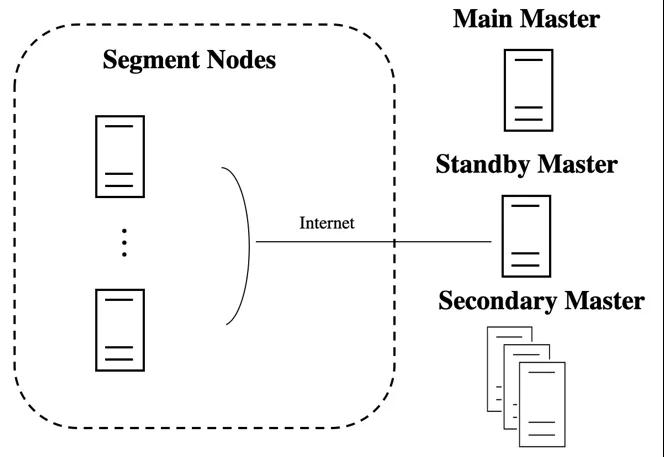
ADB PG在2019年啟動了Multi-Master項目,目標是通過節點擴展(Scale out)的方式來解決Master層的資源瓶頸問題,更好地滿足實時數倉及HTAP等業務場景的需求。上圖是Multi-master架構的示意圖,通過增加多個Secondary Master節點來實現性能的Scale out,同時保留原有的Standby Master來保證高可用能力。為了保障ADB PG的事務能力,Multi-master項目需要克服一些其他不支持事務的實時數倉不會遇到的困難。一方面,ADB PG需要對分布式事務能力進行擴展,支持多個Master的場景。一方面,對于全局死鎖處理、DDL支持以及分布式表鎖支持方面,ADB PG需要進行算法的創新和修改。最后,ADB PG需要對更新之后的新架構的集群容錯能力和高可用能力進行設計。在本文的余下部分,我們將對上述幾個議題進行介紹。
三 Multi-Master 架構設計
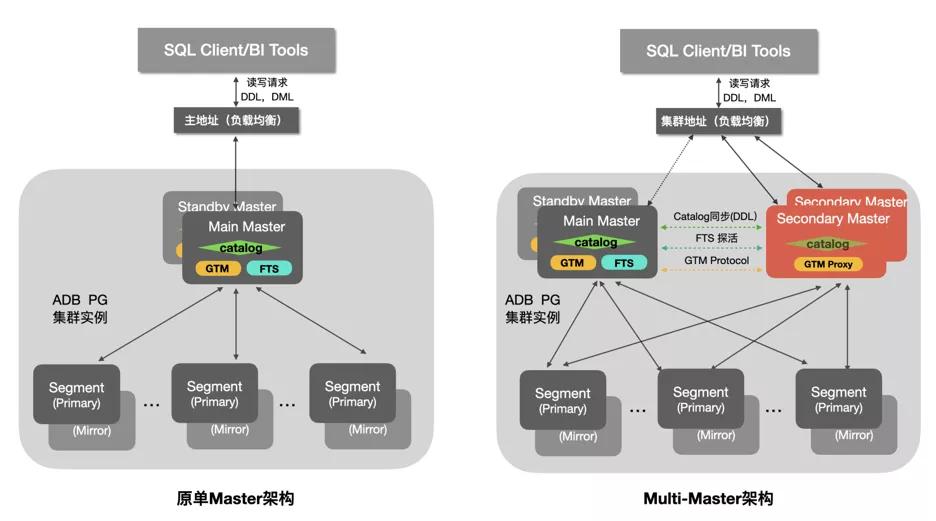
相對于原Single-Master架構,Multi-Master架構在Main Master/Standby Master的基礎之上新增實現了Secondary Master的角色,Secondary Master(s)支持承接和Main Master一樣的DDL,DML等請求,同時用戶可以按需擴展來提升系統整體能力。下面是各個Master角色及對應主要能力的簡單介紹。
Main Master:承接用戶業務請求,并把任務分發到各個計算節點進行分布式處理。除此之外,Main Master還承擔了GTM,FTS和全局元信息服務的角色,這些組件與Multi-Master的實現密切相關。
- GTM:全局事務管理(Global Transaction Manager),維護了全局的事務id及快照信息,是實現分布式事務的核心組件。
- FTS:容錯服務(Fault-Tolerance Service), 檢測計算節點及輔協調節點的健康狀態,并在計算節點發生故障時進行計算節點的Primary與Mirror角色的切換。
- Catalog:以系統表Catalog等信息為代表的全局元信息存儲。
- Standby Master:和Main Master組成典型的主備關系,在原Main Master故障的時候可以接替成為新的Main Master。
- Secondary Master:可以視為"弱化的Main Master",和Main Master一樣可以承接業務請求并將任務分發到各個計算節點進行處理。Secondary Master會通過GTM Proxy與Main Master上的GTM以及計算節點交互來實現分布式事務。
需要注意的是,Main Master與Secondary Master通過上層的SLB來做基于權重的負載均衡管理。如果是在Main Master和Secondary Master相同的規格配置下,Main Master會通過權重設置來承擔相對少的業務請求負載,從而為GTM,FTS等預留足夠的處理能力。
四 Multi-Master關鍵技術
本章將對Multi-Master的一些關鍵技術點進行詳細的介紹,主要包括分布式事務處理、全局死鎖處理、DDL支持、分布式表鎖支持、集群容錯和高可用能力。
1 分布式事務管理
ADB PG的分布式事務實現
ADB PG的分布式事務是使用二階段提交(2PC)協議來實現的,同時使用了分布式快照來保證Master和不同Segment間的數據一致性,具體實現實現要點如下。
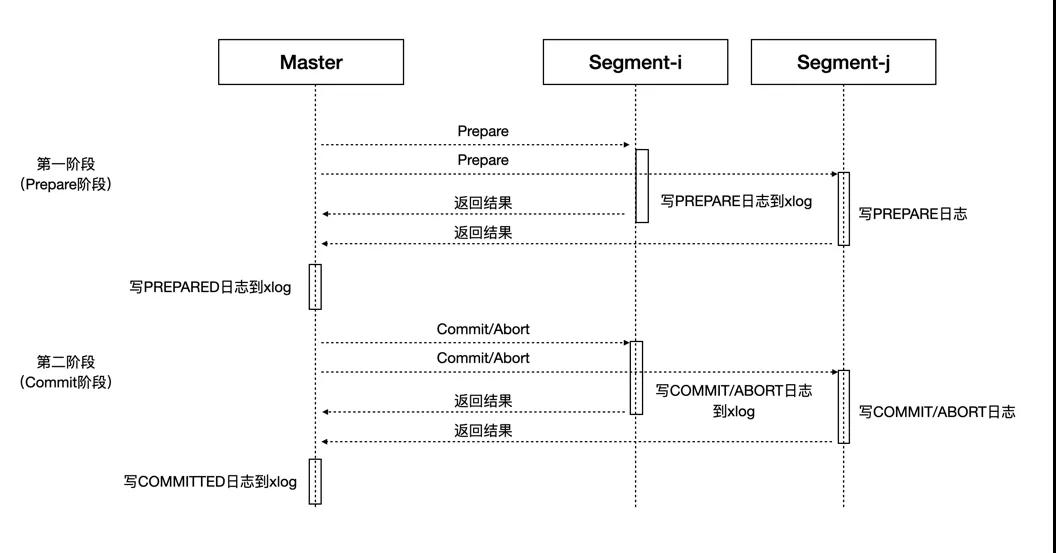
分布式事務由Main Master發起,并通過2PC協議提交到Segments。2PC是分布式系統的經典協議,將整體事務的提交過程拆分成了Prepare和Commit/Abort兩個階段,如上面的簡單示意圖所示,只有參與事務的所有Segments都成功提交整體事務才會成功提交。如果在第一階段有存在Prepare失敗的Segment,則整體事務會Abort掉;如果在第二階段有Commit失敗的Segment,而且Master已經成功記錄了PREPARED日志,則會發起重試來Retry失敗的Commits。需要說明的是,如果一個事務僅僅牽涉到1個Segment,系統會優化為按照1PC的方式來提交事務從而提升性能,具體來說就是將上圖中Master參與協調的Prepare和Commit兩個階段合二為一,最終由唯一參與的Segment來保證事務執行的原子性。
Main Master上的GTM全局事務管理組件會維護全局的分布式事務狀態,每一個事務都會產生一個新的分布式事務id、設置時間戳及相應的狀態信息,在獲取快照時,創建分布式快照并保存在當前快照中。如下是分布式快照記錄的核心信息:

執行查詢時,Main Master將分布式事務和快照等信息序列化,通過libpq協議發送給Segment上來執行。Segment反序列化后,獲得對應分布式事務和快照信息,并以此為依據來判定查詢到的元組的可見性。所有參與該查詢的Segments都使用同一份分布式事務和快照信息判斷元組的可見性,因而保證了整個集群數據的一致性。另外,和 PostgreSQL 的提交日志clog類似,ADB PG會保存全局事務的提交日志,以判斷某個事務是否已經提交。這些信息保存在共享內存中并持久化存儲在distributedlog目錄下。另外,ADB PG實現了本地事務-分布式事務提交緩存來幫助快速查到本地事務id(xid)和分布式全局事務id(gxid)的映射關系。下面讓我們通過一個例子來具體理解一下:

如上圖所示,Txn A在插入一條數據后,Txn B對該數據進行了更新。基于PostgreSQL的MVCC機制,當前Heap表中會存在兩條對應的記錄,Txn B更新完數據后會將原來tuple對應的xmax改為自身的本地xid值(由0改為4)。此后,Txn C和Txn D兩個查詢會結合自己的分布式快照信息來做可見性判斷,具體規則是:
- 如果 gxid < distribedSnapshot->xmin,則元組可見
- 如果 gxid > distribedSnapshot->xmax,則元組不可見
- 如果 distribedSnapshot->inProgressXidArray 包含 gxid,則元組不可見
- 否則元組可見。如果不能根據分布式快照判斷可見性,或者不需要根據分布式快照判斷可見性,則使用本地快照信息判斷,這個邏輯和PostgreSQL的判斷可見性邏輯一樣。
基于上述規則,Txn C查到兩條tuple記錄后,通過xid和gxid映射關系找到兩條記錄對應的gxid值(分別為100, 105),規則c會限定Txn B的更新對Txn C不可見,所以Txn C查詢到的結果是'foo';而Txn D基于規則則對Txn B更新后的tuple可見,所以查詢到的是'bar'。
Multi-Master的分布式事務實現
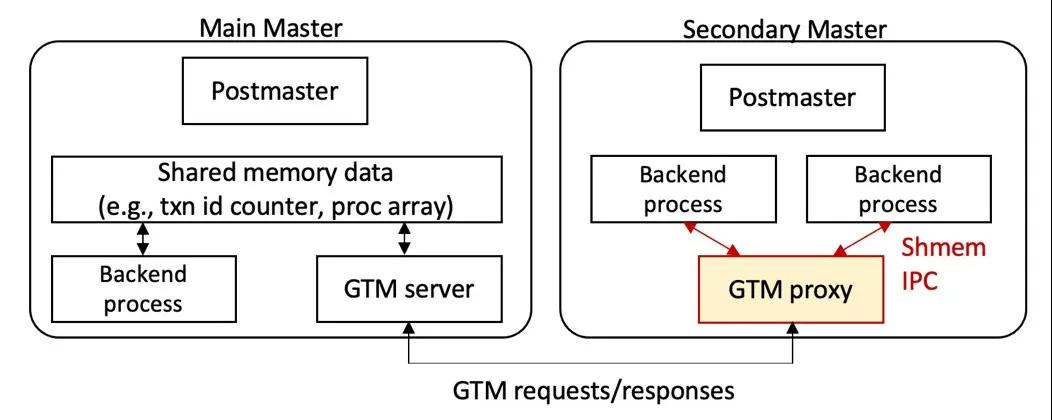
Multi-Master的分布式事務本質是在原有分布式事務基礎之上進行了增強。如上圖所示,Postmaster是守護進程,Main Master的Backend業務處理進程和GTM Server之間通過共享內存通信,但Secondary Master是無法直接通過共享內存與Main Master上的GTM Server通信的,為此,我們在Secondary Master和Main Master之間新增了一條通道并實現了一套GTM交互協議。另外,為了減少Secondary Master和Main Master之間的連接并提升網絡通信效率,我們新增實現了GTM Proxy來代理同一個Secondary Master上多個Backend進程的GTM請求。下面,本文將從GTM交互協議 、GTM Proxy和分布事務恢復三個方面來系統的闡述一下Multi-Master分布式事務實現的技術細節。
(1)GTM交互協議
GTM交互協議是Secondary Master和Main Master之間事務交互的核心協議,具體協議的消息和說明如下表所示:
| 協議核心消息 | 說明 |
| GET_GXID | 分配gxid |
| SNAPSHOT_GET | 取分布式快照 |
| TXN_BEGIN | 創建新事務 |
| TXN_BEGIN_GETGXID | 創建新事務并分配gxid |
| TXN_PREPARE | 給定的事務完成2pc的prepare階段 |
| TXN_COMMIT | 提交給定的事務 |
| TXN_ROLLBACK | 回滾給定的事務 |
| TXN_GET_STATUS | 取屬于指定master的所有事務狀態信息 |
| GET_GTM_READY | 檢查GTM server是否可服務正常事務請求 |
| SET_GTM_READY | 設置GTM server可服務正常事務請求 |
| TXN_COMMIT_RECOVERY | master恢復階段提交給定的事務 |
| TXN_ROLLBACK_RECOVERY | master恢復階段回滾給定的事務 |
| CLEANUP_MASTER_TRANS | 恢復完時清除master的剩余事務 |
可以看到,消息的核心還是在交換GXID,SNAPSHOT等信息,同時做BEGIN/PREPARE/COMMIT/ABORT等事務操作,此處就不再做一一說明。值得特別指出的是,跨節點的消息交互成本是很高的,考慮到OLAP用戶的特點和需求,我們配合協議提供了不同的一致性選項,從而讓用戶可以在性能和一致性上進行權衡和選擇:
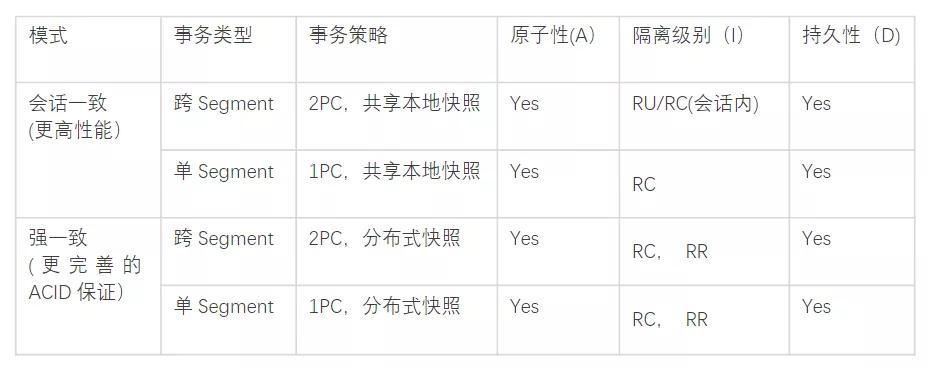
- 會話一致:同一個會話滿足可預期的一致性要求,包括單調讀,單調寫,讀自己所寫,讀后寫的一致性。
- 強一致:線性一致性,一旦操作完成,所有會話可見。也基于不同的一致性模式進行了定制和精簡。
如上表所示,如果用戶需要更高的性能而對于一致性可以做出一定妥協,則可以選擇會話一致模式,相對強一致,會話一致對協議交互進行了大幅度精簡,僅僅保留了 GET_GXID和 GET_GXID_MULTI :
| 協議核心消息 | 說明 |
| GET_GXID | 分配gxid |
| GET_GXID_MULTI | 批量分配gxid |
其中, GET_GXID_MULTI本質就是 GET_GXID的批量操作。在會話一致模式下,Secondary Master只需要從Main Master獲取全局的GXID信息,然后結合本地快照并配合重試及GDD全局死鎖檢測(后面會講到)來獨立處理事務,從而大幅度簡化與Master之間的消息交互提升性能。當然,這里的代價就是在一致性上做出的讓步,事實上,會話一致可以滿足絕大部分OLAP/HTAP客戶的訴求。
(2)GTM Proxy的實現
在Multi-Master的實現中,GTM Proxy是作為Postmaster的子進程來管理的,這樣做的好處是:1) 無需新增新的角色,配套管控更簡單;2) GTM Proxy和Backend之間是天然認證和互信的;3) GTM Proxy可以通過共享內存和Backend進程通信,這樣相比Tcp Loopback更高效,既可以減少內存拷貝,也無Network Stack開銷。
每個GTM Proxy進程會和GTM server建立一個網絡連接,并會服務多個本地的backend進程,將它們的GTM請求轉發給GTM server。GTM Proxy還針對性的做一些請求優化處理,如:
- Backends間共享Snapshot,從而減少Snapshot請求數
- 合并和批處理Backends的并發GTM請求
- 批量獲取gxid(會話一致)
GTM Proxy是減少Secondary Master和Main Master之間連接并提升網絡通信效率的關鍵。事實上,在實現中,如果用戶開啟了強一致模式,我們在Main Master上會默認開啟GTM Proxy來代理Main Master上多個Backend進程與GTM Server之間的請求,從而進一步降低GTM Server的壓力。
(3)分布式事務的恢復
在很多情況下系統都需要做分布式事務的恢復處理,比如系統/Master重啟,Main Master/Standby Master切換等,當不考慮Multi-Master,分布式事務的恢復可以簡單劃分為如下3大步驟:
- Main Master回放xlog,找出所有已經Prepared但是尚未Committed的事務;
- 命令所有Segments提交所有需要Committed的事務;
- 收集所有Segments上未Committed而且不在“Main Master”需要提交的事務列表中的事務,Abort掉這些事務。
上面的流程如果進一步考慮Multi-Master,那么一些新的問題就引入了進來,核心需要解決的有:1)Secondary Master發起的事務的恢復;2) Segments和Secondary Master上殘留Prepared階段的事務在Secondary Master或者Master重啟等情況下的恢復/清理等等。為此,針對Multi-Master,我們對二階段事務的提交和分布式事務的恢復流程都做了增強,如下主要講一下二階段事務提交的增強和Secondary Master被刪除及第一次啟動時對應的清理流程:
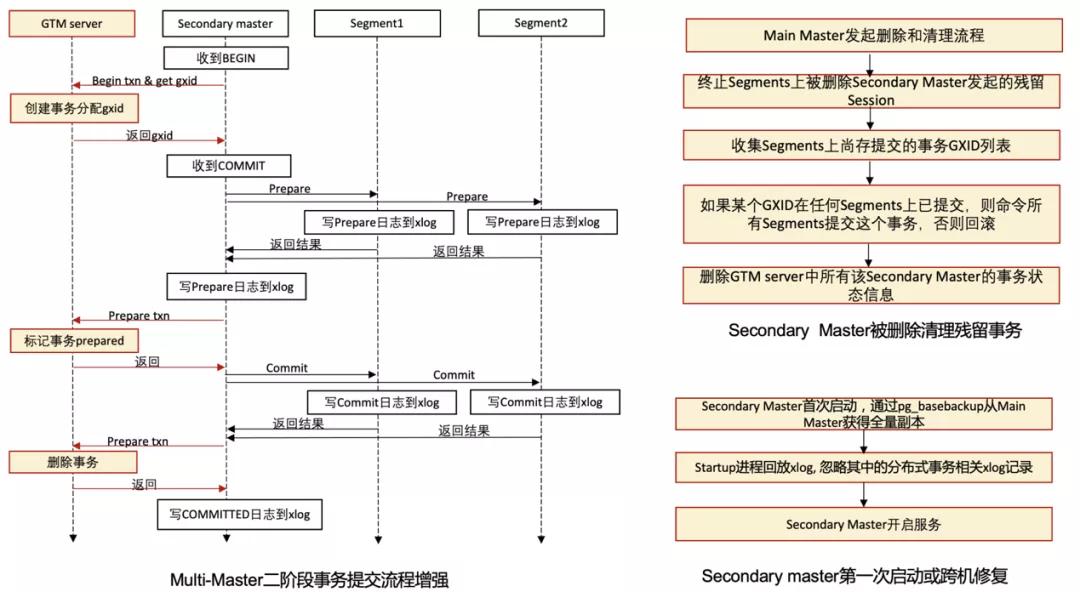
此外,Main Master/Secondary Master重啟的流程也進行了增強,這里面和原Main Master重啟恢復的主要差別是需要區分出屬于自己發起的分布式事務,具體的區分是通過增強GXID來實現的。我們在原本GXID的基本信息之上添加了masterid信息,這樣{GXID}-MasterID結合起來,就可以基于GXID來區分出具體的Master了。
2 全局死鎖檢測
ADB PG 4.3版本是通過對表加寫鎖來避免執行UPDATE和DELETE時出現全局死鎖。這個方法雖然避免了全局死鎖,但是并發更新的性能很差。ADB PG從6.0開始引入了全局死鎖檢測。該檢測進程收集并分析集群中的鎖等待信息,如果發現了死鎖則殺死造成死鎖的進程來解除死鎖,這樣極大地提高了高并發情況下簡單查詢、插入、刪除和更新操作的性能。ADB PG 6實現全局死鎖檢測的要點如下:
- 全局死鎖檢測服務進程(GDD)運行在Main Master上
- GDD會周期性獲取所有segment上的分布式事務的gxid及其等待關系
- GDD構造全局的事務等待關系圖,檢測是否成環,如果成環,則回滾環中一個事務,破解死鎖
ADB PG Multi-Master的全局死鎖檢測整體也是ADB PG 6.0版本的實現來增強的,如下圖所示:
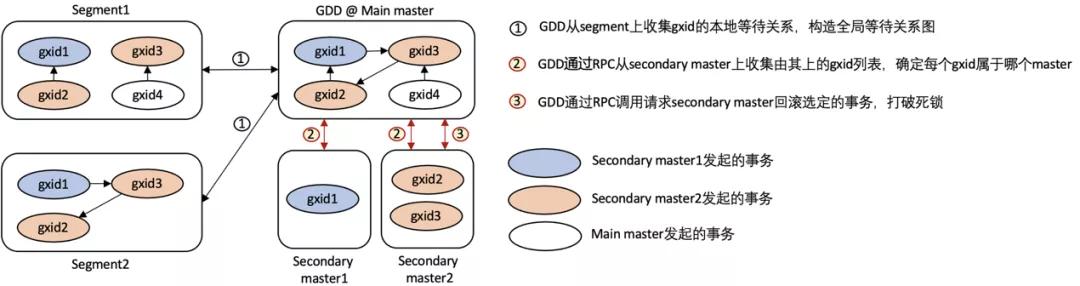
ADB PG Multi-Master的GDD也運行在Main Master之上,主要新增了兩個Master-to-Master的RPC調用來采集由Secondary Master發起的分布式事務gxid列表以及通知Secondary Master去破解負責分布式事務的死鎖。
- Get_gxids: 從每個secondary master獲取gxid列表,以判斷導致死鎖的事務各屬于哪些master
- Cancel_deadlock_txn: 如果導致死鎖的事務屬于某個secondary master,則請求該master回滾掉該事務
3 DDL支持
在ADB PG的原生實現中,Main Master對DDL的支持和與Segments上Catalog的修改同步是通過2PC的方式實現的,ADBPG Multi-Master擴展了這一實現來支持對Secondary Master上Catalog的同步。
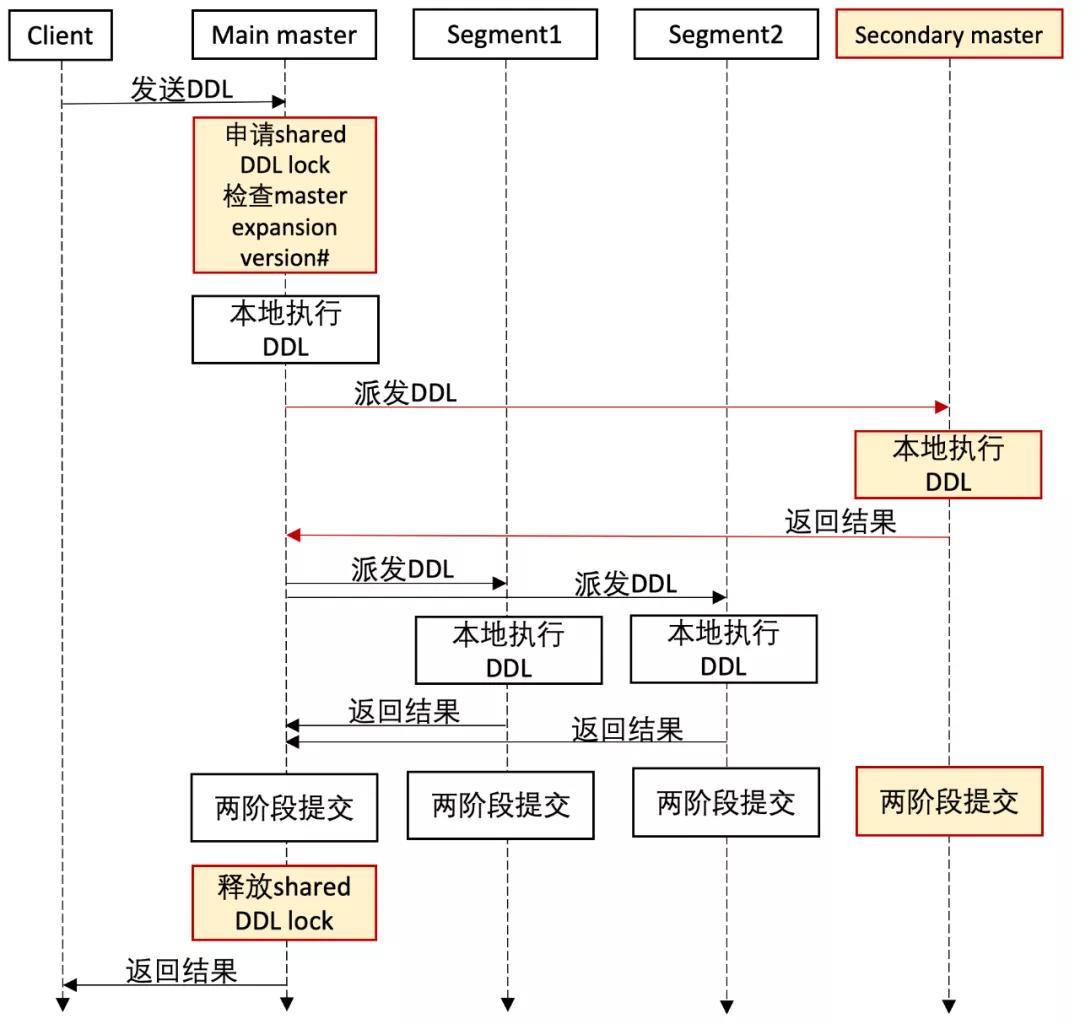
此外, Secondary Master也支持處理DDL,簡單說來,我們在Secondary Master內部實現了一個簡單的代理,Secondary Master如果收到DDL請求,會將請求轉發給Main Master來處理。具體如下圖所示:
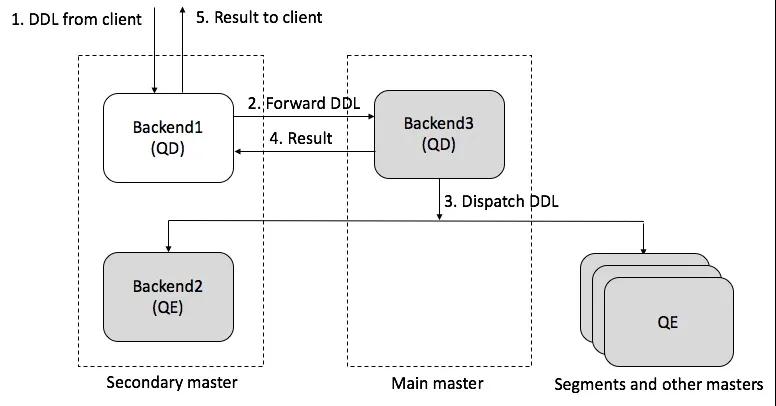
DDL的實現非常復雜,真實的落地其實要比上面復雜很多,也牽涉到很多細節,比如VACCUM/CLUSTER/ANALYZE等相對特殊的DDL處理,但整體的實現方案都基本遵從上面的原則。
4 分布式表鎖
眾所周知,在數據庫的實現里,為支持對表數據的并發訪問,一般都會通過鎖來實現。ADB PG的鎖模型和PostgreSQL是兼容的,具體如下表所示:
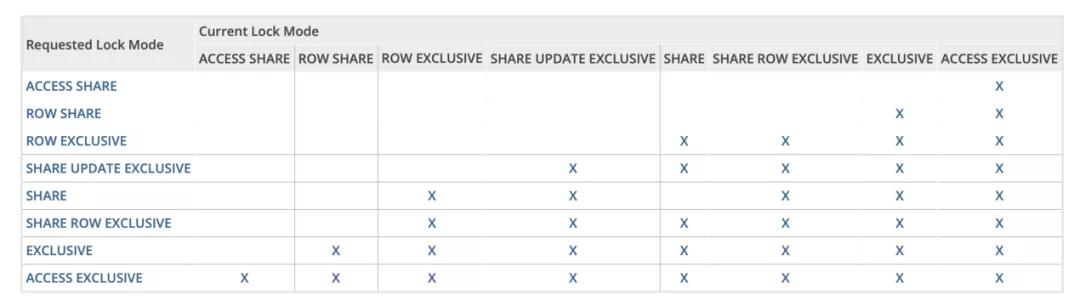
Multi-Master對ADB PG的表鎖協議進行了增強和適配,總結起來,我們定義了一套新的分布式表鎖協議來規范Main Master及Secondary Master上加鎖的順序和規則:
任意Master上的進程請求1-3級鎖
- 本地請求該表鎖
- 在所有Segments上請求該表鎖
- 事務結束時所有節點釋放鎖
Main Mater上的進程請求4-8級鎖
- 本地請求該表鎖
- 在所有Secondary master上請求該表鎖
- 在所有Segments上請求該表鎖
- 事務結束時所有節點釋放鎖
Secondary Master上的進程請求4-8級鎖
- 在Main Master上請求該表鎖
- 本地請求該表鎖
- 在所有其他Secondary Master上請求該表鎖
- 在所有Segments上請求該表鎖
- 事務結束時所有節點釋放鎖
基于上述規則,我們可以實現任何的表鎖請求會最終在某個Master或者Segment得到裁決,從而保證了對ADB PG的原表鎖協議的兼容。
5 集群容錯與高可用
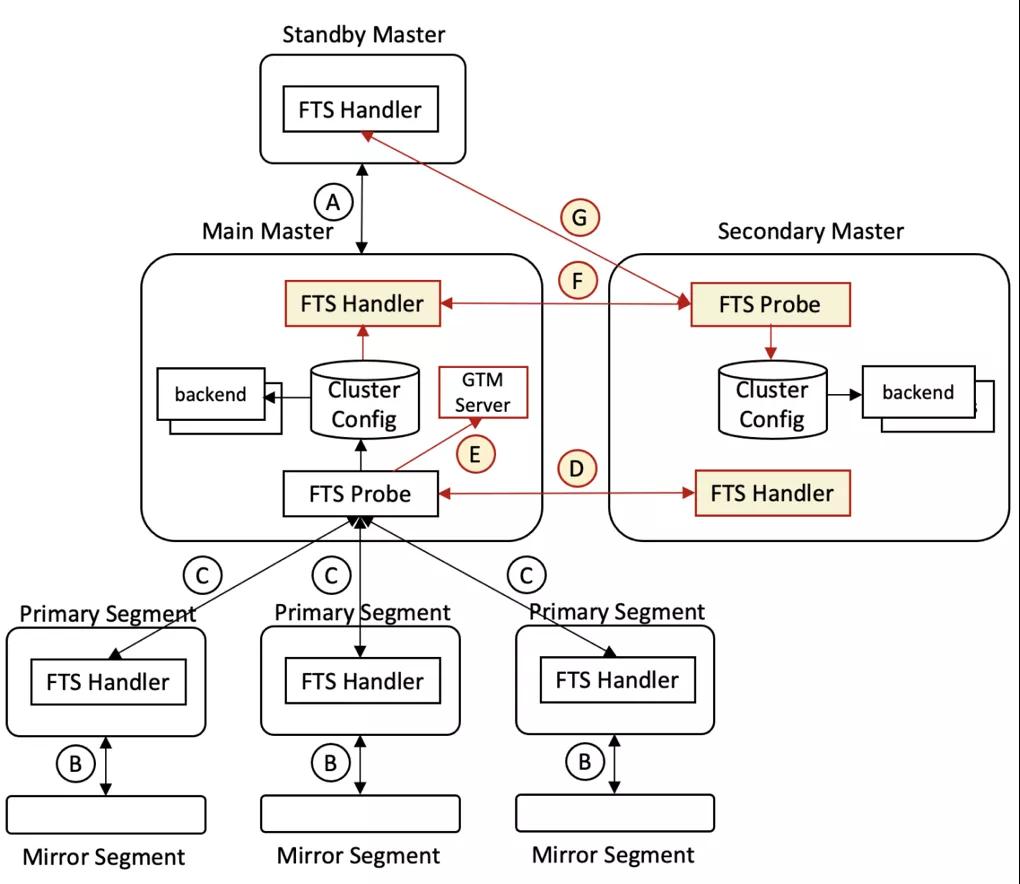
ADB PG是通過復制和監控來實現容錯和高可用的,主要包括:1)Standby Master和Mirror Segment分別為Main Master和Primary Segment提供副本(通過PG流復制實現);2)FTS在后臺負責監控與主備切換。如上圖中的流程:
- Main Master到Standby Master的流復制;
- Primary Segment到Mirror segment的流復制;
- Main Master的FTS Probe進程發包探活Primary Segment;
- Main Master的FTS Probe進程發包探活Secondary Master;
- Main Master重啟后,其FTS Probe進程向GTM Server通報所有Master;
- Secondary Master的FTS Probe發包探活Main Master,獲取最新集群配置和狀態信息并存在本地;
- Secondary Master的FTS Probe無法連接Main Master后嘗試探活Standby master,若成功則更新其為新的Main Master;否則繼續探活原Main Master。
簡單說來,ADBPG Multi-Master在原ADB PG的容錯和高可用基礎之上進行了增強,讓系統能夠進一步對Secondary Master進行兼容。另外,Secondary Master如果故障,則會進一步由管控系統看護并做實時修復。
五 Multi-master 擴展性能評測
ADB PG單Master實例在高并發點查、導入等偏OLTP的場景往往會存在單Master瓶頸,而Multi-Master的引入很好的解決了問題。為了驗證Multi-Master在OLTP負載下橫向擴展的能力,本章節對ADB PG Multi-Master在默認的會話一致模式下的TPC-B/C兩種典型負載進行了性能測試。
1 TPC-C性能測試
TPC-C是事務處理性能委員會(TPC)旗下一的一個主流性能測試Benchmark集合,主要是測試數據庫系統的事務能力。TPC-C測試過程中,會實現多種事務處理并發執行、在線與離線事務混合執行等方式,能夠比較全面地考察數據庫系統的事務能力。我們采用的測試環境是基于阿里云ECS的ADB PG實例,具體參數如下:
- Master(Main Master/Secondary Master):8c64g
- 節點規格(segment):4C32G
- 節點數量(segment): 32
- 存儲類型:ESSD云盤
- 節點存儲容量(segment): 1000GB
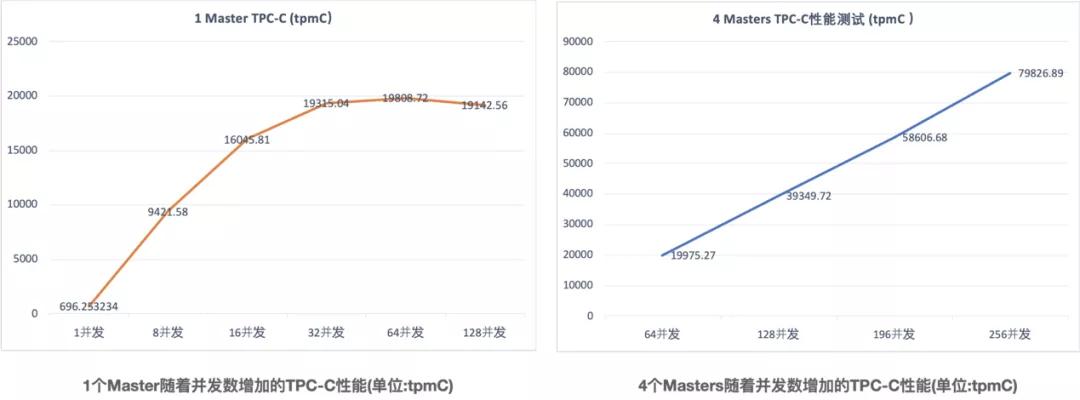
可以看到,在只有1個Master時,當并發數到達64時,TPC-C的性能基本達到峰值,無法再隨著并發數增加而增加,但是當有4個Masters時,隨著并發數的增加TPC-C的性能依舊可以非常好的線性擴展。
2 TPC-B性能測試
TPC-B是TPC旗下另一個性能測試Benchmark集合,主要用于衡量一個系統每秒能夠處理的并發事務數。我們采用的測試環境是基于阿里云ECS的ADB PG實例,具體參數如下:
- Master(Main Master/Secondary Master):8c64g
- 節點規格(segment):4C32G
- 節點數量(segment): 32
- 存儲類型:ESSD云盤
- 節點存儲容量(segment): 1000GB
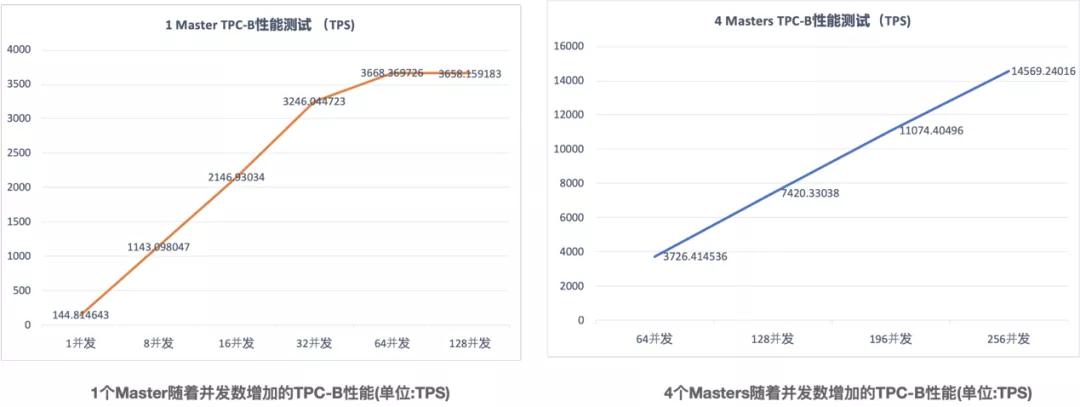
可以看到,和TPC-C類似,在只有1個Master時,當并發數到達64時,TPC-B的性能基本達到峰值,無法再隨著并發數增加而增加,但是當有4個Masters時,隨著并發數的增加TPC-B的性能依舊可以非常好的線性擴展。
六 總結
ADB PG Multi-Master通過水平擴展Master節點很好的突破了原架構單Master的限制,配合計算節點的彈性,系統整體能力尤其是連接數及讀寫性能得到進一步提升,可以更好的滿足實時數倉及HTAP等業務場景的需求。




















