













如何優(yōu)化正則表達(dá)式性能?
一.背景
正則表達(dá)式是計(jì)算機(jī)科學(xué)的一個(gè)概念,很多語言都實(shí)現(xiàn)了它。正則表達(dá)式使用一些特定的元字符來檢索、匹配以及替換符合規(guī)定的字符串。
構(gòu)造正則表達(dá)式語法的元字符,由普通字符、標(biāo)準(zhǔn)字符、限定字符(量詞)、定位符(邊界字符)組成,詳情如下:

二.正則表達(dá)式引擎
正則表達(dá)式是一個(gè)用正則符號(hào)寫出的公式,程序?qū)@個(gè)公式進(jìn)行語法分析,建立一個(gè)語法分析樹,再根據(jù)這個(gè)分析樹結(jié)合正則表達(dá)式的引擎生成執(zhí)行程序(這個(gè)執(zhí)行程序我們把它稱作狀態(tài)機(jī),也叫狀態(tài)自動(dòng)機(jī)),用于字符匹配。
而這里的正則表達(dá)式引擎就是一套核心算法,用于建立狀態(tài)機(jī)。
目前實(shí)現(xiàn)正則表達(dá)式引擎的方式有兩種:DFA自動(dòng)機(jī)(Deterministic Final Automata 確定有限狀態(tài)自動(dòng)機(jī))和 NFA(Non deterministic Finite Automaton 非確定有限狀態(tài)自動(dòng)機(jī))。
對(duì)比來看,構(gòu)造 DFA 自動(dòng)機(jī)的代價(jià)遠(yuǎn)大于 NFA 自動(dòng)機(jī),但 DFA 自動(dòng)機(jī)的執(zhí)行效率高于 NFA 自動(dòng)機(jī)。
假設(shè)一個(gè)字符串的長度是 n,如果用 DFA 自動(dòng)機(jī)作為正則表達(dá)式引擎,則匹配的時(shí)間復(fù)雜度為 O(n);如果用 NFA 自動(dòng)機(jī)作為正則表達(dá)式引擎,由于 NFA 自動(dòng)機(jī)在匹配過程中存在大量的分支和回溯,假設(shè) NFA 的狀態(tài)數(shù)為 s,則該匹配算法的時(shí)間復(fù)雜度為 O(ns)。
NFA 自動(dòng)機(jī)的優(yōu)勢(shì)是支持更多功能。例如:捕獲 group、環(huán)視、占有優(yōu)先量詞等高級(jí)功能。這些功能都是基于子表達(dá)式獨(dú)立進(jìn)行匹配,因此在編程語言里,使用的正則表達(dá)式庫都是基于 NFA 實(shí)現(xiàn)的。
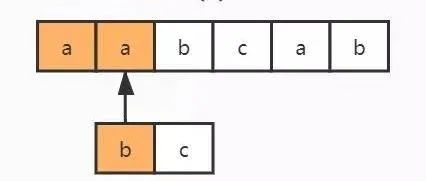
那么 NFA 自動(dòng)機(jī)到底是怎么進(jìn)行匹配的呢?接下來以下面的例子來進(jìn)行說明:
- text = "aabcab"
- regex = "bc"
NFA 自動(dòng)機(jī)會(huì)讀取正則表達(dá)式的每一個(gè)字符,拿去和目標(biāo)字符串匹配,匹配成功就換正則表達(dá)式的下一個(gè)字符,反之就繼續(xù)和目標(biāo)字符串的下一個(gè)字符進(jìn)行匹配。
分解一下過程:
1)讀取正則表達(dá)式的第一個(gè)匹配符和字符串的第一個(gè)字符進(jìn)行比較,b 對(duì) a,不匹配;繼續(xù)換字符串的下一個(gè)字符,也就是 a,不匹配;繼續(xù)換下一個(gè),是 b,匹配;
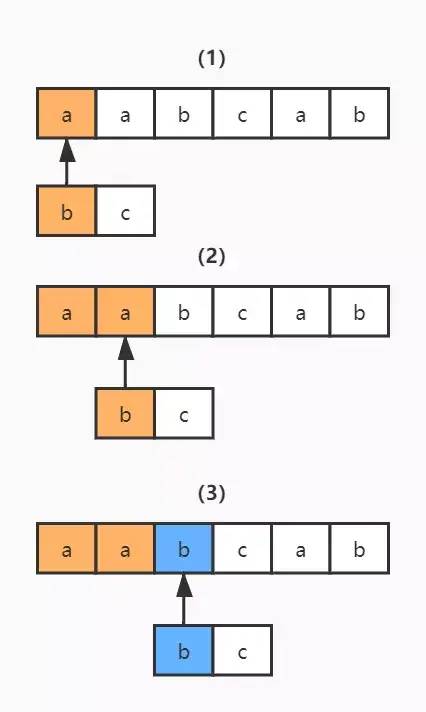
2)同理,讀取正則表達(dá)式的第二個(gè)匹配符和字符串的第四個(gè)字符進(jìn)行比較,c 對(duì) c,匹配;繼續(xù)讀取正則表達(dá)式的下一個(gè)字符,然而后面已經(jīng)沒有可匹配的字符了,結(jié)束。
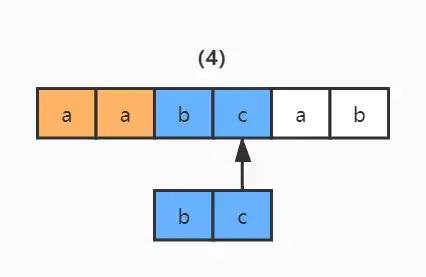
這就是 NFA 自動(dòng)機(jī)的匹配過程,雖然在實(shí)際應(yīng)用中,碰到的正則表達(dá)式都要比這復(fù)雜,但匹配方法是一樣的。
三.NFA自動(dòng)機(jī)的回溯
用 NFA 自動(dòng)機(jī)實(shí)現(xiàn)的比較復(fù)雜的正則表達(dá)式,在匹配過程中經(jīng)常會(huì)引起回溯問題。大量的回溯會(huì)長時(shí)間地占用 CPU,從而帶來系統(tǒng)性能開銷。如下面例子:
- text = "abbc"
- regex = "ab{1,3}c"
上面例子,匹配目的比較簡單。匹配以 a 開頭,以 c 結(jié)尾,中間有 1-3 個(gè) b 字符的字符串。NFA 自動(dòng)機(jī)對(duì)其解析的過程是這樣的:
1)讀取正則表達(dá)式第一個(gè)匹配符 a 和字符串第一個(gè)字符 a 進(jìn)行比較,a 對(duì) a,匹配;
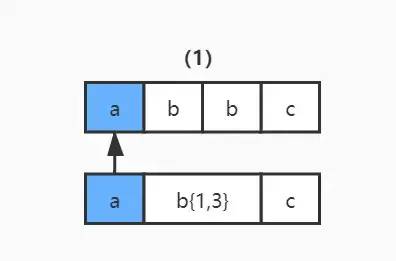
2)讀取正則表達(dá)式第一個(gè)匹配符 b{1,3} 和字符串的第二個(gè)字符 b 進(jìn)行比較,匹配。但因?yàn)?b{1,3} 表示 1-3 個(gè) b 字符串,NFA 自動(dòng)機(jī)又具有貪婪特性,所以此時(shí)不會(huì)繼續(xù)讀取正則表達(dá)式的下一個(gè)匹配符,而是依舊使用 b{1,3} 和字符串的第三個(gè)字符 b 進(jìn)行比較,結(jié)果還是匹配。
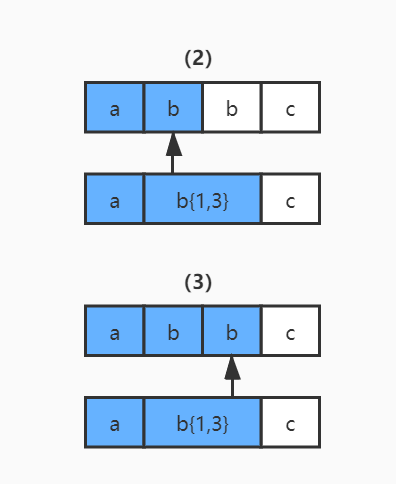
3)繼續(xù)使用 b{1,3} 和字符串的第四個(gè)字符 c 進(jìn)行比較,發(fā)現(xiàn)不匹配了,此時(shí)就會(huì)發(fā)生回溯,已經(jīng)讀取的字符串第四個(gè)字符 c 將被吐出去,指針回到第三個(gè)字符 b 的位置。
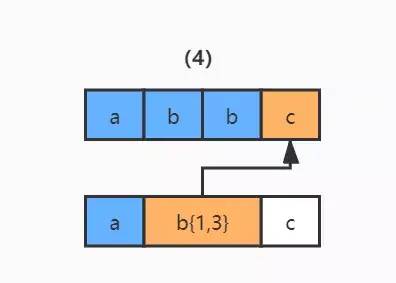
4)那么發(fā)生回溯以后,匹配過程怎么繼續(xù)呢?程序會(huì)讀取正則表達(dá)式的下一個(gè)匹配符 c,和字符串中的第四個(gè)字符 c 進(jìn)行比較,結(jié)果匹配,結(jié)束。
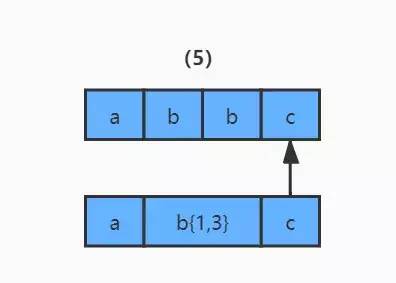
四.如何避免回溯問題?
既然回溯會(huì)給系統(tǒng)帶來性能開銷,那我們?nèi)绾螒?yīng)對(duì)呢?如果你有仔細(xì)看上面那個(gè)案例的話,你會(huì)發(fā)現(xiàn) NFA 自動(dòng)機(jī)的貪婪特性就是導(dǎo)火索,這和正則表達(dá)式的匹配模式息息相關(guān)。
1.貪婪模式(Greedy)
顧名思義,就是在數(shù)量匹配中,如果單獨(dú)使用 +、?、*或(min,max)等量詞,正則表達(dá)式會(huì)匹配盡可能多的內(nèi)容。
例如,上面那個(gè)例子:
- text = "abbc"
- regex = "ab{1,3}c"
就是在貪婪模式下,NFA自動(dòng)機(jī)讀取了最大的匹配范圍,即匹配 3 個(gè) b 字符。匹配發(fā)生了一次失敗,就引起了一次回溯。如果匹配結(jié)果是“abbbc”,就會(huì)匹配成功。
- text = "abbbc"
- regex = "ab{1,3}c"
2.懶惰模式(Reluctant)
在該模式下,正則表達(dá)式會(huì)盡可能少地重復(fù)匹配字符,如果匹配成功,它會(huì)繼續(xù)匹配剩余的字符串。
例如,上面的例子的字符后面加一個(gè)“?”,就可以開啟懶惰模式。
- text = "abc"
- regex = "ab{1,3}?c"
匹配結(jié)果是“abc”,該模式下 NFA 自動(dòng)機(jī)首先選擇最小的匹配范圍,即匹配 1 個(gè) b 字符,因此就避免了回溯問題。另外,關(guān)注公眾號(hào)Java技術(shù)棧,在后臺(tái)回復(fù):面試,可以獲取我整理的 Java 系列面試題和答案,非常齊全。
3.獨(dú)占模式(Possessive)
同貪婪模式一樣,獨(dú)占模式一樣會(huì)最大限度地匹配更多內(nèi)容;不同的是,在獨(dú)占模式下,匹配失敗就會(huì)結(jié)束匹配,不會(huì)發(fā)生回溯問題。
還是上面的例子,在字符后面加一個(gè)“+”,就可以開啟獨(dú)占模式。
- text = "abbc"
- regex = "ab{1,3}+c"
結(jié)果是不匹配,結(jié)束匹配,不會(huì)發(fā)生回溯問題。
所以綜上所述,避免回溯的方法就是:使用懶惰模式或獨(dú)占模式。
前面講述了“Split() 方法使用了正則表達(dá)式實(shí)現(xiàn)了其強(qiáng)大的分割功能,而正則表達(dá)式的性能是非常不穩(wěn)定的,使用不恰當(dāng)會(huì)引起回溯問題。”,比如使用了 split 方法提取域名,并檢查請(qǐng)求參數(shù)是否符合規(guī)定。
split 在匹配分組時(shí)遇到特殊字符產(chǎn)生了大量回溯,解決辦法就是在正則表達(dá)式后加一個(gè)需要匹配的字符和“+”解決了回溯問題:
- \\?(([A-Za-z0-9-~_=%]++\\&{0,1})+)
五.正則表達(dá)式的優(yōu)化
1.少用貪婪模式:多用貪婪模式會(huì)引起回溯問題,可以使用獨(dú)占模式來避免回溯。
2.減少分支選擇:分支選擇類型 “(X|Y|Z)” 的正則表達(dá)式會(huì)降低性能,在開發(fā)的時(shí)候要盡量減少使用。如果一定要用,可以通過以下幾種方式來優(yōu)化:
1)考慮選擇的順序,將比較常用的選擇項(xiàng)放在前面,使他們可以較快地被匹配;
2)可以嘗試提取共用模式,例如,將 “(abcd|abef)” 替換為 “ab(cd|ef)” ,后者匹配速度較快,因?yàn)?NFA 自動(dòng)機(jī)會(huì)嘗試匹配 ab,如果沒有找到,就不會(huì)再嘗試任何選項(xiàng);
3)如果是簡單的分支選擇類型,可以用三次 index 代替 “(X|Y|Z)” ,如果測(cè)試話,你就會(huì)發(fā)現(xiàn)三次 index 的效率要比 “(X|Y|Z)” 高一些。
3.減少捕獲嵌套 :
捕獲組是指把正則表達(dá)式中,子表達(dá)式匹配的內(nèi)容保存到以數(shù)字編號(hào)或顯式命名的數(shù)組中,方便后面引用。一般一個(gè)()就是一個(gè)捕獲組,捕獲組可以進(jìn)行嵌套。
非捕獲組則是指參與匹配卻不進(jìn)行分組編號(hào)的捕獲組,其表達(dá)式一般由(?:exp)組成。
在正則表達(dá)式中,每個(gè)捕獲組都有一個(gè)編號(hào),編號(hào) 0 代表整個(gè)匹配到的內(nèi)容。可以看看下面的例子:
- public static void main(String[] args) {
- String text = "<input high=\"20\" weight=\"70\">test</input>";
- String reg = "(<input.*?>)(.*?)(</input>)";
- Pattern p = Pattern.compile(reg);
- Matcher m = p.matcher(text);
- while (m.find()){
- System.out.println(m.group(0));//整個(gè)匹配到的內(nèi)容
- System.out.println(m.group(1));//<input.*?>
- System.out.println(m.group(2));//(.*?)
- System.out.println(m.group(3));//(</input>)
- }
- }
- =====運(yùn)行結(jié)果=====
- <input high="20" weight="70">test</input>
- <input high="20" weight="70">
- test
- </input>
如果你并不需要獲取某一個(gè)分組內(nèi)的文本,那么就使用非捕獲組,例如,使用 “(?:x)” 代替 “(X)” ,例如下面的例子:
- public static void main(String[] args) {
- String text = "<input high=\"20\" weight=\"70\">test</input>";
- String reg = "(?:<input.*?>)(.*?)(?:</input>)";
- Pattern p = Pattern.compile(reg);
- Matcher m = p.matcher(text);
- while (m.find()) {
- System.out.println(m.group(0));//整個(gè)匹配到的內(nèi)容
- System.out.println(m.group(1));//(.*?)
- }
- }
- =====運(yùn)行結(jié)果=====
- <input high="20" weight="70">test</input>
- test


















