













面試侃集合 | SynchronousQueue公平模式篇
面試官:呦,小伙子來的挺早啊!
Hydra:那是,不能讓您等太久了啊(別廢話了快開始吧,還趕著去下一場呢)。
面試官:前面兩輪表現還不錯,那我們今天繼續說說隊列中的SynchronousQueue吧。
Hydra:好的,SynchronousQueue和之前介紹過的隊列相比,稍微有一些特別,必須等到隊列中的元素被消費后,才能繼續向其中添加新的元素,因此它也被稱為無緩沖的等待隊列。
我還是先寫一個例子吧,創建兩個線程,生產者線程putThread向SynchronousQueue中放入元素,消費者線程takeThread從中取走元素:
- SynchronousQueue<Integer> queue=new SynchronousQueue<>(true);
- Thread putThread=new Thread(()->{
- for (int i = 0; i <= 2; i++) {
- try {
- System.out.println("put thread put:"+i);
- queue.put(i);
- System.out.println("put thread put:"+i+" awake");
- } catch (InterruptedException e) {
- e.printStackTrace();
- }
- }
- });
- Thread takeThread=new Thread(()->{
- int j=0;
- while(j<2){
- try {
- j=queue.take();
- System.out.println("take from putThread:"+j);
- } catch (InterruptedException e) {
- e.printStackTrace();
- }
- }
- });
- putThread.start();
- Thread.sleep(1000);
- takeThread.start();
執行上面的代碼,查看結果:
- put thread put:0
- take from putThread:0
- put thread put:0 awake
- put thread put:1
- take from putThread:1
- put thread put:1 awake
- put thread put:2
- take from putThread:2
- put thread put:2 awake
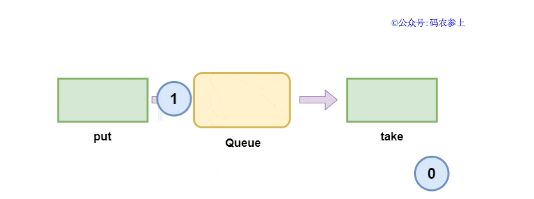
可以看到,生產者線程在執行put方法后就被阻塞,直到消費者線程執行take方法對隊列中的元素進行了消費,生產者線程才被喚醒,繼續向下執行。簡單來說運行流程是這樣的:
面試官:就這?應用誰不會啊,不講講底層原理就想蒙混過關?
Hydra:別急啊,我們先從它的構造函數說起,根據參數不同,SynchronousQueue分為公平模式和非公平模式,默認情況下為非公平模式
- public SynchronousQueue(boolean fair) {
- transferer = fair ? new TransferQueue<E>() : new TransferStack<E>();
- }
我們先來看看公平模式吧,該模式下底層使用的是TransferQueue隊列,內部節點由QNode構成,定義如下:
- volatile QNode next; // next node in queue
- volatile Object item; // CAS'ed to or from null
- volatile Thread waiter; // to control park/unpark
- final boolean isData;
- QNode(Object item, boolean isData) {
- this.item = item;
- this.isData = isData;
- }
item用來存儲數據,isData用來區分節點是什么類型的線程產生的,true表示是生產者,false表示是消費者,是后面用來進行節點匹配(complementary )的關鍵。在SynchronousQueue中匹配是一個非常重要的概念,例如一個線程先執行put產生了一個節點放入隊列,另一個線程再執行take產生了一個節點,這兩個不同類型的節點就可以匹配成功。
面試官:可是我看很多資料里說SynchronousQueue是一個不存儲元素的阻塞隊列,這點你是怎么理解的?
Hydra:通過上面節點中封裝的屬性,可以看出SynchronousQueue的隊列中封裝的節點更多針對的不是數據,而是要執行的操作,個人猜測這個說法的出發點就是隊列中存儲的節點更多偏向于操作這一屬性。
面試官:好吧,接著往下說隊列的結構吧。
Hydra:TransferQueue中主要定義的屬性有下面這些:
- transient volatile QNode head;
- transient volatile QNode tail;
- transient volatile QNode cleanMe;
- TransferQueue() {
- QNode h = new QNode(null, false); // initialize to dummy node.
- head = h;
- tail = h;
- }
比較重要的有頭節點head、尾節點tail、以及用于標記下一個要刪除的節點的cleanMe節點。在構造函數初始化中創建了一個節點,注釋中將它稱為dummy node,也就是偽造的節點,它的作用類似于AQS中的頭節點的作用,實際操作的節點是它的下一個節點。
要說SynchronousQueue,真是一個神奇的隊列,不管你調用的是put和offer,還是take和poll,它都一概交給核心的transfer方法去處理,只不過參數不同。今天我們拋棄源碼,通過畫圖對它進行分析,首先看一下方法的定義:
- E transfer(E e, boolean timed, long nanos);
面試官:呦呵,就一個方法?我倒要看看它是怎么區分實現的入隊和出隊操作…
Hydra:在方法的參數中,timed和nanos用于標識調用transfer的方法是否是能夠超時退出的,而e是否為空則可以說明是生產者還是消費者調用的此方法。如果e不為null,是生產者調用,如果e為null則是消費者調用。方法的整體邏輯可以分為下面幾步:
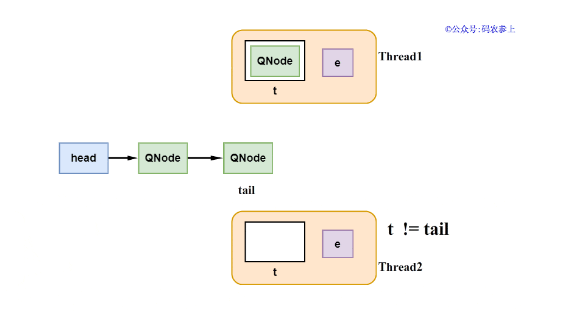
1、若隊列為空,或隊列中的尾節點類型和自己的類型相同,那么準備封裝一個新的QNode添加到隊列中。在添加新節點到隊尾的過程中,并沒有使用synchronized或ReentrantLock,而是通過CAS來保證線程之間的同步。
在添加新的QNode到隊尾前,會首先判斷之前取到的尾節點是否發生過改變,如果有改變的話那么放棄修改,進行自旋,在下一次循環中再次判斷。當檢查隊尾節點沒有發生改變后,構建新的節點QNode,并將它添加到隊尾。
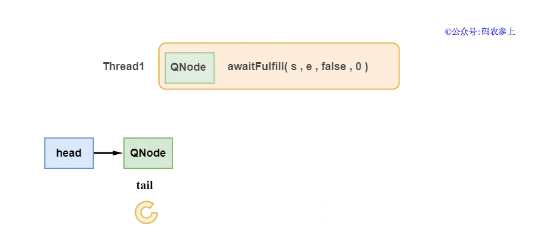
2、當新節點被添加到隊尾后,會調用awaitFulfill方法,會根據傳遞的參數讓線程進行自旋或直接掛起。方法的定義如下,參數中的timed為true時,表示這是一個有等待超時的方法。
- Object awaitFulfill(QNode s, E e, boolean timed, long nanos);
在awaitFulfill方法中會進行判斷,如果新節點是head節點的下一個節點,考慮到可能很快它就會完成匹配后出隊,先不將它掛起,進行一定次數的自旋,超過自旋次數的上限后再進行掛起。如果不是head節點的下一個節點,避免自旋造成的資源浪費,則直接調用park或parkNanos掛起線程。
3、當掛起的線程被中斷或到達超時時間,那么需要將節點從隊列中進行移除,這時會執行clean()方法。如果要被刪除的節點不是鏈表中的尾節點,那么比較簡單,直接使用CAS替換前一個節點的next指針。
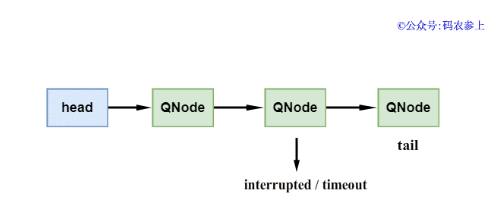
如果要刪除的節點是鏈表中的尾節點,就會有點復雜了,因為多線程環境下可能正好有其他線程正在向尾節點后添加新的節點,這時如果直接刪除尾節點的話,會造成后面節點的丟失。
這時候就會用到TransferQueue中定義的cleanMe標記節點了,cleanMe的作用就是當要被移除的節點是隊尾節點時,用它來標記隊尾節點的前驅節點。具體在執行過程中,又會分為兩種情況:
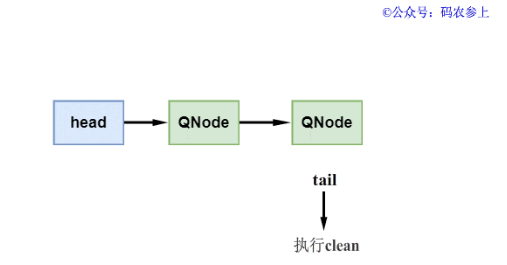
- cleanMe節點為null,說明隊列在之前沒有標記需要刪除的節點。這時會使用cleanMe來標識該節點的前驅節點,標記完成后退出clean方法,當下一次執行clean方法時才會刪除cleanMe的下一個節點。
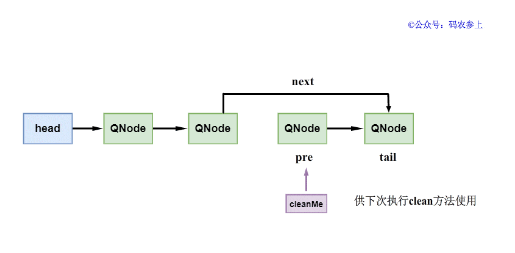
- cleanMe節點不為null,那么說明之前已經標記過需要刪除的節點。這時刪除cleanMe的下一個節點,并清除當前cleanMe標記,并再將當前節點未修改前的前驅節點標記為cleanMe。注意,當前要被刪除的節點的前驅節點不會發生改變,即使這個前驅節點已經在邏輯上從隊列中刪除掉了。
執行完成clean方法后,transfer方法會直接返回null,說明入隊操作失敗。
面試官:講了這么多,入隊的還都是一個類型的節點吧?
Hydra:是的,TransferQueue隊列中,只會存在一個類型的節點,如果有另一個類型的節點過來,那么就會執行出隊的操作了。
面試官:好吧,那你接著再說說出隊方法吧。
Hydra:相對入隊來說,出隊的邏輯就比較簡單了。因為現在使用的是公平模式,所以當隊列不為空,且隊列的head節點的下一個節點與當前節點匹配成功時,進行出隊操作,喚醒head節點的下一個節點,進行數據的傳遞。
根據隊列中節點類型的不同,可以分為兩種情況進行分析:
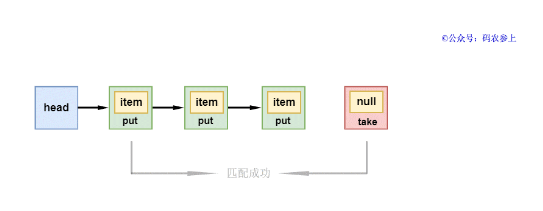
1、如果head節點的下一個節點是put類型,當前新節點是take類型。take線程取出put節點的item的值,并將其item變為null,然后推進頭節點,喚醒被掛起的put線程,take線程返回item的值,完成數據的傳遞過程。
head節點的下一個節點被喚醒后,會推進head節點,雖然前面說過隊列的head節點是一個dummy節點,并不存儲數據,理論上應該將第二個節點直接移出隊列,但是源碼中還是將head節點出隊,將原來的第二個節點變成了新的head節點。
2、同理,如果head節點的下一個節點是take類型,當前新節點是put類型。put線程會將take節點的item設為自己的數據值,然后推進頭節點,并喚醒掛起的take線程,喚醒的take線程最終返回從put線程獲得的item的值。
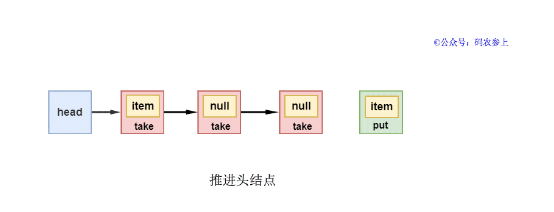
此外,在take線程喚醒后,會將自己QNode的item指針指向自己,并將waiter中保存的線程置為null,方便之后被gc回收。
面試官:也就是說,在代碼中不一定非要生產者先去生產產品,也可以由消費者先到達后進行阻塞等待?
Hydra:是的,兩種線程都可以先進入隊列。
面試官:好了,公平模式下我是明白了,我去喝口水,給你十分鐘時間,回來我們聊聊非公平模式的實現吧。
本文轉載自微信公眾號「碼農參上」,可以通過以下二維碼關注。轉載本文請聯系碼農參上公眾號。
















