













一篇帶給你Go語言的并發(fā)
并發(fā)
前言
在學習 Go 的并發(fā)之前,先復習一下操作系統(tǒng)的基礎知識。
并發(fā)與并行
先來理一理并發(fā)與并行的區(qū)別。
- 并行:指的是在同一時間,多個程序在不同的 CPU 上共同運行,互相之間并沒有對 CPU 資源進行競爭。比如,我在看書的時候,左手用來翻書,右手做筆記,兩者可以同時進行。
- 并發(fā):如果系統(tǒng)只有一個 CPU,有多個程序要運行,系統(tǒng)只能將 CPU 的時間劃分為多個時間片,然后分配給不同的程序。比如,我看書的時候,只能用右手翻完書之后,才能騰出手來做筆記。
可是明確的是并發(fā)≠并行,但是只要 CPU 運行足夠快,每個時間片劃分足夠小,就會給人們造成一種假象,認為計算機在同一時刻做了多個事情。
進程、線程、協程
進程是一個程序執(zhí)行的過程,也是系統(tǒng)進行資源分配和調度的基本單位。簡單來說,一個進程就是我們電腦上某個獨立運行的程序。
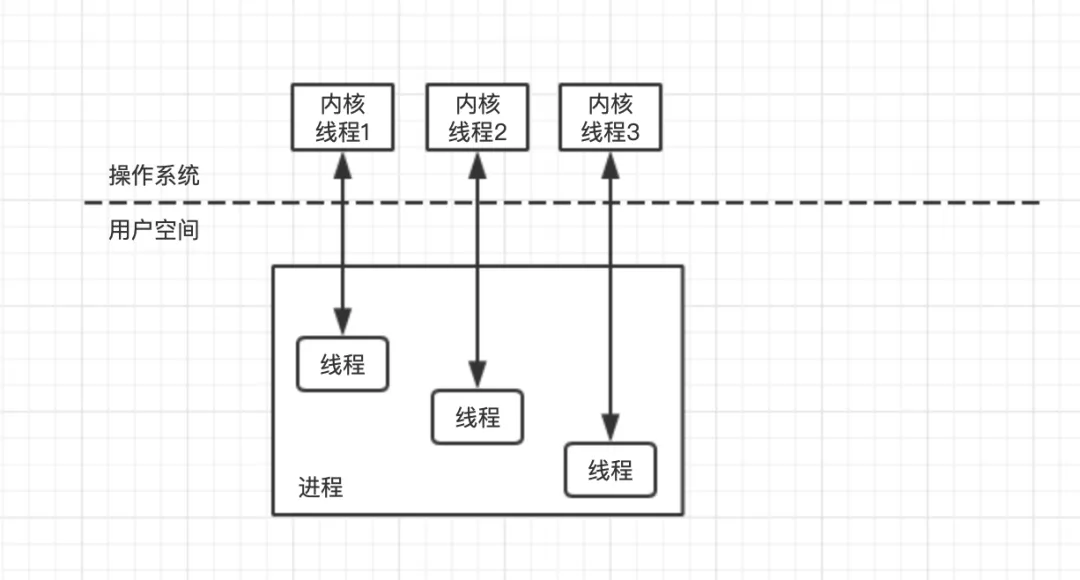
而線程是系統(tǒng)能夠調度的最小單位,它被包含在進程里面,是進程中的實際運作單位,一個進程可以包含多個線程。可以將進程理解為一個工廠,而工廠里面的工人就是線程。就像工廠里面必須要有一個工人才能工作一樣,每個進程里面也必須有一個線程才能工作。比如,JavaScript 就被成為單線程的語言,說明 JavaScript 工廠里面只有一個打工人,這個打工人就是工頭,稱為主線程。多線程的進程中也會有一個主線程,主線程一般隨著進程一起創(chuàng)建和銷毀。
進程與線程都是操作系統(tǒng)上的概念,程序中如果要進行進程或者線程的切換,在切換的過程中,需要先保存當線程的狀態(tài),然后恢復另一個線程的狀態(tài),這是需要耗費時間的,如果是進程的切換還可能跨 CPU,無法利用 CPU 緩存,導致進程比線程的切換成本更加高昂。
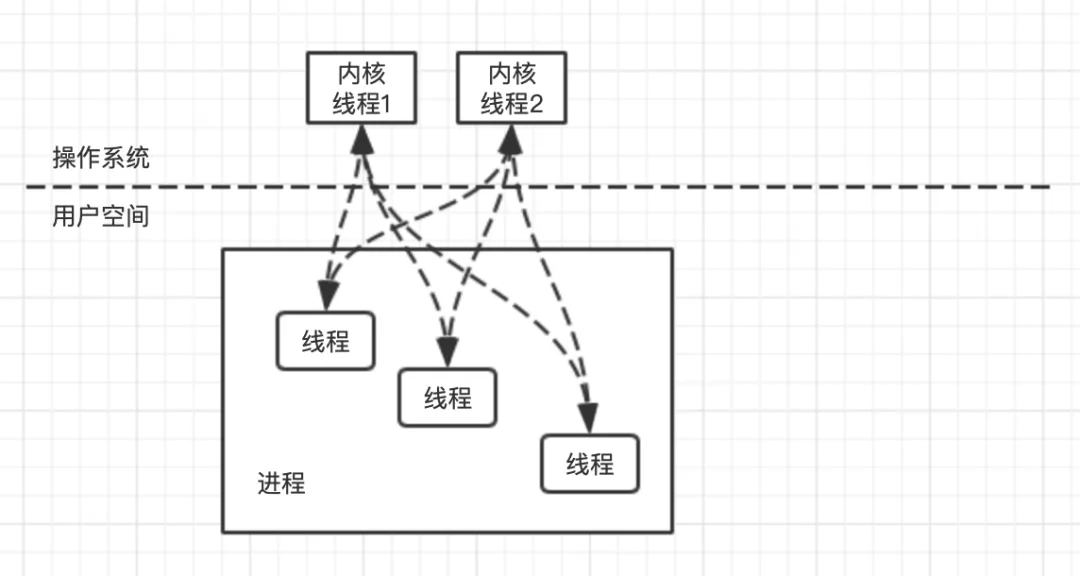
所以,除了系統(tǒng)級別的內核線程外,一些程序中創(chuàng)建了用戶線程這一說,這么做可以減少與操作系統(tǒng)交互,將線程的切換控制在程序內,這種用戶態(tài)的線程被稱為協程。用戶線程的切換完全由程序控制,實際上使用的內核線程就只存在一個,內核線程與用戶線程之間的關系為一對多。雖然這樣做可以減少線程上下文切換帶來的開銷,但是,無法避免阻塞的問題。一旦某個用戶線程被阻塞會導致內核線程的阻塞,無法進行用戶線程進行切換,從而整個進程都被掛起,

協程
Go 語言中的線程模型既不是使用內核線程,也不是完全的用戶線程,而是一種混合型的線程模型。用戶線程與內核線程的對應關系為多對多,用戶線程與內核線程動態(tài)關聯,當某個線程出現阻塞的時候,可以動態(tài)切換到另外的內核線程上。
G-P-M模型
上面只是 Go 語言中抽象層面的線程模型,具體是如何進行線程調度的,還是看看 Go 語言的代碼。
- func log(msg string) {
- fmt.Println(msg)
- }
- func main() {
- log("hello")
- go log("world")
- }
之前的文章介紹過,Go 程序在運行時,默認以 main 函數為入口,main 函數中運行的代碼會到一個 goroutine 中運行。如果我們在調用的函數前,加上一個 go 關鍵詞,那么這個函數就放到另外一個 goroutine 中運行。
這里說的 goroutine 就是 Go 語言中的用戶線程,也就是協程。Go 語言在運行時,會建立一個 G-P-M 模型,這個模型專門負責 goroutine 的調度。
- G:gotoutine(用戶線程);
- P:processor(邏輯處理器);
- M:machine(機器資源);
每個 goroutine 都會放到一個 goroutine 隊列中,由于是用戶自主創(chuàng)建,上下文的切換成本極低。P(processor)的主要作用是管理用戶線程,將 goroutine 合理的安排到內核線程上,也就是這個模型的 M。通常情況下,G 的數量遠遠多于 M。

Goroutine
如果你有運行過上面的代碼,你會發(fā)現,go 關鍵詞后的函數并沒有真正執(zhí)行。
- func log(msg string) {
- fmt.Println(msg)
- }
- func main() {
- log("hello")
- go log("world")
- }
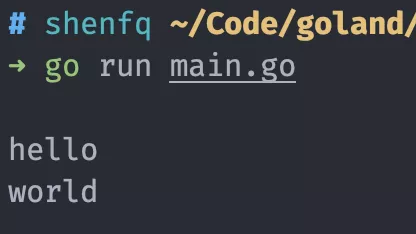
運行后,終端只輸出了 hello,并沒有輸出 world。
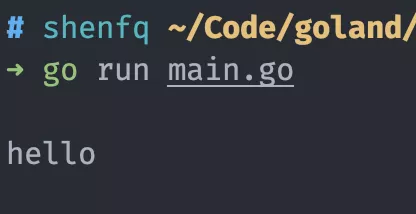
這是因為 main 函數會在主 goroutine 中運行,類似于主線程,而每個 go 語句會啟動一個新的 goroutine,啟動后的 goroutine 并不會直接執(zhí)行,而是會放入一個 G 隊列中,等待 P 的分配。但是主 goroutine 結束后,就意味著程序結束了,G 隊列中的 goroutine 還沒有等到執(zhí)行時間。所以,go 語句后的函數是一個異步的函數,go 語句調用后,會立即去執(zhí)行后面的語句,而不會等待 go 語句后的函數執(zhí)行。
如果要 world 輸出,我們可以在 main 函數后面加一個休眠,延長主 goroutine 的執(zhí)行時間。
- import (
- "fmt"
- "time"
- )
- func log(msg string) {
- fmt.Println(msg)
- }
- func main() {
- fmt.Println()
- log("hello")
- go log("world")
- time.Sleep(time.Millisecond * 500)
- }
通道
多線程編程中,由于各個線程之間需要共享數據,一般采用的是共享內存的方案。但是這么做,勢必會出現多個線程同時修改同一份數據情況,為了保證數據的安全性,需要為數據加鎖,處理起來就比較麻煩。
所以在 Go 語言社區(qū)有一句名言:
不要通過共享內存來通信,而應該通過通信來共享內存。
創(chuàng)建通道
這里說的通信的方式,就是 Go 語言中的通道(channel)。通道是 Go 語言中的一種特殊類型,需要通過 make 方法創(chuàng)建一個通道。
- ch := make(chan int) // 創(chuàng)建一個 int 類型的通道
創(chuàng)建通道的時候,需要加上一個類型,表示該通道傳輸數據的類型。也可以通過指定一個空接口的方式,創(chuàng)建一個可以傳送任意數據的通道。
- ch := make(chan interface{})
創(chuàng)建的通道分為無緩存通道和有緩存通道,make 方法的第二個參數表示可緩存的數量(如果傳入 0,效果和不傳一樣)。
- ch := make(chan string, 0) // 無緩存通道,傳入
- ch := make(chan string, 1)
發(fā)送和接收數據
通道創(chuàng)建后,通過 <- 符號來接收和發(fā)送數據。
- ch := make(chan string)
- ch <- "hello world" // 發(fā)送一個字符串
- msg := <- ch // 接收之前發(fā)送的字符串
實際在這個代碼運行的時候,會提示一個錯誤。
- fatal error: all goroutines are asleep - deadlock!
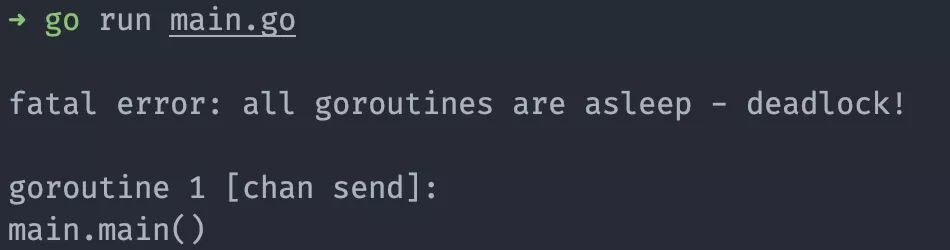
表明當前的 goroutine 處于掛起狀態(tài),并且后續(xù)不會有響應,只能直接中斷程序。因為這里創(chuàng)建的是無緩存通道,發(fā)送數據后通道不會將數據緩存在通道中,導致后面要找通道要數據的時候無法正常從通道中獲取數據。我們可以將通道的緩存設置為 1,讓通道可以緩存一個數據在里面。
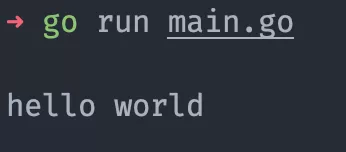
- ch := make(chan string, 1)
- ch <- "hello world" // 發(fā)送一個字符串
- msg := <- ch // 接收之前發(fā)送的字符串
- fmt.Println(msg)
但是如果發(fā)送的數據超出了緩存數量,或者接受數據時,緩存里面已經沒有數據了,依然會報錯。
- ch := make(chan string, 1)
- ch <- "hello world"
- ch <- "hello world"
- // fatal error: all goroutines are asleep - deadlock!
- ch := make(chan string, 1)
- ch <- "hello world"
- <- ch
- <- ch
- // fatal error: all goroutines are asleep - deadlock!
協程中使用通道
那么無緩存的通道中,應該怎么發(fā)送和接收數據呢?這就需要將通道與協程進行結合,也就是 Go 語言中常用的并發(fā)的開發(fā)模式。
無緩存的通道在收發(fā)數據時,由于一次只能同步的發(fā)送一個數據,會在兩個 goroutine 間反復橫跳,通道在接受數據時,會阻塞當前 goroutine,直到通道在另一個 goroutine 發(fā)送了數據。
- ch := make(chan string) // 創(chuàng)建一個無緩存通道
- temp := "我在地球"
- go func () {
- // 接收一個字符串
- ch <- "hello world"
- temp = "進入了異次元"
- }()
- // 運行到這里會被阻塞
- // 直到通道在另一個 goroutine 發(fā)送了數據
- msg := <- ch
- fmt.Println(msg)
- fmt.Println("temp =>", temp)
為了證明通道在接收數據時會被阻塞,我們可以在前面加上一個 temp 變量,然后在另外的 goroutine 中修改這個變量,看最后輸出的值是否被修改,以此證明通道在接受數據時是否發(fā)生了阻塞。
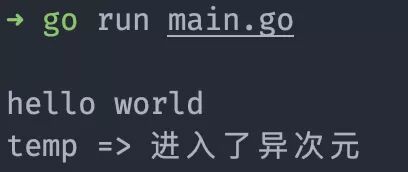
運行結果已經證明,當通道接收數據時,阻塞了主 goroutine 的執(zhí)行。除了主動的從通道里面一條條的獲取數據,還可以通過 range 的方式循環(huán)獲取數據。
- ch := make(chan string)
- go func() {
- for i := 0; i < 5; i++ {
- ch <- fmt.Sprintf("數據 %d", i)
- }
- close(ch)
- }()
- for data := range ch {
- fmt.Println("接收 =>", data)
- }

如果使用 range 循環(huán)讀取通道中的數據時,在數據發(fā)送完畢時,需要調用 close(ch) ,將通道關閉。
實戰(zhàn)
在了解了前面的基礎知識之后,我們可以通過協程 + 通道的寫一段爬蟲,來實戰(zhàn)一下 Go 語言的并發(fā)能力。
首先確定爬蟲需要爬取的網站,由于個人比較喜歡看電影,所以決定爬一爬豆瓣的電影 TOP 榜單。
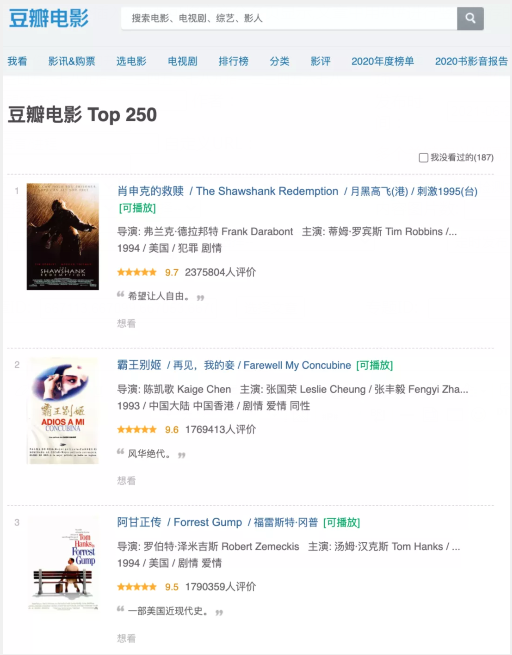
其域名為 https://movie.douban.com/top250,翻到第二頁后,域名為 https://movie.douban.com/top250?start=25 ,第三頁的域名為 https://movie.douban.com/top250?start=50,說明每次這個 TOP 榜單每頁會有 25 部電影,每次翻頁就給 start 參數加上 25。
- const limit = 25 // 每頁的數量為 25
- const total = 100 // 爬取榜單的前 100 部電影
- const page = total / limit // 需要爬取的頁數
- func main() {
- var start int
- var url string
- for i :=0; i < page; i++ {
- start := i * limit
- // 計算得到所有的域名
- url := "https://movie.douban.com/top250?start=" + strconv.Itoa(start)
- }
- }
然后,我們可以構造一個 fetch 函數,用于請求對應的頁面。
- func fetch(url string) {
- // 構造請求體
- req, _ := http.NewRequest("GET", url, nil)
- // 由于豆瓣會校驗請求的 Header
- // 如果沒有 User-Agent,http code 會返回 418
- req.Header.Add("User-Agent", "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.114 Safari/537.36")
- // 發(fā)送請求
- client := &http.Client{}
- rsp, _ := client.Do(req)
- // 斷開連接
- defer rsp.Body.Close()
- }
- func main() {
- for i :=0; i < page; i++ {
- url := ……
- go fetch(url, ch)
- }
- }
然后使用 goquery 來解析 HTML,提取電影的排名以及電影名。
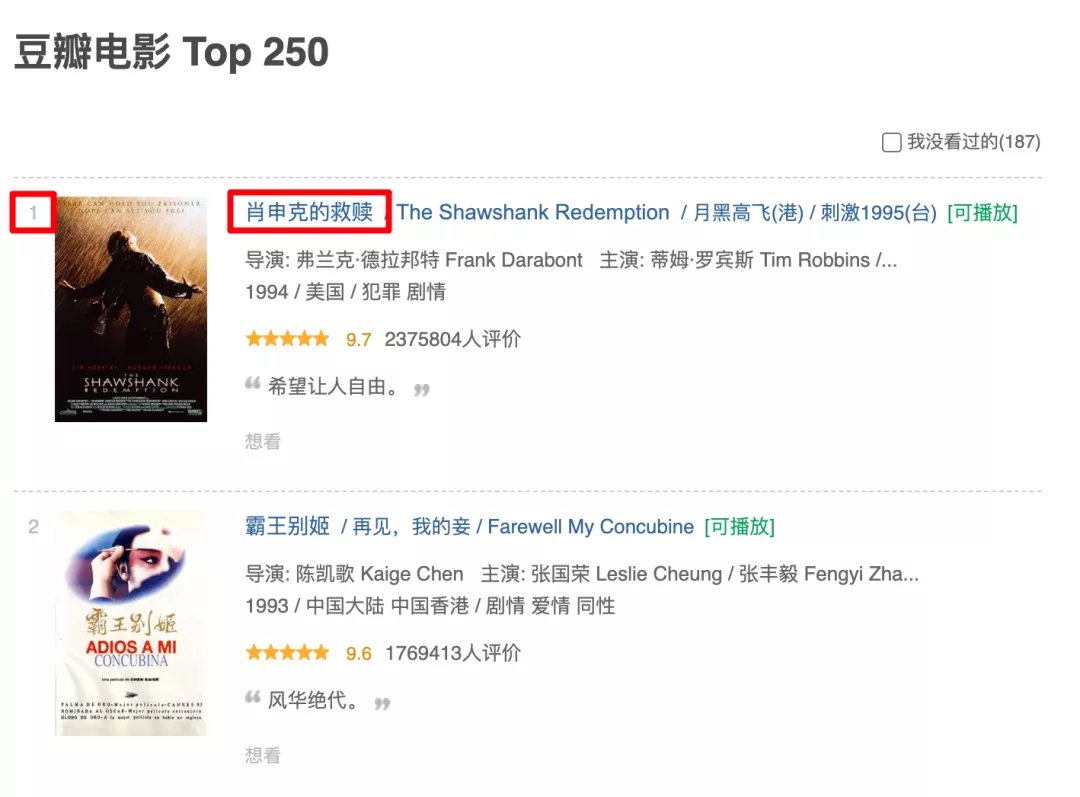
- // 第二個參數為與主goroutine 溝通的通道
- func fetch(url string, ch chan string) {
- // 省略部分代碼 ……
- rsp, _ := client.Do(req)
- // 斷開連接
- defer rsp.Body.Close()
- // 解析 HTML
- doc, _ := goquery.NewDocumentFromReader(rsp.Body)
- // 提取 HTML 中的電影排行與電影名稱
- doc.Find(".item").Each(func(_ int, s *goquery.Selection) {
- num := s.Find(".pic em").Text()
- title := s.Find(".title::first-child").Text()
- // 將電影排行與名稱寫入管道中
- ch <- fmt.Sprintf("top %s: %s\n", num, title)
- })
- }
最后,在主 goroutine 中創(chuàng)建通道,以及接收通道中的數據。
- func main() {
- ch := make(chan string)
- for i :=0; i < page; i++ {
- url := ……
- go fetch(url, ch)
- }
- for i :=0; i < total; i++ {
- top := <- ch // 接收數據
- fmt.Println(top)
- }
- }
最后的執(zhí)行結果如下:

可以看到由于是并發(fā)執(zhí)行,輸出的順序是亂序。
完整代碼
- package main
- import (
- "fmt"
- "github.com/PuerkitoBio/goquery"
- "net/http"
- "strconv"
- )
- const limit = 25
- const total = 100
- const page = total / limit
- func fetch(url string, ch chan string) {
- req, _ := http.NewRequest("GET", url, nil)
- req.Header.Add("User-Agent", "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.114 Safari/537.36")
- client := &http.Client{}
- rsp, _ := client.Do(req)
- defer rsp.Body.Close()
- doc, _ := goquery.NewDocumentFromReader(rsp.Body)
- doc.Find(".item").Each(func(_ int, s *goquery.Selection) {
- num := s.Find(".pic em").Text()
- title := s.Find("span.title::first-child").Text()
- ch <- fmt.Sprintf("top %s: %s\n", num, title)
- })
- }
- func main() {
- ch := make(chan string)
- for i :=0; i < page; i++ {
- start := i * limit
- url := "https://movie.douban.com/top250?start=" + strconv.Itoa(start)
- go fetch(url, ch)
- }
- for i :=0; i < total; i++ {
- top := <- ch
- fmt.Println(top)
- }
- }






















