













三個一組還是四個一組?從 Bytes 到 Unicode 的字節劃分方法
大家在 Python 開發過程中,經常會進行字符串encode為 Bytes型數據,或者把 Bytes 型數據 decode為字符串的操作。例如:圖片我們知道,在 Unicode 編碼中,中文占3個字節,所以一個中文字符編碼為 Bytes 型數據以后,會占用3個 Bytes 字符,例如:
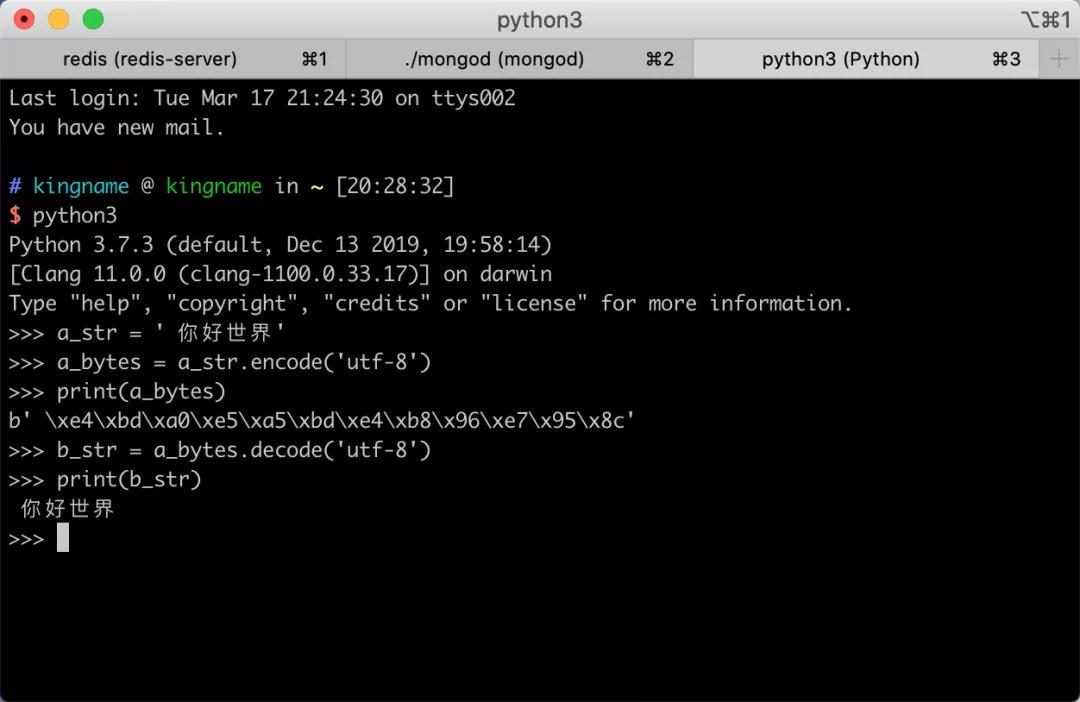
- >>> a = '青'
- >>> a.encode()
- b'\xe9\x9d\x92'
- >>> b = '青南'
- >>> b.encode()
- b'\xe9\x9d\x92\xe5\x8d\x97'
注意這里的\xe9需要作為整體來看待,表示一個16進制數。
所以,當我要把 Bytes 型數據\xe9\x9d\x92\xe5\x8d\x97 轉為字符串時,Python 會把\xe9\x9d\x92轉成青字,把\xe5\x8d\x97轉成南字,看起來,似乎是 Python 知道應該把每3個 Bytes 符號一組來進行處理。
然而,Unicode 中,emoji 表情是4個字節,例如表情符號:
??,它對應的 Bytes 型數據為:
\xf0\x9f\xa4\x94,如下圖所示:

如果我把青??南轉換為 Bytes 型數據,值為:
\xe9\x9d\x92\xf0\x9f\xa4\x94\xe5\x8d\x97,如下圖所示,一共10個 Bytes 字符:
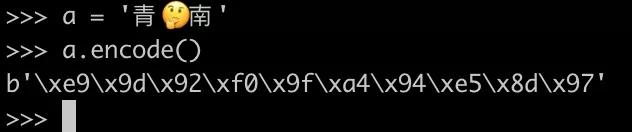
那么問題來了,當我對這個 Bytes 型數據進行 decode 會怎么樣呢?如下圖所示:

Python 可以正確地把 Bytes 數據劃分為:
- \xe9\x9d\x92 對應“青”
- \xf0\x9f\xa4\x94 對應“🤔”
- \xe5\x8d\x97 對應“南”
為什么 Python 知道要把\xf0\x9f\xa4\x94這4個符號分到一組?為什么不會像下面這樣分組?
- \xe9\x9d\x92
- \xf0\x9f\xa4
- \x94\xe5\x8d\x97
實際上,這個問題的原因,只有當我們用二進制來看的時候,才能發現端倪。 青對應的第一個 Bytes 字符\xe9,其中的e9是一個十六進制數字,把它轉成十進制是233,轉成二進制是11101001。 南對應的第一個 Bytes 字符\xe5,其中的e5是一個十六進制數字,把它轉成十進制是229,轉成二進制是11100101。 ??對應的第一個 Bytes 字符\xf0,其中的f0是一個十六進制數字,把它轉成十進制是240,轉成二進制是11110000。如果還看不出他們的差異,那我們把他們放在一起對比一下:
- 11101001
- 11100101
- 11110000
看出差異了嗎?中文漢字是三個字節,轉換為 Bytes 型數據以后,第一個字符對應的二進制數是1110開頭。emoji 是4個字節,轉換為 Bytes 型數據以后,第一個字符對應的二進制數是1111開頭。所以,當給定一個 Bytes 型數據需要給 Python 來轉換為字符串的時候,Python 是這樣判斷應該有幾個字符一組的。
- 給定 Bytes 型數據:\xe9\x9d\x92\xf0\x9f\xa4\x94\xe5\x8d\x97
- 看第一個字符對應的二進制數的高4位是1110,所以當前字符和它后面兩個字符(合計3個字符)一組,進行解析,得到青字。
- 跳過已經解析的字符,直接來到第四位\xf0,發現它對應的二進制數高4位是1111,所以這個字符和接下來3個字符(合計4個字符)一組,解析出??。
- 跳過已經解析的字符,來到第8位\xe5,對應的二進制高4位是1110,因此這個字符和接下來的兩個字符一組進行解析,得到南。
- 完成。對于數字和英文字母,在 Unicode 里面只使用一個字節來表示,他們的 Ascii 碼小于128。而多字節的 Unicode 字符,都是從129開頭,所以英文字母數字與中文混合生成的 Bytes 型數據,在解碼時也不會出現分組不明確的問題。
本文轉載自微信公眾號「未聞Code」,可以通過以下二維碼關注。轉載本文請聯系未聞Code公眾號。


















