原來這就是比 ThreadLocal 更快的玩意
本文轉(zhuǎn)載自微信公眾號(hào)「yes的練級(jí)攻略」,作者是Yes呀。轉(zhuǎn)載本文請(qǐng)聯(lián)系yes的練級(jí)攻略公眾號(hào)。
你好,我是yes。
繼上一篇之后我把 ThreadLocal 能問的,都寫了,咱們?cè)賮肀P一盤 FastThreadLocal ,這個(gè)算是 ThreadLocal 的進(jìn)階版,是 Netty 針對(duì) ThreadLocal 自己造的輪子,所以對(duì) ThreadLocal 沒有完全理解的話,建議先看上一篇文章,打個(gè)基礎(chǔ)。
那了解 FastThreadLocal 之后呢,對(duì)平日的一些優(yōu)化可能可以提供一些思路,或者面試就能裝個(gè)x。
面試官:ThreadLocal 竟然有xxx這個(gè)缺點(diǎn),那怎么優(yōu)化啊?
你就把 FastThreadLocal 的實(shí)現(xiàn) BB 一遍,這不就穩(wěn)妥了嘛!
所以,今天我們就來看看 Netty 是如何實(shí)現(xiàn) FastThreadLocal 的,話不多說,本文大綱如下:
- 數(shù)數(shù) ThreadLocal 的缺點(diǎn)。
- 應(yīng)該如何針對(duì) ThreadLocal 缺點(diǎn)改進(jìn)?
- FastThreadLocal 的原理。
- FastThreadLocal VS ThreadLocal 的實(shí)操。
這篇下來,進(jìn)階版 ThreadLocal 基本拿下,下篇我會(huì)基于這篇做一個(gè)延伸,一個(gè)比較底層的延伸,屬于絕對(duì)裝x的那種,等下看文章你就知道了,我會(huì)埋坑的,哈哈。
預(yù)告一下,這篇是個(gè)長(zhǎng)文,源碼也有點(diǎn)多,但是耐心看完肯定會(huì)有收獲的。
發(fā)車發(fā)車!
數(shù)數(shù) ThreadLocal 的缺點(diǎn)
看完上篇文章的同學(xué),應(yīng)該都很清楚了 ThreadLocal 的一個(gè)缺點(diǎn):hash 沖突用的是線性探測(cè)法,效率低。
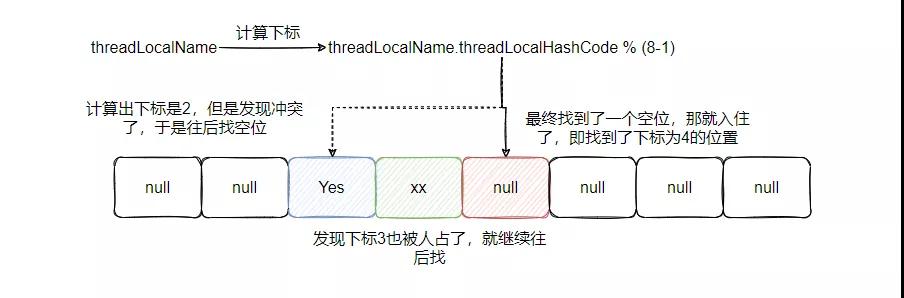
可以看到,圖上顯示的是經(jīng)過兩個(gè)遍歷找到了空位,假設(shè)沖突多了,需要遍歷的次數(shù)就多了。并且下次 get 的時(shí)候,hash 直接命中的位置發(fā)現(xiàn)不是要找的 Entry ,于是就接著遍歷向后找,所以說這個(gè)效率低。
而像 HashMap 是通過鏈表法來解決沖突,并且為了防止鏈表過長(zhǎng)遍歷的開銷變大,在一定條件之后又會(huì)轉(zhuǎn)變成紅黑樹來查找,這樣的解決方案在頻繁沖突的條件下,肯定是優(yōu)于線性探測(cè)法,所以這是一個(gè)優(yōu)化方向。
不過 FastThreadLocal 不是這樣優(yōu)化的,我們下面再說。
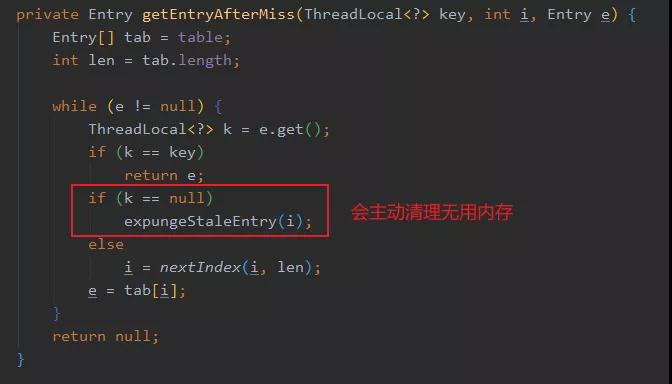
還有一個(gè)缺點(diǎn)是 ThreadLocal 使用了 WeakReference 以保證資源可以被釋放,但是這可能會(huì)產(chǎn)生一些 Etnry 的 key 為 null,即無用的 Entry 存在。
所以調(diào)用 ThreadLocal 的 get 或 set 方法時(shí),會(huì)主動(dòng)清理無用的 Entry,減輕內(nèi)存泄漏的發(fā)生。
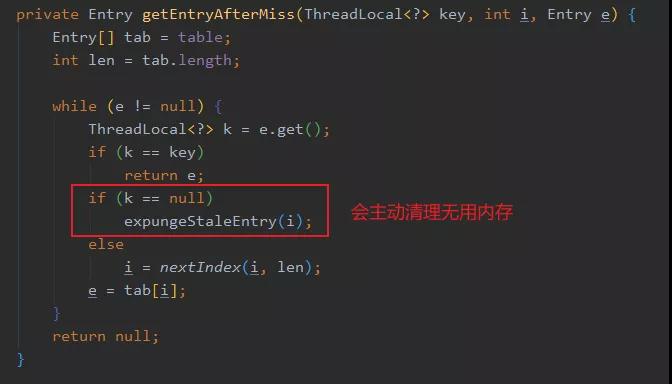
這其實(shí)等于把清理的開銷弄到了 get 和 set 上,萬一 get 的時(shí)候清理的無用 Entry 特別多,那這次 get 相對(duì)而言就比較慢了。
還有一個(gè)就是內(nèi)存泄漏的問題了,當(dāng)然這個(gè)問題只存在于用線程池使用的時(shí)候,并且上面也提到了 get 和 set 的時(shí)候也能清理一些無用的 Key,所以沒有那么的夸張,只要記得用完后調(diào)用 ThreadLocal#remove 就不會(huì)有內(nèi)存泄漏的問題了。
大致就這么幾點(diǎn)。
應(yīng)該如何針對(duì) ThreadLocal 缺點(diǎn)改進(jìn)
所以怎么改呢?
前面提到 ThreadLocal hash 沖突的線性探測(cè)法不好,還有 Entry 的弱引用可能會(huì)發(fā)生內(nèi)存泄漏,這些都和 ThreadLocalMap 有關(guān),所以需要搞個(gè)新的 map 來替換 ThreadLocalMap。
而這個(gè) ThreadLocalMap 又是 Thread 里面的一個(gè)成員變量,這么一看 Thread 也得動(dòng)一動(dòng),但是我們又無法修改 Thread 的代碼,所以配套的還得弄個(gè)新的 Thread。
所以我們不僅得弄個(gè)新的 ThreadLocal、ThreadLocalMap 還得弄個(gè)配套的 Thread 來用上新的 ThreadLocalMap 。
所以如果想改進(jìn) ThreadLocal ,就需要?jiǎng)舆@三個(gè)類。
對(duì)應(yīng)到 Netty 的實(shí)現(xiàn)就是 FastThreadLocal、InternalThreadLocalMap、FastThreadLocalThread
然后發(fā)散一下思維,既然 Hash 沖突的想線性探測(cè)效果不好,你可能比較容易想到的就是上面提到的鏈表法,然后再基于鏈表法說個(gè)改成紅黑樹,這個(gè)確實(shí)是一方面,但是可以再想想。
比如,讓 Hash 不沖突,所以設(shè)計(jì)一個(gè)不會(huì)沖突的 hash 算法?不存在的!
所以怎么樣才不會(huì)產(chǎn)生沖突呢?
各自取號(hào)入座
什么意思?就是每往 InternalThreadLocalMap 中塞入一個(gè)新的 FastThreadLocal 對(duì)象,就給這個(gè)對(duì)象發(fā)個(gè)唯一的下標(biāo),然后讓這個(gè)對(duì)象記住這個(gè)下標(biāo),到時(shí)候去 InternalThreadLocalMap 找 value 的時(shí)候,直接通過下標(biāo)去取對(duì)應(yīng)的 value 。
這樣不就不會(huì)沖突了?
這就是 FastThreadLocal 給出的方案,具體下面分析。
還有個(gè)內(nèi)存泄漏的問題,這個(gè)其實(shí)只要規(guī)范的使用即用完后 remove 就好了,其實(shí)也沒太好的解決方案,不過 FastThreadLocal 曲線救國(guó)了一下,這個(gè)也且看下面的分析!
FastThreadLocal 的原理
以下 Netty 基于 4.1 版本分析
先來看下 FastThreadLocal 的定義:
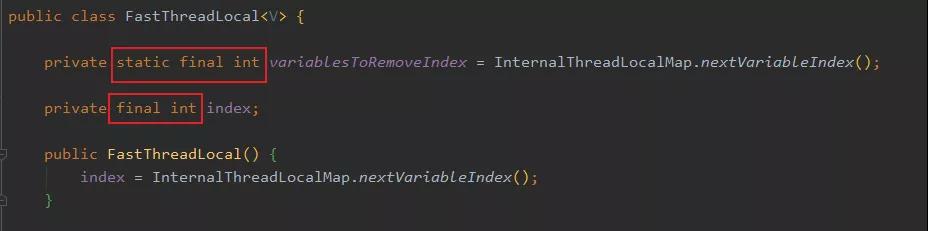
可以看到有個(gè)叫 variablesToRemoveIndex 的類成員,并且用 final 修飾的,所以等于每個(gè) FastThreadLocal 都有個(gè)共同的不可變 int 值,值為多少等下分析。
然后看到這個(gè) index 沒,在 FastThreadLocal 構(gòu)造的時(shí)候就被賦值了,且也被 final 修飾,所以也不可變,這個(gè) index 就是我上面說的給每個(gè)新 FastThreadLocal 都發(fā)個(gè)唯一的下標(biāo),這樣每個(gè) index 就都知道自己的位置了。
上面兩個(gè) index 都是通過 InternalThreadLocalMap.nextVariableIndex() 賦值的,盲猜一下,這個(gè)肯定是用原子類遞增實(shí)現(xiàn)的。
我們來看一下實(shí)現(xiàn):
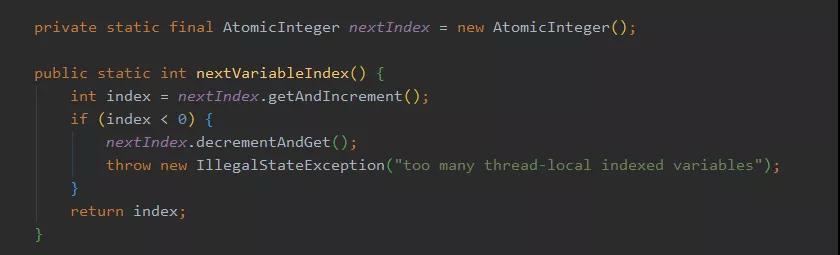
確實(shí),在 InternalThreadLocalMap 也定義了一個(gè)靜態(tài)原子類,每次調(diào)用 nextVariableIndex 就返回且遞增,沒有什么別的賦值操作,從這里也可以得知 variablesToRemoveIndex 的值為 0,因?yàn)樗鼘儆诔A抠x值,第一次調(diào)用時(shí) nextIndex 的值為 0 。
看到這,不知道大家是否已經(jīng)感覺到一絲不對(duì)勁了。好像有點(diǎn)浪費(fèi)空間的意思,我們繼續(xù)往下看。
InternalThreadLocalMap 對(duì)標(biāo)的就是之前的 ThreadLocalMap 也就是 ThreadLocal 缺點(diǎn)集中的類,需要重點(diǎn)看下。
我們?cè)賮砘仡櫼幌?ThreadLocalMap 的定義。
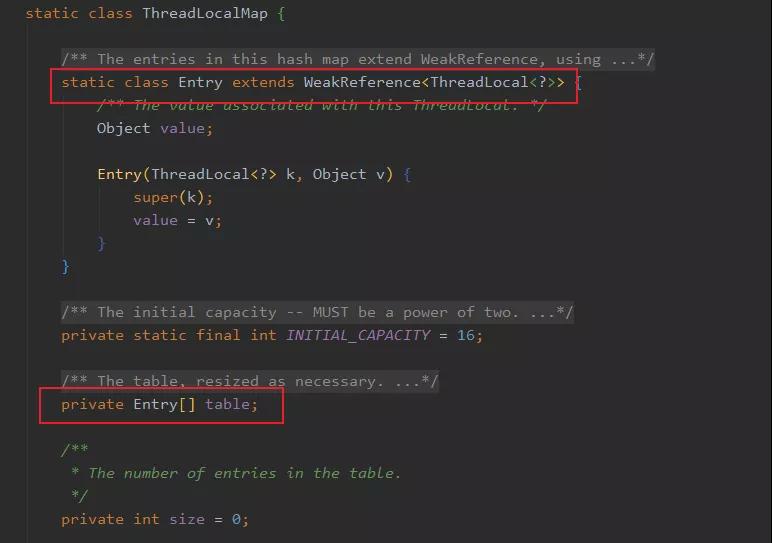
它是個(gè) Entry 數(shù)組,然后 Entry 里面弱引用了 ThreadLocal 作為 Key。
而 InternalThreadLocalMap 有點(diǎn)不太一樣:
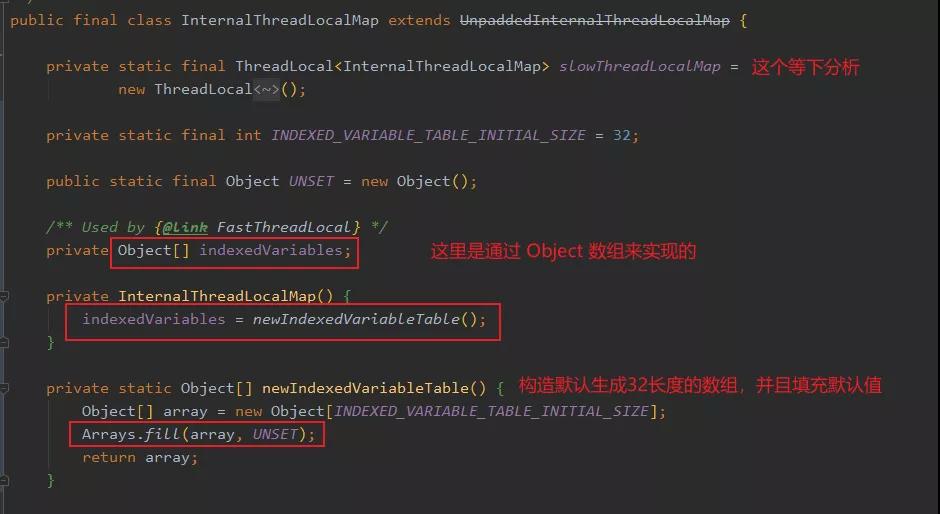
可以看到, InternalThreadLocalMap 好像放棄了 map 的形式,沒用定義 key 和 value,而是一個(gè) Object 數(shù)組?
那它是如何通過 Object 來存儲(chǔ) FastThreadLocal 和對(duì)應(yīng)的 value 的呢?我們從 FastThreadLocal#set 開始分析:
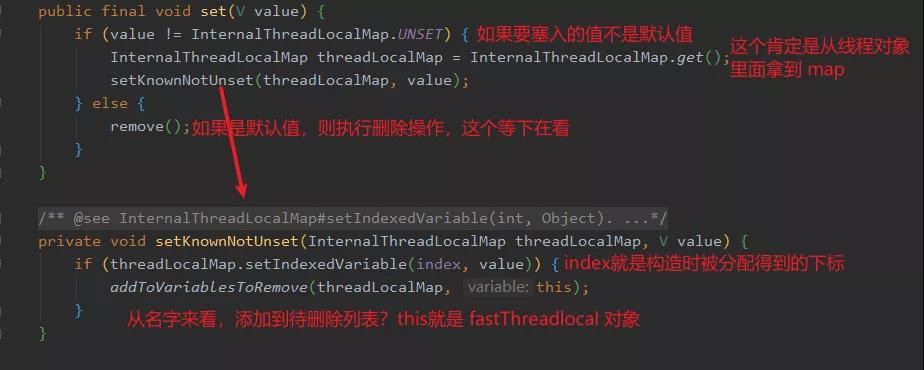
因?yàn)槲覀円呀?jīng)熟悉 ThreadLocal 的套路,所以我們知道 InternalThreadLocalMap 肯定是 FastThreadLocalThread 里面的一個(gè)變量。
然后我們從對(duì)應(yīng)的 FastThreadLocalThread 里面拿到了 map 之后,就要執(zhí)行塞入操作即 setKnownNotUnset。
我們先看一下塞入操作里面的 setIndexedVariable 方法:
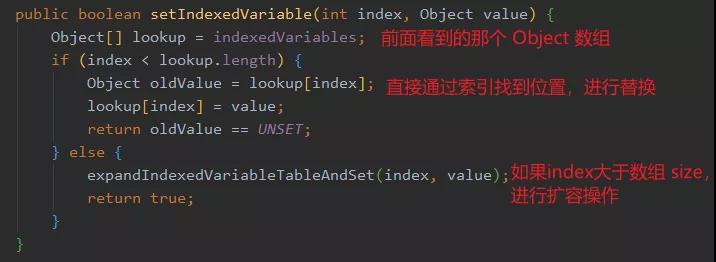
可以看到,根據(jù)傳入構(gòu)造 FastThreadLocal 生成的唯一 index 可以直接從 Object 數(shù)組里面找到下標(biāo)并且進(jìn)行替換,這樣一來壓根就不會(huì)產(chǎn)生沖突,邏輯很簡(jiǎn)單,完美。
那如果塞入的 value 不是 UNSET(默認(rèn)值),則執(zhí)行 addToVariablesToRemove 方法,這個(gè)方法又有什么用呢?

是不是看著有點(diǎn)奇怪?這是啥操作?別急,看我畫個(gè)圖來解釋解釋:
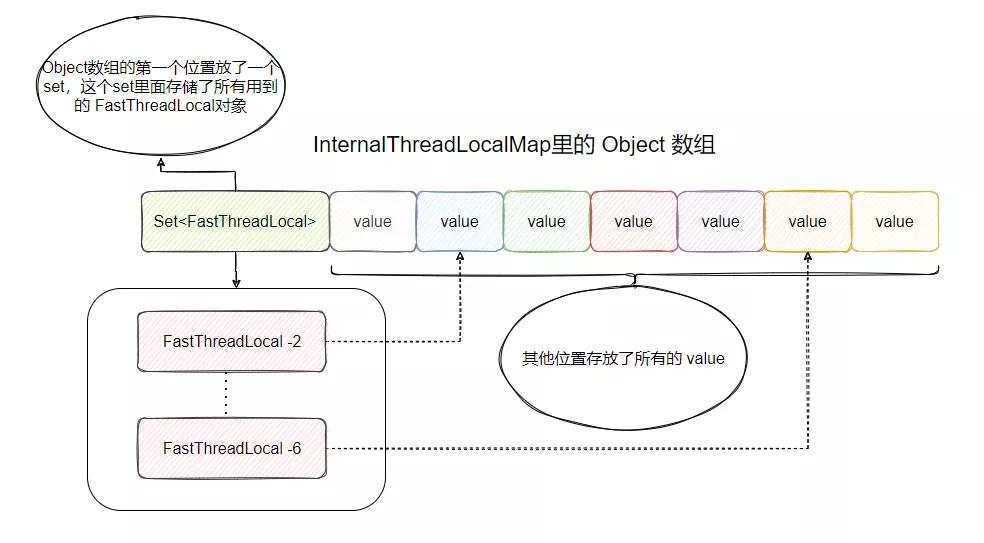
這就是 Object 數(shù)組的核心關(guān)系圖了,第一個(gè)位置放了一個(gè) set ,set 里面存儲(chǔ)了所有使用的 FastThreadLocal 對(duì)象,然后數(shù)組后面的位置都放 value。
那為什么要放一個(gè) set 保存所有使用的 FastThreadLocal 對(duì)象?
用于刪除,你想想看,假設(shè)現(xiàn)在要清空線程里面的所有 FastThreadLocal ,那必然得有一個(gè)地方來存放這些 FastThreadLocal 對(duì)象,這樣才能找到這些家伙,然后干掉。
所以剛好就把數(shù)組的第一個(gè)位置騰出來放一個(gè) set 來保存這些 FastThreadLocal 對(duì)象,如果要?jiǎng)h除全部 FastThreadLocal 對(duì)象的時(shí)候,只需要遍歷這個(gè) set ,得到 FastThreadLocal 的 index 找到數(shù)組對(duì)應(yīng)的 位置將 value 置空,然后把 FastThreadLocal 從 set 中移除即可。
剛好 FastThreadLocal 里面實(shí)現(xiàn)了這個(gè)方法,我們來看下:
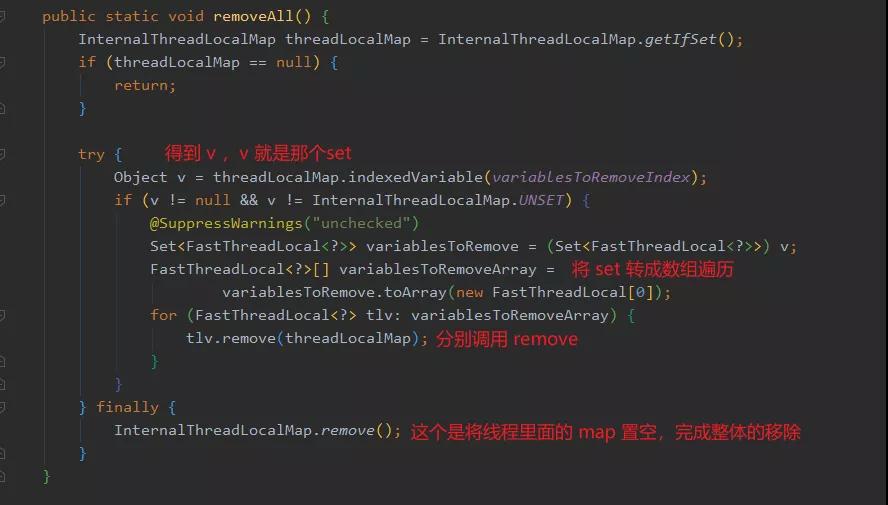
圖片內(nèi)容可能有點(diǎn)多了,我們做下小結(jié),理一理上面說的:
首先 InternalThreadLocalMap 沒有采用 ThreadLocalMap k-v形式的存儲(chǔ)方式,而是用 Object 數(shù)組來存儲(chǔ) FastThreadLocal 對(duì)象和其 value,具體是在第一個(gè)位置存放了一個(gè)包含所使用的 FastThreadLocal 對(duì)象的 set,然后后面存儲(chǔ)所有的 value。
之所以需要個(gè) set 是為了存儲(chǔ)所有使用的 FastThreadLocal 對(duì)象,這樣就能找到這些對(duì)象,便于后面的刪除工作。
之所以數(shù)組其他位置可以直接存儲(chǔ) value ,是因?yàn)槊總€(gè) FastThreadLocal 構(gòu)造的時(shí)候已經(jīng)被分配了一個(gè)唯一的下標(biāo),這個(gè)下標(biāo)對(duì)應(yīng)的就是 value 所處的下標(biāo)。
看到這里,不知道大家是否有感受到空間的浪費(fèi)?
我舉個(gè)例子。
假設(shè)系統(tǒng)里面一個(gè) new 了 100 個(gè) FastThreadLocal ,那第 100 個(gè) FastThreadLocal 的下標(biāo)就是 100 ,這個(gè)應(yīng)該沒有疑義。
從上面的 set 方法可以得知,只有調(diào)用 set 的時(shí)候,才會(huì)從當(dāng)前線程中拿出 InternalThreadLocalMap ,然后往這個(gè) map 的數(shù)組里面塞入 value,這里我們?cè)倩仡櫼幌?set 的方法。
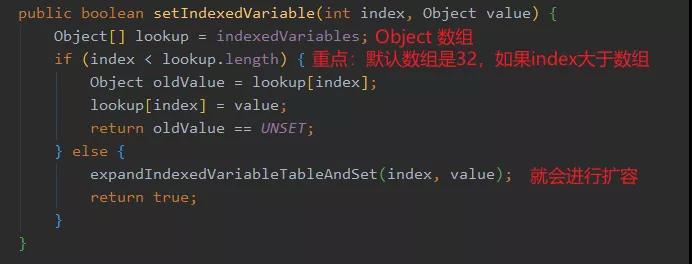
那這里是什么意思呢?
如果我這個(gè)線程之前都沒塞過 FastThreadLocal ,此時(shí)要塞入第一個(gè) FastThreadLocal ,構(gòu)造出來的數(shù)組長(zhǎng)度是32,但是這個(gè) FastThreadLocal 的下標(biāo)已經(jīng)漲到了 100 了,所以這個(gè)線程第一次塞值,也僅僅只有這么一個(gè)值,數(shù)組就需要擴(kuò)容。
看到?jīng)],這就是我所說的浪費(fèi),空間被浪費(fèi)了。
Netty 相關(guān)實(shí)現(xiàn)者知道這樣會(huì)浪費(fèi)空間,所以數(shù)組的擴(kuò)容是基于 index 而不是原先數(shù)組的大小,你看看如果是基于原先數(shù)組的擴(kuò)容,那么第一次擴(kuò)容 2 倍,32 變成 64,還是塞不下下標(biāo) 100 的數(shù)據(jù),所以還得擴(kuò)容一次,這就不美了。
所以可以看到擴(kuò)容傳進(jìn)去的參數(shù)是 index 。
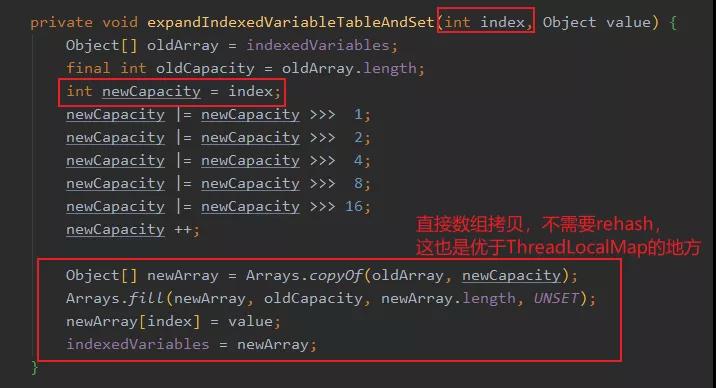
可以看到,直接基于 index 的向上 2 次冪取整。然后就是擴(kuò)容的拷貝,這里是直接進(jìn)行數(shù)組拷貝,不需要進(jìn)行 rehash,而 ThreadLocalMap 的擴(kuò)容需要進(jìn)行rehash,也就是重新基于 key 的 hash 值進(jìn)行位置的分配,所以這個(gè)也是 FastThreadLocal 優(yōu)于ThreadLocal 的一個(gè)點(diǎn)。
對(duì)了,上面那個(gè)向上 2 次冪取整的操作,不知道你們熟悉不熟悉,這個(gè)和 HashMap 的實(shí)現(xiàn)是一致的。
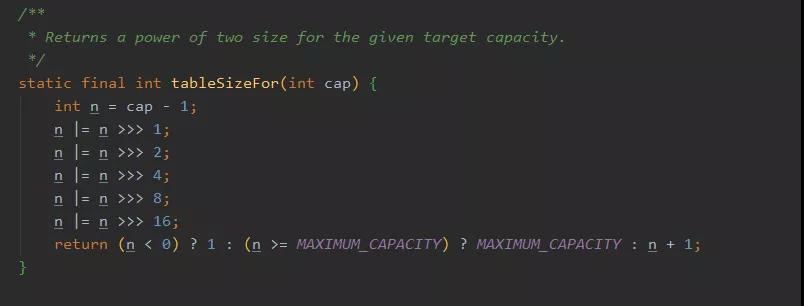
咳咳,但是我沒有證據(jù),只能說優(yōu)秀的代碼,就是源遠(yuǎn)流長(zhǎng)。
所以從上面的實(shí)現(xiàn)可以得知 Netty 就是特意這樣設(shè)計(jì)的,用多余的空間去換取不會(huì)沖突的 set 和 get ,這樣寫入和獲取的速度就更快了,這就是典型的空間換時(shí)間。
好了,想必此時(shí)你已經(jīng)弄懂了 FastThreadLocal 的核心原理了,我們?cè)賮砜纯?get 方法的實(shí)現(xiàn),我想你應(yīng)該能腦補(bǔ)這個(gè)實(shí)現(xiàn)了。
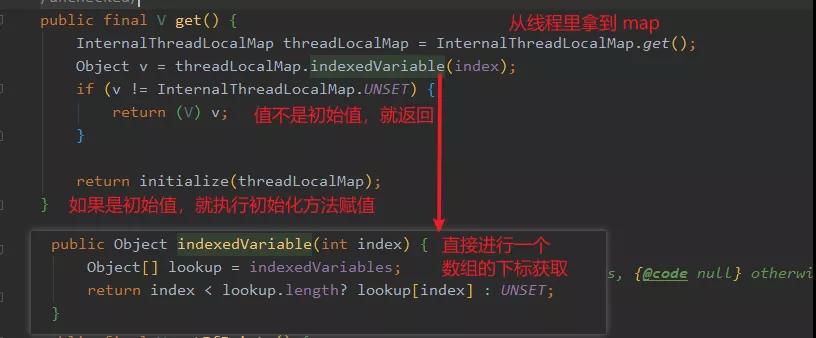
是吧,沒啥難度,index 就是 FastThreadLocal 構(gòu)造時(shí)候預(yù)先分配好的那個(gè)下標(biāo),然后直接進(jìn)行一個(gè)數(shù)組下標(biāo)查找,如果沒找到就調(diào)用 init 方法進(jìn)行初始化。
我們這里再繼續(xù)探究一下InternalThreadLocalMap.get(),這里面做了一個(gè)兼容。不過我要先介紹一下 FastThreadLocalThread ,就是這玩意替代了 Thread。
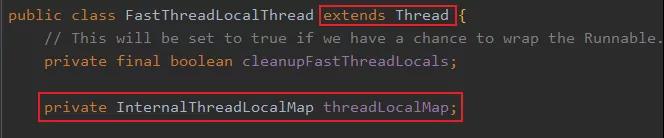
可以看到它繼承了 Thread ,并且弄了一個(gè)成員變量就是我們前面說的 InternalThreadLocalMap。
然后我們?cè)賮砜匆幌?get 方法,我截了好幾個(gè),不過邏輯很簡(jiǎn)單。
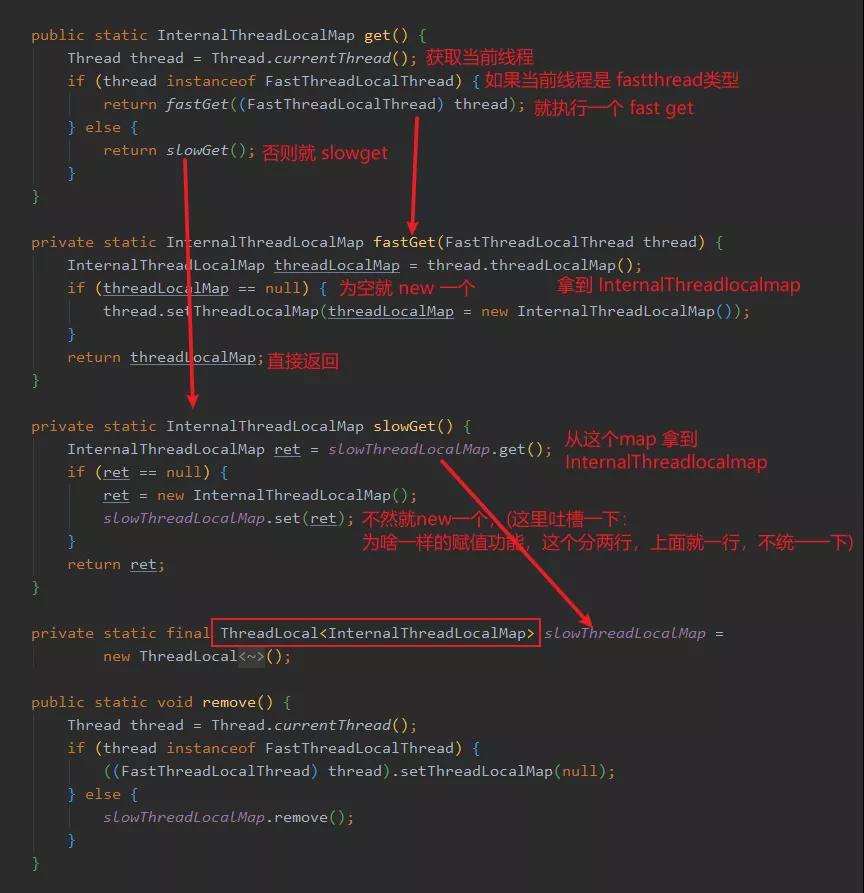
這里之所以分了 fastGet 和 slowGet 是為了做一個(gè)兼容,假設(shè)有個(gè)不熟悉的人,他用了 FastThreadLocal 但是沒有配套使用 FastThreadLocalThread ,然后調(diào)用 FastThreadLocal#get 的時(shí)候去 Thread 里面找 InternalThreadLocalMap 那不就傻了嗎,會(huì)報(bào)錯(cuò)的。
所以就再弄了個(gè) slowThreadLocalMap ,它是個(gè) ThreadLocal ,里面保存 InternalThreadLocalMap 來兼容一下這個(gè)情況。
從這里我們也能得知,F(xiàn)astThreadLocal 最好和 FastThreadLocalThread 配套使用,不然就隔了一層了。
- FastThreadLocal<String> threadLocal = new FastThreadLocal<String>();
- Thread t = new FastThreadLocalThread(new Runnable() { //記得要 new FastThreadLocalThread
- public void run() {
- threadLocal.get();
- ....
- }
- });
好了,get 和 set 這兩個(gè)核心操作都分析完了,我們最后再來看一下 remove 操作吧。
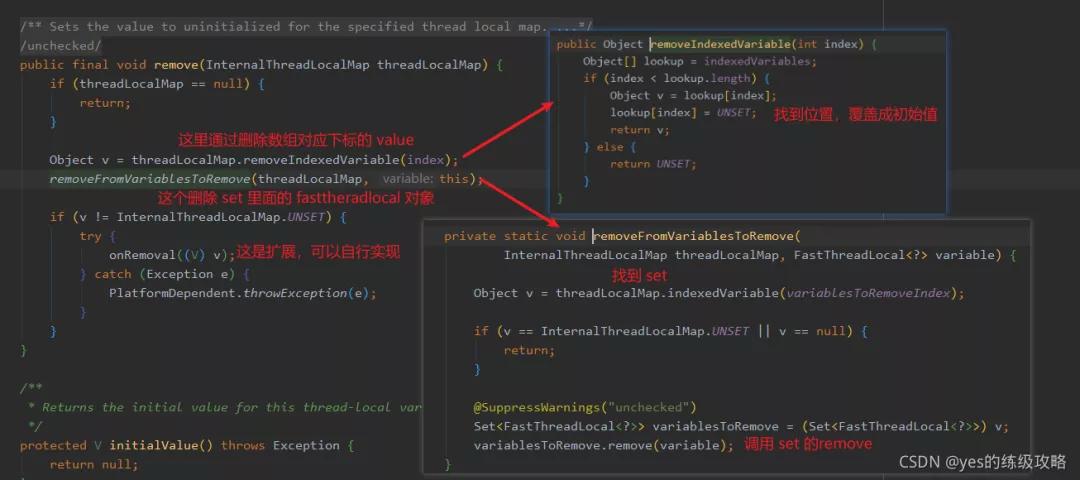
很簡(jiǎn)單對(duì)吧,把數(shù)組里的 value 給覆蓋了,然后再到 set 里把對(duì)應(yīng)的 FastThreadLocal 對(duì)象給刪了。
不過看到這里,可能有人會(huì)發(fā)出疑惑,內(nèi)存泄漏相關(guān)的點(diǎn)呢?
其實(shí)吧,可以看到 FastThreadLocal 就沒用弱引用,所以它把無用 FastThreadLocal 的清理就寄托到規(guī)范使用上,即沒用了就主動(dòng)調(diào)用 remove 方法。
但是它曲線救國(guó)了一下,我們來看一下 FastThreadLocalRunnable 這個(gè)類:
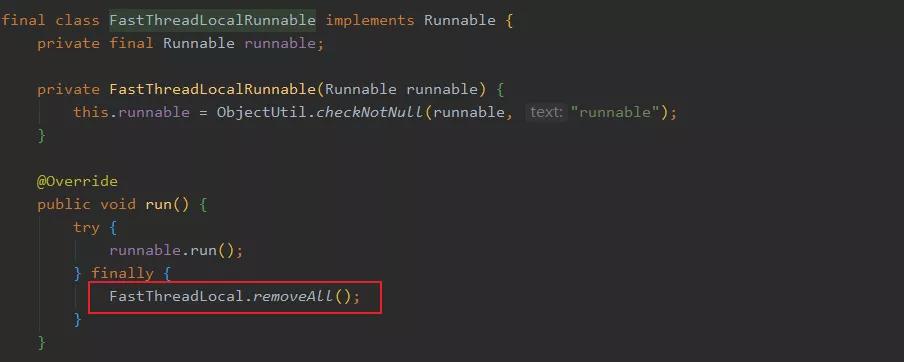
我已經(jīng)把重點(diǎn)畫出來了,可以看到這個(gè) Runnable 執(zhí)行完畢之后,會(huì)主動(dòng)調(diào)用 FastThreadLocal.removeAll() 來清理所有的 FastThreadLocal,這就是我說的曲線救國(guó),怕你完了調(diào)用 remove ,沒事我?guī)湍惴庋b一下,就是這么貼心。
當(dāng)然,這個(gè)前提是你不能用 Runnable 而是用 FastThreadLocalRunnable。不過這里 Netty 也是做了封裝的。
Netty 實(shí)現(xiàn)了一個(gè) DefaultThreadFactory 工廠類來創(chuàng)建線程。
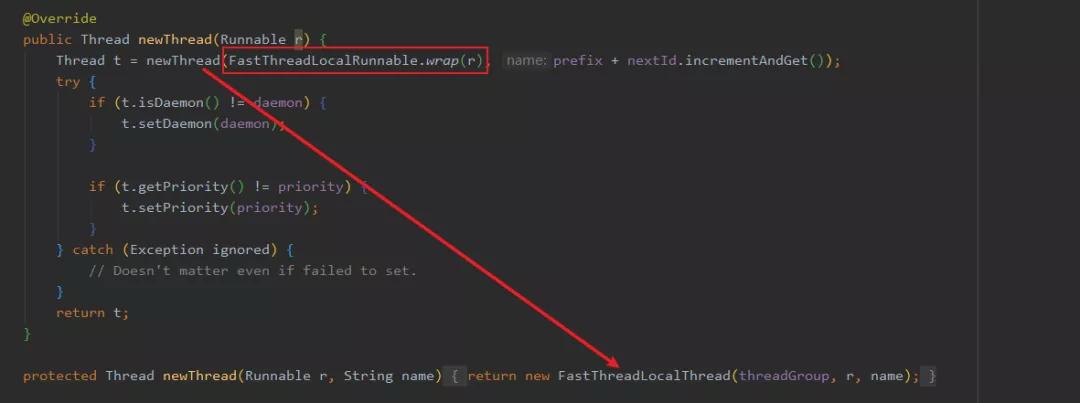
你看,你傳入 Runnable 是吧,沒事,我把它包成 FastThreadLocalRunnable,并且我 new 回去的線程是 FastThreadLocalThread 類型,這樣就能在很大程度上避免使用的錯(cuò)誤,也減少了使用的難度。
這也是工廠方法這個(gè)設(shè)計(jì)模式的好處之一啦。所以工程上如果怕對(duì)方?jīng)]用對(duì),我們就封裝了再給別人使用,這樣也屏蔽了一些細(xì)節(jié),他好你也好。
所以說多看看開源框架的源碼,有很多可以學(xué)習(xí)的地方!好了,F(xiàn)astThreadLocal 原理大致就說到這里。
FastThreadLocal VS ThreadLocal
到此,我們已經(jīng)充分了解了兩者之間的不同,但是 Fast 到底有多 Fast 呢?
我們用實(shí)驗(yàn)說話,Netty 源碼里面已經(jīng)有 benchmark 了,我們直接跑就行了
里面有兩個(gè)實(shí)驗(yàn):
FastPath 對(duì)應(yīng)的是使用 FastThreadLocalThread 線程對(duì)象。
SlowPath 對(duì)應(yīng)的是使用 Thread 線程對(duì)象。

兩個(gè)實(shí)驗(yàn)都是分別定義了 ThreadLocal 和 FastThreadLocal :
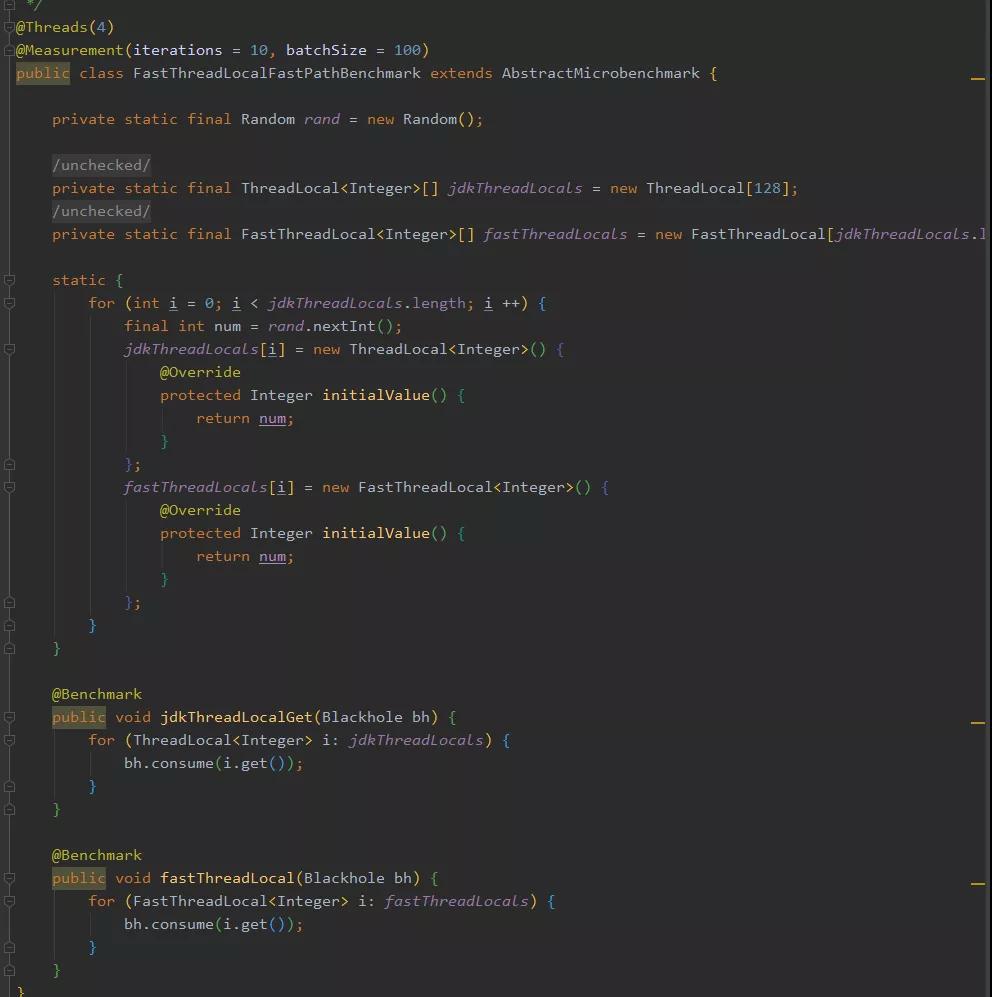
我們來看一下執(zhí)行的結(jié)果:
FastPath:

SlowPath:

可以看到搭配 FastThreadLocalThread 來使用 FastThreadLocal 吞吐確實(shí)比使用 ThreadLocal 大,但是好像也沒大太多?
不過,我在網(wǎng)上有看別比人的 benchmark 對(duì)比,同樣的代碼,他的結(jié)果是大了三倍。
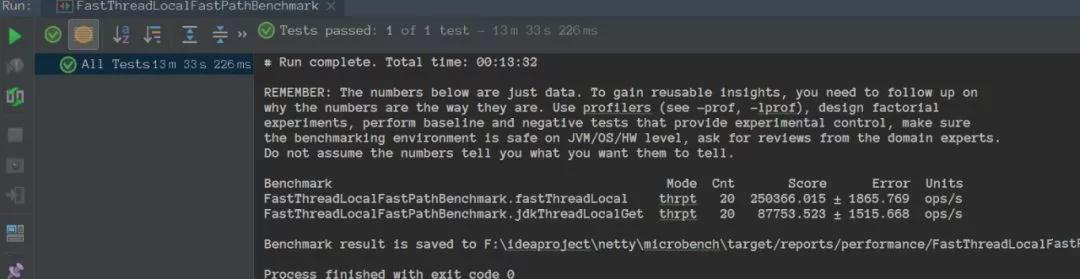
我反正又跑了幾遍,每次都比原生的 ThreadLocal 吞吐好,但是也沒好那么多...有點(diǎn)奇怪。
至于 FastThreadLocal 搭配 Thread 則吞吐比 ThreadLocal 都少,說明 FastThreadLocal 的使用必須得搭配 FastThreadLocalThread ,不然就是反向優(yōu)化了。
代碼在 netty 的 microbench 這個(gè)項(xiàng)目里,有興趣的可以自己 down 下來跑一跑看看。
最后
我們?cè)賮砜偨Y(jié)一下:
- FastThreadLocal 通過分配下標(biāo)直接定位 value ,不會(huì)有 hash 沖突,效率較高。
- FastThreadLocal 采用空間換時(shí)間的方式來提高效率。
- FastThreadLocal 需要配套 FastThreadLocalThread 使用,不然還不如原生 ThreadLocal。
- FastThreadLocal 使用最好配套 FastThreadLocalRunnable,這樣執(zhí)行完任務(wù)后會(huì)主動(dòng)調(diào)用 removeAll 來移除所有 FastThreadLocal ,防止內(nèi)存泄漏。
- FastThreadLocal 的使用也是推薦用完之后,主動(dòng)調(diào)用 remove。
這就是 Netty 實(shí)現(xiàn)的加強(qiáng)版 ThreadLocal,如果你看過 Netty 源碼,你會(huì)發(fā)現(xiàn)內(nèi)部是有挺多使用 ThreadLocal 的場(chǎng)景,所以這個(gè)優(yōu)化還是有必要的。
并且 Netty work 線程池默認(rèn)線程數(shù)是兩倍 CPU 核心數(shù),所以線程不會(huì)太多,那么空間的浪費(fèi)其實(shí)也不會(huì)很多,所以這波空間換時(shí)間影響不大。
好了,文章就到這了。挖個(gè)坑,我在 InternalThreadLocalMap 這個(gè)類里面發(fā)現(xiàn)了一些奇怪的 long 變量。

懂行的同學(xué)看著可能知道,這是為了填充 Cache Line,避免偽共享問題的產(chǎn)生。
ok ,那為什么被標(biāo)記了@deprecated?并且說將來的版本要被移除?
且聽下回分解。