













終于有人將Spark的技術框架講明白了
Spark是加州大學伯克利分校的AMP實驗室開源的類似MapReduce的通用并行計算框架,擁有MapReduce所具備的分布式計算的優點。但不同于MapReduce的是,Spark更多地采用內存計算,減少了磁盤讀寫,比MapReduce性能更高。同時,它提供了更加豐富的函數庫,能更好地適用于數據挖掘與機器學習等分析算法。
Spark在Hadoop生態圈中主要是替代MapReduce進行分布式計算,如下圖所示。同時,組件SparkSQL可以替換Hive對數據倉庫的處理,組件Spark Streaming可以替換Storm對流式計算的處理,組件Spark ML可以替換Mahout數據挖掘算法庫。
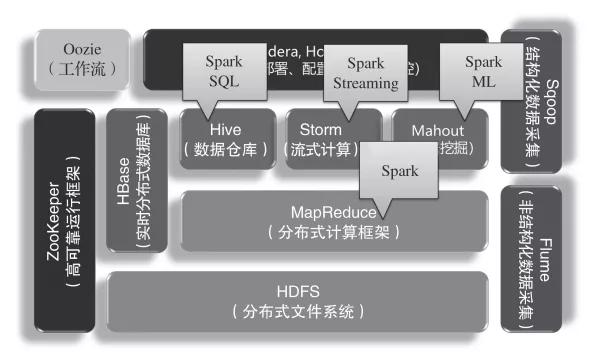
Spark在Hadoop生態圈中的位置
01Spark的運行原理
如今,我們已經不再需要去學習煩瑣的MapReduce設計開發了,而是直接上手學習Spark的開發。這一方面是因為Spark的運行效率比MapReduce高,另一方面是因為Spark有豐富的函數庫,開發效率也比MapReduce高。
首先,從運行效率來看,Spark的運行速度是Hadoop的數百倍。為什么會有如此大的差異呢?關鍵在于它們的運行原理,Hadoop總要讀取磁盤,而Spark更多地是在進行內存計算,如下圖所示。
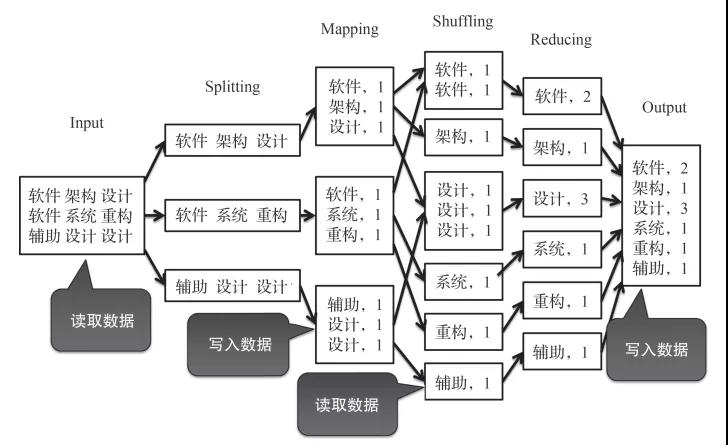
Hadoop的運行總是在讀寫磁盤
前面談到,MapReduce的主要運算過程,實際上就是循環往復地執行Map與Reduce的過程。但是,在執行每一個Map或Reduce過程時,都要先讀取磁盤中的數據,然后執行運算,最后將執行的結果數據寫入磁盤。因此,MapReduce的執行過程,實際上就是讀數據、執行Map、寫數據、再讀數據、執行Reduce、再寫數據的往復過程。這樣的設計雖然可以在海量數據中減少對內存的占用,但頻繁地讀寫磁盤將耗費大量時間,影響運行效率。
相反,Spark的執行過程只有第一次需要從磁盤中讀數據,然后就可以執行一系列操作。這一系列操作也是類似Map或Reduce的操作,然而在每次執行前都是從內存中讀取數據、執行運算、將執行的結果數據寫入內存的往復過程,直到最后一個操作執行完才寫入磁盤。這樣整個執行的過程中都是對內存的讀寫,雖然會大量占用內存資源,然而運行效率將大大提升。
Spark框架的運行原理如下圖所示,Spark在集群部署時,在NameNode節點上部署了一個Spark Driver,然后在每個DataNode節點上部署一個Executor。Spark Driver是接收并調度任務的組件,而Executor則是分布式執行數據處理的組件。同時,在每一次執行數據處理任務之前,數據文件已經通過HDFS分布式存儲在各個DataNode節點上了。因此,在每個節點上的Executor會首先通過Reader讀取本地磁盤的數據,然后執行一系列的Transformation操作。每個Transformation操作的輸入是數據集,在Spark中將其組織成彈性分布式數據集(RDD),從內存中讀取,最后的輸出也是RDD,并將其寫入內存中。這樣,整個一系列的Transformation操作都是在內存中讀寫,直到最后一個操作Action,然后通過Writer將其寫入磁盤。這就是Spark的運行原理。
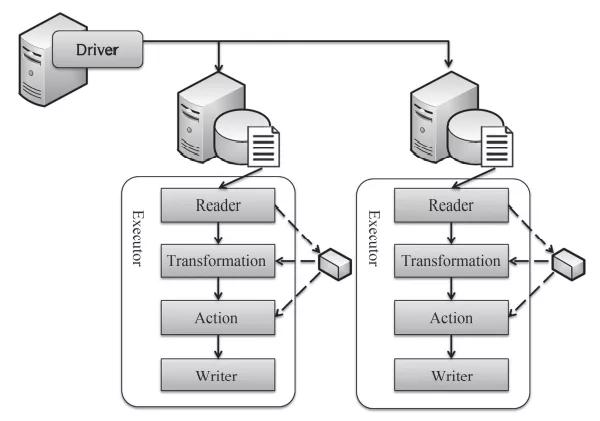
Spark框架的運行原理圖
同時,Spark擁有一個非常豐富的函數庫,許多常用的操作都不需要開發人員自己編寫,直接調用函數庫就可以了。這樣大大提高了軟件開發的效率,只用寫更少的代碼就能執行更加復雜的處理過程。在這些豐富的函數庫中,Spark將其分為兩種類型:轉換(Transfer)與動作(Action)。
Transfer的輸入是RDD,輸出也是RDD,因此它實際上是對數據進行的各種Trans-formation操作,是Spark要編寫的主要程序。同時,RDD也分為兩種類型:普通RDD與名-值對RDD。
普通RDD,就是由一條一條的記錄組成的數據集,從原始文件中讀取出來的數據通常都是這種形式,操作普通RDD最主要的函數包括map、flatMap、filter、distinct、union、intersection、subtract、cartesian等。
名-值對RDD,就是k-v存儲的數據集,map操作就是將普通RDD的數據轉換為名-值對RDD。有了名-值對RDD,才能對其進行各種reduceByKey、joinByKey等復雜的操作。操作名-值對RDD最主要的函數包括reduceByKey、groupByKey、combineByKey、mapValues、flatMapValues、keys、values、sortByKey、subtractByKey、join、leftOuterJoin、rightOuterJoin、cogroup等。
所有Transfer函數的另外一個重要特征就是,它們在處理RDD數據時都不會立即執行,而是延遲到下一個Action再執行。這樣的執行效果就是,當所有一系列操作都定義好以后,一次性執行完成,然后立即寫磁盤。這樣在執行過程中就減少了等待時間,進而減少了對內存的占用時間。
Spark的另外一種類型的函數就是Action,它們輸入的是RDD,輸出的是一個數據結果,通常拿到這個數據結果就要寫磁盤了。根據RDD的不同,Action也分為兩種:針對普通RDD的操作,包括collect、count、countByValue、take、top、reduce、fold、aggregate、foreach等;針對名-值對RDD的操作,包括countByKey、collectAsMap、lookup等。
02Spark的設計開發
Spark的設計開發支持3種語言,Scala、Python與Java,其中Scala是它的原生語言。Spark是在Scala語言中實現的,它將Scala作為其應用程序框架,能夠與Scala緊密集成。Scala語言是一種類似Java的函數式編程語言,它在運行時也使用Java虛擬機,可以與Java語言無縫結合、相互調用。同時,由于Scala語言采用了當前比較流行的函數式編程風格,所以代碼更加精簡,編程效率更高。
前面講解的那段計算詞頻的代碼如下:
- 1val textFile = sc.textFile("hdfs://...")
- 2val counts = textFile.flatMap(line => line.split(""))
- 3 .map(word => (word, 1))
- 4 .reduceByKey(_ + _)
- 5counts.saveAsTextFile("hdfs://...")
為了實現這個功能,前面講解的MapReduce框架需要編寫一個Mapper類和一個Reducer類,還要通過一個驅動程序把它們串聯起來才能夠執行。然而,在Spark程序中通過Scala語言編寫,只需要這么5行代碼就可以實現,編程效率大大提升。這段代碼如果使用Java語言編寫,那么需要編寫成這樣:
- 1JavaRDD<String> textFile = sc.textFile("hdfs://...");
- 2JavaRDD<String> words = textFile.flatMap(
- 3 new FlatMapFunction<String, String>() {
- 4 public Iterable<String> call(String s) {
- 5 return Arrays.asList(s.split(" ")); }
- 6});
- 7JavaPairRDD<String, Integer> pairs = words.mapToPair(
- 8 new PairFunction<String, String, Integer>() {
- 9 public Tuple2<String, Integer> call(String s) {
- 10 return new Tuple2<String, Integer>(s, 1); }
- 11});
- 12JavaPairRDD<String, Integer> counts= pairs.reduceByKey(
- 13 new Function2<Integer, Integer, Integer>() {
- 14 public Integer call(Integer a, Integer b) { return a + b; }
- 15});
- 16counts.saveAsTextFile("hdfs://...");
很顯然,采用Scala語言編寫的Spark程序比Java語言的更精簡,因而更易于維護與變更。所以,Scala語言將會成為更多大數據開發團隊的選擇。
下圖是一段完整的Spark程序,它包括初始化操作,如SparkContext的初始化、對命令參數args的讀取等。接著,從磁盤載入數據,通過Spark函數處理數據,最后將結果數據存入磁盤。

完整的Spark程序
03Spark SQL設計開發
在未來的三五年時間里,整個IT產業的技術架構將會發生翻天覆地的變化。數據量瘋漲,原有的數據庫架構下的存儲成本將越來越高,查詢速度越來越慢,數據擴展越來越困難,因此需要向著大數據技術轉型。
大數據轉型要求開發人員熟悉Spark/Scala的編程模式、分布式計算的設計原理、大量業務數據的分析與處理,還要求開發人員熟悉SQL語句。
因此,迫切需要一個技術框架,能夠支持開發人員用SQL語句進行編程,然后將SQL語言轉化為Spark程序進行運算。這樣的話,大數據開發的技術門檻會大大降低,更多普通的Java開發人員也能夠參與大數據開發。這樣的框架就是Spark SQL+Hive。
Spark SQL+Hive的設計思路就是,將通過各種渠道采集的數據存儲于Hadoop大數據平臺的Hive數據庫中。Hive數據庫中的數據實際上存儲在分布式文件系統HDFS中,并將這些數據文件映射成一個個的表,通過SQL語句對數據進行操作。在對Hive數據庫的數據進行操作時,通過Spark SQL將數據讀取出來,然后通過SQL語句進行處理,最后將結果數據又存儲到Hive數據庫中。
- 1CREATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name
- 2 [(col_name data_type [COMMENT col_comment], ...)]
- 3 [COMMENT table_comment]
- 4 [PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)]
- 5 [CLUSTERED BY (col_name, col_name, ...)
- 6 [SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS]
- 7 [ROW FORMAT row_format]
- 8 [STORED AS file_format]
- 9 [LOCATION hdfs_path]
首先,通過以上語句在Hive數據庫中建表,每個表都會在HDFS上映射成一個數據庫文件,并通過HDFS進行分布式存儲。完成建表以后,Hive數據庫的表不支持一條一條數據的插入,也不支持對數據的更新與刪除操作。數據是通過一個數據文件一次性載入的,或者通過類似insert into T1 select * from T2的語句將查詢結果載入表中。
- 1# 從NameNode節點中加載數據文件
- 2LOAD DATA LOCAL INPATH './examples/files/kv1.txt' OVERWRITE INTO TABLE pokes;
- 3# 從NameNode節點中加載數據文件到分區表
- 4LOAD DATA LOCAL INPATH './examples/files/kv2.txt'
- 5OVERWRITE INTO TABLE invites PARTITION (ds='2008-08-15');
- 6# 從HDFS中加載數據文件到分區表
- 7LOAD DATA INPATH '/user/myname/kv2.txt' OVERWRITE
- 8INTO TABLE invites PARTITION (ds='2008-08-15');
加載數據以后,就可以通過SQL語句查詢和分析數據了:
- 1SELECT a1, a2, a3 FROM a_table
- 2LEFT JOIN | RIGHT JOIN | INNER JOIN | SEMI JOIN b_table
- 3ON a_table.b = b_table.b
- 4WHERE a_table.a4 = "xxx"
注意,這里的join操作除了有左連接、右連接、內連接以外,還有半連接(SEMI JOIN),它的執行效果類似于in語句或exists語句。
有了Hive數據庫,就可以通過Spark SQL去讀取數據,然后用SQL語句對數據進行分析了:
- 1import org.apache.spark.sql.{SparkSession, SaveMode}
- 2import java.text.SimpleDateFormat
- 3object UDFDemo {
- 4 def main(args: Array[String]): Unit = {
- 5 val spark = SparkSession
- 6 .builder()
- 7 .config("spark.sql.warehouse.dir","")
- 8 .enableHiveSupport()
- 9 .appName("UDF Demo")
- 10 .master("local")
- 11 .getOrCreate()
- 12
- 13 val dateFormat = new SimpleDateFormat("yyyy")
- 14 spark.udf.register("getYear", (date:Long) => dateFormat.format(date).toInt)
- 15 val df = spark.sql("select getYear(date_key) year, * from etl_fxdj")
- 16 df.write.mode(SaveMode.Overwrite).saveAsTable("dw_dm_fx_fxdj")
- 17 }
- 18}
在這段代碼中,首先進行了Spark的初始化,然后定義了一個名為getYear的函數,接著通過spark.sql()對Hive表中的數據進行查詢與處理。最后,通過df.write.mode().saveAsTable()將結果數據寫入另一張Hive表中。其中,在執行SQL語句時,可以將getYear()作為函數在SQL語句中調用。
有了Spark SQL+Hive的方案,在大數據轉型的時候,實際上就是將過去存儲在數據庫中的表變為Hive數據庫的表,將過去的存儲過程變為Spark SQL程序,將過去存儲過程中的函數變為Spark自定義函數。這樣就可以幫助企業更加輕松地由傳統數據庫架構轉型為大數據架構。
本書摘編自《架構真意:企業級應用架構設計方法論與實踐》,經出版方授權發布。
















