阿里云二面:Zookeeper一致性算法
上次跟學弟學妹們聊完了Spring相關的一些知識點,學弟學妹們還是挺開心的,但是上次有學弟在跟我留言,在出去面試的時候被面試官問了個一臉蒙逼急的問題:
zookeeper你用過嗎?作為注冊中心它是怎么如何保證CP的呢?
為了對的起學弟學妹們的信賴這次跟大家具體聊聊zookeeper中的一致性選舉算法Paxos算法
什么是CAP?
CAP理論指的是在一個分布式系統中,不可能同時滿足Consistency(一致性)、Availablity(可用性)、Partition tolerance(分區容錯性)這三個基本需求,最多只能滿足其中的兩項。
- 一致性(Consistency):數據在不同的副本之間數據是保持一致的,并且當執行數據更新之后,各個副本之間能然是處于一致的狀態。
- 可用性(Availablity):系統提供的服務必須是處于一直可用的狀態,針對每一次對系統的請求操作在設定的時間內,都能得到正常的result返回。
- 分區容錯性(Partition tolerance):分布式系統在遇到任何網絡分區故障的時候,仍然需要能夠保證對外提供滿足一致性和可用性的服務,除非整個網絡環境全部癱瘓了。
什么是三二原則?
- 對于分布式系統,在CAP原則中,P是一定要保證的,如果沒有分區容錯性那這個系統就太脆落了,但是并不能同時保證一致性或者可用性,在現在我們的分布式系統中,滿足一致性,則必然會失去可用性,滿足可用性,則必然失去一執性。所以CAP原則對一個分布式系統來說要么滿足AP,要么滿足CP,這就是三二原則。
Zookeeper與Eureka的區別?
- Zookeeper遵循是的CP原則,即保證了一致性,失去了可用性,體現在當Leader宕機后,zk 集群會馬上進行新的 Leader 的選舉,但是選舉的這個過程是處于癱瘓狀態的。所以其不滿足可用性。
- Eureka遵循的是AP原則,即保證了高可用,失去了一執行。每臺服務器之間都有心跳檢測機制,而且每臺服務器都能進行讀寫,通過心跳機制完成數據共享同步,所以當一臺機器宕機之后,其他的機器可以正常工作,但是可能此時宕機的機器還沒有進行數據共享同步,所以其不滿足一致性。
言歸正轉,基礎就跟大家聊到這里了,開始直接開始正文吧!!!
Paxos算法
- Paxos 算法是萊斯利·蘭伯特(Leslie Lamport)1990 年提出的一種基于消息傳遞的、具有高容錯性的一致性算法。Google Chubby 的作者 Mike Burrows 說過,世上只有一種一致性算法, 那就是 Paxos,所有其他一致性算法都是 Paxos 算法的不完整版。
- Paxos 算法是一種公認的晦澀難懂的算法,并且工程實現上也具有很大難度。
- 所以 Paxos算法主要用來解決我們的分布式系統中如何根據表決達成一致。
算法前置理解
首先需要理解的是算法中的三種角色
- Proposer(提議者)
- Acceptor(決策者)
- Learners(群眾)
一個提案的決策者(Acceptor)會存在多個,但在一個集群中提議者(Proposer)也是可能存在多個的,不同的提議者(Proposer)會提出不同的提案。
paxos算法特點:
- 沒有提案被提出則不會有提案被選定。
- 每個提議者在提出提案時都會首先獲取到一個具有全局唯一性的、遞增的提案編號 N, 即在整個集群中是唯一的編號N,然后將該編號賦予其要提出的提案。(在zookeeper中就是zxid,由epoch 和xid組成)
- 每個表決者在 accept 某提案后,會將該提案的編號N 記錄在本地,這樣每個表決者中保存的已經被 accept 的提案中會存在一個編號最大的提案,其編號假設為 maxN。每個表決者僅會 accept 編號大于自己本地maxN 的提案。
- 在眾多提案中最終只能有一個提案被選定。
- 一旦一個提案被選定,則其它服務器會主動同步(Learn)該提案到本地。
Paxos算法整個選舉的過程可以分為兩個階段來理解。
階段一
這個階段主要是準備階段發送提議
- 提議者(Proposer)準備提交一個編號為 N 的提議,于是其首先向所有表決者(Acceptor)發送 prepare(N)請求,用于試探集群是否支持該編號的提議。
- 每個決策者(Acceptor)中都保存著自己曾經 accept 過的提議中的最大編號 maxN。當一個表決者接收到其它主機發送來的 prepare(N)請求時,其會比較 N 與 maxN 的值。
- 若 N 小于 maxN,則說明該提議已過時,當前表決者采取不回應來拒絕該 prepare 請求
- 若N 大于maxN,則說明該提議是可以接受的,當前表決者會首先將該 N 記錄下來, 并將其曾經已經 accept 的編號最大的提案 Proposal(myid,maxN,value)反饋給提議者, 以向提議者展示自己支持的提案意愿。其中第一個參數 myid 表示表決者 Acceptor 的標識 id,第二個參數表示其曾接受的提案的最大編號 maxN,第三個參數表示該提案的真正內容 value。
- 若當前表決者還未曾 accept 過任何提議(第一次初始化的時候),則會將Proposal(myid,null,null)反饋給提議者。
- 在當前階段 N 不可能等于maxN。這是由 N 的生成機制決定的。要獲得 N 的值, 其必定會在原來數值的基礎上采用同步鎖方式增一
階段二
當前階段要是真正的發送接收階段又被稱為Accept階段
- 當提議者(Proposer)發出 prepare(N)后,若收到了超過半數的決策者(Accepter)的反饋, 那么該提議者就會將其真正的提案 Proposal(N,value)發送給所有的表決者。
- 當決策者(Acceptor)接收到提議者發送的 Proposal(N,value)提案后,會再次拿出自己曾經accept 過的提議中的最大編號 maxN,及曾經記錄下的 prepare 的最大編號,讓 N 與它們進行比較,若N 大等于于這兩個編號,則當前表決者 accept 該提案,并反饋給提議者。若 N 小于這兩個編號,則決策者采取不回應來拒絕該提議。
- 若提議者沒有接收到超過半數的表決者的 accept 反饋,則重新進入 prepare 階段,遞增提案號,重新提出 prepare 請求。若提議者接收到的反饋數量超過了半數,則其會向外廣播兩類信息:
- 向曾 accept 其提案的表決者發送“可執行數據同步信號”,即讓它們執行其曾接收到的提案
向未曾向其發送 accept 反饋的表決者發送“提案 + 可執行數據同步信號”,即讓它們接受到該提案后馬上執行。
看到這里可能很多學弟都是一臉懵逼,什么鬼?為了加深理解,讓整個過程更加的透明,還是舉例說明一下吧!!!
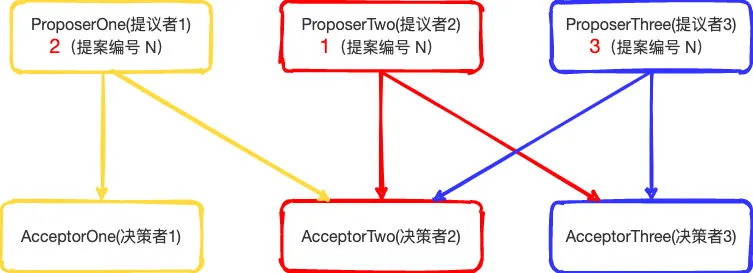
假設現在我們有三臺主機服務器從中選取leader(也可以選擇其他的更多的服務器,為了比較方便容易理解這里選少一點)。所以這三臺主機它們就分別充當著提議者(Proposer)、決策者(Acceptor)、Learners(群眾)三種角色。
所以假設現在開始模擬選舉,三臺服務分別開始獲取N(具有全局唯一性的、遞增的提案編號 N)的值,此時 serverOne(主機1) 就對應這個 ProposerOne(提議者1)、serverTwo(主機2)對應ProposerTwo(提議者2)、serverThree(主機3)對應ProposerThree(提議者3)。
為了整個流程比較簡單清晰,過程中更好理解。他們的初始N值就特定的設置為 ServerOne(2)、ServerTwo(1)、ServerThree(3),所以他們都要發送給提議(Proposal)給決策者(Acceptor),讓它們進行表決確定
- 名詞解析
- 提議(Proposal):提議者向決策者發送的中間數據的包裝簡稱提議。
同時每個 提議者(Proposer)向其中的兩個決策者(Acceptor)發送提案消息。所以假設:
ProposerOne(提議者1)向 AcceptorOne(決策者1)和AcceptorTwo(決策者2)、
ProposerTwo(提議者2)向AcceptorTwo(決策者2)和AcceptorThree(決策者3)、
ProposerThree(提議者3)向AcceptorTwo(決策者2)和AcceptorThree(決策者3)、
發送提案消息。為了流程結構簡單就向其中的2臺發送提案,但是也是已經超過半票了,當然也可以多選幾個主機,多發送提案,只是流程就復雜了一點不好理解了。注意點就是一定要超過半票。
那么整個圖可以如下所示:
所以根據上面的圖開始走第一階段
按照上面我們假設的流程開始執行流程
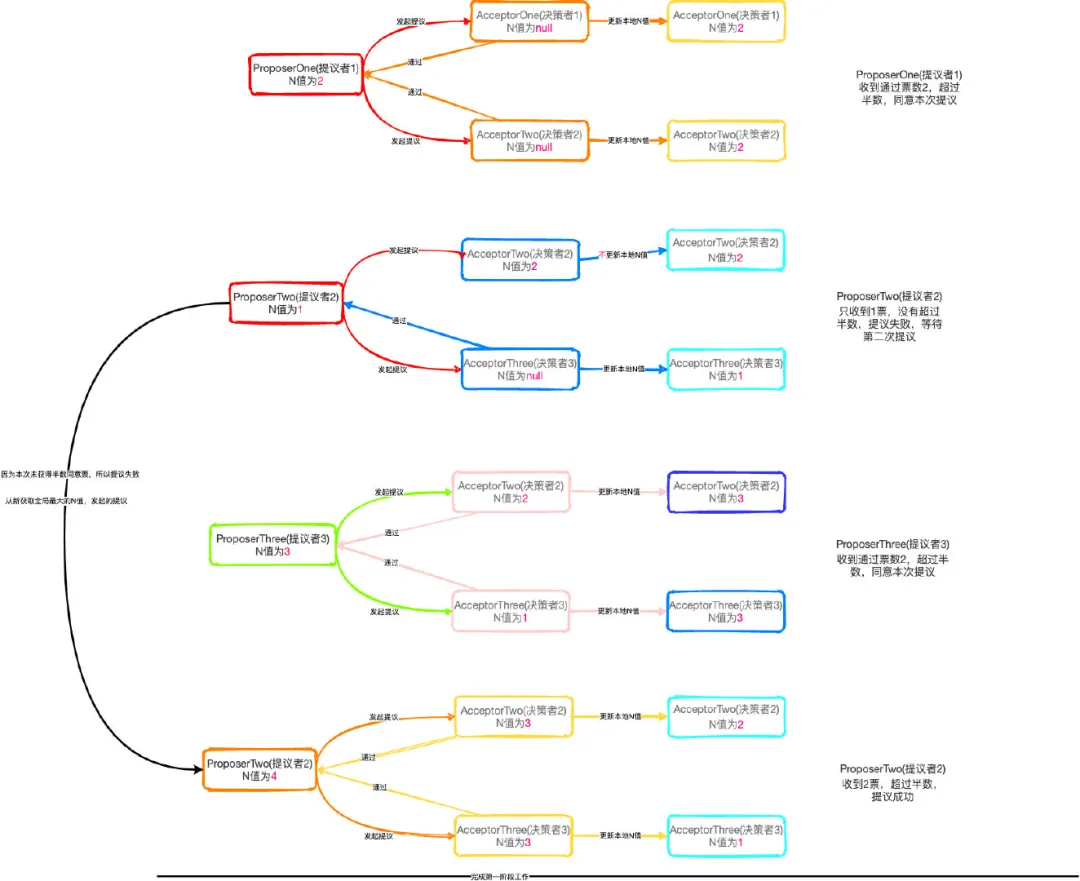
ProposerOne(提議者1)向 AcceptorOne(決策者1)和AcceptorTwo(決策者2)
- AcceptorOne(決策者1)和AcceptorTwo(決策者2)第一次收到ProposerOne(提議者1)的提議(Proposal),由于是第一次收到提議(Proposal),本地沒有存儲最大的N值,所以都會接受ProposerOne(提議者1)的提議。
- 所以AcceptorOne(決策者1)和AcceptorTwo(決策者2)都會提議返回給ProposerOne(提議者1)告知我贊同你的提議。
- 同時AcceptorOne(決策者1)和AcceptorTwo(決策者2)因為收到的當前的最大提議編號N為2,并且保存在本地,所以想接受到其他的N值小于2時則不會回復提議。
- 而ProposerOne(提議者1)已經收到超過半數返回,所以提議通過
- 此時 :
- AcceptorOne(決策者1)本地 N值為2
- AcceptorTwo(決策者2) 本地 N值為2
- AcceptorThree(決策者3)本地 N值為null
ProposerTwo(提議者2)向AcceptorTwo(決策者2)和AcceptorThree(決策者3)
- AcceptorTwo(決策者2)和AcceptorThree(決策者3)收到ProposerTwo(提議者2)的提議(Proposal)時。因為AcceptorTwo(決策者2)之前已經接受過ProposerOne(提議者1)的提議,所以本地的N值已經存儲了2
- 當ProposerTwo(提議者2)的N值為1的時候,小于本地存的最大N值,所以不給予通過,也就不回復ProposerTwo(提議者2)
- 而AcceptorThree(決策者3)因為這是第一次收到提議,沒有最大N值,所以同意提議(Proposal),返回當前提,更新本地N值。
- 最后ProposerTwo(提議者2)只收到AcceptorThree(決策者3)的同意反饋,沒有超過半數選擇,所以不給通過。
- 此時 :
- AcceptorOne(決策者1)本地 N值為2
- AcceptorTwo(決策者2) 本地 N值為2
- AcceptorThree(決策者3)本地 N值為1
ProposerThree(提議者3)向AcceptorTwo(決策者2)和AcceptorThree(決策者3)
- AcceptorTwo(決策者2)和AcceptorThree(決策者3)收到ProposerThree(提議者3)的提議(Proposal)時。因為
- AcceptorTwo(決策者2)和AcceptorThree(決策者3)都已經都到過提議(Proposal),所以AcceptorTwo(決策者2)收到ProposerThree(提議者3)的提議時,本地N值2小于ProposerThree(提議者3)的N值3,所以通過提議
- AcceptorThree(決策者3)因為本地之前收到最大的值為1,所以本次通過也通過提議,更新本次的N值為3
- 最后ProposerThree(提議者3)收到超過半數的同意反饋,所以通過。
- 此時 :
- AcceptorOne(決策者1)本地 N值為2
- AcceptorTwo(決策者2) 本地 N值為3
- AcceptorThree(決策者3)本地 N值為3
由于之前ProposerTwo(提議者2)向AcceptorTwo(決策者2)和AcceptorThree(決策者3)發出提議時,沒有超過半數投票。所以會從新獲取最大N值(具有全局唯一性的、遞增的提案編號 N),這個時候ProposerTwo(提議者2)本地獲取的N值為4所以會再次發起一輪投票
- AcceptorTwo(決策者2)和AcceptorThree(決策者3)再次收到ProposerTwo(提議者2)的提議(Proposal)時。AcceptorTwo(決策者2)和AcceptorThree(決策者3)本地存儲的最大N值都小于現在最新的ProposerTwo(提議者2)的N值4,所以全部通過返回提議,更新本地N值
- 當ProposerTwo(提議者2)的N值為1的時候,小于本地存的最大N值,所以不給予通過,也就不回復ProposerTwo(提議者2)
- 最后ProposerTwo(提議者2)收到超過半數的同意反饋,所以通過。
- 此時 :
- AcceptorOne(決策者1)本地 N值為2
- AcceptorTwo(決策者2) 本地 N值為4
- AcceptorThree(決策者3)本地 N值為4
到此第一階段的工作就已經完成了,整個流程都是文字較多,看起需要多看幾遍。同時我也給大家畫了一個流程圖如下:
由于上面已經走完第一階段,那么接下來肯定就是第二階段的流程了
同時整體第二階段可以分為兩塊來理解,第一塊是正式提交提議,第二塊是表決確定階段
第一階段執行完得到的結果:
Proposer
- ProposerOne(提議者1) 本地N值為2
- ProposerTwo(提議者2) 本地N值為4
- ProposerThree(提議者3) 本地N值為3
Acceptor
- AcceptorOne(決策者1) 本地N值為2
- AcceptorTwo(決策者2) 本地N值為4
- AcceptorThree(決策者3) 本地N值為4
第一塊:
- ProposerOne(提議者1)正式發出提議到AcceptorOne(決策者1)和AcceptorTwo(決策者2),通過第一階段的結果可以知道只有AcceptorOne(決策者1)表決通過,AcceptorTwo(決策者2)不通過因為小于本地N值
- ProposerTwo(提議者2)正式發出提議到AcceptorTwo(決策者2)和AcceptorThree(決策者3),同樣的通過第一階段的結果,可以知道兩個決策者都通過,所以超過半數投票
- ProposerThree(提議者3)正式發出提議到AcceptorTwo(決策者2)和AcceptorThree(決策者3),同樣的通過第一階段的結果,可以知道兩個決策者都沒有通過
第二塊:
- 從上面的第一塊結果來看,只有**ProposerTwo(提議者2)**得到半數同意,所以ProposerTwo(提議者2)立馬就能成為leader。至此選舉狀態就結束,即ProposerTwo(提議者2)會發布廣播給所有的learner,通知它們過來同步數據。當數據完成同步時,那個整個服務器的集群就能正常工作了。
總結
整個Paxos算法過程還是比較難理解,為了講明白這里面的流程都是按最簡單的例子來的。這里面也可以有更多的機器發起更多的提議。但是整個流程那就更難理解了。
理解Paxos算法需要按上面的兩個階段來理解。第一階段是做什么,得到了什么結果,第二階段又是基于第一階段的結果執行怎樣的一個選舉流程,這個是大家需要思考的重點。
這里主要是跟大家分享的是Paxos算法這個選舉過程,也有很多其他的優化版本比如 Fast Paxos、EPaxos等等。
Zookeeper
在zookeeper中的選舉算法就是用的 Fast Paxos算法,為什么用Fast paxos?
Fast Paxos算法是Paxos的優化版本,解決了Paxos算法的活鎖問題保證每次線程過來獲取到唯一的N值。
ZAB(Zookeeper Atomic BroadCast)原子廣播協議
ZAB其實就是上面算法的一種實現,所以Zookeeper也就是依賴ZAB來實現分布式數據的一致性的。
所以在zookeeper中,只有一臺服務器機器作為leader機器,所以當客戶端鏈接到機器的某一個節點時
- 當這個客戶端提交的是讀取數據請求,那么當前連接的機器節點,就會把自己保存的數據返回出去。
- 當這個客戶端提交的是寫數據請求時,首先會看當前連接的節點是不是leader節點,如果不是leader節點則會轉發出去到leader機器的節點上,由leader機器寫入,然后廣播出去通知其他的節點過來同步數據
在ZAB中的三類角色
- Leader:ZK集群的老大,唯一的一個可以進行寫數據的機器。
- Follower:ZK集群的具有一定職位的干活人。只能進行數據的讀取,當老大(leader)機器掛了之后可以參與選舉投票的機器。
- Observe:最小的干活小弟,只能進行數據讀取,就算老大(leader)機器掛了,跟他一毛關系沒有,不能參與選舉投票的機器。
在ZAB中的三個重點數據
- Zxid:是zookeeper中的事務ID,總長度為64位的長度的Long類型數據。其中有兩部分構成前32位是epoch后32位是xid
- Epoch:每一個leader都會有一個這個值,表示當前leader獲取到的最大N值,可以理解為“年代”
- Xid:事務ID,表示當前zookeeper集群當前提交的事物ID是多少(watch機制),方便選舉的過程后不會出現事務重復執行或者遺漏等一些特殊情況。
zookeeper中的一些知識點就分享到這里了,因為這里面還有很多很多東西,比如Session 、Znode、Watcher機制 、ACL、三種狀態模式 還zookeeper怎么實現分布式事務鎖等等。沒有辦法一次性跟大家聊完。
這次主要還是想讓學弟學妹了解清楚Zookeeper中的一致性的算法是怎么保證。
結尾
針對面試來說能完全的跟面試官講明白這個一致性算法,那你就已經走在前面了。整個過程還是比較復雜的,需要自己不斷的多看多畫圖理解。
在這個互聯內卷的時代,只有懂得比別人多才能走的比別人遠。
最后希望我的學弟學妹們都能有一個好的校招結果!!!