為何說KubeMQ會是Kafka的替代品?
譯文【51CTO.com快譯】為了實現這種復雜的操作,必須有某種類型的服務“郵局”來跟蹤所有請求和警報。實現這一目標的工具便是消息隊列。
消息隊列是一種專門的應用程序,它充當分布式應用程序的不同服務之間或不同應用程序之間的中介。它將應用程序服務彼此分離,確保無論消息接收者是否可用,都會進行處理。消息隊列確保最終成功接收所有消息。
消息隊列的常見用例包括:
- 不同應用程序之間的異步處理。
- 基于微服務的應用程序,其中不同組件之間的可靠通信至關重要。
- 事務排序和限制。
- 可以從批處理的簡化效率中受益的數據處理操作。
- 必須可擴展以滿足突然和意外需求變化的應用程序。
- 應用程序必須具有足夠的彈性才能從崩潰和意外故障中恢復。
- 通過長時間運行的進程限制資源消耗。
消息隊列領域不乏供應商。像Amazon Web Services、Microsoft Azure和谷歌cloud這樣的大型云平臺都有自己的產品(AWS Simple Queue Service、Azure的服務總線和谷歌的Pub/Sub)。也有獨立的通用消息代理,如RabbitMQ、Apache的ActiveMQ和Kafka。
本文介紹了一個名為KubeMQ的現代Kubernetes原生消息隊列,以嘗試讓已經在Kubernetes上使用kafka的組織如何從中受益。
什么是Apache Kafka
要了解 KubeMQ 的全部價值,我們首先需要花一些時間來了解 Kafka。Kafka 最初由 LinkedIn 工程師創建,作為跟蹤 LinkedIn 用戶活動的軟件總線。它后來作為開源產品發布,今天,Kafka 由 Apache 軟件基金會開發和管理。
Apache 指出,超過 80% 的財富 100 強公司信任并使用 Kafka。盡管是開源的,但眾所周知它是一個高度可擴展的系統,可以連接到廣泛的事件生產者和消費者。它可以配置為使用數據流執行復雜的功能,即使在有限的網絡環境中也能很好地工作。憑借在線用戶社區中廣泛可用的支持,Kafka 還提供多種商業產品。例如,AWS 提供托管 Kafka,Confluent 也是如此。
Kafka的局限性
盡管采用率很高,但 Kafka 并不總是作為消息隊列系統的最佳選擇。它具有單體架構,適用于本地集群或高端多虛擬機設置。鑒于 Kafka 需要多少內存和存儲空間,在獨立工作站上快速啟動多節點集群以進行測試可能是一項挑戰。
簡而言之,將 Kafka 與你的基礎設施集成所需的所有復雜部分成功地整合在一起并不容易。對于基于 Kubernetes 的架構尤其如此。
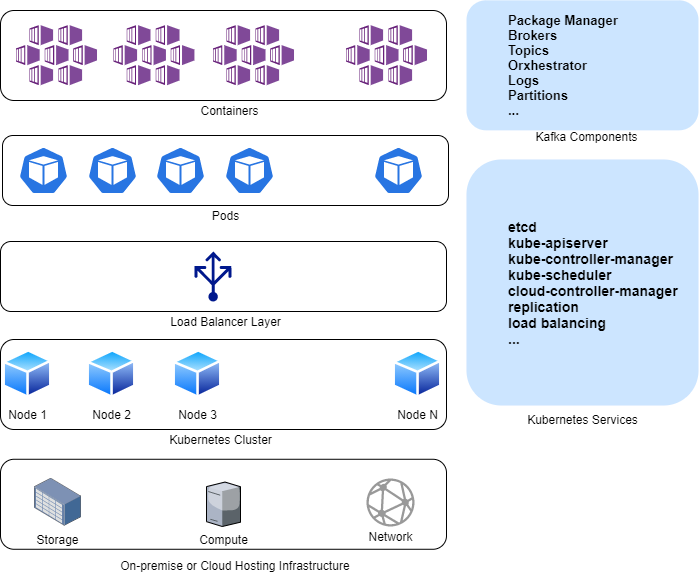
如下圖所示,基于 Kubernetes 的 Kafka 部署有不同的活動部分。除了為基本 Kubernetes 集群配置底層計算、網絡和存儲基礎設施(如果你在本地實施),你還需要安裝所有 Kafka 部分并將其與 Helm 等包管理器集成。這些組件可以包括一個協調器,如 ZooKeeper 或 Mesos,用于管理 Kafka 的代理和主題。其他需要注意的地方包括依賴、日志、分區等。如果甚至缺少一個元素或配置錯誤,事情都不會奏效——成功部署 Kafka 并非易事。
? ??
??
Kafka on Kubernetes 架構
將新的 Kafka 節點添加到 Kubernetes 集群需要復雜的手動平衡以保持最佳資源使用。這就是為什么沒有簡單的方法來管理和確保可靠的備份和恢復策略;對運行在大量節點上的 Kafka 集群進行防災并不容易。與 Kubernetes 集群中的數據保存在 pod 之外,并且編排器自動啟動失敗的 pod 不同,Kafka 沒有這樣的原生防故障機制。
最后,對 Kafka/ZooKeeper/Kubernetes 部署的有效監控需要第三方工具。
什么是KubeMQ
Kube MQ 是一種消息服務,從頭開始構建時就考慮到了 Kubernetes。遵循容器架構最佳實踐,KubeMQ 旨在實現無狀態和短暫的。也就是說,一個 KubeMQ 節點將在其整個生命周期內保持不變、可預測和可重現。如果需要更改配置,則會關閉并更換節點。
這種可重復性意味著,與 Kafka 不同,KubeMQ 帶有零配置設置,安裝后無需調整配置。
KubeMQ 旨在適應最廣泛的消息模式。它是一個消息代理和消息隊列,支持以下內容:
- 具有或不具有持久性的 Pub/Sub
- 請求/回復(同步、異步)
- 最多一次交貨
- 至少一次交付
- 流媒體模式
- RPC
相比之下,Kafka 只支持具有持久性和流式傳輸的 Pub/Sub。Kafka 根本不支持 RPC 和請求/回復模式。
在資源使用方面,KubeMQ 以最小的占用空間勝過 Kafka。KubeMQ docker 容器僅占用 30MB 空間。如此小的占地面積有助于容錯設置和簡化部署。與 Kafka 不同,將 KubeMQ 添加到本地工作站中的小型開發 Kubernetes 環境非常簡單。但與此同時,KubeMQ 具有足夠的可擴展性,可以部署在運行在數百個本地和云托管節點上的混合環境中。這種易于部署的核心是kubemqctl,它是KubeMQ的命令行界面工具,類似于 Kubernetes 的 kubectl。
KubeMQ 優于 Kafka 的另一個方面是它的速度。Kafka 是用 Java 和 Scala 編寫的,而 KubeMQ 是用 Go 編寫的,確保快速運行。在內部基準操作中,KubeMQ 處理 100 萬條消息的速度比 Kafka 快 20%。
回到 KubeMQ 的“免配置”方面,通道是開發人員唯一需要創建的對象。你可以忘記代理、交換和協調器——KubeMQ 的 Raft 代替 ZooKeeper 完成所有這些工作。
從監控的角度來看,通過 Prometheus 和 Grafana 的儀表板與 KubeMQ 完全集成,因此你無需手動集成第三方可觀察性工具的額外工作。但是,由于 KubeMQ 與工具的原生集成,你仍然可以使用現有的日志記錄和監控解決方案,包括:
- Fluentd、Elastic 和 Datadog,用于監控
- Loggly,用于記錄
- Jaeger 和 Open Tracing,用于跟蹤
由于Kafka 不是云原生計算基金會 (CNCF) 環境的原生部分,因此通常不支持與 CNCF 工具的集成,必須手動配置。
如果配置好,可以通過開源的gRPC遠程過程調用系統進行連接,其與Kubernetes的卓越兼容性是眾所周知的。Kafka 自己專有的連接機制不一定能提供可比的結果。
從 Kafka 到 KubeMQ 的透明遷移
除了 KubeMQ 的部署和操作簡單之外,將現有的 Kafka 設置移植到 KubeMQ 也很簡單。
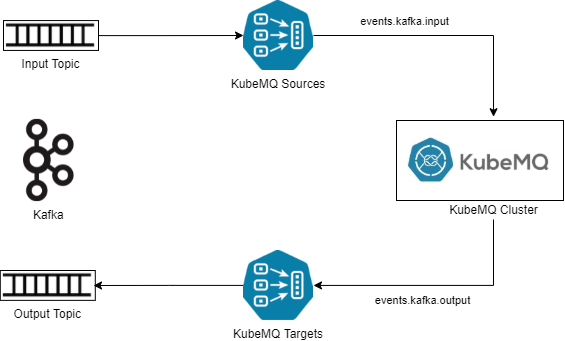
為此,開發人員可以從使用 KubeMQ Kafka 連接器開始。KubeMQ 目標和源連接器被配置為轉換來自 Kafka 的消息。在高層次上,KubeMQ 源連接器作為訂閱者消費來自 Kafka 源主題的消息,將消息轉換為 KubeMQ 消息格式,然后將消息發送到內部日志。KubeMQ 目標連接器訂閱包含轉換消息的輸出日志,然后將消息發送到 Kafka 中的目標主題。高層架構如下圖所示:
? ??
??
Kafka 與 KubeMQ 的集成
此外,Kafka 支持的任何消息傳遞模式都由 KubeMQ 支持。例如,Kafka 僅支持具有持久性和流的 Pub/Sub。KubeMQ 是一個消息隊列和消息代理,支持 Pub/Sub(有或沒有持久化)請求/回復(同步、異步)、至少一種交付、流模式和 RPC。因此,從 Kafka 遷移到 KubeMQ 時,無需重構應用程序代碼并適應復雜的邏輯變化。
最后
對于大多數工作負載,KubeMQ內置的簡單性、輕量級和容器優先集成將提供優于 Kafka 的性能。此外,所需的幾乎為零的配置將節省大量的管理和設置時間。正如我們提到的,遷移很簡單。
KubeMQ 是免費下載的,附帶六個月的免費開發試用版。如果你使用 OpenShift,可以在 Red Hat Marketplace 中使用 KubeMQ 。它還適用于所有主要云環境,包括 GCP、AWS、Azure 和 DigitalOcean。
【51CTO譯稿,合作站點轉載請注明原文譯者和出處為51CTO.com】