













企業(yè)級(jí)推薦系統(tǒng)為什么拆解為召回、排序兩個(gè)階段?
大家好,我是強(qiáng)哥。一個(gè)熱愛(ài)暴走、讀書(shū)、寫(xiě)作的人!
推薦算法從業(yè)者肯定知道,在企業(yè)級(jí)推薦系統(tǒng)中,一般將推薦算法業(yè)務(wù)流程拆分為召回和排序兩個(gè)階段(有些公司還將排序分為粗排和精排,我們這里不加區(qū)分了,見(jiàn)下面圖)。為什么這么做呢?這樣做有什么好處嗎?將推薦算法流程分為召回和排序兩個(gè)階段,好處是非常多的,本文我們就從多個(gè)角度來(lái)解釋這么做的價(jià)值主要體現(xiàn)在哪里。
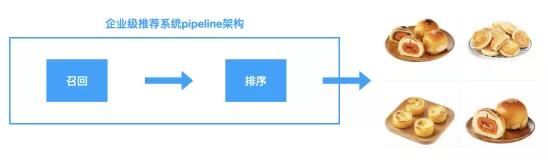
在講解之前,簡(jiǎn)單說(shuō)一個(gè)召回和排序這兩個(gè)階段分別解決的問(wèn)題,方便大家更好地理解下面的講述。召回就是采用比較多的方法和策略從物品庫(kù)中將用戶可能喜歡的物品挑選出來(lái),一般召回的是幾十到幾百個(gè)物品。排序階段是將不同召回算法獲得的結(jié)果采用一個(gè)統(tǒng)一的模型進(jìn)行重新打分排序,將得分最高的幾十個(gè)作為最終的物品推薦給用戶。通過(guò)召回,我們事先就從海量的全物品庫(kù)中過(guò)濾出了少量的用戶可能喜歡的物品了,這大大減少了排序階段需要處理的物品數(shù)量。
講解完了召回和排序兩個(gè)階段的作用,下面我們從4個(gè)維度來(lái)說(shuō)明企業(yè)級(jí)推薦算法流程為什么拆解為召回和排序兩個(gè)階段。
1. 推薦算法流程解耦合
我們知道推薦系統(tǒng)是一個(gè)偏工程的計(jì)算機(jī)與機(jī)器學(xué)習(xí)的交叉學(xué)科,那么軟件工程的一些思路和做法也是適合推薦系統(tǒng)的。將推薦算法流程拆分為召回和排序兩個(gè)階段,那么推薦算法就分解為兩個(gè)相對(duì)獨(dú)立的子系統(tǒng)了。我們可以分別對(duì)每個(gè)子系統(tǒng)進(jìn)行迭代、優(yōu)化、升級(jí),出了問(wèn)題也方便我們?nèi)シ治觥⒍ㄎ弧⑴挪椤⑿迯?fù)、優(yōu)化。總之,拆分為兩個(gè)系統(tǒng),更易于進(jìn)行系統(tǒng)開(kāi)發(fā)與維護(hù)。軟件工程的思路就是分而治之的思路,這個(gè)做法是跟軟件工程的思路一脈相承的。
2. 有利于團(tuán)隊(duì)的分工協(xié)作
將推薦算法流程拆分為召回、排序兩個(gè)階段,這對(duì)于規(guī)模比較大的算法團(tuán)隊(duì),也方便進(jìn)行更精細(xì)化的任務(wù)安排和人員職能分派。讓不同的人聚焦在某一個(gè)小的領(lǐng)域,這樣更容易讓員工在這個(gè)方向上做到極致。畢竟召回、排序的思路、方法、策略還有有差異的,讓不同的人分工做不同的模塊,更聚焦。
3. 可實(shí)現(xiàn)性上的考慮
隨著深度學(xué)習(xí)技術(shù)的發(fā)展,我們知道深度學(xué)習(xí)技術(shù)等復(fù)雜推薦模型可以達(dá)到比傳統(tǒng)模型好得多的推薦效果。因此,大家肯定愿意去嘗試更復(fù)雜的模型。但是復(fù)雜的模型在特征預(yù)處理、推斷時(shí)間花費(fèi)、推薦服務(wù)延遲等方面相對(duì)傳統(tǒng)簡(jiǎn)單的模型有更高的要求。這里舉個(gè)推斷時(shí)間花費(fèi)的例子,在一個(gè)用戶規(guī)模和物品規(guī)模都非常大的應(yīng)用場(chǎng)景中(比如抖音、淘寶等),用一個(gè)復(fù)雜的深度學(xué)習(xí)模型去對(duì)每個(gè)用戶物品組合進(jìn)行打分是非常耗時(shí)的,也是不現(xiàn)實(shí)的。如果召回階段事先篩選出了少量的用戶可能喜歡的物品,那么排序階段的工作量就小了很多了。
另外,目前信息流推薦是推薦系統(tǒng)的標(biāo)配技術(shù)了,在實(shí)時(shí)推薦場(chǎng)景下,對(duì)時(shí)效性的要求就更高了。推薦算法進(jìn)行拆解對(duì)于近實(shí)時(shí)完成推薦推斷過(guò)程是非常關(guān)鍵、必不可少的。
4. 提升推薦精準(zhǔn)度上的考慮
將推薦算法流程拆分為召回和排序兩個(gè)階段。那么每個(gè)階段可以解決本階段的核心問(wèn)題。最終可以更好地提升推薦的精準(zhǔn)度。下面分別加以說(shuō)明。
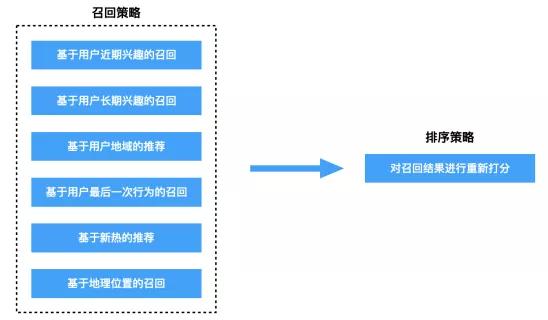
推薦系統(tǒng)召回階段的主要目標(biāo)是將用戶可能喜歡的物品篩選出來(lái),目的是不要漏掉用戶可能會(huì)喜歡的物品。一般召回階段可以采用很多的方法進(jìn)行召回,比如基于內(nèi)容標(biāo)簽的召回、基于用戶畫(huà)像的召回、基于用戶最近行為的召回、基于熱門(mén)的召回、基于地域(或者位置)的召回、基于特殊事件的召回、基于時(shí)間的召回、基于協(xié)同過(guò)濾的召回等等(參考下圖)。不同召回算法考慮的是用戶興趣點(diǎn)的某個(gè)方面,那么用多種召回算法就可以更好地覆蓋用戶更多樣化的興趣點(diǎn),最終將用戶所有喜歡的物品篩選出來(lái),避免遺漏掉重要的興趣點(diǎn)。
排序階段只對(duì)少量的、召回階段篩選出的物品進(jìn)行打分,因而可以選擇效果好的、復(fù)雜的算法模型(比如深度學(xué)習(xí)模型等)。在這一階段我們可以將精力聚焦在模型的效果上。
如果用統(tǒng)計(jì)誤差的思路來(lái)看召回、排序這個(gè)拆解過(guò)程,那么每個(gè)召回算法相當(dāng)于一次隨機(jī)變量的抽樣(抽樣的是用戶的興趣這個(gè)隨機(jī)變量),由于自身方法的原因,每個(gè)召回算法是有一定誤差的,不同的召回算法的誤差方向是不一樣的 。那么當(dāng)我們?cè)谂判螂A段將所有召回算法的結(jié)果匯聚起來(lái)時(shí),各個(gè)召回算法的誤差是可能相互抵消的,最終可以獲得更精準(zhǔn)的推薦結(jié)果。
推薦系統(tǒng)將算法流程分解為召回排序兩個(gè)階段,這個(gè)做法也可以用集成學(xué)習(xí)的思路解釋?zhuān)和ㄟ^(guò)多個(gè)模型的集成,獲得整體更優(yōu)的效果。召回階段就是利用了多個(gè)模型,可能每個(gè)模型刻畫(huà)的是用戶興趣的某個(gè)方面,它不太準(zhǔn),但是沒(méi)關(guān)系,只要找準(zhǔn)了用戶的某個(gè)興趣點(diǎn)就夠了。我們?cè)谂判螂A段會(huì)將這些召回算法的結(jié)果整合起來(lái),獲得最終的最有利于描述用戶興趣的結(jié)果。
上面我們從4個(gè)角度來(lái)說(shuō)明了為什么企業(yè)級(jí)推薦系統(tǒng)的推薦算法流程要拆解為召回、排序兩個(gè)階段。希望通過(guò)本文的學(xué)習(xí),讀者可以更好地理解這種設(shè)計(jì)的哲學(xué),同時(shí),也希望讀者可以更加深入地理解推薦算法流程。














