













Flink SQL 知其所以然之流 Join 很難嘛???(下)
1.序篇
本節是 flink sql 流 join 系列的下篇,上篇的鏈接如下:
flink sql 知其所以然之:流 join 很難嘛???(上)
廢話不多說,咱們先直接上本文的目錄和結論,小伙伴可以先看結論快速了解博主期望本文能給小伙伴們帶來什么幫助:
- 背景及應用場景介紹:博主期望你能了解到,flink sql 提供的豐富的 join 方式(總結 6 種:regular join,維表 join,快照 join,interval join,array 拍平,table function)對我們滿足需求提供了強大的后盾, 這 6 種 join 中涉及到流與流的 join 最常用的是 regular join 以及 interval join,本節主要介紹 interval join
- 來一個實戰案例:博主以上節說到的曝光日志流點擊日志流為案例展開,主要是想告訴小伙伴 flink sql left join 數據不會互相等待,存在 retract 問題,會導致寫入 kafka 的數據量變大, 然后轉變思路為使用 flink sql interval join 的方式可以使得數據互相等待一段時間進行 join,這種方式不會存在 retract 問題
- flink sql interval join 的解決方案以及原理的介紹:主要介紹 interval join 的在上述實戰案例的運行結果及分析源碼機制,博主期望你能了解到,interval join 的執行機制是會在你設置的 interval 區間之內互相等待一段時間,一旦時間推進(事件時間由 watermark 推進)到區間之外(即當前這條數據再也不可能被另一條流的數據 join 到時),outer join 會輸出沒有 join 到的數據,inner join 會從 state 中刪除這條數據
- 總結及展望
2.背景及應用場景介紹
書接上文,上文介紹了曝光流在關聯點擊流時,使用 flink sql regular join 存在的 retract 問題。
本文介紹怎么使用 flink sql interval join 解決這些問題。
3.來一個實戰案例
flink sql 知其所以然之流 join 很難嘛???(上)
看看上節的實際案例,來看看在具體輸入值的場景下,輸出值應該長啥樣。
場景:即常見的曝光日志流(show_log)通過 log_id 關聯點擊日志流(click_log),將數據的關聯結果進行下發。
來一波輸入數據:
曝光數據:
| log_id | timestamp | show_params |
|---|---|---|
| 1 | 2021-11-01 00:01:03 | show_params |
| 2 | 2021-11-01 00:03:00 | show_params2 |
| 3 | 2021-11-01 00:05:00 | show_params3 |
點擊數據:
| log_id | timestamp | click_params |
|---|---|---|
| 1 | 2021-11-01 00:01:53 | click_params |
| 2 | 2021-11-01 00:02:01 | click_params2 |
預期輸出數據如下:
| log_id | timestamp | show_params | click_params |
|---|---|---|---|
| 1 | 2021-11-01 00:01:00 | show_params | click_params |
| 2 | 2021-11-01 00:01:00 | show_params2 | click_params2 |
| 3 | 2021-11-01 00:02:00 | show_params3 | null |
上節的 flink sql regular join 解決方案如下:
- INSERT INTO sink_table
- SELECT
- show_log.log_id as log_id,
- show_log.timestamp as timestamp,
- show_log.show_params as show_params,
- click_log.click_params as click_params
- FROM show_log
- LEFT JOIN click_log ON show_log.log_id = click_log.log_id;
上節說道,flink sql left join 在流數據到達時,如果左表流(show_log)join 不到右表流(click_log) ,則不會等待右流直接輸出(show_log,null),在后續右表流數據代打時,會將(show_log,null)撤回,發送(show_log,click_log)。這就是為什么產生了 retract 流,從而導致重復寫入 kafka。
對此,我們也是提出了對應的解決思路,既然 left join 中左流不會等待右流,那么能不能讓左流強行等待右流一段時間,實在等不到在數據關聯不到的數據即可。
當當當!!!
本文的 flink sql interval join 登場,它就能等。
4.flink sql interval join
4.1.interval join 定義
大家先通過下面這句話和圖簡單了解一下 interval join 的作用(熟悉 DataStream 的小伙伴萌可能已經使用過了),后續會詳細介紹原理。
interval join 就是用一個流的數據去關聯另一個流的一段時間區間內的數據。關聯到就下發關聯到的數據,關聯不到且在超時后就根據是否是 outer join(left join,right join,full join)下發沒關聯到的數據。
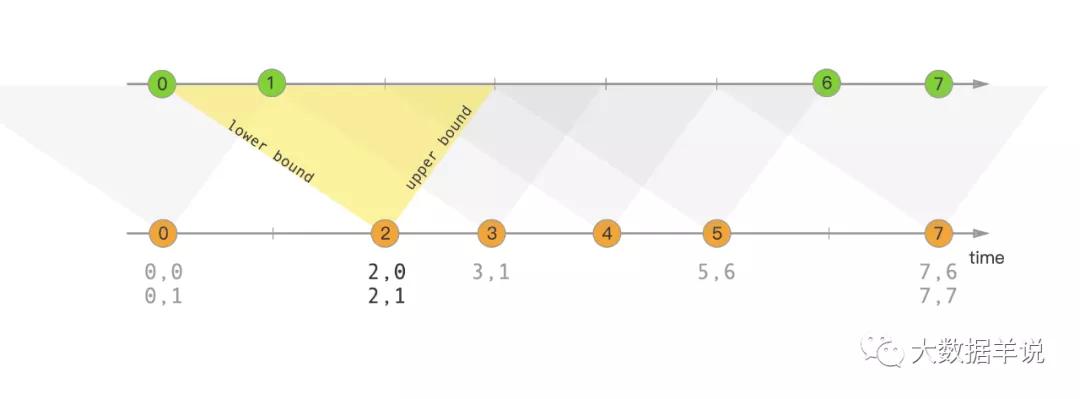
interval join
4.2.案例解決方案
來看看上述案例的 flink sql interval join sql 怎么寫:
- INSERT INTO sink_table
- SELECT
- show_log.log_id as log_id,
- show_log.timestamp as timestamp,
- show_log.show_params as show_params,
- click_log.click_params as click_params
- FROM show_log LEFT JOIN click_log ON show_log.log_id = click_log.log_id
- AND show_log.row_time
- BETWEEN click_log.row_time - INTERVAL '10' MINUTE
- AND click_log.row_time + INTERVAL '10' MINUTE;
這里設置了 show_log.row_time BETWEEN click_log.row_time - INTERVAL '10' MINUTE AND click_log.row_time + INTERVAL '10' MINUTE代表 show_log 表中的數據會和 click_log 表中的 row_time 在前后 10 分鐘之內的數據進行關聯。
運行結果如下:
- +[1 | 2021-11-01 00:01:03 | show_params | click_params]
- +[2 | 2021-11-01 00:03:00 | show_params | click_params]
- +[3 | 2021-11-01 00:05:00 | show_params | null]
如上就是我們期望的正確結果了。
flink web ui 算子圖如下:

flink web ui
那么此時你可能有一個問題,結果中的前兩條數據 join 到了輸出我是理解的,那當 show_log join 不到 click_log 時為啥也輸出了?原理是啥?
博主帶你們來定位到具體的實現源碼。先看一下 transformations。
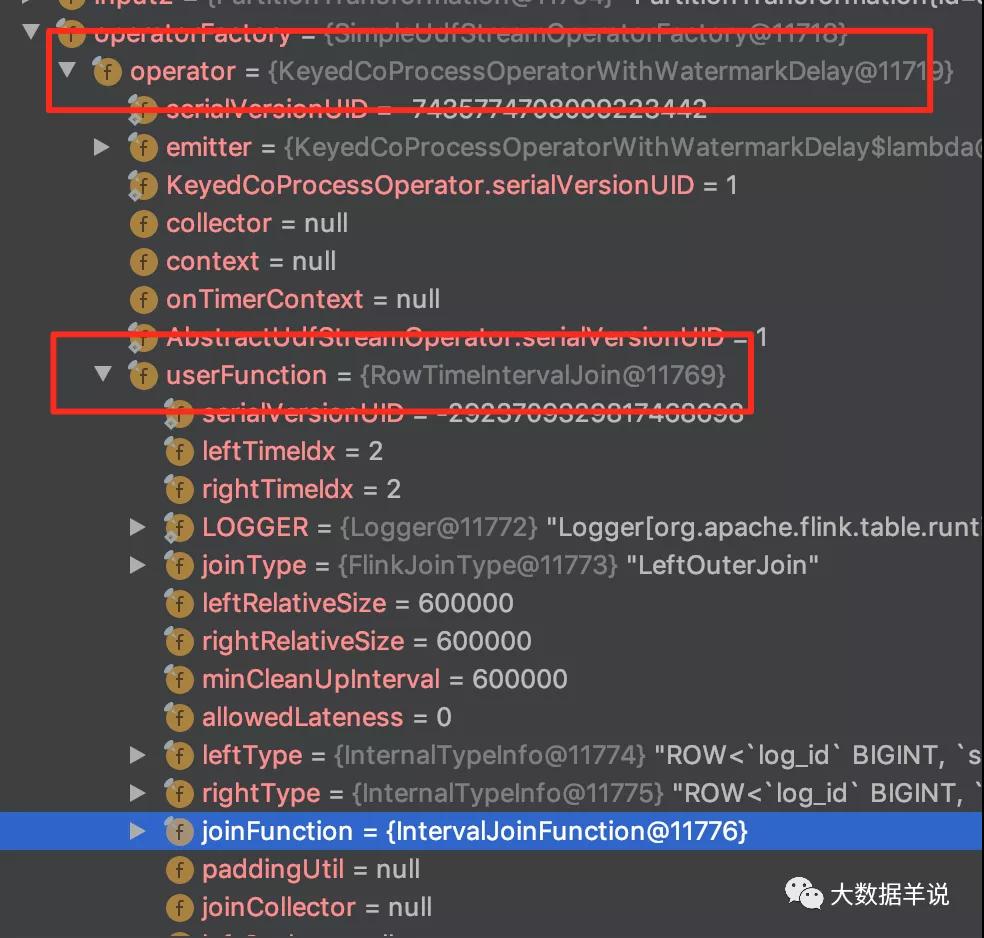
transformations
可以看到事件時間下 interval join 的具體 operator 是 org.apache.flink.table.runtime.operators.join.KeyedCoProcessOperatorWithWatermarkDelay。
其核心邏輯就集中在 processElement1 和 processElement2 中,在 processElement1 和 processElement2 中使用 org.apache.flink.table.runtime.operators.join.interval.RowTimeIntervalJoin 來處理具體 join 邏輯。RowTimeIntervalJoin 重要方法如下圖所示。
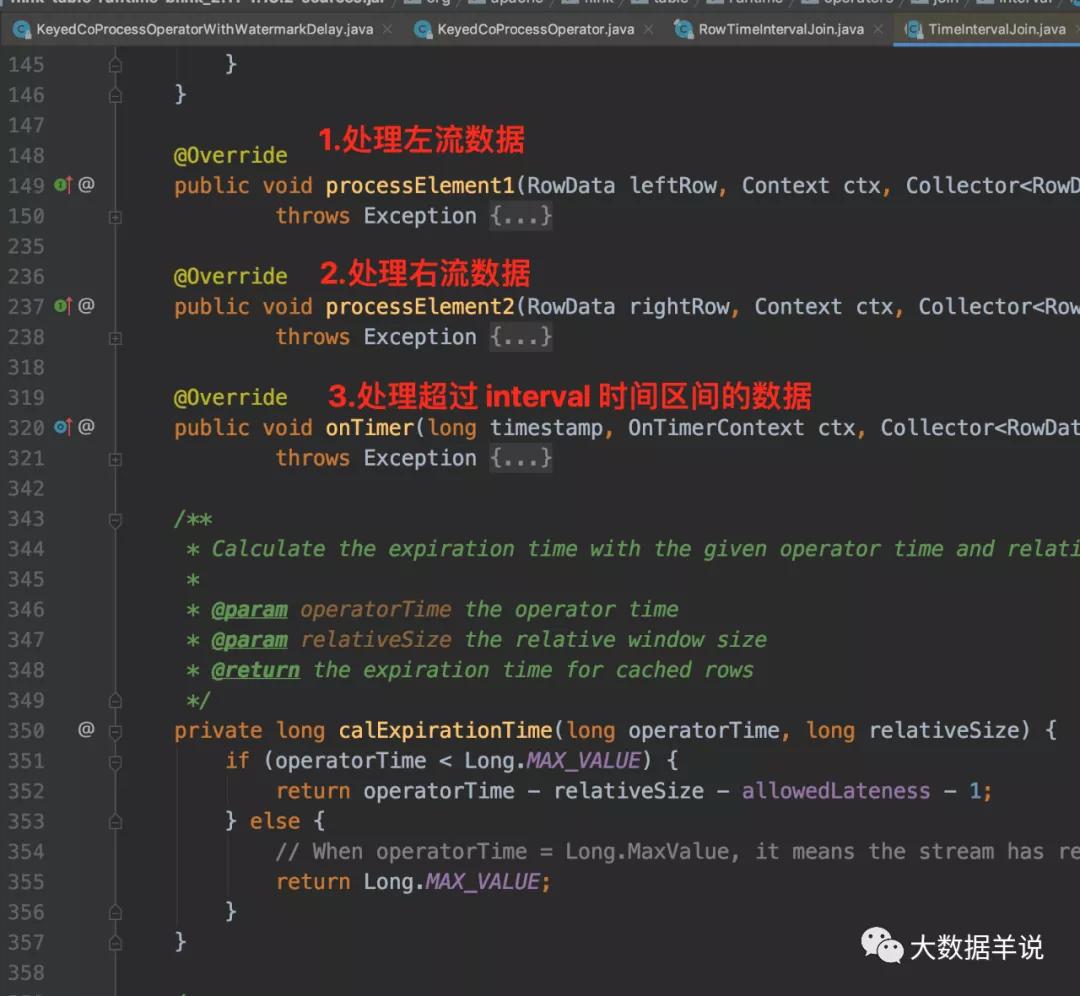
TimeIntervalJoin
下面詳細給大家解釋一下。
4.3.TimeIntervalJoin 簡版說明
join 時,左流和右流會在 interval 時間之內相互等待,如果等到了則輸出數據[+(show_log,click_log)],如果等不到,并且另一條流的時間已經推進到當前這條數據在也不可能 join 到另一條流的數據時,則直接輸出[+(show_log,null)],[+(null,click_log)]。
舉個例子,show_log.row_time BETWEEN click_log.row_time - INTERVAL '10' MINUTE AND click_log.row_time + INTERVAL '10' MINUTE, 當 click_log 的時間推進到 2021-11-01 11:00:00 時,這時 show_log 來一條 2021-11-01 02:00:00 的數據, 那這條 show_log 必然不可能和 click_log 中的數據 join 到了,因為 click_log 中 2021-11-01 01:50:00 到 2021-11-01 02:10:00 之間的數據以及過期刪除了。則 show_log 直接輸出 [+(show_log,null)]
Notes:
如果你設置了 allowLateness,join 不到的數據的輸出和 state 的清理會多保留 allowLateness 時間
4.4.TimeIntervalJoin 詳細實現說明
以上面案例的 show_log(左表) interval join click_log(右表) 為例(不管是 inner interval join,left interval join,right interval join 還是 full interval join,都會按照下面的流程執行):
第一步,首先如果 join xxx on 中的條件是等式則代表 join 是在相同 key 下進行的(上述案例中 join 的 key 即 show_log.log_id,click_log.log_id),相同 key 的數據會被發送到一個并發中進行處理。如果 join xxx on 中的條件是不等式,則兩個流的 source 算子向 join 算子下發數據是按照 global 的 partition 策略進行下發的,并且 join 算子并發會被設置為 1,所有的數據會被發送到這一個并發中處理。
第二步,相同 key 下,一條 show_log 的數據先到達,首先會計算出下面要使用的最重要的三類時間戳:
- 根據 show_log 的時間戳(l_time)計算出能關聯到的右流的時間區間下限(r_lower)、上限(r_upper)
- 根據 show_log 目前的 watermark 計算出目前右流的數據能夠過期做過期處理的時間的最小值(r_expire)
- 獲取左流的 l_watermark,右流的 r_watermark,這兩個時間戳在事件語義的任務中都是 watermark
第三步,遍歷所有同 key 下的 click_log 來做 join
- 對于遍歷的每一條 click_log,走如下步驟
- 經過判斷,如果 on 中的條件為 true,則和 click_log 關聯,輸出[+(show_log,click_log)]數據;如果 on 中的條件為 false,則啥也不干
- 接著判斷當前這條 click_log 的數據時間(r_time)是否小于右流的數據過期時間的最小值(r_expire)(即判斷這條 click_log 是否永遠不會再被 show_log join 到了)。如果小于,并且當前 click_log 這一側是 outer join,則不用等直接輸出[+(null,click_log)]),從狀態刪除這條 click_log;如果 click_log 這一側不是 outer join,則直接從狀態里刪除這條 click_log。
第四步,判斷右流的時間戳(r_watermark)是否小于能關聯到的右流的時間區間上限(r_upper):
- 如果是,則說明這條 show_log 還有可能被 click_log join 到,則 show_log 放到 state 中,并注冊后面用于狀態清除的 timer。
- 如果否,則說明關聯不到了,則輸出[+(show_log,null)]
第五步,timer 觸發時:
- timer 觸發時,根據當前 l_watermark,r_watermark 以及 state 中存儲的 show_log,click_log 的 l_time,r_time 判斷是否再也不會被對方 join 到,如果是,則根據是否為 outer join 對應輸出[+(show_log,null)],[+(null,click_log)],并從狀態中刪除對應的 show_log,click_log。
上面只是左流 show_log 數據到達時的執行流程(即 ProcessElement1),當右流 click_log 到達時也是完全類似的執行流程(即 ProcessElement2)。
4.5.使用注意事項
小伙伴萌在使用 interval join 需要注意的兩點事項:
interval join 的時間區間取決于日志的真實情況:設置大了容易造成任務的 state 太大,并且時效性也會變差。設置小了,join 不到,下發的數據在后續使用時,數據質量會存在問題。所以小伙伴萌在使用時建議先使用離線數據做一遍兩條流的時間戳 diff 比較,來確定真實情況下的時間戳 diff 的分布是怎樣的。舉例:你通過離線數據 join 并做時間戳 diff 后發現 99% 的數據都能在時間戳相差 5min 以內 join 到,那么你就有依據去設置 interval 時間差為 5min。
interval join 中的時間區間條件即支持事件時間,也支持處理時間。事件時間由 watermark 推進。
5.總結與展望
源碼公眾號后臺回復1.13.2 sql interval join獲取。
本文主要介紹了 flink sql interval 是怎么避免出現 flink regular join 存在的 retract 問題的,并通過解析其實現說明了運行原理,博主期望你讀完本文之后能了解到:
背景及應用場景介紹:博主期望你能了解到,flink sql 提供的豐富的 join 方式(總結 6 種:regular join,維表 join,快照 join,interval join,array 拍平,table function)對我們滿足需求提供了強大的后盾, 這 6 種 join 中涉及到流與流的 join 最常用的是 regular join 以及 interval join,本節主要介紹 interval join
來一個實戰案例:博主以上節說到的曝光日志流點擊日志流為案例展開,主要是想告訴小伙伴 flink sql left join 數據不會互相等待,存在 retract 問題,會導致寫入 kafka 的數據量變大, 然后轉變思路為使用 flink sql interval join 的方式可以使得數據互相等待一段時間進行 join,這種方式不會存在 retract 問題
flink sql interval join 的解決方案以及原理的介紹:主要介紹 interval join 的在上述實戰案例的運行結果及分析源碼機制,博主期望你能了解到,interval join 的執行機制是會在你設置的 interval 區間之內互相等待一段時間,一旦時間推進(事件時間由 watermark 推進)到區間之外(即當前這條數據再也不可能被另一條流的數據 join 到時),outer join 會輸出沒有 join 到的數據,inner join 會從 state 中刪除這條數據
總結及展望























