文件的拷貝、字節流的緩沖區、BufferedInputStream類
前言
本文主要學習文件的拷貝、字節流的緩沖區、BufferedInputStream類。讀取文件如果一個一個的讀寫,這樣的操作文件效率太低,通過學習字節流的緩沖區通過一個字節數組來讀取多個字節的數據,再把字節數組的數據一次性的寫入文件中。接下來小編帶大家一起來學習!
一、文件的拷貝
1.文件的拷貝是通過輸入流來讀取文件的數據,通過輸出流把數據寫入文件。怎么進行文件復制的呢?使用FileInputStream類與FileOutputStream類復制文件。
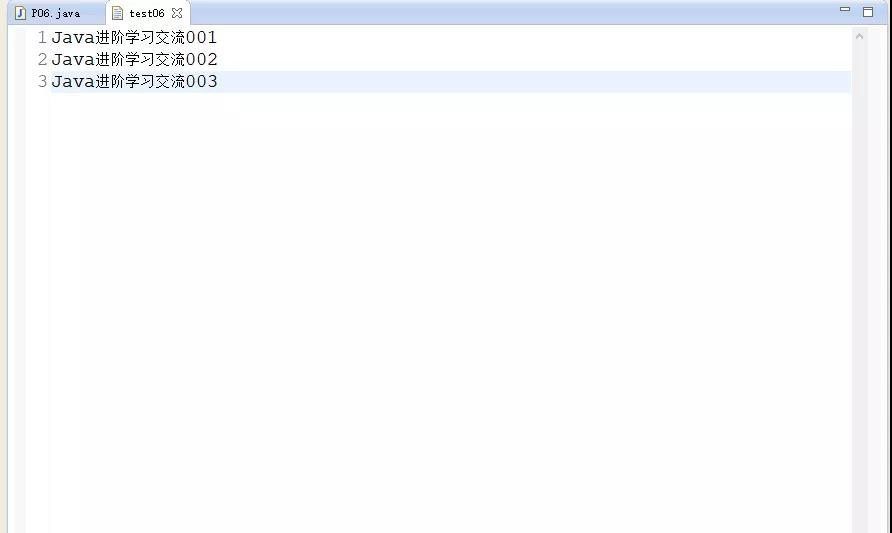
2.首先在text文件夾下創建一個test06.txt文件,并寫入內容為“Java進階學習交流001、Java進階學習交流002、Java進階學習交流003”,如下圖所示:
3.代碼實現文件的拷貝如下所示:
- import java.io.*;
- public class P06 {
- public static void main(String[] args) throws Exception {
- // TODO Auto-generated method stub
- //創建一個字節輸入流,讀取text文件夾下test06.txt數據
- InputStream in = new FileInputStream("text/test06");
- //創建一個字節輸出流,用來讀取數據并在text文件夾下創建一個test07.txt文件
- OutputStream out = new FileOutputStream("text/test07");
- int num;//定義個int類型的變量num,保存每次讀取的一個字節
- //復制文件前的系統時間
- long startTime=System.currentTimeMillis();
- //while循環判斷讀取的一個字節是否讀到文件的末尾
- while((num=in.read())!=-1){
- //讀到的數據寫到文件中
- out.write(num);
- }
- //復制文件后的系統時間
- long endTime=System.currentTimeMillis();
- System.out.println("復制文件所使用的時間是:"+(endTime-startTime)+"毫秒");
- //關閉流
- in.close();
- out.close();
- }
- }
運行的結果如下圖所示:
二、字節流的緩沖區
1.在實現文件拷貝時,如果一個個字節來讀寫,經常操作文件這樣的效率太低了。首先創建一個字節數組來保存一次性讀取多個字節的數據,再把字節數組中的數據一次性寫入文件。這里的緩沖區相當字節數組!
2.如何使用緩沖區拷貝文件?
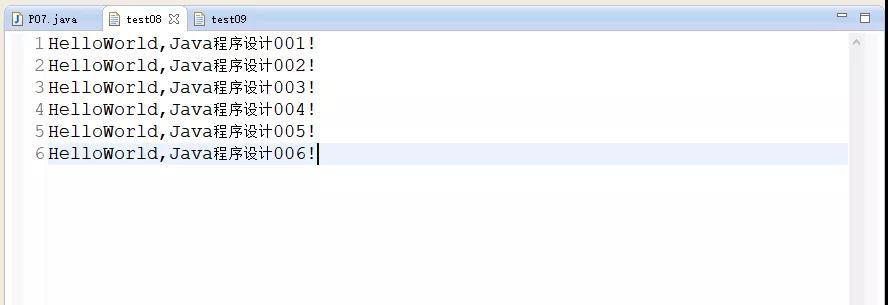
(1)首先在text文件夾下創建一個test08.txt文件,并寫入內容為“HelloWorld,Java程序設計001!、HelloWorld,Java程序設計002!、HelloWorld,Java程序設計003!、HelloWorld,Java程序設計004!、HelloWorld,Java程序設計005!、HelloWorld,Java程序設計006!”,如下圖所示:
(2)代碼如下所示:
- import java.io.*;
- public class P07 {
- public static void main(String[] args) throws Exception {
- // TODO Auto-generated method stub
- //創建一個字節輸入流,讀取text文件夾下test08.txt數據
- InputStream in = new FileInputStream("text/test08");
- //創建一個字節輸出流,用來讀取數據并在text文件夾下創建一個test09.txt文件
- OutputStream out = new FileOutputStream("text/test09");
- //定義字節數組使用緩存區讀寫文件數據
- byte bt[]=new byte[1024];
- //定義一個int類型的變量num,保存讀取讀到緩沖區的字節數
- int num;
- //復制文件前的系統時間
- long startTime=System.currentTimeMillis();
- //while循環判斷讀取的字節是否讀到文件的末尾
- while((num=in.read(bt))!=-1){
- out.write(bt,0,num);
- }
- //復制文件后的系統時間
- long endTime=System.currentTimeMillis();
- System.out.println("復制文件所使用的時間是:"+(endTime-startTime)+"毫秒");
- //關閉流
- in.close();
- out.close();
- }
- }
運行的結果如下圖所示:
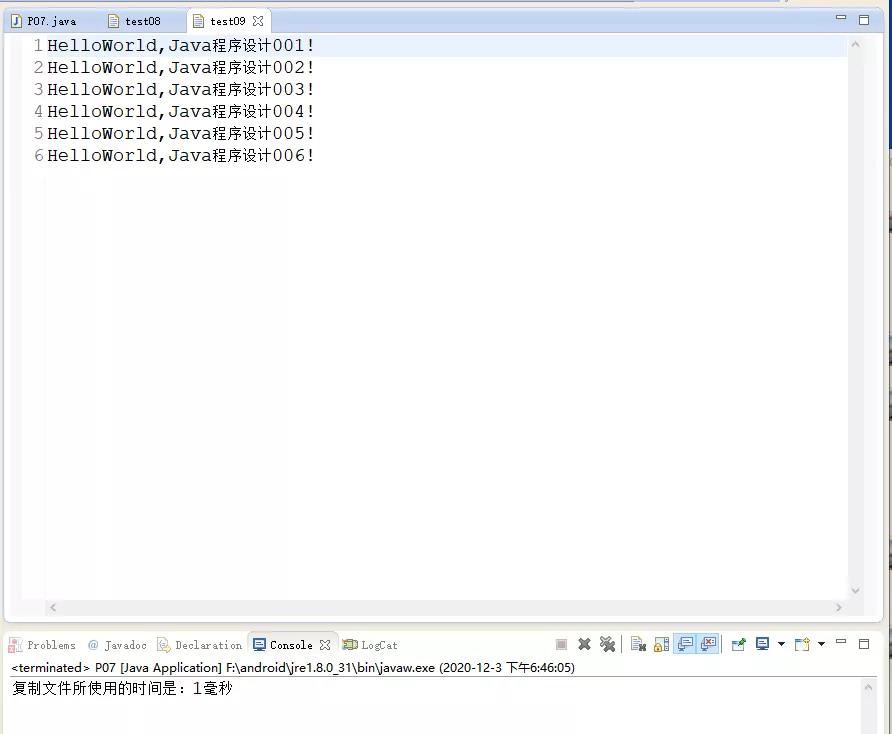
上面代碼中主要實現了test08.txt文件的拷貝,拷貝過程中使用到了while循環將字節文件進行拷貝,每循環一次在test08.txt文件中讀取很多個字節保存到數組中,通過變量num保存讀取的數組的字節數,從數組的第一個字節開始,把num個字節寫到文件中,當num值為-1,讀取文件就結束了。最終實現了文件之間的拷貝是通過字節流的緩沖區。
三、BufferedInputStream類
1.BufferedInputStream是緩沖輸入流,可以減少訪問磁盤的次數,提高文件的讀取性能,它是FilterInputStream類的子類。
2.BufferedInputStream作用它相對于普通輸入流優點是,它有一個緩沖數組,每次去調用read()方法,先從緩沖區讀取數據,如果讀取數據失敗,從文件讀取新數據放到緩沖區,再把緩沖區的內容顯示出來。
3.如何用BufferedInputStream類讀取文本內容?
(1)定義一個字節數組bt,再通過循環把文本內容循環讀到bt中,再把讀取到的數據顯示出來。
(2)首先再text文件夾下創建一個test10.txt文件并寫入"Java進階學習交流001!"的內容。
(3)代碼的實現:
- import java.io.*;
- public class P08 {
- public static void main(String[] args) throws Exception {
- // TODO Auto-generated method stub
- //創建一個帶有緩沖區的輸入流
- BufferedInputStream bi = new BufferedInputStream(new FileInputStream("text/test10"));
- //定義字節數組
- byte[] bt = new byte[1024];
- int num = 0;
- //判斷是否讀到文件的末尾
- while ((num = bi.read(bt)) != -1) {
- //讀取的字節轉為字符串對象
- String s = new String(bt, 0, num);
- System.out.println("讀取的內容是:"+s);
- }
- //關閉流
- bi.close();
- }
- }
運行的結果如下圖所示:
四、總結
本文主要介紹了文件的拷貝、字節流的緩沖區、BufferedInputStream類。文件的拷貝是輸入流來讀取文件的數據,通過輸出流把數據寫入文件。字節流的緩沖區創建一個字節數組來保存一次性讀取多個字節的數據,再把字節數組中的數據一次性寫入文件。BufferedInputStream是緩沖輸入流,可以減少訪問磁盤的次數,提高文件的讀取性能,它是FilterInputStream類的子類;它有一個緩沖數組,每次去調用read()方法,先從緩沖區讀取數據,如果讀取數據失敗,從文件讀取新數據放到緩沖區,再把緩沖區的內容顯示出來。希望通過本文的學習,對你有所幫助!
本文轉載自微信公眾號「Java進階學習交流」,可以通過以下二維碼關注。轉載本文請聯系Java進階學習交流公眾號。