













不止SQL優(yōu)化!數(shù)據(jù)庫(kù)還有哪些優(yōu)化大法?
前言
當(dāng)有人問(wèn)你如何對(duì)數(shù)據(jù)庫(kù)進(jìn)行優(yōu)化時(shí),很多人第一反應(yīng)想到的就是SQL優(yōu)化,如何創(chuàng)建索引,如何改寫SQL,他們把數(shù)據(jù)庫(kù)優(yōu)化與SQL優(yōu)化劃上了等號(hào)。
當(dāng)然這不能算是完全錯(cuò)誤的回答,只不過(guò)思考的角度稍微片面了些,太“程序員思維”化了,沒(méi)有站在更高層次來(lái)思考回答。那今天我們就將視角拔高,站在架構(gòu)的角度來(lái)聊聊這一問(wèn)題,數(shù)據(jù)庫(kù)優(yōu)化可以從哪些維度入手?
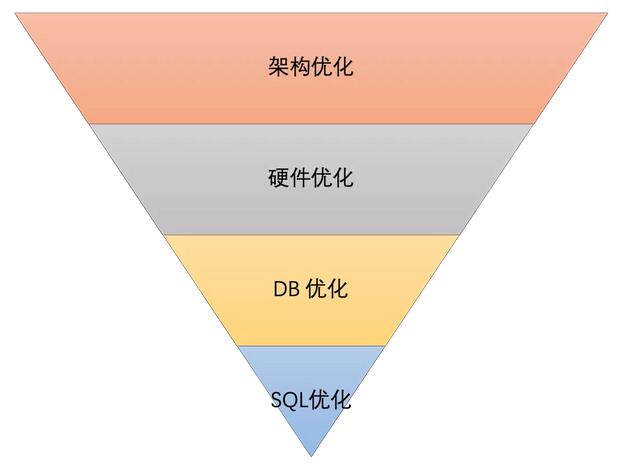
正如上圖所示,數(shù)據(jù)庫(kù)優(yōu)化可以從架構(gòu)優(yōu)化,硬件優(yōu)化,DB優(yōu)化,SQL優(yōu)化四個(gè)維度入手。
此上而下,位置越靠前優(yōu)化越明顯,對(duì)數(shù)據(jù)庫(kù)的性能提升越高。我們常說(shuō)的SQL優(yōu)化反而是對(duì)性能提高最小的優(yōu)化。
接下來(lái)我們?cè)倏纯疵糠N優(yōu)化該如何實(shí)施。
一、架構(gòu)優(yōu)化
一般來(lái)說(shuō)在高并發(fā)的場(chǎng)景下對(duì)架構(gòu)層進(jìn)行優(yōu)化其效果最為明顯,常見(jiàn)的優(yōu)化手段有:分布式緩存,讀寫分離,分庫(kù)分表等,每種優(yōu)化手段又適用于不同的應(yīng)用場(chǎng)景。
1、分布式緩存
有句老話說(shuō)的好,性能不夠,緩存來(lái)湊。當(dāng)需要在架構(gòu)層進(jìn)行優(yōu)化時(shí)我們第一時(shí)間就會(huì)想到緩存這個(gè)神器,在應(yīng)用與數(shù)據(jù)庫(kù)之間增加一個(gè)緩存服務(wù),如Redis或Memcache。
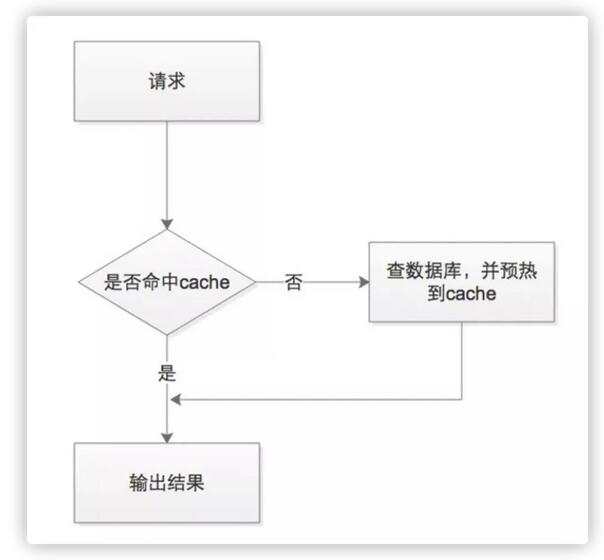
當(dāng)接收到查詢請(qǐng)求后,我們先查詢緩存,判斷緩存中是否有數(shù)據(jù),有數(shù)據(jù)就直接返回給應(yīng)用,如若沒(méi)有再查詢數(shù)據(jù)庫(kù),并加載到緩存中,這樣就大大減少了對(duì)數(shù)據(jù)庫(kù)的訪問(wèn)次數(shù),自然而然也提高了數(shù)據(jù)庫(kù)性能。
不過(guò)需要注意的是,引入分布式緩存后系統(tǒng)需要考慮如何應(yīng)對(duì)緩存穿透、緩存擊穿和緩存雪崩的問(wèn)題。
簡(jiǎn)單理解一下 緩存穿透、緩存擊穿 和 緩存雪崩
- 緩存穿透:它是指當(dāng)用戶在查詢一條數(shù)據(jù)的時(shí)候,而此時(shí)數(shù)據(jù)庫(kù)和緩存都沒(méi)有關(guān)于這條數(shù)據(jù)的任何記錄。這條數(shù)據(jù)在緩存中沒(méi)找到就會(huì)向數(shù)據(jù)庫(kù)請(qǐng)求獲取數(shù)據(jù)。它拿不到數(shù)據(jù)時(shí),是會(huì)一直查詢數(shù)據(jù)庫(kù),這樣會(huì)對(duì)數(shù)據(jù)庫(kù)的訪問(wèn)造成很大的壓力。
- 緩存擊穿:一個(gè)熱點(diǎn)key剛好在某個(gè)時(shí)間點(diǎn)失效了,但是這時(shí)候突然來(lái)了大量對(duì)這個(gè)key的并發(fā)訪問(wèn)請(qǐng)求,導(dǎo)致大并發(fā)請(qǐng)求直接穿透緩存直達(dá)數(shù)據(jù)庫(kù),瞬間對(duì)數(shù)據(jù)庫(kù)的訪問(wèn)壓力增大。
- 緩存雪崩:某一個(gè)時(shí)間段內(nèi),緩存集中過(guò)期失效,如果這個(gè)時(shí)間段內(nèi)有大量請(qǐng)求,而查詢數(shù)據(jù)量巨大,所有的請(qǐng)求都會(huì)達(dá)到存儲(chǔ)層,存儲(chǔ)層的調(diào)用量會(huì)暴增,引起數(shù)據(jù)庫(kù)壓力過(guò)大甚至宕機(jī)。
2、讀寫分離
一主多從,讀寫分離,主動(dòng)同步,是一種常見(jiàn)的數(shù)據(jù)庫(kù)架構(gòu)優(yōu)化手段。
一般來(lái)說(shuō)當(dāng)你的應(yīng)用是讀多寫少,數(shù)據(jù)庫(kù)扛不住讀壓力的時(shí)候,采用讀寫分離,通過(guò)增加從庫(kù)數(shù)量可以線性提升系統(tǒng)讀性能。
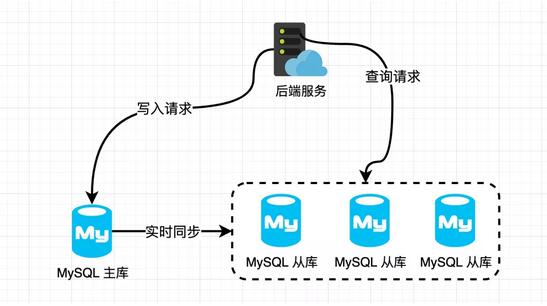
主庫(kù),提供數(shù)據(jù)庫(kù)寫服務(wù);從庫(kù),提供數(shù)據(jù)庫(kù)讀能力;主從之間,通過(guò)binlog同步數(shù)據(jù)。
當(dāng)準(zhǔn)備實(shí)施讀寫分離時(shí),為了保證高可用,需要實(shí)現(xiàn)故障的自動(dòng)轉(zhuǎn)移,主從架構(gòu)會(huì)有潛在主從不一致性問(wèn)題。
3、水平切分
水平切分,也是一種常見(jiàn)的數(shù)據(jù)庫(kù)架構(gòu)優(yōu)化手段。
當(dāng)你的應(yīng)用業(yè)務(wù)數(shù)據(jù)量很大,單庫(kù)容量成為性能瓶頸后,采用水平切分,可以降低數(shù)據(jù)庫(kù)單庫(kù)容量,提升數(shù)據(jù)庫(kù)寫性能。
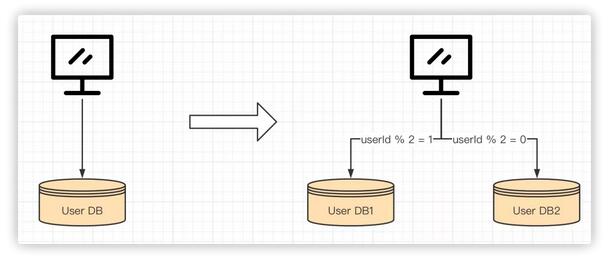
當(dāng)準(zhǔn)備實(shí)施水平切分時(shí),需要結(jié)合實(shí)際業(yè)務(wù)選取合理的分片鍵(sharding-key),有時(shí)候?yàn)榱私鉀Q非分片鍵查詢問(wèn)題還需要將數(shù)據(jù)寫到單獨(dú)的查詢組件,如ElasticSearch。
4、架構(gòu)優(yōu)化小結(jié)
- 讀寫分離主要是用于解決 “數(shù)據(jù)庫(kù)讀性能問(wèn)題”
- 水平切分主要是用于解決“數(shù)據(jù)庫(kù)數(shù)據(jù)量大的問(wèn)題”
- 分布式緩存架構(gòu)可能比讀寫分離更適用于高并發(fā)、大數(shù)據(jù)量大場(chǎng)景。
二、硬件優(yōu)化
我們使用數(shù)據(jù)庫(kù),不管是讀操作還是寫操作,最終都是要訪問(wèn)磁盤,所以說(shuō)磁盤的性能決定了數(shù)據(jù)庫(kù)的性能。一塊PCIE固態(tài)硬盤的性能是普通機(jī)械硬盤的幾十倍不止。這里我們可以從吞吐率、IOPS兩個(gè)維度看一下機(jī)械硬盤、普通固態(tài)硬盤、PCIE固態(tài)硬盤之間的性能指標(biāo)。
- 吞吐率:?jiǎn)挝粫r(shí)間內(nèi)讀寫的數(shù)據(jù)量
- 機(jī)械硬盤:約100MB/s ~ 200MB/s
- 普通固態(tài)硬盤:200MB/s ~ 500MB/s
- PCIE固態(tài)硬盤:900MB/s ~ 3GB/s
- IOPS:每秒IO操作的次數(shù)
- 機(jī)械硬盤:100 ~200
- 普通固態(tài)硬盤:30000 ~ 50000
- PCIE固態(tài)硬盤:數(shù)十萬(wàn)
通過(guò)上面的數(shù)據(jù)可以很直觀的看到不同規(guī)格的硬盤之間的性能差距非常大,當(dāng)然性能更好的硬盤價(jià)格會(huì)更貴,在資金充足并且迫切需要提升數(shù)據(jù)庫(kù)性能時(shí),嘗試更換一下數(shù)據(jù)庫(kù)的硬盤不失為一個(gè)非常好的舉措,你之前遇到SQL執(zhí)行緩慢問(wèn)題在你更換硬盤后很可能將不再是問(wèn)題。
三、DB優(yōu)化
SQL執(zhí)行慢有時(shí)候不一定完全是SQL問(wèn)題,手動(dòng)安裝一臺(tái)數(shù)據(jù)庫(kù)而不做任何參數(shù)調(diào)整,再怎么優(yōu)化SQL都無(wú)法讓其性能最大化。要讓一臺(tái)數(shù)據(jù)庫(kù)實(shí)例完全發(fā)揮其性能,首先我們就得先優(yōu)化數(shù)據(jù)庫(kù)的實(shí)例參數(shù)。
數(shù)據(jù)庫(kù)實(shí)例參數(shù)優(yōu)化遵循三句口訣:日志不能小、緩存足夠大、連接要夠用。
數(shù)據(jù)庫(kù)事務(wù)提交后需要將事務(wù)對(duì)數(shù)據(jù)頁(yè)的修改刷( fsync)到磁盤上,才能保證數(shù)據(jù)的持久性。這個(gè)刷盤,是一個(gè)隨機(jī)寫,性能較低,如果每次事務(wù)提交都要刷盤,會(huì)極大影響數(shù)據(jù)庫(kù)的性能。數(shù)據(jù)庫(kù)在架構(gòu)設(shè)計(jì)中都會(huì)采用如下兩個(gè)優(yōu)化手法:
- 先將事務(wù)寫到日志文件RedoLog(WAL),將隨機(jī)寫優(yōu)化成順序?qū)?/li>
- 加一層緩存結(jié)構(gòu)Buffer,將單次寫優(yōu)化成順序?qū)?/li>
所以日志跟緩存對(duì)數(shù)據(jù)庫(kù)實(shí)例尤其重要。而連接如果不夠用,數(shù)據(jù)庫(kù)會(huì)直接拋出異常,系統(tǒng)無(wú)法訪問(wèn)。
接下來(lái)我們以O(shè)racle、MySQL(InnoDB)、POSTGRES、達(dá)夢(mèng)為例,看看每種數(shù)據(jù)庫(kù)的參數(shù)該如何配置。
1、Oracle
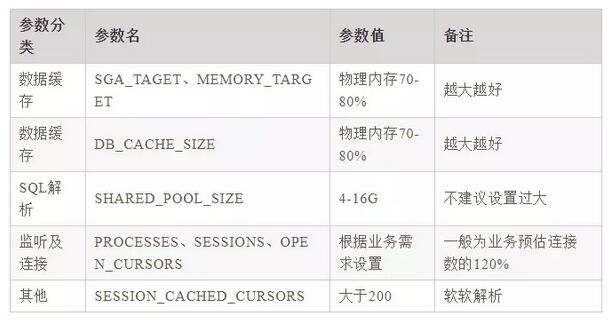
2、MySQL
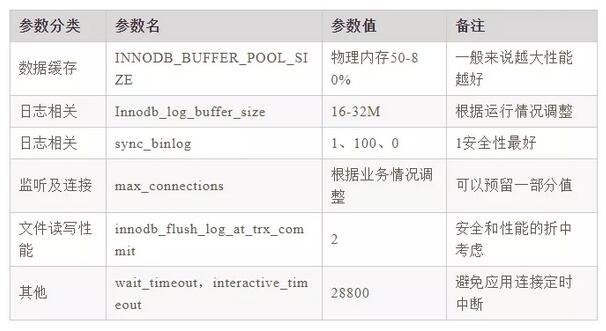
3、POSTGRES

4、達(dá)夢(mèng)數(shù)據(jù)庫(kù)
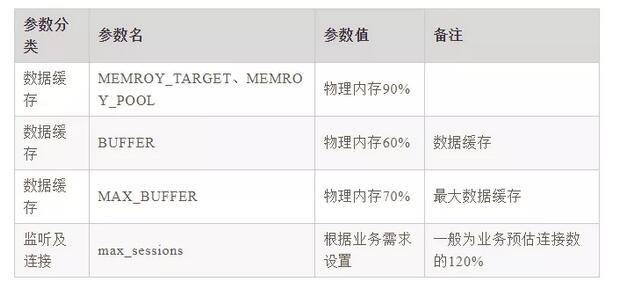
四、SQL優(yōu)化
SQL優(yōu)化很容易理解,就是通過(guò)給查詢字段添加索引或者改寫SQL提高其執(zhí)行效率,一般而言,SQL編寫有以下幾個(gè)通用的技巧:
1)合理使用索引
索引少了查詢慢;索引多了占用空間大,執(zhí)行增刪改語(yǔ)句的時(shí)候需要?jiǎng)討B(tài)維護(hù)索引,影響性能 選擇率高(重復(fù)值少)且被where頻繁引用需要建立B樹(shù)索引;一般join列需要建立索引;復(fù)雜文檔類型查詢采用全文索引效率更好;索引的建立要在查詢和DML性能之間取得平衡;復(fù)合索引創(chuàng)建時(shí)要注意基于非前導(dǎo)列查詢的情況
2)使用UNION ALL替代UNION
UNION ALL的執(zhí)行效率比UNION高,UNION執(zhí)行時(shí)需要排重;UNION需要對(duì)數(shù)據(jù)進(jìn)行排序
3)避免select * 寫法
執(zhí)行SQL時(shí)優(yōu)化器需要將 * 轉(zhuǎn)成具體的列;每次查詢都要回表,不能走覆蓋索引。
4)JOIN字段建議建立索引
- 一般JOIN字段都提前加上索引
5)避免復(fù)雜SQL語(yǔ)句
- 提升可閱讀性;避免慢查詢的概率;可以轉(zhuǎn)換成多個(gè)短查詢,用業(yè)務(wù)端處理
6)避免where 1=1寫法
7)避免order by rand()類似寫法
- RAND()導(dǎo)致數(shù)據(jù)列被多次掃描
1、執(zhí)行計(jì)劃
要想優(yōu)化SQL必須要會(huì)看執(zhí)行計(jì)劃,執(zhí)行計(jì)劃會(huì)告訴你哪些地方效率低,哪里可以需要優(yōu)化。我們以MYSQL為例,來(lái)認(rèn)識(shí)一下執(zhí)行計(jì)劃。
通過(guò)explain sql 可以查看執(zhí)行計(jì)劃,如:


2、SQL優(yōu)化實(shí)戰(zhàn)
這里為大家準(zhǔn)備了一套SQL優(yōu)化的綜合實(shí)戰(zhàn),一步一步帶你走一遍完整SQL優(yōu)化的過(guò)程。
在執(zhí)行優(yōu)化之前我們需要先認(rèn)識(shí)一下原始表及待優(yōu)化的SQL。
1)原數(shù)據(jù)庫(kù)表結(jié)構(gòu)
- CREATE TABLE `a`
- (
- `id` int(11) NOT NULL AUTO_INCREMENT,
- `seller_id` bigint(20) DEFAULT NULL,
- `seller_name` varchar(100) CHARACTER SET utf8 COLLATE utf8_bin DEFAULT NULL,
- `gmt_create` varchar(30) DEFAULT NULL,
- PRIMARY KEY (`id`)
- );
- CREATE TABLE `b`
- (
- `id` int(11) NOT NULL AUTO_INCREMENT,
- `seller_name` varchar(100) DEFAULT NULL,
- `user_id` varchar(50) DEFAULT NULL,
- `user_name` varchar(100) DEFAULT NULL,
- `sales` bigint(20) DEFAULT NULL,
- `gmt_create` varchar(30) DEFAULT NULL,
- PRIMARY KEY (`id`)
- );
- CREATE TABLE `c`
- (
- `id` int(11) NOT NULL AUTO_INCREMENT,
- `user_id` varchar(50) DEFAULT NULL,
- `order_id` varchar(100) DEFAULT NULL,
- `state` bigint(20) DEFAULT NULL,
- `gmt_create` varchar(30) DEFAULT NULL,
- PRIMARY KEY (`id`)
- );
2)待優(yōu)化的SQL(查詢當(dāng)前用戶在當(dāng)前時(shí)間前后10個(gè)小時(shí)的訂單情況,并根據(jù)訂單創(chuàng)建時(shí)間升序排列)
- select a.seller_id,
- a.seller_name,
- b.user_name,
- c.state
- from a,
- b,
- c
- where a.seller_name = b.seller_name
- and b.user_id = c.user_id
- and c.user_id = 17
- and a.gmt_create
- BETWEEN DATE_ADD(NOW(), INTERVAL – 600 MINUTE)
- AND DATE_ADD(NOW(), INTERVAL 600 MINUTE)
- order by a.gmt_create;
3)原表數(shù)據(jù)量:

4)原執(zhí)行時(shí)間
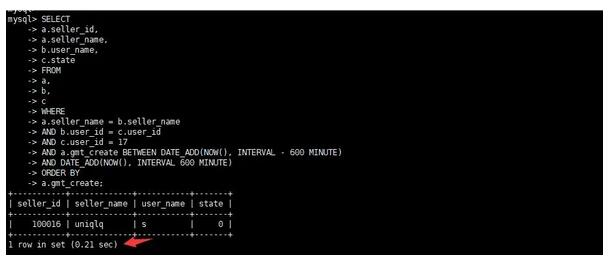
0.21s,執(zhí)行速度還挺快
5)原執(zhí)行計(jì)劃
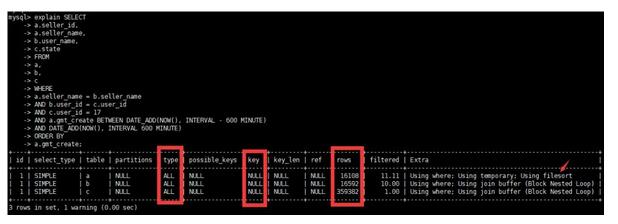
真是糟糕的執(zhí)行計(jì)劃。(全表掃描,沒(méi)有索引;臨時(shí)表;排序)
①初步優(yōu)化思路:
- SQL中 where條件字段類型要跟表結(jié)構(gòu)一致,表中user_id 為varchar(50)類型,實(shí)際SQL用的int類型,存在隱式轉(zhuǎn)換,也未添加索引。將b和c表user_id 字段改成int類型。
- 因存在b表和c表關(guān)聯(lián),將b和c表user_id創(chuàng)建索引
- 因存在a表和b表關(guān)聯(lián),將a和b表seller_name字段創(chuàng)建索引
- 利用復(fù)合索引消除臨時(shí)表和排序
②初步優(yōu)化SQL
- alter table b modify `user_id` int(10) DEFAULT NULL;
- alter table c modify `user_id` int(10) DEFAULT NULL;
- alter table c add index `idx_user_id`(`user_id`);
- alter table b add index `idx_user_id_sell_name`(`user_id`,`seller_name`);
- alter table a add index `idx_sellname_gmt_sellid`(`gmt_create`,`seller_name`,`seller_id`);
③查看優(yōu)化后的執(zhí)行時(shí)間
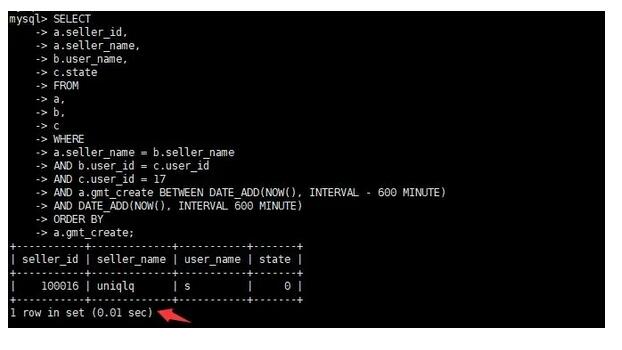
通過(guò)執(zhí)行計(jì)劃可以看到,執(zhí)行時(shí)間從0.21s優(yōu)化成了0.01s,執(zhí)行時(shí)間近乎縮短20倍。
④查看優(yōu)化后的執(zhí)行計(jì)劃
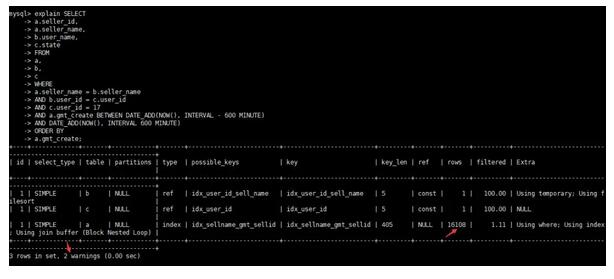
執(zhí)行計(jì)劃顯示從全表掃描優(yōu)化成了走索引,rows減少,但是此時(shí)出現(xiàn)了2個(gè)告警。
⑤通過(guò)show warning語(yǔ)句 查看告警信息
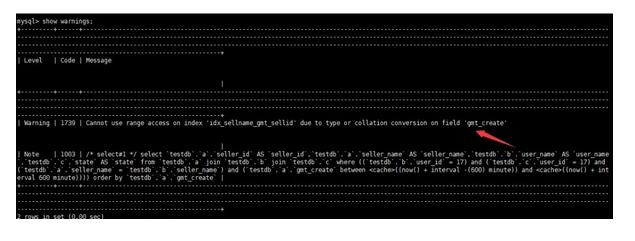
提示gmt_crteate 的格式不對(duì),mysql進(jìn)行了隱式轉(zhuǎn)換導(dǎo)致不能使用索引。
⑥繼續(xù)優(yōu)化,修改gmtc-create的格式
- alter table a modify "gmt_create" datetime DEFAULT NULL;
⑦再次查看執(zhí)行時(shí)間
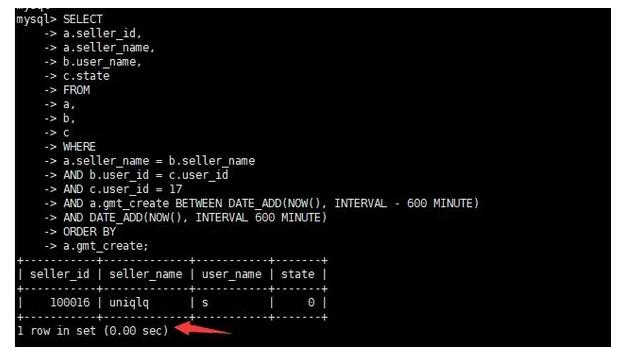
⑧再次查看執(zhí)行計(jì)劃
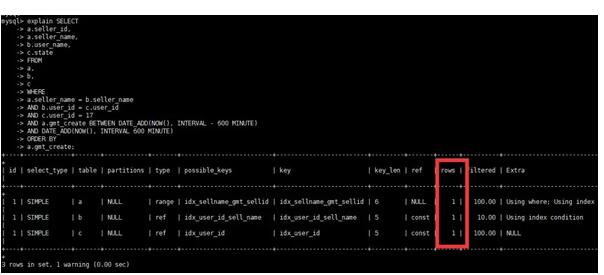
至此,我們的優(yōu)化過(guò)程結(jié)束,結(jié)果非常完美。
3、SQL優(yōu)化小結(jié)
這里給大家總結(jié)一下SQL優(yōu)化的套路:
- 查看執(zhí)行計(jì)劃 explain sql
- 如果有告警信息,查看告警信息 show warnings;
- 查看SQL涉及的表結(jié)構(gòu)和索引信息
- 根據(jù)執(zhí)行計(jì)劃,思考可能的優(yōu)化點(diǎn)
- 按照可能的優(yōu)化點(diǎn)執(zhí)行表結(jié)構(gòu)變更、增加索引、SQL改寫等操作
- 查看優(yōu)化后的執(zhí)行時(shí)間和執(zhí)行計(jì)劃
- 如果優(yōu)化效果不明顯,重復(fù)第四步操作
小結(jié)
我們今天分別從架構(gòu)優(yōu)化、硬件優(yōu)化、DB優(yōu)化、SQL優(yōu)化四個(gè)角度探討了如何實(shí)施優(yōu)化,提升數(shù)據(jù)庫(kù)性能。但是大家還是要記住一句話,數(shù)據(jù)庫(kù)系統(tǒng)沒(méi)有銀彈, 要讓適合的系統(tǒng),做合適的事情。













