實戰(zhàn) Cnn 卷積神經(jīng)網(wǎng)絡(luò)識別驗證碼,準確率99.5%
一、背景介紹
這是一個運行了2年的個人小項目,最近目標網(wǎng)站改為掃碼登錄,于是公布出來作為技術(shù)分享。項目緣起是女神參與的簽到活動,堅持了很久,后來嫌麻煩,中途放棄又覺得可惜,問我能不能實現(xiàn)程序自動登錄+簽到。我打開某網(wǎng)站看了下,python+selenium就可以實現(xiàn),但人家要的是全自動,這就需要把驗證碼自動識別的難點攻克掉了。懶永遠是技術(shù)進步的源動力啊,不過我對機器視覺本身也比較感興趣,那些年小區(qū)和單位的門口都是車牌識別了,也想借此機會探究一下這門技術(shù)是怎么回事。
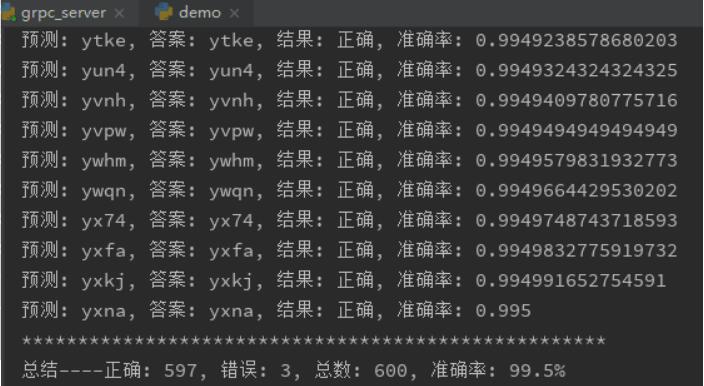
先上兩張鎮(zhèn)樓圖,一張是準確率統(tǒng)計,一張是實戰(zhàn)截圖。其中動圖只進行了驗證碼識別,沒有登錄操作,僅用于效果展示。本文不會對技術(shù)細節(jié)及理論原理做太多介紹,只是展示一下聽起來高大上的人工智能+機器學(xué)習+計算機視覺,個人也有很多場景可以把玩的。如果對這個效果感興趣,可以接著往下看看:
二、分析驗證碼:
某網(wǎng)站的驗證碼還是挺復(fù)雜的,有四套模版,有的加了干擾線,有的是用點陣構(gòu)建字母,有的進行的各種扭曲,還渲染上了七彩色。
先去網(wǎng)上看看有沒有現(xiàn)成的輪子,方法很多,簡單的方法能實現(xiàn),就不用麻煩的。
1、先試試谷歌的tesseract、pytesser3,都是一回事,代碼極其簡潔,兩三行就出結(jié)果,勉強可以接受吧,規(guī)規(guī)矩矩的字,識別率還挺高,但稍加變形,結(jié)果就驢唇不對馬嘴。
2、本著一切從簡的原則,還是打算依賴pytesser3,給它喂適合的數(shù)據(jù),把驗證碼轉(zhuǎn)灰度圖、二值化、濾波降噪、模糊各種手段組合著用,還測試了4位驗證碼切割成4張小圖片,以單字符識別的形式提高它的準確率。不過不論你用什么手段往它身上招呼,識別效果都差得遠著呢。
3、只有祭出終極大招了,機器深度學(xué)習+卷積神經(jīng)網(wǎng)絡(luò),在入這個坑之前,做了好久好久的心理建設(shè),cnn這么大的坑我爬得出來嘛?經(jīng)過了一個多星期的學(xué)習,跑出了鎮(zhèn)樓圖的效果,也穩(wěn)定運行2年時間,可以簡單分享一下大致調(diào)試過程了。
三、開發(fā)調(diào)試流程
cnn模型訓(xùn)練需要有訓(xùn)練集和測試集,這兩個數(shù)據(jù)集,計算機需要知道答案,那么知道答案的數(shù)據(jù)怎么來?
1、先寫個腳本,采集了200份目標網(wǎng)站的驗證碼,人工打上標簽,把答案作為驗證碼圖片的文件名前4個字符。
2、人肉打標效率太低。花錢打標?不至于吧,自己寫個小程序簽到玩,還要投資?那就自己生成一批吧。觀察目標網(wǎng)站的驗證碼,扭曲、模糊、加線的手法挺像谷歌開源驗證碼開發(fā)包的,下一個回來,模擬一下。包是java的,在eclipse里略做改動,一頓午飯的時間就生成了50萬張帶答案的驗證碼。類似這樣,文件名前4個字符就是答案。
3、訓(xùn)練集有了,下面搭建訓(xùn)練和部署環(huán)境,基于簡便和通用性考慮,這次驗證碼圖片不再切割,整體丟給機器去訓(xùn)練。
四、驗證效果
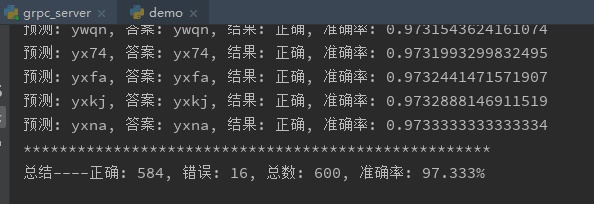
到了收獲的時候。程序調(diào)好,臨近下班,把訓(xùn)練集和測試集丟給程序,6W數(shù)據(jù)CPU要跑一晚上,GPU只用20分鐘。我這50W數(shù)據(jù),GPU半個晚上也就訓(xùn)練完了。下面是第二天早上,實驗環(huán)境下的數(shù)據(jù),實驗環(huán)境是指:訓(xùn)練集,測試集,考試集都是用同一套系統(tǒng)生成的。準確率達到97.3%。
那么在實際環(huán)境中,效果如何呢?實際環(huán)境是指訓(xùn)練集,測試集是通過自己寫的代碼生成的。而考試集是從目標網(wǎng)站采集回來并人工標識的。
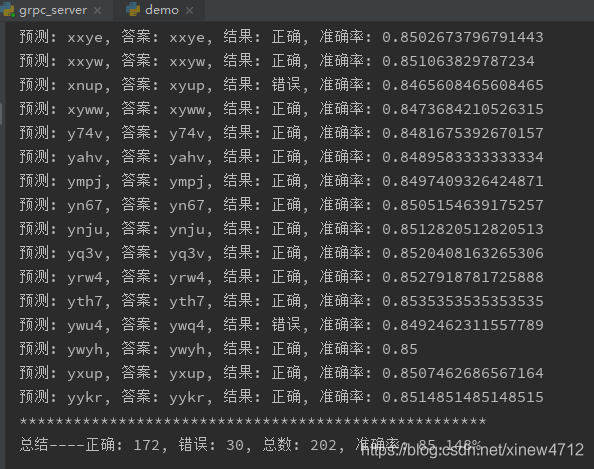
真實環(huán)境才85%,有點低了對不對?把錯誤的地方都找出來查找一下原因:
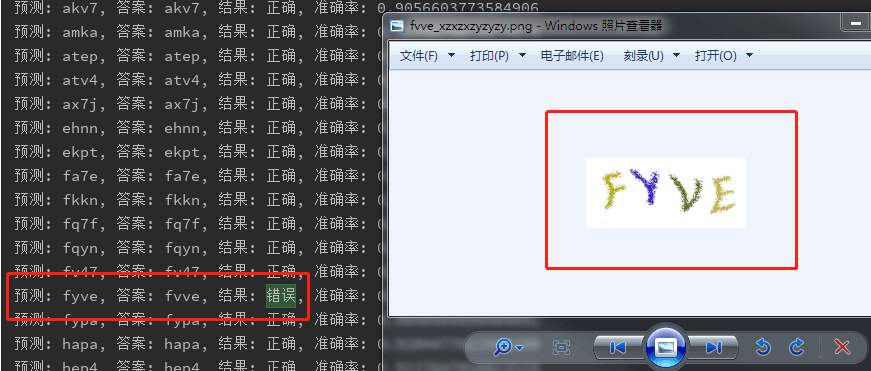
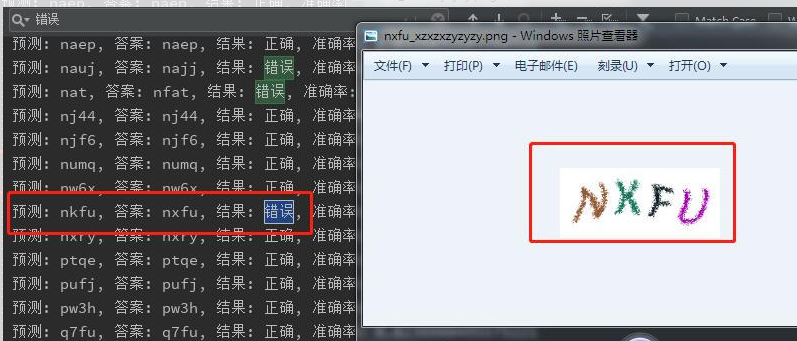
類似這樣的錯誤,是我識別錯了,機器給我指出了答案的不正確,讓我自愧不如啊。不過這感覺挺美妙的。
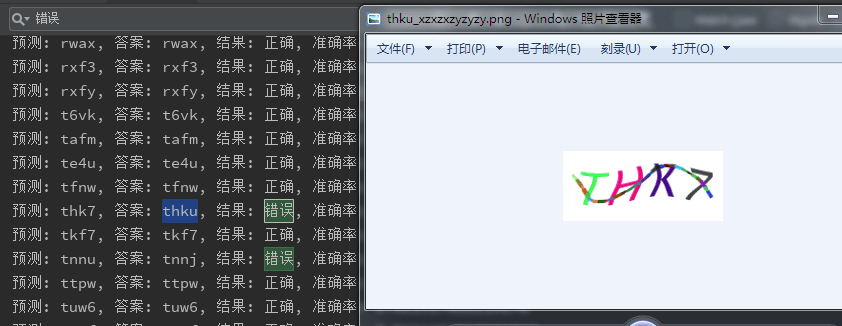
還有這種的,這么明顯,怎么可能人肉識別錯呢,后來一看鍵盤,7和U離得太近,一定手滑了。排除這些人工標識出錯,真實環(huán)境的準確率達到90%。基本能符合自動登錄的要求了。
五、如何提高準確率
后來我進一步思考,還有沒有什么辦法可以讓準確率更高一些呢?實驗環(huán)境和真實環(huán)境差在哪里,有7%的差距呢?目標網(wǎng)站一定是有哪些微調(diào)我沒有觀察到。比如這張:
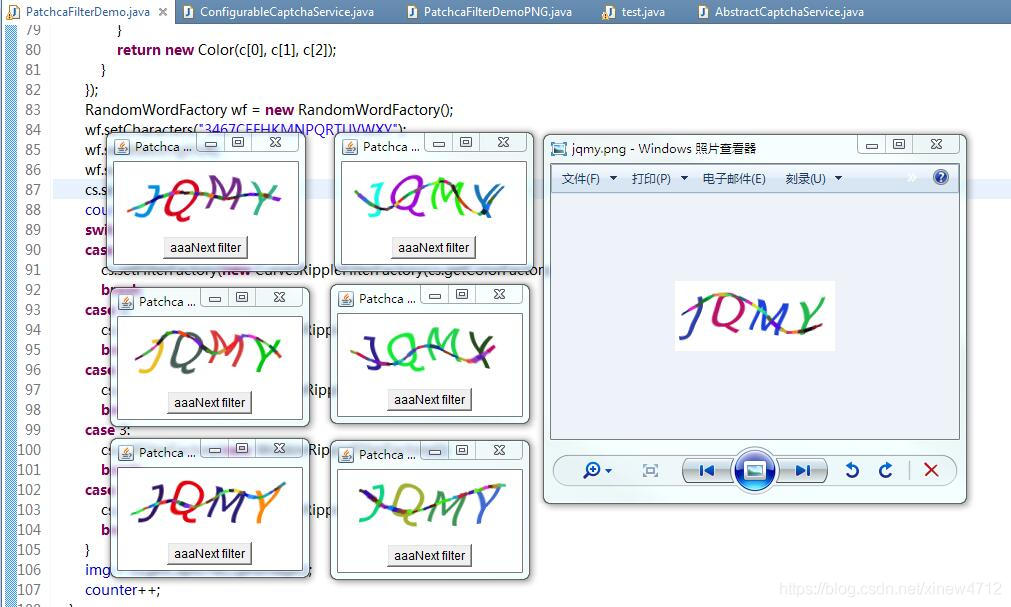
左邊六張圖是模擬生成的驗證碼,右邊一張圖是人肉從目標網(wǎng)站上打來的碼。肉眼看上去很像,字體上似乎有微小的差別,導(dǎo)致了實驗環(huán)境與真實環(huán)境7%的準確率誤差,要解決這個問題,有兩個辦法:
1、人肉打出足夠多的碼,以此為測試集,重新訓(xùn)練。效果應(yīng)該不錯,可是缺點也顯而易見,哪有那么多功夫去人肉打碼。或者有時間,就是懶,你要用技術(shù)去解決啊。這么一說,好像也有辦法,Apple 的AI首秀就是治這種懶的,見辦法2。
2、關(guān)鍵字:simgan。認真研究了相關(guān)的2篇論文,覺得有搞頭啊,決定試一下。
六、提高準確率的進階實驗
又經(jīng)過十幾天的實驗(訓(xùn)練一次太久了),對simgan原理有了更深的了解,SimGAN-Captcha的實驗也完全復(fù)現(xiàn),然后對其進行擴展,應(yīng)用到自己的環(huán)境中進行樣本增強,實驗過程按這樣的思路:
首先復(fù)現(xiàn)SimGAN-Captcha過程。然后改灰度圖為RGB,通過無標識的真實數(shù)據(jù)和有標識的模擬數(shù)據(jù),訓(xùn)練SimGAN-Captcha,通過訓(xùn)練好的模型,Refine上面提到的50萬+1萬模擬的訓(xùn)練數(shù)據(jù),通過Refined的數(shù)據(jù),重新訓(xùn)練驗證碼識別模型,統(tǒng)計準確率做對比。可是效果并不好,甚至肉眼放大也無法在像素層面上找到差異,可以說模擬的很逼真,也可以說Refine沒效果。甚至讓人懷疑,SimGAN-Captcha是否工作了。于是用另一套驗證碼生成器生成完全不相同的驗證碼,讓SimGAN-Captcha在像素層面對新驗證碼進行強化,用以證明Refine確實是干活了。
經(jīng)過了50多小時的訓(xùn)練,SimGAN-Captcha有了明顯的增強效果,舉個例子:
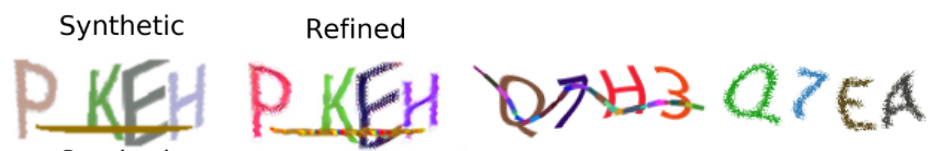
為了方便表述,從左到右我們依次叫它們1號、2號、3號、4號。1號是用完全不同的算法X生成的驗證碼,灰頭土臉的。3號、4號是上文提到的目標網(wǎng)站的真實的不同形式的驗證碼。以算法X生成的類1號驗證碼為Synthetic數(shù)據(jù)集,以類似3號、類似4號驗證碼為real數(shù)據(jù)集,refine出來的合成驗證碼為2號。仔細觀察2號,已經(jīng)有了很多3、4號的特征,比如:1、不再灰頭土臉,變得鮮艷了,P,K,H色彩對比都比較明顯;2、干擾線有了彩色斷點,這個特征很好的模擬了類3號樣本;3、字母P與E有了類4號的點陣效果,模擬點陣應(yīng)該是SimGAN的拿手好戲,如果讓它把干擾線變扭曲就難為它了。
看來SimGAN的確有效果,它能在像素層面上,把模擬樣本盡量向著真實樣本的方向改造,不過,即使改造的“像一些”了,好像對準確率的提高也沒多大幫助。用谷歌的captcha生成的驗證碼做Synthetic數(shù)據(jù)集,目標網(wǎng)站驗證碼做real數(shù)據(jù)集,進行訓(xùn)練,然后用這樣的模型生成cnn的訓(xùn)練集與測試集,再對目標網(wǎng)站的驗證碼進行測試,準確率提高不到0.5%。用上面提到的算法X生成的驗證碼做Synthetic數(shù)據(jù)集,目標網(wǎng)站驗證碼做real數(shù)據(jù)集進行訓(xùn)練,然后用這樣的模型生成cnn的訓(xùn)練集與測試集訓(xùn)練cnn,與直接用X算法生成的訓(xùn)練集與測試訓(xùn)練出的cnn模型,在正確率的對比上,只提高0.1%。把上面的過程用語言描述出來,都已經(jīng)很繞了,實際訓(xùn)練時,盡量安排在晚上或周末,累計在訓(xùn)練上花了4、5百小時,花了這么大的時間成本,取得這么小的進步,確有不值。而當我走了一大圈,回到起點,試著把cnn的訓(xùn)練加強,對它提高要求,不以準確率達到99%為中止條件,要準確率達到200%才停止訓(xùn)練(類似while 1 循環(huán)),只用了一頓午飯的時間,準確率就有了2.2%的提升。用同樣的600份實驗數(shù)據(jù)做對比,上篇文章中準確率是97.33%,這次提高到99.5%,如鎮(zhèn)樓圖。對于驗證碼識別來說,在正確的道路上努力訓(xùn)練才是王道,SimGAN并沒有那么好的效果。
SimGAN應(yīng)該是有自己擅長的領(lǐng)域的,驗證碼增強不行,圖像增強會不會效果不錯?前文提到的蘋果AI首秀的那篇論文,對眼球控制的圖像進行樣本增強,似乎效果顯著啊,我也完成了復(fù)現(xiàn),效果非常好,有機會再分享吧。