Flink on K8s 在京東的持續優化實踐
一、基本介紹

K8s 是目前業內非常流行的容器編排和管理平臺,它可以非常簡單高效地管理云平臺中多個主機上的容器化應用。在 2017 年左右,我們實時計算是多個引擎并存的,包括 Storm、Spark Streaming 以及正在引入的新一代計算引擎 Flink,其中 Storm 集群運行在物理機上,Spark Streaming 運行在 YARN 上,不同的運行環境導致部署和運營成本特別高,且資源利用有一定浪費,所以迫切需要一個統一的集群資源管理和調度系統來解決這個問題。
而 K8s 可以很好地解決這些問題:它可以很方便地管理成千上萬的容器化應用,易于部署和運維;很容易做到混合部署,將不同負載的服務比如在線服務、機器學習、流批計算等混合在一起,獲得更好的資源利用;此外,它還具有天然容器隔離、原生彈性自愈的能力,可以提供更好的隔離性與安全性。
經過一系列的嘗試、優化和性能對比后,我們選擇了 K8s。
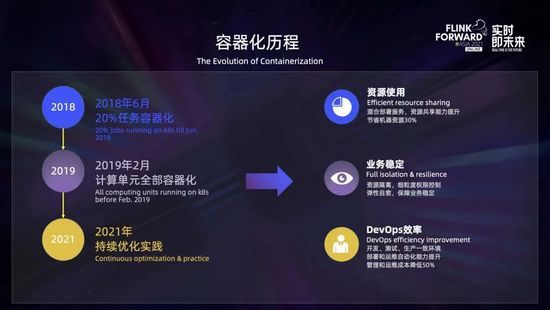
- 2018 年初,實時計算平臺開始全面容器化改造;
- 到 2018 年 6 月,已經有 20% 的任務運行在 K8s 上,從運行結果看,無論是資源的共享能力、還是業務處理能力,以及敏捷性和效率方面都獲得了較大提升,初步達到了預期的效果;
- 到 2019 年 2 月實現了實時計算全部容器化;
- 之后直到現在,我們在 K8s 的環境也一直在進行優化和實踐,比如進行彈性伸縮、服務混部、任務快速恢復能力建設等方面的實踐。
全部 on K8s 后收益還是比較明顯的:
- 首先混合部署服務和資源共享能力獲得了提升,節省機器資源 30%;
- 其次,具有更好的資源隔離和彈性自愈能力,比較容易實現根據業務的負載進行資源的彈性伸縮,保證了業務的穩定性;
- 最后開發、測試、生產一致性的環境,避免環境給整個開發過程帶來問題,同時極大提升了部署和運營自動化的能力,降低了管理運維的成本。

京東 Flink on K8s 的平臺架構如上圖,最下面是物理機和云主機,之上是 K8s,它采用京東自研的 JDOS 平臺,基于標準的 K8s 進行了許多定制優化,使之更適應我們生產環境的實際情況。JDOS 大部分運行在物理機上,少部分是在云主機上。再往上是基于社區版 Flink 進行深度定制化后的 Flink 引擎。
最上面就是京東的實時計算平臺 JRC,支持 SQL 作業和 jar 包作業,提供高吞吐、低延遲、高可用、彈性自愈易用的一站式海量流批數據計算能力,支持豐富的數據源和目標源,具備完善的作業管理、配置、部署、日志監控和自運維的功能,提供備份回滾和一鍵遷移的功能。
我們的實時計算平臺服務于京東內部非常多的業務線,主要應用場景包括實時數倉,實時大屏、實時推薦、實時報表、實時風控和實時監控以及其他的應用場景。目前我們的實時 K8s 集群由 7000 多臺機器組成,線上 Flink 任務數有 5000 多,數據處理峰值可以達到每秒 10 億多條。
二、生產實踐
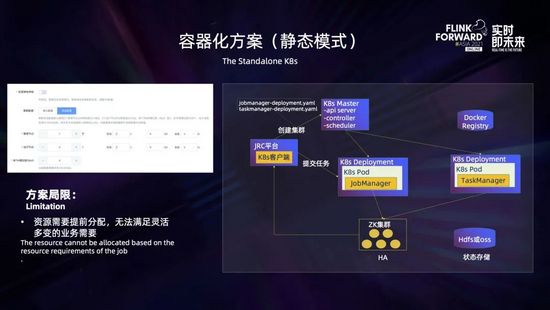
最開始容器化方案采用的是基于 K8s deployment 部署的 standalone session 集群,這是資源靜態分配的模式,如上圖所示,需要用戶在創建的時候就決定好所需要的管理節點 Jobmanager 的個數和規格 (包括 CPU 的核數、內存和磁盤的大小等)、運行節點 Taskmanager 的個數和規格 (包括 CPU、內存和磁盤大小等),以及 Taskmanager 包含的 slot 個數。創建集群后,JRC 平臺通過 K8s 客戶端向 K8s master 發出請求,創建 Jobmanager 的 deployment,這里使用 ZK 保證高可用,使用 HDFS 和 OSS 進行狀態存儲,集群創建完成后就可以提交任務了。
但是在我們實踐的過程中發現該方案存在一些不足,它需要業務提前預估出所需要的資源,對業務不太友好,無法滿足靈活多變的業務場景。比如對一些復雜拓撲或者一個集群跑多個任務的場景,業務很難預先精準確定出所需要資源,這時候一般都會先創建出一個較大的集群,這樣就會帶來一定的資源浪費。在任務運行的過程中,也沒有辦法根據任務的運行情況,按需進行資源的動態伸縮。
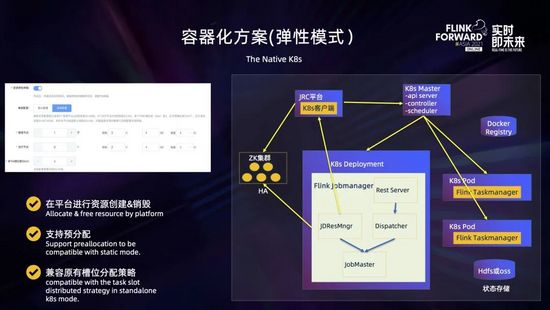
于是我們又對容器化方案進行了升級,支持彈性資源模式。這是采用資源按需分配的方式,如上圖所示,它需要用戶在創建時指定好所需要管理節點 Jobmanager 的個數和規格,以及運行節點 Taskmanager 的規格,而 Taskmanager 的個數可以不指定。點擊創建集群后,JRC 平臺會通過 K8s 客戶端向 K8s master 發出請求,創建 Jobmanager 的 deployment 以及可選地預創建指定數量 Taskmanager 的 pod。
平臺提交任務后,由 JobMaster 通過 JDResourceManager 向 JRC 平臺發出申請資源的 rest 請求,然后平臺向 K8s master 動態申請資源去創建運行 Taskmanager 的 pod,在運行過程中,如果發現某個 Taskmanager 長時間空閑,可以根據配置動態釋放資源。 這里通過平臺與 K8s 交互進行資源的創建和銷毀,主要是為了保證計算平臺對資源的管控,同時避免了集群配置和邏輯變化對鏡像的影響;通過支持用戶配置 Taskmanager 個數進行資源的預分配,可以做到與資源靜態分配同樣快速的任務提交速度;同時通過定制資源分配策略,可以做到兼容原有 slot 分散分布的均衡調度。
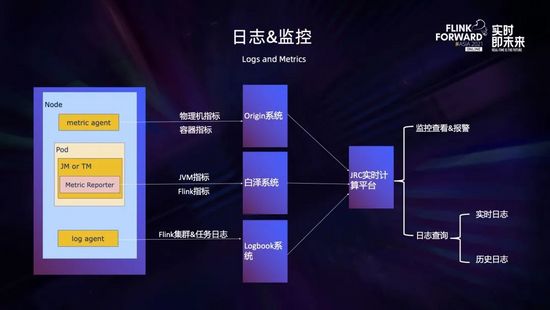
在 Flink on K8s 的環境中,日志和監控指標是非常重要的,它可以幫助我們觀察整個集群、容器、任務的運行情況,根據日志和監控快速定位問題并及時處理。
這里的監控指標包括物理機指標 (比如 CPU、內存、負載、網絡、連通性、磁盤等指標)、容器指標 (比如 CPU、內存、網絡等指標)、JVM 指標和 Flink 指標 (集群指標和任務指標)。其中物理機指標和容器指標是通過 metric agent 采集上報到 Origin 系統,JVM 指標和 Flink 指標是通過 Jobmanager 和 Taskmanager 中定制的 metric reporter 上報到白澤系統,之后統一在計算平臺進行監控的查看和告警。
日志采集采用京東的 Logbook 服務,它的基本機制是在每個 Node 上會運行一個 log agent,用于采集指定路徑的日志;然后 Jobmanager 或 Taskmanager 會按照指定規則輸出日志到指定目錄,之后日志就會被自動采集到 Logbook 系統;最后可以通過計算平臺進行實時日志和歷史日志的檢索和查詢。
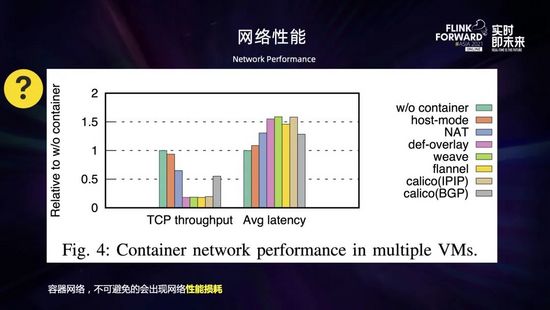
接下來是容器網絡的性能問題。一般來說虛擬化的東西都會帶來一定的性能損耗,容器網絡作為容器虛擬化的一個重要組件,相比物理機網絡來說,不可避免地會出現一些性能的損耗。性能的下降程度根據網絡插件的不同、協議類型和數據包的大小會有所不同。
如上圖所示,是對于跨主機容器網絡通信的性能測評。參考基線是 server 和 client 在同一主機上進行通信。從圖中可以看到,host 模式取得了接近參考基線的吞吐量和延遲,NAT 和 Calico 有較大的性能損失,這是由于地址轉換和網絡包路由的開銷導致的;而所有 overlay 網絡都有非常大的性能損失。總的來說,網絡包的封裝和解封相比地址轉換和路由來說開銷更大,那么采用何種網絡就需要做一個權衡。比如 overlay 網絡由于網絡包的封裝和解封導致了很大的開銷,性能會比較差,但允許更靈活和安全的網絡管理;NAT 和主機模式的網絡比較容易取得好的性能,但是安全性較差;Routing 網絡性能也不錯但需要額外的支持。
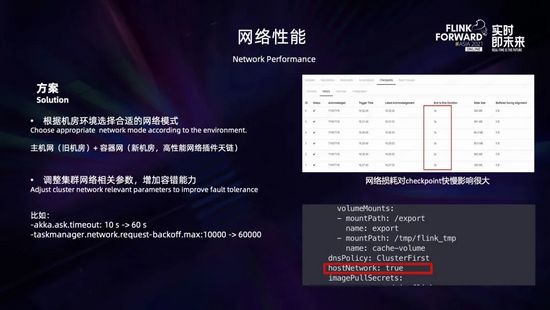
此外,網絡損耗對于 checkpoint 的快慢影響也很大。根據我們對比測試,網絡模式不同的情況下,同樣的環境下運行同樣的任務,采用容器網絡任務的 checkpoint 時長比使用主機網絡慢了一倍以上。那么怎么解決這個容器網絡的性能問題?
- 一是可以根據機房環境選擇合適的網絡模式:比如對于我們一些舊的機房,容器網絡性能下降特別明顯,而且網絡的架構也不能升級,采用了主機網絡 (如上圖所示,在 pod yaml 文件中配置 hostNetwork=true) 來避免損耗的問題,雖說這不太符合 K8s 的風格,但需要根據條件做個權衡;而對于新的機房,由于基礎網絡的性能提升以及采用了新的高性能網絡插件,性能損耗相比主機網非常小,就采用了容器網;
- 二是盡量不要使用異構網絡環境,避免 K8s 跨機房,同時適當調整集群網絡的相關參數,增加網絡的容錯能力。比如可以適當調大 akka.ask.timeout 和 taskmanager.network.request-backoff.max 兩個參數。

下面說一下磁盤的性能問題。容器中的存儲空間由兩部分組成,如上圖所示,底層是只讀的鏡像層,頂部是可讀寫的容器層。容器運行的時候涉及到文件的寫操作都是在容器層中完成的,這里需要一個存儲驅動提供聯合文件系統來管理。存儲驅動一般來說為空間效率進行了優化,額外的抽象會帶來一定的性能損耗 (取決于具體存儲驅動),寫入速度要低于本地文件系統,特別是使用了寫時復制的存儲驅動來說,損耗更大。這對于寫密集型的應用來說,會有更大的性能影響。而在 Flink 中,很多地方都涉及到本地磁盤的讀寫,比如日志輸出、RocksDB 讀寫、批任務 shuffle 等。那么該如何處理來減小影響?
- 一是可以考慮使用外掛的 Volume,使用本地存儲卷,直接寫數據到 host fileSystem 來提升性能;
- 此外也可以調優磁盤 IO 相關參數,比如調優 RocksDB 參數,提升磁盤的訪問性能;
- 最后也可以考慮采用一些存儲計算分離的方案,比如使用 remote shuffle,提升本地 shuffle 的性能和穩定性。
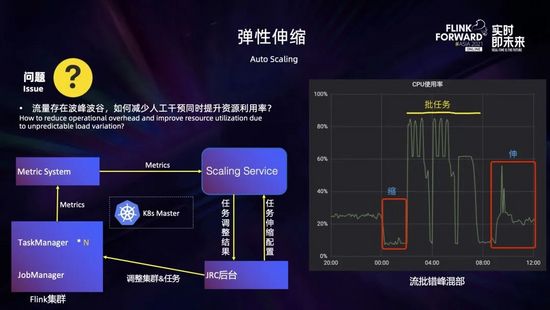
在實踐過程中經常會發現,很多業務的計算任務配置不合理,占用了過多的資源造成了資源浪費。此外,流量存在波峰波谷,如何在洪峰時自動擴容,在波谷時自動縮容,在減少人工干預、保證業務穩定的同時提高資源利用率,這都涉及到資源彈性伸縮的問題。為此我們開發了彈性伸縮的服務,根據作業運行情況動態調整任務的并行度以及 Taskmanager 的規格,來解決作業吞吐不足、資源浪費等問題。
如上圖所示,大致的工作流程如下:首先在 JRC 平臺進行任務的伸縮配置,主要包括運行度調整的上下限以及一些伸縮策略的閾值,這些配置都會發送到伸縮服務;伸縮服務運行過程中會實時監測集群和任務的運行指標 (主要是一些 CPU 的使用率和算子的繁忙程度等),結合伸縮配置和調整策略生成任務調整結果,發送到 JRC 平臺;最后 JRC 平臺根據調整結果,對集群和任務進行調整。
目前通過該伸縮服務,可以較好地解決一些場景的資源浪費問題,以及任務吞吐與算子并行度呈線性關系條件下的性能問題。不過它還是存在一定的局限性,比如對于外部的系統瓶頸、數據傾斜以及任務本身的性能瓶頸還有無法通過擴并行度提升的場景,不能很好地應對解決。
此外,結合彈性伸縮,我們也進行了一些實時流任務和離線批任務錯峰混部的嘗試。如上圖右所示,在凌晨前后,流任務比較空閑,會縮容釋放出一些資源給批任務;之后可以使用這些釋放的資源在夜間運行批任務;到了白天批任務運行完釋放的資源又可以還給流任務,用于擴容以應對流量洪峰,從而提高資源的整體利用率。
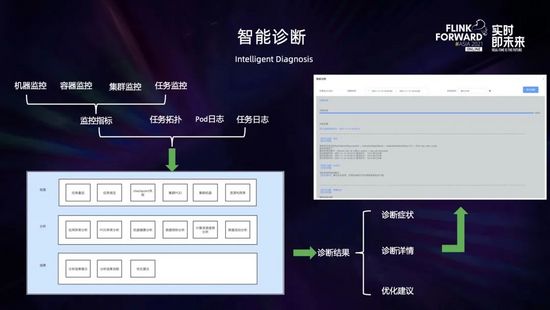
相比物理機或 YARN 環境,Flink on K8s 出現問題以后的排查相對要更困難,因為這里面還涉及到 K8s 許多組件,比如容器網絡、DNS 解析、K8s 調度等各方面的問題,都存在一定的門檻。
為了解決這個問題,我們開發了智能診斷的服務,將作業相關的各個維度的監控指標 (包括物理機的、容器的、集群的和任務的指標) 與任務拓撲結合起來并與 K8s 打通,結合 pod 日志和任務日志聯合進行分析,并將日常人工運維的一些方法進行歸納總結應用到分析策略中,診斷出作業的問題并給出優化建議。目前支持對任務重啟、任務背壓、checkpoint 失敗、集群資源利用率低等一些常見問題進行診斷,后續會持續豐富和完善。
三、優化改進
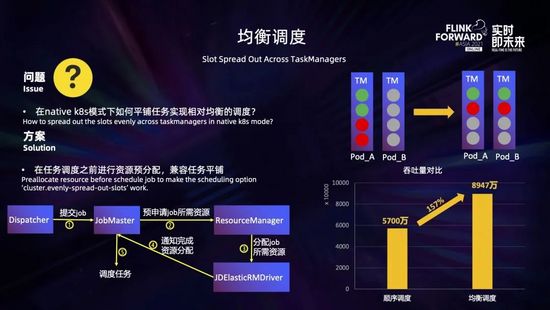
在實踐的過程中,采用資源靜態分配模式的時候,一般都會將 slot 按照 Taskmanager 打散,將耗費資源的算子按照 Taskmanager 分散開來,實現作業的均衡調度,提高作業的性能。
如右上圖所示有 2 個 Taskmanager,每個 Taskmanager 有 4 個 slot,1 個作業有 2 個算子 (分別用綠色和紅色表示),每個算子 2 個并行度。在使用默認調度策略 (順序調度) 的情況下,這個作業的所有算子都會集中在一個 Taskmanager;而如果使用均衡調度,這個作業的所有算子都會按照 Taskmanager 進行橫向打散,每個 Taskmanager 都會分到兩個算子的一個并行度 (綠色和紅色)。
而在采用資源動態分配模式 (native K8s) 的時候,資源是一個個 pod 單獨申請創建的,那么這個時候如何實現均衡調度呢?我們采用了在任務調度之前進行資源預分配的方式來解決這個問題。具體過程如下:用戶提交作業后,如果開啟了資源預分配,JobMaster 不會立即調度任務,而是會向 ResourceManager 一次性預申請作業所需的資源,在所需資源到位后,JobMaster 會得到通知,此時再調度任務就可以做到和靜態資源分配模式時同樣的均衡調度了。這里還可以給 JobMaster 配置一個超時時間,超時后就走正常任務調度流程,而不會無限地等待資源。
我們進行了真實場景的性能對比,如上圖右所示,使用順序調度的時候作業吞吐量為 5700 萬/分鐘,而開啟了資源預分配和均衡調度后,作業吞吐量為 8947 萬/分鐘,性能提升了 57%,還是有比較明顯的效果的。
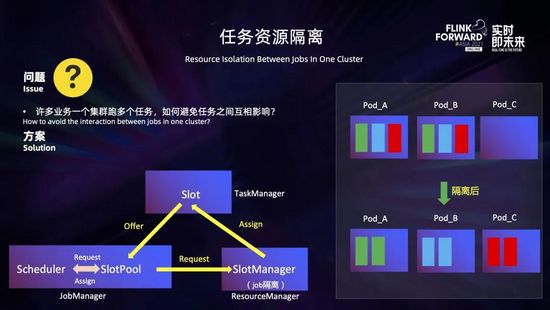
我們平臺有不少業務采用一個集群運行多個任務的模式,這樣就會存在一個 Taskmanager 分布了不同 job 的 Task,從而導致不同 job 之間相互影響。那么如何解決這個問題?
我們定制了 slot 的分配策略,在 Jobmanager 向 ResourceManager 請求 slot 時,如果開啟了任務資源隔離,SlotManager 會把已經分配 slot 的 Taskmanager 打上 job 的標簽,之后該 Taskmanager 的空閑 slot 只能用于該 job 的 slot 請求。通過將 Taskmanager 按照 job 分組,實現了集群多任務的資源隔離。
如上圖右所示,一個 Taskmanager 提供 3 個 slot,有 3 個 job,每個 job 有一個算子,且并行度都為 3 (分別用綠色、藍色和紅色表示)。開啟 slot 平鋪分散,在隔離前,這三個 job 會共享這三個 Taskmanager,每個 Taskmanager 上都分布了每個 job 的一個并行度。而在開啟任務資源隔離后,每一個 job 部將會獨占一個 Taskmanager,不會相互影響。
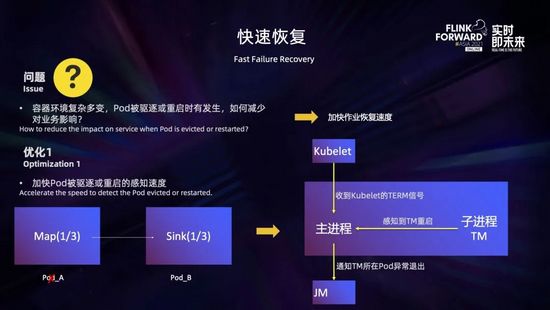
容器環境復雜多變,pod 被驅逐或重啟時有發生:比如機器發生硬件故障、docker 故障、節點負載較高等都會導致 pod 被驅逐;進程不健康、進程異常退出、docker 異常重啟等也都會導致 pod 重啟。此時,會導致任務重啟恢復,對業務造成影響。那么如何才能減少對業務的影響?
一個方面是針對容器環境,加快 pod 異常 (被驅逐或重啟) 的感知速度,迅速恢復作業。在官方的默認實現中,如果 pod 發生異常,可能會從兩個路徑感知到:一個是故障 pod 下游算子可能會感知到網絡連接的斷開,從而引發異常觸發 failover;一個是 Jobmanager 會首先感覺到 Taskmanager 心跳超時,此時也會觸發 failover。無論是通過哪個路徑,所需要的時長都會比超時要多一些,在我們默認系統配置下,所需的時間是 60 多秒。
這里我們優化了 pod 異常感知的速度。在 pod 異常被停止時,默認會有一個 30 秒的優雅停止的時間,此時容器主進程啟動腳本會收到來自 K8s 的 TERM 信號,除了做必要的清理動作之外,我們增加了通知 Jobmanager 異常 Taskmanager 的環節;在容器內工作進程 Taskmanager 異常退出的時候,主進程 (這里是啟動腳本) 也會感知到,也會通知 Jobmanager 是哪個 Taskmanager 發生了異常。這樣一來,Jobmanager 就可以在 pod 異常的時候第一時間得到通知,并及時進行作業的故障恢復。
通過這項優化,測試典型場景下,在集群有空余資源的情況下,任務 failover 的時長從原來的 60 多秒縮短到幾秒;在集群中沒有空余資源需要等待 pod 重建的情況下,任務 failover 的時長也縮短了 30 多秒,效果還是比較明顯的。
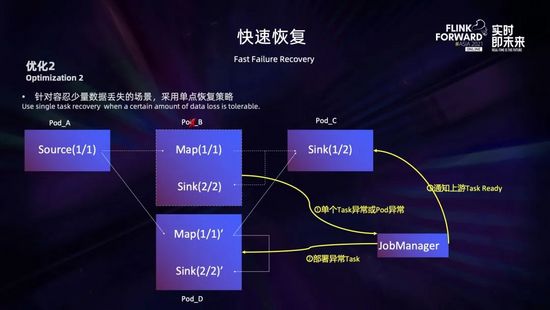
另外一個方面是減小 pod 異常對作業的影響范圍。雖說社區版在 1.9 之后,提供了基于 region 的局部恢復策略,在 Task 發生故障時,只重啟故障 Task 關聯 region 內的 Task,在有的場景下可以減小影響。但是很多時候一個作業的算子之間都是 rebalance 或者 hash 等全連接的方式,region 策略也起不到太大作用。為此,我們在 1.10 和 1.12 版本中,開發了基于故障 Task 的單點故障恢復策略,Task 發生故障時只恢復該故障 Task,非故障 Task 不受影響。
如上圖所示,這個作業有三個算子 source、map 和 sink。其中 source 和 map 都是 1 個并行度,sink 是 2 個并行度。map 的第一個并行度 map(1/1) 和 sink 的第二個并行度 sink(2/2) 分布在 pod_B 上,在 pod_B 被驅逐的時候,Jobmanager 會檢測到 pod_B 異常,之后會在新的 pod_D 上重新部署這兩個 Task,記為 map(1/1)’ 和 sink(2/2)’;部署完成后,會通知故障 Task map(1/1) 的下游 sink(1/1) 新的上游 Task map(1/1)’ 已經 ready,然后 sink(1/1) 就會和上游 map(1/1)’ 重新建立連接,進行通信。
在具體實現的時候有以下幾點需要注意:
- 一是故障恢復前,故障 Task 的上游對于待發送數據和下游對于接收的殘留數據如何進行處理?這里我們會將上游輸出到故障Task數據直接丟棄掉,下游如果收集到不完整的數據也會丟棄掉;
- 二是上下游無法感知到對方異常時,再恢復的時候如何進行處理?這里可能需要一個強制的更新處理;
- 三是一個 pod 上分布了多個 Task 的情況,如果該 pod 異常,存在多個故障 Task,這些故障 Task 之間如果存在依賴關系,如何正確地進行處理?這里需要按照依賴關系進行順序的部署。
通過單點恢復策略,在線應用取得了不錯的效果,對作業的影響范圍大大減少 (取于具體的作業,能夠減少為原來的幾十分之一到幾百分之一),避免了業務的斷流,同時恢復時長也大大降低 (從典型場景的一分多鐘降低到幾秒 - 幾十秒)。
當然,這個策略也是有代價的,它在恢復的時候會帶來少量的丟數,適用于對少量丟數不敏感的業務場景,比如流量業務。
四、未來規劃

未來我們會在以下幾方面繼續探索:
一個是 K8s 層面資源調度優化,更高效地管理大數據的在線服務和離線作業,提升 K8s 集群的利用率和運行效率;
一個是 Flink 作業調度優化,支持更豐富、更細粒度的調度策略,提升 Flink 作業資源的利用率和穩定性,滿足不同的業務場景需要。
首先是調度優化:
其次是服務混部:將不同負載的服務混部在一起,在保證服務穩定的前提下盡量提升資源利用率,使服務器的價值最大化;
然后是智能運維:支持對任務進行智能診斷,并自適應調整運行參數,實現作業的資質,降低用戶調優和平臺運維的成本;
最后是 Flink AI 的支持:人工智能應用場景中,Flink 在包括特征工程、在線學習、資源預測等方面都有一些獨特的優勢,后續我們也將在這些場景從平臺層面進行探索和實踐。