詳解容災架構中的數(shù)據(jù)復制技術
1. 什么是企業(yè)容災的數(shù)據(jù)復制技術?
企業(yè)容災架構中,所謂的數(shù)據(jù)復制技術主要是指能夠?qū)⒔Y構化數(shù)據(jù)進行復制,從而保證數(shù)據(jù)具備雙副本或者多副本分散在不同數(shù)據(jù)中心的技術。這里面需要強調(diào)兩點:
① 結構化數(shù)據(jù):以結構化數(shù)據(jù)為主的數(shù)據(jù)復制技術。
② 分散在不同數(shù)據(jù)中心:數(shù)據(jù)副本必須分布在不同的數(shù)據(jù)中心。
就具體的實現(xiàn)技術而言,就目前業(yè)界發(fā)展來看,可以實現(xiàn)數(shù)據(jù)復制的技術多種多樣,有基于數(shù)據(jù)庫層面的數(shù)據(jù)復制技術,例如Oracle公司的Active Data Gurad、IBM公司的 Db2 HADR等;有基于系統(tǒng)層面的數(shù)據(jù)復制技術,例如賽門鐵克的vxvm、傳統(tǒng)的邏輯卷管理(LVM)、Oracle公司的自動存儲管理(ASM)冗余技術、IBM公司的GPFS等;有基于存儲虛擬化實現(xiàn)的數(shù)據(jù)復制技術,例如EMC公司Vplex Stretch Cluster、IBM公司SVC Split Cluster、NetAPP公司Metro Cluster等;也有基于存儲底層實現(xiàn)的數(shù)據(jù)復制技術,例如IBM公司的DS8000 PPRC技術、EMC公司的SRDF技術、HP公司的CA技術等等。每一種技術都有其實現(xiàn)的前提條件,也有各自的技術特點和實現(xiàn)的不同效果。
2. 企業(yè)容災中的數(shù)據(jù)復制技術的分類
2.1 同步復制和異步復制
從RPO維度來劃分,大的方面可以分為同步復制和異步復制。
① 同步復制:要求每一個寫入操作在執(zhí)行下一個操作處理之前,在源端和目標端都能完成。特點是數(shù)據(jù)丟失少,會影響生產(chǎn)系統(tǒng)性能,除非目標系統(tǒng)物理上離生產(chǎn)系統(tǒng)比較近。
② 異步復制:在處理下一個操作前, 只需要完成源端數(shù)據(jù)寫入即可, 不等待數(shù)據(jù)復制到目標系統(tǒng)中。特點是復制的數(shù)據(jù)與源數(shù)據(jù)有時間差,但這種復制對生產(chǎn)系統(tǒng)性能影響較小。
那么這里有一個問題“如何界定一個寫入操作完成?”,一般來講,存儲端的寫入以存儲設備的緩存寫入為標準,數(shù)據(jù)庫的寫入以數(shù)據(jù)庫的事務日志落盤為標準。

如果用圖的方式來區(qū)別同步和異步之前的區(qū)別就在于:同步需要等待黑色和紅色的ACK返回才會執(zhí)行下一個IO,而異步只需要等待黑色的ACK返回即可執(zhí)行下一個IO。從結果上來看,等待紅色的ACK返回顯然需要花費更多時間,因為A和B分別位于不同的數(shù)據(jù)中心;但是等待會帶來RPO=0的回報。
2.2 根據(jù)實現(xiàn)復制的手段來劃分

根據(jù)上圖,數(shù)據(jù)復制最終完成的結果是在兩個磁盤介質(zhì)上完成同一個IO數(shù)據(jù),但是將來自客戶端的單個IO請求鏡像為兩個IO的源頭可以有三種不同的選擇:操作系統(tǒng)層面、數(shù)據(jù)庫層面以及存儲層面。
1)操作系統(tǒng)層面的復制技術:以LVM、VXVM等邏輯卷鏡像為基礎,IO寫入的時候可以在組成同一個邏輯卷的物理鏡像上同時寫入數(shù)據(jù),底層數(shù)據(jù)寫入是需要通過SAN協(xié)議完成的。
2)數(shù)據(jù)庫層面的復制技術:一種是類似操作系統(tǒng)邏輯卷的模式,比如ORACLE的ASM,它也是一種邏輯卷管理模式,同樣也可以通過多個物理鏡像來組成一個邏輯卷,從而通過鏡像復制的方式完成數(shù)據(jù)副本的同時寫入。本質(zhì)上它與操作系統(tǒng)層面的邏輯卷鏡像技術沒有區(qū)別,只是它離數(shù)據(jù)庫更近,數(shù)據(jù)庫更懂它。另外一種是通過數(shù)據(jù)庫事務日志復制的方式將數(shù)據(jù)修改行為在另外一個備庫上重新演繹一遍,最終可以達到使數(shù)據(jù)結果一致的目的。
3)存儲層面的復制技術:一種是通過存儲網(wǎng)關將兩個物理存儲卷組成一個邏輯存儲卷,通過鏡像復制的方式完成數(shù)據(jù)在存儲落盤時的雙寫。本質(zhì)上它與操作系統(tǒng)層面的邏輯卷鏡像技術也沒有區(qū)別,只是它選擇在存儲層面實現(xiàn)。另外一種是通過存儲介質(zhì)之間以塊拷貝的方式來實現(xiàn)數(shù)據(jù)副本的冗余。
究其原理,其實無論從哪個層面來實現(xiàn),這些技術從原理上可以劃分為三種類型:
- IO雙寫(操作系統(tǒng)邏輯卷鏡像、ASM、存儲網(wǎng)關鏡像.etc)
- 事務回放(以Oracle ADG為代表.etc)
- 數(shù)據(jù)單元拷貝(以存儲CA、DP技術為代表的存儲復制技術)
3. 系統(tǒng)層如何實現(xiàn)數(shù)據(jù)復制?
3.1 通過操作系統(tǒng)邏輯卷鏡像實現(xiàn)數(shù)據(jù)復制

對于操作系統(tǒng)層面的邏輯卷管理器LVM模式來講,是將底層來自不同數(shù)據(jù)中心的的兩個物理存儲卷作為物理鏡像( PV) 組合成一個可用的邏輯存儲卷( LV) 提供給上層應用來存放數(shù)據(jù),本地物理卷和遠程物理卷分別是由存儲經(jīng)過本地SAN環(huán)境以及跨數(shù)據(jù)中心SAN環(huán)境提供給服務器操作系統(tǒng)層。
建立邏輯卷的時候就已經(jīng)定義好LV和PV的映射關系,并且邏輯頁(LP ) 和物理頁(PP ) 的映射關系也已經(jīng)完全定義好了。這種復制只能采用同步復制機制,復制對象為邏輯卷層的變化Block,其過程為:捕獲邏輯頁( LP) 當中的變化塊,同步寫兩個物理頁( PP) ,等于在一個主機上將同一數(shù)據(jù)寫入兩個不同的磁盤,本地寫完得到ACK確認,并且遠端寫完也得到ACK確認,才能算是一個完整的寫入。假設遠端存儲卷寫入超時就會被標為故障或者是離線狀態(tài),當遠端存儲寫入恢復之后,對于LVM來講需要重新進行手動同步實現(xiàn)鏡像副本完全一致。
3.2 通過數(shù)據(jù)庫邏輯卷鏡像實現(xiàn)的數(shù)據(jù)復制

對于ASM模式來講,其實原理與LVM基本相同,創(chuàng)建DiskGroup的時候,將冗余策略選擇為Normal,也就是所有業(yè)務數(shù)據(jù)保證兩份鏡像。這樣的話,我們可以將相等數(shù)量的磁盤分別歸入不同的故障組( Failure Group) 。ASM對Oracle數(shù)據(jù)文件( Data File) 進行修改的時候,以AU為單元進行實時雙向?qū)懭耄镜貙懲甑玫紸CK確認,并且遠端寫完也得到ACK確認,才能算是一個完整的寫入。
相比LVM的優(yōu)勢在于兩點:ASM會有一個短時間內(nèi)的寫事務日志記錄,它會幫助恢復離線鏡像恢復數(shù)據(jù),但是如果超過這個時間,同樣需要一個全新的同步來保證數(shù)據(jù)的一致性。另外一點,AU并非建立數(shù)據(jù)文件的時候就已經(jīng)映射好了,ASM是在數(shù)據(jù)寫入時才會分配具體的AU,完全可以做到通過指針轉(zhuǎn)移的方式避免壞塊兒導致的數(shù)據(jù)寫入失敗問題。
3.3 通過分布式文件系統(tǒng)文件鏡像實現(xiàn)的數(shù)據(jù)復制

對于GPFS模式來講,它是通過將底層來自不同站點的兩個物理存儲卷歸屬到不同的Failure Group當中,然后由這些物理存儲卷經(jīng)過文件系統(tǒng)格式化形成分布式文件系統(tǒng),提供給上層應用以文件的形式寫入數(shù)據(jù)。文件本身會被GPFS文件系統(tǒng)打散形成若干文件碎片,這些碎片在落盤時分別落入不同F(xiàn)ailure Group當中的物理磁盤,從而保證底層數(shù)據(jù)的雙副本。這種模式與前兩種模式的最大區(qū)別在于它的數(shù)據(jù)落盤是根據(jù)NSD磁盤定義的服務實例順序來決定的,正常情況下我們需要定義本站點的服務節(jié)點為磁盤的主服務節(jié)點,這樣的話兩個鏡像寫入的時候是靠GPFS位于不同中心的兩個服務實例節(jié)點分別寫入,兩個服務實例之間也需要私有協(xié)議的交互,相當于數(shù)據(jù)的雙寫多了一個環(huán)節(jié)。
4. 數(shù)據(jù)庫層如何實現(xiàn)數(shù)據(jù)復制?
4.1 通過數(shù)據(jù)庫日志回放模式實現(xiàn)數(shù)據(jù)復制
對于事務日志的復制技術,可以分為絕對同步模式、近似同步模式和異步模式三種。

對于Oracle DB來講,客戶端的數(shù)據(jù)更新請求首先要由日志寫入進程( LGWR) 從重做緩存刷到重做日志文件當中,然后由數(shù)據(jù)寫進程再周期性地寫入數(shù)據(jù)文件當中。重做日志當中以SCN為數(shù)據(jù)庫獨有的時間戳序列來記錄所有數(shù)據(jù)庫更新的先后順序,從而保障數(shù)據(jù)庫恢復能夠按照正確的順序執(zhí)行保障數(shù)據(jù)一致性和完整性。也就是說在數(shù)據(jù)庫的認知當中,只要事務日志寫入重做日志文件,這個IO就算完成。

如圖,對于配置了Data Guard絕對同步模式的數(shù)據(jù)庫,在以上所述過程中,寫入進程( LGWR) 在本地日志文件并不能結束,日志傳輸進程( LNS) 會將緩存里面的重做日志通過TCP /IP 網(wǎng)絡傳輸給災備站點的備庫實例的日志接受進程(RFS ) ,備庫實例的日志接收進程( RFS) 根據(jù)接受到的重做日志在備庫上重新執(zhí)行數(shù)據(jù)庫的更新操作,然后將ACK回傳給日志傳輸進程( LNS) ,日志傳輸進程( LNS) 再通知寫入進程( LGWR) ,才算是一個完整的IO完成。這樣做可以保證主庫和備庫的事務性更新行為實時一致,最終保證數(shù)據(jù)的一致。當然也有一個前提條件,那就是在Data Guard開始同步復制之前,必須保證備庫的數(shù)據(jù)保持與主庫的某一固定時間點的完整副本,這需要靠傳統(tǒng)數(shù)據(jù)備份技術來實現(xiàn)備庫的初始數(shù)據(jù)復制。因為事務復制的本質(zhì)是行為復制,那么行為作用的初始數(shù)據(jù)副本必須保持一致,才能保證最終兩副本的一致性。
如圖,對于配置了Data Guard異步模式的數(shù)據(jù)庫,日志傳輸進程( LNS) 會將緩存里面的重做日志以及被LGWR歸檔的重做日志文件通過TCP /IP 網(wǎng)絡異步傳輸給災備站點的備庫實例的日志接受進程(RFS ) ,備庫實例的日志接收進程( RFS) 根據(jù)接受到的重做日志在備庫上重新執(zhí)行數(shù)據(jù)庫的更新操作,但是并不會實時給日志傳輸進程( LNS) 進行ACK反饋,PrimaryDB只要完成本庫的事務更新就認為IO結束。但是備庫日志接受進程(RFS ) 會定期將進度信息反饋給主庫進程。
當主備庫傳輸管理剝離之后,主庫會主動通過以下兩種方式探測并嘗試重新和備庫建立聯(lián)系,第一是歸檔日志進程會周期性ping備庫,成功情況下,它會根據(jù)獲得的備庫控制文件的記錄的最后歸檔點和自己的歸檔日志決定向備庫推送哪些歸檔日志。第二是日志發(fā)送進程會在重做日志準備發(fā)生歸檔的時刻點主動去ping備庫日志接受進程并把剩余的重做條目發(fā)送給備庫接受進程。
近似同步模式是指在傳輸正常情況下保持與絕對同步模式一樣的模式,在網(wǎng)絡傳輸超時的情況下,就會剝離備庫重做日志的過程,只要保證主庫重做日志落盤就可以了。
5. 存儲層如何實現(xiàn)數(shù)據(jù)復制?
5.1 通過存儲網(wǎng)關邏輯卷鏡像實現(xiàn)數(shù)據(jù)復制
所謂存儲網(wǎng)關雙寫復制技術,就是在物理存儲層之上增加一層網(wǎng)關技術,用以形成存儲資源透明抽象層,即存儲虛擬化是服務器與存儲間的一個抽象層用以實現(xiàn)存儲底層的虛擬化以及高可用鏡像,它是物理存儲的邏輯表示方法。其主要目的就是要把物理存儲介質(zhì)抽象為邏輯存儲空間,將分散的物理存儲管理整合為集中存儲管理并且由存儲網(wǎng)關來控制鏡像寫入的策略和模式。IBM、EMC、NETAPP 、 HUAWEI、英方等公司都有相應容災技術方案及相應產(chǎn)品 。基于寫入原理及策略的不同, 各自方案又各有一些區(qū)別。但是拋開細節(jié)究原理,歸類總結之后有兩種模式 。

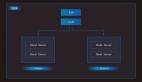
模式 1,如 圖中所示,是以 EMC Vplex為代表的分布式存儲卷技術。在存儲網(wǎng)關VPLEX上重新定義虛擬存儲卷,該虛擬卷由分布在兩個數(shù)據(jù)中心的物理存儲卷以1:1方式映射組成,并且以共享模式提供給VPLEX的兩個引擎,引擎之間類似Oracle RAC的原理來共享全局緩存、心跳信息以及分布式鎖的信息。兩個引擎同時可以寫IO,對于Block級別的并發(fā)寫操作,是通過分布式鎖及全局緩存機制來完成。所以這種雙寫是可以做到IO級別。

模式 2,如圖中所示,是以 IBM SVC為代表的虛擬存儲卷技術。在存儲網(wǎng)關SVC上重新定義虛擬存儲卷,該虛擬卷由分布在兩個數(shù)據(jù)中心的物理存儲卷以1:1方式映射組成,并且歸屬同一個IO Group,并且以共享模式提供給SVC的兩個節(jié)點,雖然兩個節(jié)點都可以寫操作,但是對于某一個IO Group來講,只能通過一側(cè)節(jié)點進行物理層面的雙寫操作,這樣就避免了兩個節(jié)點的在Block級別的并發(fā)控制。所以這種雙寫只能做到應用級別,做不到IO級別。
當然還有一些類似的架構,在某些細節(jié)上更先進,比如NetApp的容災方案MCC架構,它在此基礎之上可以將負責存儲寫操作的實例節(jié)點做到VM級別,VM負責以卷為粒度的雙寫,同時VM可以在存儲網(wǎng)關的物理引擎或節(jié)點之間進行漂移和重組,這樣的話以應用為粒度的寫操作的容災切換更加平滑。
5.2 通過存儲介質(zhì)塊復制實現(xiàn)數(shù)據(jù)復制

對于存儲存儲底層的塊兒復制技術來講, 它的數(shù)據(jù)復制是完全脫離了上層的應用層、系統(tǒng)層、數(shù)據(jù)庫層。主要是依靠存儲層兩個物理存儲設備 來完成源到目標 設備 的 Block 復制。
如圖所示,從組成上來看,只有兩個同型物理存儲設備,數(shù)據(jù)復制跟上層沒有任何關系,只需要存儲層從一邊的物理卷捕獲 Block變化,復制到另外一邊的物理存儲卷,整個復制行為通過源端的日志文件來記錄進度以及保障故障恢復。根據(jù)整個復制過程是否需要等待復制完成的ACK返回可以分為同步復制和異步復制。復制過程依賴的傳輸環(huán)境可以是遠距離的以太網(wǎng)也可以是近距離的SAN網(wǎng)絡。
但是這種數(shù)據(jù)復制技術和上層的聯(lián)系幾乎是割裂的,基本很難與上層的容災切換配合。?