轉轉AB平臺的設計與實現
導讀
在數據驅動時代,不管是在產品功能迭代還是策略決策時都需要數據的支撐。那么,當我們準備上線一個新功能或者策略時,如何評估新老版本優劣,即數據的可量化就成了問題。這個時候就需要引入 A/B Test 了。
一、A/B Test 是什么?
A/B Test 的概念來源于生物醫學的雙盲測試,雙盲測試中病人被隨機分成兩組,在不知情的情況下分別給予安慰劑和測試用藥,經過一段時間的實驗后再來比較這兩組病人的表現是否具有顯著的差異,從而決定測試用藥是否有效。
在互聯網行業中,在產品正式迭代發版之前,將 Web 或 App 界面或流程以同一個目的制定兩個或多個方案,在同一時間維度,將流量對應分成若干個組,在保證每組用戶特征相同(相似)的前提下,展示給用戶不同的設計方案,收集各組的用戶體驗數據和業務數據,最后分析評估出最好版本,科學的進行決策。

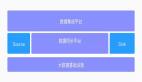
二、AB 系統設計與實現
2.1 系統介紹
轉轉 AB Test 系統的核心功能主要包含五個部分:
- 實驗管理:實驗配置、上下線等操作。
- 指標管理:分業務線創建與管理數據指標,數據指標分為「事件指標」和「復合指標」。
- 白名單管理:各種分流標識的白名單創建與管理。
- 數據報告:總實驗用戶數、流量概覽、關注指標圖表和實驗結論數據。
- 分流服務:供業務方調用獲取實驗分組結果的 RPC 服務。
2.2 系統架構

2.3 系統實現
2.3.1 實驗管理
- 實驗列表:是所有實驗的集合,整個實驗列表分為三個區域「篩選/查詢區域」、「新建實驗」、「列表區域」。

- 新建實驗:要求填三個部分信息基礎信息、實驗配置信息、實驗策略配置,狀態默認為測試中。
實驗基本信息

實驗配置信息

實驗策略配置

2.3.2 指標管理
指標分為「事件指標」和「復合指標」兩種類型。事件指標通過埋點事件配置統計,復合指標通過基礎的事件指標進行四則運算生成。


2.3.3 白名單管理
白名單功能提供統一的白名單創建與管理,用于實驗配置時給相關實驗組添加白名單,作用與分流服務,方便業務實驗開發測試時通過配置白名單直接進入相應的實驗組。

2.3.4 數據報告
實驗報告是針對單個實驗,配置的核心指標以及相關指標一個統計性的數據報告說明。
- 基本信息
實驗ID:該實驗的實驗ID。
實驗名稱:該實驗的實驗名稱。
開始時間:該實驗正式上線的時間。
運行天數:該實驗從上線至今/結束前的運行天數。
操作記錄:記錄這個實驗的操作變化記錄,包含流量分配、核心指標修改、實驗暫停/上線等。
查看配置:查看這個實驗的配置信息。

- 核心數據
整體-總實驗用戶數:實驗上線至今/結束前共參與實驗的用戶數,按照分流標識進行統計。
分組-總實驗用戶數:各個分組實驗上線至今/結束前共參與實驗的用戶數,按照分流標識進行統計。
總實驗用戶占比:「分組-總實驗用戶數」 / 「整體 - 總實驗用戶數」* 100%。
流量分配:創建實驗時,流量的分配比例。
核心指標值:創建實驗時,配置的「核心指標」對應的數值,這里會根據【指標管理】中配置的數值方式與小數位數進行顯示。
統計學校驗:用于描述試驗組指標相比于對照組的提升范圍。隨著參與試驗的樣本量逐漸增加,數據指標波動趨于穩定,置信區間會逐漸收窄。一般來說,置信區間選擇 95%。
統計功效:統計功效用于描述通過試驗能檢測出試驗結果真實可靠的概率;一般用于衡量實驗不顯著時,是否需要繼續擴大樣本繼續實驗。一般當差異不顯著時,統計功效小于 80%,需要繼續做實驗,當差異不顯著是,統計功效大于 80%,說明基本對照組與實驗組沒有差異。
實驗結論:實驗結論根據「核心指標」與「統計功效」得出實驗結論。

- 流量概覽
主要目的衡量流量分配是否均勻,指標為「新進組用戶數」:當天第一次參與實驗的用戶數。

- 關注指標(包含核心指標)
實驗UV:同「分組-總實驗用戶數」,各個分組實驗上線至今/結束前共參與實驗的用戶數,按照分流標識進行統計。
指標名稱:所選的指標對應的名稱。
差異絕對值:該分組對應對照組在該指標上的差異的值,舉例:如對照組訂單數為 50,實驗組為 100, 這里的差異絕對值為 100 - 50 = 50。
差異相對值:該分組對應對照組在該指標上的差異的百分比,舉例:如對照組訂單數為 50,實驗組為 100, 這里的差異絕對值為(100 - 50)/ 50 = 100%。
置信區間:核心指標通過實驗配置的置信水平統計計算。

2.3.5 分流服務
- 分流邏輯
分流服務實時同步已上線運行的實驗配置,業務調用方通過實驗ID+分流標識獲取實驗的分組結果,具體實現邏輯如下:
- 分流方案
結合轉轉業務的特點,使用了無層方案。所謂無層,就是每個實驗都是單獨一層,使用實驗 id 作為種子將 1-100 的桶號進行洗牌打亂,具體實現方法如下:
如此一來確保了每個實驗都單獨占有所有流量,可以取任意組的流量進行實驗,但是又引進了新的問題,無層會導致同一個用戶命中多個實驗,即使這些實驗是互斥的。
為了解決實驗需要互斥的需求,后期將引入互斥實驗組的概念,將互斥實驗放在同一個組中,共享所有流量。具體實現邏輯如下:
新分流邏輯
新分流方案
三、A/B Test 實施指南
實驗的每個流程與節點都至關重要,拒絕為做實驗而做實驗,用心用科學來做實驗,整體實驗實施流程圖如下圖。

3.1 實驗設計
3.1.1 實驗設計初衷
對于互聯網產品而言,每次上線新版本都尤為慎重,為了衡量與判斷「新上線的版本」/「現有版本」哪個版本的策略更優,通過事實的數據結合統計學原理進行科學、合理的進行決策。
實驗的設計是實驗最重要的一環,實驗設計的好壞決定了最終實驗的成功與否。
3.1.2 實驗設計模板

3.1.3 實驗設計的結構
整體實驗的設計分為四個部分:
實驗基本信息
- 業務線歸屬,可分為「B2C」、「C2B」、「C2C」,根據具體業務進行選擇即可。(為什么要區分業務線?不同業務線進行指標隔離,提升實驗人員更好更快進行指標選擇,底層數據處理效率與指標也更高效,數據響應更快。)
- 實驗名稱,實驗具體的名稱。
- 實驗編號,在具體「AB Test 平臺」在創建實驗后即可獲得,唯一標識了一個實驗。
- 實驗目標,在實驗設計的初期,上線新版本的目的是什么,希望您能用「核心指標」的提升程度來衡量;如:新版本「優化下單流程」,核心指標「訂單轉化率」希望提升 0.8%。
實驗配置信息
- 實驗類型,目前包含了「編程實驗」,「策略實驗」。
- 預期上線時間,預期的實驗上線的時間。
- 預期上線天數,根據實驗受眾群體的樣本數量,簡單估測上線的時長,單位天。業界的實驗時長一般是 2-3 周,最短時長建議不要少于 7 天。因為不同日期活躍的用戶群體可能不一樣,所以最好要覆蓋一個周期,如 7 天、14 天、21 天。那實驗時長是不是越長越好呢,也不是的,實驗時間過長會把各版本的區別拉平了,不同時期用戶對不同策略的反應不一樣,一般不超過 30 天。
- 實驗指標,通常可被統計學檢驗的指標分為以下三類:人均類指標、次均類指標、轉化率類指標。
- 核心指標(人均類指標、次均類指標、轉化率類指標):實驗目標直接相關,且決定實驗結果的關鍵指標。
- 相關指標:該實驗需要關注的其他指標,用于輔助試驗結果的解讀。
- 護欄指標:實際上是相關指標比較特殊的一種,通常是能反映用戶體驗受到傷害的指標,常常擁有“一票否決權”,幫助我們平衡實驗決策。
注意:
- 對于少部分比較重要的相關指標/護欄指標來說,他們是有“一票否決權”的,他們也需要符合可被統計學檢驗的要求(判斷這些數值差異到底是出自偶然,還是有確鑿的判定把握)。
- 對于核心指標,必須是可以直接關聯到實驗中的變量,否則無法推測實驗整體的差異性(即實驗有差異性,但是通過數據無法觀測出來)。
- 用戶分流標識,目前分為 token/deviceId 與 uid,用于埋點上報和數據統計的區分。
- 受眾群體,與用戶畫像進行打通,針對圈定用戶人群的部分用戶開展精準實驗。
實驗策略設計
- 實驗分組,默認按照字母順序來, A/B/C/D/E...
- 版本描述,各個版本的描述性文字,描述清晰各個版本的情況。
- 流量分配,最多分配 100% 流量,最細粒度為 1%。
實驗結論
- 決策分組,最終實驗下線的決策分組。
- 統計數據,各個版本之前的核心數據(核心指標_均值,置信區間,統計功效)。
- 實驗結論描述,整體實驗結果描述。
3.2 實驗埋點上報規范
"實驗ID":實驗的id標識,用于實驗數據統計。
"實驗分組":實驗分組結果,用于實驗版本展示的標識。
"分流用戶類型" :用于實驗分流的標識類型,便于精準統計 UV 類指標數據。
埋點上報格式舉例:
3.3 實驗決策指南
3.3.1 實驗決策流程
當我們的實驗在線上已經運行了一段時間之后,我們需要衡量實驗整體的效果,整體實驗決策的流程如下圖。

實驗報告:包含了整體實驗總用戶在每個實驗組的流量分配情況以及「核心指標」、「相關指標」的統計學檢驗結果,根據實驗組的核心指標相對于對照組的核心指標變化率情況、置信區間及統計功效來評估試驗效果。
「核心指標」的提升/下降決定了整體實驗的效果,一般我們用置信區間和統計功效來整體判斷實驗的結果。
注意:對于少部分比較重要的相關指標/護欄指標來說,他們是有“一票否決權”的,需要進行整體評估,平衡試驗決策。
3.3.2 置信區間&統計功效計算
什么是置信區間?
置信區間是一種常用的區間估計方法,所謂置信區間就是分別以統計量的置信上限和置信下限為上下界構成的區間 。對于一組給定的樣本數據,其平均值為 μ,標準偏差為 σ,則其整體數據的平均值的 100(1 - α)% 置信區間為 (μ - Ζα/2σ, μ + Ζα / 2σ) ,其中 α 為非置信水平在正態分布內的覆蓋面積 ,Ζα / 2 即為對應的標準分數。
為什么要計算置信區間?
在「A/B測試」的場景下,主要通過某個指標或留存的實驗版本均值變化值以及置信區間來判斷,在當前指標或用戶留存上,實驗版本是否比對照版本表現得更好。
置信水平,也稱置信水平、置信系數、統計顯著性,指實驗組與對照組之間存在真正性能差異的概率,實驗組和對照組之間衡量目標(即配置的指標)的差異不是因為隨機而引起的概率。置信度使我們能夠理解結果什么時候是正確的,對于大多數企業而言,一般來說,置信度高于 95% 都可以理解為實驗結果是正確的。因此,默認情況下,「A/B測試」將置信區間參數值設置為 95%。
置信水平 | Z值 |
99% | 2.58 |
95% | 1.96 |
90% | 1.645 |
80% | 1.28 |
- 如果置信區間上下限均為正值,則表明試驗結果為正向顯著。
- 如果置信區間上下限均為負值,則表明試驗結果為負向顯著。
- 如果置信區間一正一負,則表明試驗結果差異不顯著。
計算邏輯


- 均值類
舉例:實驗核心指標是「人均支付金額」,需要計算 2022-06-01~2022-06-10;區間內「實驗組」相對「對照組」置信區間范圍,數據如下所示:
對照組:參與實驗用戶 239 個,累積支付金額 121392 元。
實驗組:參與實驗用戶 640 個,累積支付金額 504795 元。

- 比率類
例如:某個區間內

3.4 實驗到期下線
實驗到期下線分為兩種情況:未到期決策下線、到期自動下線。
- 未到期決策下線,核心指標的統計功效已經很明顯,可以直接分出實驗各組的效果,則可以直接以優勝組進行決策下線,全量決策組,后期業務代碼邏輯進行下線,落地實驗結果。
- 到期自動下線,當實驗設定的實驗周期已結束,實驗各組的核心指標的統計功效不明顯,則自動以對照組下線,全量對照組,后期業務代碼邏輯進行下線,落地實驗結果。

四、未來規劃與展望
- 實驗類型多樣化。提供更多、更豐富的實驗類型,根據業務場景選擇最合適的實驗類型,更科學有效的進行實驗。
- 數據報告豐富化。目前只有單指標維度的看數圖表,留存分析、漏斗分析和歸因分析將是后期的功能迭代點。
- 數據與監控告警實時化。目前的數據是離線數倉 T + 1 清洗打寬,有待提高數據的實時性,能快速發現問題,調整實驗方案。
五、總結
本文主要分享了:
- A/B Test 是什么?
- AB 系統設計與實現
- A/B Test 實施指南
- 未來規劃與展望
從了解 AB、如何開發 AB 平臺、如何實施 AB 實驗和未來的規劃迭代四個方面介紹了 A/B Test 在轉轉的落地與應用。在互聯網產品玲瑯滿目下,如何吸引新用戶,留住老用戶以及試錯成本越來越高的場景下,如何通過 A/B Test 小流量、多方案,快速迭代、決策、優化產品變得越來越重要。AB 平臺的建設還有很長的路要走。
未來轉轉會針對痛點與不足進行持續優化,輸出更多的技術實踐給大家,一起進步成長。