













分析型數(shù)據(jù)庫DuckDB基準測試
我們都知道Polars很快,但是最近DuckDB以其獨特的數(shù)據(jù)庫特性讓我們對他有了更多的關(guān)注,本文將對二者進行基準測試,評估它們的速度、效率和用戶友好性。

在評測之前我們先看看這兩個框架
- DuckDB(0.9.0):一個用c++編寫的內(nèi)存分析數(shù)據(jù)庫。
- Polars(0.19.6):一個用Rust實現(xiàn)的超快的DataFrame庫
除此以外還有Pandas、Dask、Spark和Vaex本文主要關(guān)注DuckDB和Polars的基準測試,因為它們特別強調(diào)在某些環(huán)境下的速度性能。之所以對這兩個框架進行對比是因為 Polars是我目前測試后得到最快的庫,而DuckDB它可以更好的支持SQL,這對于我來說是非常好的特這個,因為我更習(xí)慣使用SQL來進行查詢。
指標設(shè)置
我使用了官方的polar基準測試存儲庫進行此評估。基準測試由tpc標準化查詢組成。這些是專門用來評估實際的、真實的工作流的性能的。在Polars官方網(wǎng)站上,提供了8個此類查詢的詳細結(jié)果。這個基準包含22個唯一的查詢(q1、q2等)。這些范圍從多表連接到聚合排序,所有這些都是大家認可的經(jīng)過特殊構(gòu)建的查詢。
測試在一臺配備16核AMD vCPU和32GB RAM的機器上進行。所有代碼都使用Python 3.10執(zhí)行。
數(shù)據(jù)大小
數(shù)據(jù)是由使用scale10的存儲庫代碼生成的,下面是每個實體的大小

數(shù)據(jù)轉(zhuǎn)換與查詢
我們文件讀取到內(nèi)存中,然后進行查詢。

在q1、q9、q13和q17中,多連接、基于字符串的過濾和復(fù)雜聚合的組合對于polars 來說很難像duckdb那樣有效地進行優(yōu)化。Q21是對惟一值的計數(shù)、基于這些計數(shù)進行過濾以及隨后的一系列連接的操作。
總的來說DuckDB在這兩種情況下看起來更快,但這并不是全部。
因為將數(shù)據(jù)加載到內(nèi)存中的過程會產(chǎn)生時間和內(nèi)存開銷。我們通過Makefile準確地度量這些成本。
/usr/bin/time -v make run_duckdb
/usr/bin/time -v make run_polars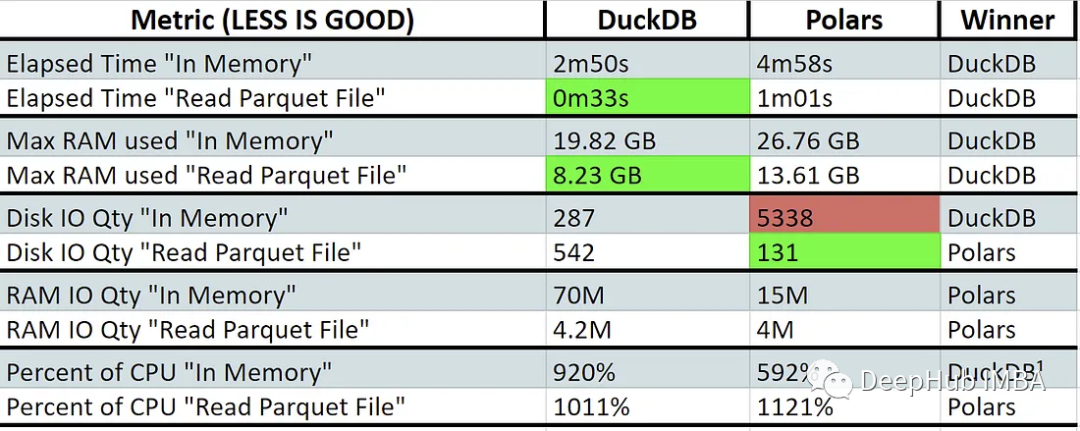
與polar相比,DuckDB在直接讀取文件時表現(xiàn)出更快的性能和更低的內(nèi)存使用。這表明polars 可能使用了交換內(nèi)存(紅色)。這些庫不是為跨多臺機器擴展而設(shè)計的,所以它們都進行了高效CPU核心利用率的設(shè)計。
Polars在某些特定領(lǐng)域表現(xiàn)出具有競爭力甚至更好的性能,例如直接讀取文件時的磁盤IO和內(nèi)存操作時的RAM IO。在磁盤IOPS較低的系統(tǒng)中,polar可以表現(xiàn)得更好。
另外:上圖中的CPU百分比越高越好。值大于100%表示正在使用多核處理。
下面是我們測試的代碼:
DuckDB讀取Parquet直接查詢
import duckdb
conn = duckdb.connect(database=':memory:')
df_count = conn.sql("""
SELECT
count(*) as count_order
FROM
'lineitem.parquet'
"""
).fetchdf()
print(df_count)DuckDB內(nèi)存查詢
import duckdb
conn = duckdb.connect(database=':memory:')
conn.sql("""
CREATE TEMP TABLE IF NOT EXISTS lineitem AS
SELECT *
FROM read_parquet('lineitem.parquet');
"""
)
df_count = conn.sql("""
SELECT
count(*) as count_order
FROM
lineitem
"""
).fetchdf()
print(df_count)Polars 讀取Parquet直接查詢
import polars as pl
df = pl.scan_parquet('lineitem.parquet')
df_count = df.select(
pl.count().alias("count_order"),
).collect()
print(df_count)Polars 內(nèi)存查詢
import polars as pl
df = pl.scan_parquet('lineitem.parquet')
df = df.collect().rechunk().lazy()
df_count = df.select(
pl.count().alias("count_order"),
).collect()
print(df_count)總結(jié)
可以看到在Python處理引擎領(lǐng)域,DuckDB是一個很有前途的競爭者。他在涉及連接和復(fù)雜聚合的任務(wù)中表現(xiàn)非常亮眼。另外它的簡單并且更干凈、而且還支持SQL語句直接查詢。
但是DuckDB仍處于初級階段。可能偶爾會遇到bug或缺少功能的問題,如果你有興趣,可以在你的研究項目中使用DuckDB替代Polars或者Pandas。
本文的測試腳本:
https://github.com/pola-rs/tpch#polars-tpch

















