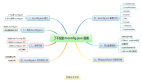
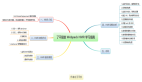
了不起的Unicode
前言
提出一個(gè)小小的問(wèn)題。大家按照自己的開(kāi)發(fā)語(yǔ)言的特性,想想結(jié)果是啥?
"????♂?"這個(gè)Emoji的長(zhǎng)度是多少?
如果,現(xiàn)在你用電腦閱讀本文,你可以輕松的打開(kāi)xx PlayGround(xx可以為Js/Java/Rust等)。然后會(huì)得到屬于自己語(yǔ)言的結(jié)果。
如果,你現(xiàn)在手頭沒(méi)電腦,無(wú)法親自驗(yàn)證,我來(lái)直接告訴你答案。上述Emoji在每種語(yǔ)言環(huán)境下的結(jié)果都不統(tǒng)一。(當(dāng)然,有些語(yǔ)言內(nèi)核使用的機(jī)制一樣,結(jié)果可能也一樣)。
也就是說(shuō),在編程層面,這不是一種 「所見(jiàn)即所得」的表現(xiàn)形式。大家這里可能會(huì)納悶了,我要知道這個(gè)有啥?現(xiàn)在舉一個(gè)例子,在前端頁(yè)面中,我們總是會(huì)有統(tǒng)計(jì)用戶字?jǐn)?shù)的輸入框,但是由于用戶輸入了Emoji,從用戶的角度來(lái)看,這就是一個(gè)字符,但是在編程層面,如果不做一次解析的話,我們會(huì)得到千奇百怪的答案。
然后,我們?cè)賮?lái)一個(gè)讓人匪夷所思的例子。在瀏覽器中,嘗試復(fù)制如下代碼,然后進(jìn)行觀察答案。結(jié)果是不是又再一次顛覆你的所學(xué)。
"A?" === "?";平時(shí),我們時(shí)不時(shí)的會(huì)提到UTF-8/UTF-16/UTF-32它們到底是個(gè)啥?又有啥關(guān)系和區(qū)別呢?
還有其他的例子就不一一列舉了。之所以會(huì)出現(xiàn)這么多讓人匪夷所思的結(jié)果。一切的根源都是Unicode的鬧的。
所以,今天我們就來(lái)談?wù)勥@是何方神圣。
在2000多年前,我們那迷人的老祖宗,秦始皇,就實(shí)現(xiàn)了「車同軌,書同文」,劃破「地域障礙」,從而給不同地方的人在交流上開(kāi)辟了新的空間。雖然,有些地方還存在「十里不同音,百里不通俗」的情況(我老家山西就是這種情況)。但是,在官方層面或者書面層面上,大家可以溝通無(wú)阻。
好了,天不早了,干點(diǎn)正事哇。
我們能所學(xué)到的知識(shí)點(diǎn)
- 前置知識(shí)點(diǎn)
- Unicode 是個(gè)啥?
- UTF-8 又是什么?
- UTF-32 問(wèn)題
- Unicode 病癥
- 如何檢測(cè)擴(kuò)展形素簇
- "A?" !== "?" !== "?"
- Unicode 取決于區(qū)域設(shè)置
1. 前置知識(shí)點(diǎn)
「前置知識(shí)點(diǎn)」,只是做一個(gè)概念的介紹,不會(huì)做深度解釋。因?yàn)椋@些概念在下面文章中會(huì)有出現(xiàn),為了讓行文更加的順暢,所以將本該在文內(nèi)的概念解釋放到前面來(lái)。「如果大家對(duì)這些概念熟悉,可以直接忽略」同時(shí),由于閱讀我文章的群體有很多,所以有些知識(shí)點(diǎn)可能「我視之若珍寶,爾視只如草芥,棄之如敝履」。以下知識(shí)點(diǎn),請(qǐng)「酌情使用」。
ASCll
ASCII[1](American Standard Code for Information Interchange)的縮寫,發(fā)音為ask-key。ASCII是一種用于表示字符的7位標(biāo)準(zhǔn)編碼,其中包括字母、數(shù)字和標(biāo)點(diǎn)符號(hào)。
 圖片
圖片
7 位編碼允許計(jì)算機(jī)編碼總共128個(gè)字符,包括數(shù)字 0-9、大寫和小寫字母 A-Z 以及一些標(biāo)點(diǎn)符號(hào)。然而,這 128 位編碼僅適用于英語(yǔ)用戶。
ASCII 的功能
- ASCII的建立旨在實(shí)現(xiàn)各種數(shù)據(jù)處理設(shè)備之間的「兼容性」,從而使這些組件能夠成功地相互通信。
- ASCII使制造商能夠生產(chǎn)可以確保在計(jì)算機(jī)中正確運(yùn)行的組件。
- ASCII使人機(jī)互動(dòng)。
ASCII 在計(jì)算機(jī)系統(tǒng)中的工作原理
當(dāng)我們按下鍵盤上的鍵,例如字母D時(shí),電子信號(hào)被發(fā)送到計(jì)算機(jī)的CPU進(jìn)行處理和存儲(chǔ)在內(nèi)存中。「每個(gè)字符都被轉(zhuǎn)換為其對(duì)應(yīng)的二進(jìn)制形式」。計(jì)算機(jī)將字母處理為一個(gè)字節(jié),實(shí)際上是一系列電子狀態(tài)的開(kāi)和關(guān)。當(dāng)計(jì)算機(jī)完成處理字節(jié)后,系統(tǒng)中安裝的軟件將字節(jié)轉(zhuǎn)換回,并在屏幕上顯示。字母 D 被轉(zhuǎn)換為01000100。
TextEncoder 和 TextDecoder
TextEncoder 和 TextDecoder 是 JavaScript 中用于處理字符編碼的「內(nèi)置對(duì)象」。它們通常用于在不同字符編碼之間進(jìn)行文本的編碼和解碼。
TextEncoder
- TextEncoder 是用于「將字符串文本編碼為字節(jié)數(shù)組」(通常是 UTF-8 編碼)的對(duì)象。
- 它提供了一個(gè) encode() 方法,接受一個(gè)字符串作為參數(shù),并返回一個(gè)包含字節(jié)的 Uint8Array 對(duì)象。
- TextEncoder 用于將文本數(shù)據(jù)轉(zhuǎn)換為字節(jié)數(shù)據(jù),以便在網(wǎng)絡(luò)傳輸、文件讀寫或其他需要字節(jié)數(shù)據(jù)的情況下使用。
示例:
const encoder = new TextEncoder();
const text = "前端柒八九!";
const bytes = encoder.encode(text); // 將文本編碼為字節(jié)數(shù)組TextDecoder
- TextDecoder 是用于將字節(jié)數(shù)組解碼為字符串文本的對(duì)象。
- 它提供了一個(gè) decode() 方法,接受一個(gè)包含字節(jié)的 Uint8Array 對(duì)象,并返回相應(yīng)的字符串。
- TextDecoder 用于將字節(jié)數(shù)據(jù)還原為文本,通常用于處理來(lái)自網(wǎng)絡(luò)請(qǐng)求或文件的字節(jié)數(shù)據(jù)。
示例:
const decoder = new TextDecoder("UTF-8");
const bytes = new Uint8Array([
72, 101, 108, 108, 111, 44, 32, 87, 111, 114, 108, 100, 33,
]);
const text = decoder.decode(bytes); // 將字節(jié)數(shù)組解碼為字符串這些對(duì)象在處理「多語(yǔ)言文本」、「字符編碼轉(zhuǎn)換」和處理「國(guó)際化內(nèi)容」時(shí)非常有用,使 JavaScript 能夠處理不同字符編碼之間的數(shù)據(jù)轉(zhuǎn)換。
Emoji
Emoji 是可以插入文字的圖形符號(hào)。
 圖片
圖片
它是一個(gè)日語(yǔ)詞,e表示"絵",moji表示"文字"。連在一起,就是"絵文字"。
2010 年,Unicode 開(kāi)始為 Emoji 分配碼點(diǎn)。也就是說(shuō),「現(xiàn)在的 Emoji 符號(hào)就是一個(gè)文字」,它會(huì)被渲染為圖形。
 圖片
圖片
想了解更多,可以翻閱Emoji 簡(jiǎn)介[2]
2. Unicode 是個(gè)啥?
Unicode是一個(gè)旨在統(tǒng)一所有人類語(yǔ)言(包括過(guò)去和現(xiàn)在的語(yǔ)言)并使它們與計(jì)算機(jī)兼容的標(biāo)準(zhǔn)。
Unicode 是一個(gè)將「不同字符分配給唯一編號(hào)的表格」。
例如:
- 拉丁字母 A 被分配編號(hào) 65。
- 阿拉伯字母 Seen ?是 1587。
- 片假名字母 Tu ツ 是 12484
- 音樂(lè)符號(hào) G 調(diào)號(hào) ?? 是 119070。
- ?? 是 128169。
Unicode 將這些編號(hào)稱為「碼位」(code points)。
由于這套準(zhǔn)則是全球都認(rèn)準(zhǔn)的,所以我們采用這套規(guī)則,就可以達(dá)到「書同文」的情況,來(lái)自不同語(yǔ)言環(huán)境下的人,可以閱讀彼此的文本。
有如下的關(guān)系鏈子。 一個(gè)Unicode對(duì)應(yīng)著一個(gè)字符,并且該字符擁有幾乎唯一的碼位。
Unicode === 字符 ? 碼位。
Unicode 有多大?
目前,「最大的已定義碼位」是0x10FFFF。(0x10FFFF 是一個(gè)十六進(jìn)制數(shù),將其轉(zhuǎn)換為十進(jìn)制,其值為 1,114,111。)這給我們提供了大約 110 萬(wàn)個(gè)碼位的空間。
目前已定義了約 15%(約 170,000 個(gè)),另外 11%(為私人使用)已被保留。其余約 800,000 個(gè)碼位目前尚未分配,它們可能在未來(lái)成為字符。
大致如下圖所示:
 圖片
圖片
- 大正方形 包含 65,536 個(gè)字符。
- 小正方形 包含 256 個(gè)字符。
- 整個(gè) ASCII 字符集僅占位于左上角的小紅色正方形的一半。
私人使用區(qū)(Private Use)
私人使用區(qū)是為應(yīng)用程序開(kāi)發(fā)人員保留的碼位,不會(huì)由 Unicode 本身定義。
例如,Unicode 中沒(méi)有為蘋果標(biāo)志保留位置,因此蘋果將它放在了 U+F8FF,這位于私人使用區(qū)。在任何其他字體中,它將呈現(xiàn)為缺失的字符 ??,但在與 macOS 一起提供的字體中,我們將看到蘋果圖標(biāo)。
私人使用區(qū)主要用于「圖標(biāo)字體」:
上面的圖標(biāo)都是文本格式
U+1F4A9 是什么意思?
這是一種寫碼位值的約定。前綴 U+表示 Unicode,而 1F4A9 是一個(gè)「十六進(jìn)制的碼位編號(hào)」。
U+1F4A9 具體表示的是 ??。(是不是我們多了一種很委婉的"表?yè)P(yáng)別人"方式)
3. UTF-8 又是什么?
UTF-8 是一種「編碼方式」。
編碼是我們將碼位存儲(chǔ)在內(nèi)存中的方法。在互聯(lián)網(wǎng)和許多操作系統(tǒng)中,UTF-8是「默認(rèn)的文本編碼」。
最簡(jiǎn)單的 Unicode 編碼是 UTF-32。它將碼位簡(jiǎn)單地「存儲(chǔ)為 32 位整數(shù)」。因此,U+1F4A9 變成了 00 01 F4 A9,占用了「四個(gè)字節(jié)」。UTF-32 中的「任何其他碼位也將占用四個(gè)字節(jié)」。由于最高定義的碼位是 U+10FFFF,因此任何碼位都能夠容納。
- UTF-8通常用于存儲(chǔ)和傳輸文本
- UTF-16用于某些操作系統(tǒng)和編程語(yǔ)言
- UTF-16被許多系統(tǒng)采用。其中包括 Microsoft Windows、Objective-C、Java、JavaScript、.NET、Python 2等
- UTF-32適用于需要直接操作Unicode代碼點(diǎn)的情況
UTF-8 有多少字節(jié)?
UTF-8 是一種「可變長(zhǎng)度」的編碼方式。
一個(gè)碼位可能被編碼為「一個(gè)到四個(gè)字節(jié)」的序列。
以下是 UTF-8 編碼的表示形式,「根據(jù)不同的碼位范圍使用不同數(shù)量的字節(jié)」
碼位范圍 | Byte 1 | Byte 2 | Byte 3 | Byte 4 |
U+0000..007F | 0xxxxxxx | |||
U+0080..07FF | 110xxxxx | 10xxxxxx | ||
U+0800..FFFF | 1110xxxx | 10xxxxxx | 10xxxxxx | |
U+10000..10FFFF | 11110xxx | 10xxxxxx | 10xxxxxx | 10xxxxxx |
這些規(guī)則描述了如何將不同碼位范圍內(nèi)的 Unicode 字符編碼為 UTF-8 字節(jié)序列。
如果將這些內(nèi)容與 Unicode 表結(jié)合起來(lái),我們將看到
- 英語(yǔ)使用 1 個(gè)字節(jié)進(jìn)行編碼,
- 西里爾字母、拉丁歐洲語(yǔ)言、希伯來(lái)語(yǔ)和阿拉伯語(yǔ)需要 2 個(gè)字節(jié),
- 中文、日語(yǔ)、韓語(yǔ)、其他亞洲語(yǔ)言和表情符號(hào)需要 3 或 4 個(gè)字節(jié)。
以下是一些重要的要點(diǎn):
首先,UTF-8 與 ASCII 是「字節(jié)兼容」的。碼位 0..127,即舊的 ASCII 字符,使用一個(gè)字節(jié)進(jìn)行編碼,而且它們的字節(jié)表示完全相同。例如,U+0041(A,拉丁大寫字母 A)就是 41,一個(gè)字節(jié)。
任何純 ASCII 文本也是有效的 UTF-8 文本,而且「只使用碼位 0..127 的 UTF-8 文本可以直接讀取為 ASCII」。
其次,UTF-8 對(duì)于基本拉丁字符來(lái)說(shuō)是「空間高效」的。
- 對(duì)于像 HTML 標(biāo)簽或 JSON 這樣的技術(shù)字符串來(lái)說(shuō),這是有意義的。
第三,UTF-8 內(nèi)置了「錯(cuò)誤檢測(cè)」和「恢復(fù)功能」。
- 第一個(gè)字節(jié)的前綴總是與第 2 到第 4 個(gè)字節(jié)不同。這樣,我們始終可以確定是否正在查看完整和有效的 UTF-8 字節(jié)序列,或者是否有遺漏。
- 然后,我們可以通過(guò)向前或向后移動(dòng),直到找到正確序列的開(kāi)頭來(lái)進(jìn)行糾正。
還有一些重要的結(jié)論:
- 我們「無(wú)法通過(guò)計(jì)算字節(jié)來(lái)確定字符串的長(zhǎng)度」。
- 我們「無(wú)法隨機(jī)跳到字符串的中間并開(kāi)始閱讀」。
- 我們無(wú)法通過(guò)在任意字節(jié)偏移處進(jìn)行「切割來(lái)獲取子字符串」,可能會(huì)切斷字符的一部分。
如果硬要這么做的話,系統(tǒng)會(huì)給你一個(gè)?。
“?”是什么?
U+FFFD,即「替換字符」(Replacement Character),只是 Unicode 表中的另一個(gè)碼位。應(yīng)用程序和庫(kù)可以在檢測(cè)到 Unicode 錯(cuò)誤時(shí)使用它。
如果將碼位的一半切掉,那么另一半也就沒(méi)什么用了,除了顯示錯(cuò)誤。這時(shí)就會(huì)使用?。
JS 版本
const text = "前端柒八九";
const encoder = new TextEncoder();
const bytes = encoder.encode(text);
const partial = bytes.slice(0, 11);
const decoder = new TextDecoder("UTF-8");
const result = decoder.decode(partial);
console.log(result); // 輸出 "前端柒?"Rust 版本
fn main() {
let text = "前端柒八九";
let bytes = text.as_bytes();
let partial = &bytes[0..11];
let result = String::from_utf8_lossy(partial);
println!("{}", result); // 輸出 "前端柒?"
}在 JavaScript 中使用 TextEncoder 和 TextDecoder 來(lái)處理編碼,而在 Rust 中使用 String::from_utf8_lossy 來(lái)處理字節(jié)。它們的目標(biāo)是在 UTF-8 編碼中處理文本并「截取部分字節(jié)」。
4. UTF-32 問(wèn)題
UTF-32 非常適用于處理碼位。它的編碼方式中,「每個(gè)碼位始終是 4 個(gè)字節(jié)」,那么strlen(s) == sizeof(s) / 4,substring(0, 3) == bytes[0, 12](上面代碼為偽代碼)等等。
問(wèn)題在于,我們不想處理碼位。一個(gè)碼位即「不是一個(gè)書寫單位」,又并「不總是代表一個(gè)字符」。我們應(yīng)該處理的是擴(kuò)展形素簇(extended grapheme clusters),或簡(jiǎn)稱為形素(graphemes)。
形素是在特定書寫系統(tǒng)的上下文中的「最小可區(qū)分」的書寫單位。
例如,? 是一個(gè)形素,e?也是一個(gè)形素。還有像?這樣的形素。基本上,「形素是用戶認(rèn)為是一個(gè)字符的單元」。
問(wèn)題是,在 Unicode 中,一些形素是由「多個(gè)碼位編碼」的!
 圖片
圖片
例如,e?(一個(gè)單一的形素)在 Unicode 中編碼為 e(U+0065 拉丁小寫字母 E)+ ′(U+0301 連接重音符)。兩個(gè)碼位!
它也可能不止兩個(gè):
- ?? 是 U+2639 + U+FE0F
- ???? 是 U+1F468 + U+200D + U+1F3ED
- ????♀? 是 U+1F6B5 + U+1F3FB + U+200D + U+2640 + U+FE0F
- y?????????? 是 U+0079 + U+0316 + U+0320 + U+034D + U+0318 + U+0347 + U+0357 + U+030F + U+033D + U+030E + U+035E
即使在最寬的編碼 UTF-32 中,???? 仍需要「三個(gè) 4 字節(jié)單元」來(lái)進(jìn)行編碼。它仍然需要被「視為一個(gè)單獨(dú)的字符」。
我們可以將 Unicode 本身(沒(méi)有任何編碼)視為「可變長(zhǎng)度」的。
擴(kuò)展形素簇(Extended Grapheme Cluster)是「一個(gè)或多個(gè) Unicode 碼位的序列」,必須將其視為「一個(gè)單獨(dú)的、不可分割的字符。
因此,在「碼位級(jí)別」上:「不能只取序列的一部分,它總是應(yīng)該作為一個(gè)整體選擇、復(fù)制、編輯或刪除」。
不正確使用形素簇會(huì)導(dǎo)致像這樣的錯(cuò)誤:
無(wú)論是否選擇UTF-32還是UTF-8在處理形素上遇到相似的問(wèn)題。所以如何使用形素才是我們應(yīng)該關(guān)心的。
5. Unicode 病癥
上面的例子中大部分都是涉及到表情符號(hào),這會(huì)給人一種錯(cuò)覺(jué)。Unicode只有在表示表情符號(hào)時(shí),會(huì)遇到問(wèn)題。--其實(shí)不是。
擴(kuò)展形素簇也用于常見(jiàn)的語(yǔ)言。
例如:
- ?(德語(yǔ))是一個(gè)單一字符,但包含多個(gè)碼位(U+006F U+0308)。
- ??(立陶宛語(yǔ))是 U+00E1 U+0328。
- ?(韓語(yǔ))是 U+1100 U+1161 U+11A8。
所以,問(wèn)題不僅僅是表情符號(hào)。
"????♂?".length 是多少?
不同的編程語(yǔ)言給出了不同的結(jié)果。
Python 3:
>>> len("????♂?")
5JavaScript / Java / C#:
>> "????♂?".length
7Rust:
println!("{}", "????♂?".len());
// => 17不同的語(yǔ)言使用不同的「內(nèi)部字符串」表示(UTF-32、UTF-16、UTF-8),并以存儲(chǔ)字符的單位(整數(shù)、短整數(shù)、字節(jié))來(lái)報(bào)告長(zhǎng)度。
但是!如果你問(wèn)任何不懂編程理論的人,他們會(huì)給你一個(gè)明確的答案:????♂? 字符串的長(zhǎng)度是 1。
這就是擴(kuò)展形素簇的意義:「人們視為單一字符的內(nèi)容」。在這種情況下,????♂? 顯然是一個(gè)單一字符。
????♂? 由 5 個(gè)碼位組成(U+1F926 U+1F3FB U+200D U+2642 U+FE0F)僅僅是「實(shí)現(xiàn)細(xì)節(jié)」。它不應(yīng)該被分開(kāi),「不應(yīng)該被計(jì)為多個(gè)字符」,文本光標(biāo)不應(yīng)該定位在其中,不應(yīng)該被部分選擇,等等。
這是「文本的一個(gè)不可分割的單位」。在內(nèi)部,它可以被編碼為任何形式,但對(duì)于面向用戶的 API,應(yīng)該將其視為一個(gè)整體。
唯一正確處理此問(wèn)題的現(xiàn)代語(yǔ)言是 Swift:
print("????♂?".count)
// => 1而對(duì)于我們比較熟悉的JS和Rust,我們可以使用一些方式做一下封裝。
function visibleLength(str) {
return [...new Intl.Segmenter().segment(str)].length;
}
visibleLength("????♂?"); // 輸出結(jié)果為1當(dāng)然,我們還可以校驗(yàn)其他的形素。
visibleLength("?"); // => 1
visibleLength("????"); // => 1
visibleLength("????????????"); // => 2
visibleLength("と日本語(yǔ)の文章"); // => 7但是呢,Intl.Segmenter的兼容性不是很好。
如果,我們要實(shí)現(xiàn)多瀏覽器適配,我們可以找一些第三方的庫(kù)。
- graphemer[3]
- text-segmentation[4]
如果想了解更多細(xì)節(jié),可以參考JS 如何正確處理 Unicode[5]
對(duì)于Rust我們可以使用unicode_segmentation[6]crate。
extern crate unicode_segmentation; // "1.9.0"
use std::collections::HashSet;
use unicode_segmentation::UnicodeSegmentation;
fn count_unique_grapheme_clusters(s: &str) -> usize {
let is_extended = true;
s.graphemes(is_extended).collect::<HashSet<_>>().len()
}
fn main() {
assert_eq!(count_unique_grapheme_clusters(""), 0);
assert_eq!(count_unique_grapheme_clusters("????♂?"), 1);
assert_eq!(count_unique_grapheme_clusters("????"), 1);
}6. 如何檢測(cè)擴(kuò)展形素簇
大多數(shù)編程語(yǔ)言選擇了簡(jiǎn)單的方式,允許我們迭代字符串時(shí)使用 1-2-4 字節(jié)的塊,但「不支持直接處理擴(kuò)展形素簇」。
由于它是默認(rèn)方式,結(jié)果我們看到了損壞的字符串:
 圖片
圖片
如果遇到這種問(wèn)題,我們首先的就是應(yīng)該想到使用Unicode 庫(kù)。
使用庫(kù)
即使是像 strlen、indexOf 或 substring 這樣的基本操作也應(yīng)該使用 Unicode 庫(kù)!
例如:
- C/C++/Java:使用 ICU[7]。這是 Unicode 自身發(fā)布的庫(kù),包含了關(guān)于文本分割的所有規(guī)則。
- Swift:只需使用標(biāo)準(zhǔn)庫(kù)。Swift 默認(rèn)情況下會(huì)正確處理。
- Javascript的話,我們上面提到過(guò),可以使用瀏覽器內(nèi)置功能Intl.Segmenter或者graphemer/text-segmentation
- Rust而言,我們可以使用unicode_segmentation
不管選擇哪種方式,確保它使用的是「新版本」的 Unicode,因?yàn)樾嗡氐亩x會(huì)隨版本而變化。
Unicode 規(guī)則更新
從大約 2014 年開(kāi)始,Unicode 每年都會(huì)發(fā)布其標(biāo)準(zhǔn)的重大修訂版本。
每年更新
 圖片
圖片
隨之而來(lái)的不良反映就是,定義形素簇的規(guī)則每年也會(huì)發(fā)生變化。今天被認(rèn)為是由兩個(gè)或三個(gè)獨(dú)立碼位組成的序列,明天可能會(huì)成為一個(gè)形素簇!這種朝令夕改的做法,很是讓人深惡痛絕。
更糟糕的是,我們自己的應(yīng)用程序的不同版本可能運(yùn)行在不同的 Unicode 標(biāo)準(zhǔn)上,并報(bào)告不同的字符串長(zhǎng)度!
7. "A?" !== "?" !== "?"
將其中任何一個(gè)復(fù)制到你的 JavaScript 控制臺(tái):
"A?" === "?";
"?" === "?";
"A?" === "?";你會(huì)得到讓你匪夷所思的答案。沒(méi)錯(cuò),它們的打印結(jié)果都是false。
還記得之前的,? 是由兩個(gè)碼位組成,U+006F U+0308 。基本上,Unicode 提供了「多種」編寫字符如 ? 或 ? 的方式。
- 通過(guò)將普通的拉丁字母 A 與一個(gè)組合字符組合成 ?,
- 或者使用已經(jīng)預(yù)先組合的碼位 U+00C5。
因?yàn)椋鼈儭缚雌饋?lái)是相同」的(A? 與 ?),所以從用戶的角度,我們就「認(rèn)為它們應(yīng)該是相同」的,但結(jié)果卻和我們的想法大相徑庭。
這就是為什么我們需要規(guī)范化。有四種形式:
這里先從NFD和NFC介紹。
- NFD(Normalization Form C) 嘗試將一切都分解為最小可能的部分,并如果存在多個(gè)部分,則按照規(guī)范順序?qū)@些部分進(jìn)行排序。
它消除任何規(guī)范化差異,并生成一個(gè)「分解的結(jié)果」
- NFC(Normalization Form C),嘗試將一切組合成已經(jīng)預(yù)先組合的形式(如果存在)
它消除任何規(guī)范化差異,通常生成一個(gè)「合成的結(jié)果」
不同的形式用于不同的用例,以確保文本在不同的方式下都保持一致。所以,盡管"A?" !== "?" !== "?",但通過(guò)適當(dāng)?shù)囊?guī)范化,我們可以使它們等同。
 圖片
圖片
對(duì)于某些字符,Unicode 中還存在多個(gè)版本。例如,有 U+00C5 帶有上面環(huán)圈的拉丁大寫字母 A,但還有外觀相同的 U+212B ?ngstr?m 符號(hào)。
這些字符在規(guī)范化過(guò)程中也會(huì)被替換,以確保它們的一致性。
 圖片
圖片
NFD 和 NFC 被稱為“規(guī)范化規(guī)范”(canonical normalization)。另外兩種形式是“兼容規(guī)范化”(compatibility normalization):
- NFKD 試圖將「所有內(nèi)容分解」,并使用默認(rèn)形式替換視覺(jué)變體。
它消除規(guī)范化和兼容性差異,并生成一個(gè)分解的結(jié)果
- NFKC 試圖將「所有內(nèi)容組合」在一起,同時(shí)用默認(rèn)形式替換視覺(jué)變體。
它消除規(guī)范化和兼容性差異,并通常生成一個(gè)合成的結(jié)果
 圖片
圖片
視覺(jué)變體是表示相同字符的獨(dú)立 Unicode 碼位,但它們應(yīng)該呈現(xiàn)不同的方式。比如,①、? 或 ??。
 圖片
圖片
所有這些字符都有自己的碼位,但它們也都是Xs。
在比較字符串或搜索子字符串之前,進(jìn)行規(guī)范化!
`Unicode`規(guī)范化[8]傳送 ??
在JavaScript 中,我們可以使用 normalize() 方法來(lái)實(shí)現(xiàn) NFC(Normalization Form C)和 NFD(Normalization Form D)。
const str1 = "A?";
const str2 = "?";
const normalizedStr1 = str1.normalize("NFC"); // NFC 形式
const normalizedStr2 = str2.normalize("NFC"); // NFC 形式
console.log(normalizedStr1 === normalizedStr2); // true上述代碼首先使用 normalize('NFC') 方法將兩個(gè)字符串都轉(zhuǎn)換為 NFC 形式,然后比較它們是否相等。這將使 "A?" 和 "?" 的比較結(jié)果為 true。
如果使用 NFD 形式,只需將 normalize('NFC') 更改為 normalize('NFD') 即可。
8. Unicode 取決于區(qū)域設(shè)置
俄羅斯名字「尼古拉」
 圖片
圖片
在Unicode 中編碼為 U+041D 0438 043A 043E 043B 0430 0439。
保加利亞名字「尼古拉」
 圖片
圖片
也寫成 U+041D 0438 043A 043E 043B 0430 0439。
它們的Unicode值完全一樣,但是所顯示的字體信息卻不盡相同。是不是有種小腦萎縮的感覺(jué)。
然后心中有一個(gè) ??,計(jì)算機(jī)如何知道何時(shí)呈現(xiàn)保加利亞風(fēng)格的字形,何時(shí)使用俄羅斯的字形?
其實(shí),計(jì)算機(jī)也不知。Unicode 并不是一個(gè)完美的系統(tǒng),它有很多不足之處。其中一個(gè)問(wèn)題是「將本應(yīng)呈現(xiàn)不同外觀的字形分配給相同的碼位」,比如西里爾字母的小寫字母 K 和保加利亞的小寫字母 K(都是 U+043A)。
針對(duì)一些表音語(yǔ)言這塊還能好點(diǎn),但是到了我們大亞洲,很多國(guó)家的文字都是「表意」的。許多漢字、日語(yǔ)和韓語(yǔ)表意字形的寫法都截然不同,但被分配了相同的碼位。
 圖片
圖片
Unicode 的動(dòng)機(jī)是為了「節(jié)省碼位空間」。渲染信息應(yīng)該在字符串外部以區(qū)域設(shè)置/語(yǔ)言元數(shù)據(jù)的方式傳遞。
在實(shí)踐中,依賴于區(qū)域設(shè)置帶來(lái)了許多問(wèn)題:
- 作為元數(shù)據(jù),區(qū)域設(shè)置通常會(huì)丟失。
- 人們不限于使用「單一區(qū)域設(shè)置」。例如,我們可以閱讀和寫作中文,美國(guó)英語(yǔ)、英國(guó)英語(yǔ)、德語(yǔ)和俄語(yǔ)。
- 難以混合和匹配。比如在保加利亞文本中使用俄羅斯名字,反之亦然。
- 沒(méi)有地方可以指定區(qū)域設(shè)置。即使制作上面的兩個(gè)屏幕截圖也不容易,因?yàn)樵诖蠖鄶?shù)軟件中,沒(méi)有下拉菜單或文本輸入來(lái)更改區(qū)域設(shè)置。
9. 處理特殊語(yǔ)言
另一個(gè)不幸的例子是土耳其語(yǔ)中無(wú)點(diǎn) i 的 Unicode 處理。
與英語(yǔ)不同,土耳其語(yǔ)有兩種 I 變體:有點(diǎn)和無(wú)點(diǎn)。
Unicode 決定重用 ASCII 中的 I 和 i,并只添加了兩個(gè)新的碼位:? 和 ?。
這導(dǎo)致了在相同輸入上 toLowerCase/toUpperCase 表現(xiàn)不同:
var en_US = Locale.of("en", "US");
var tr = Locale.of("tr");
System.out.println("I".toLowerCase(en_US)); // => "i"
System.out.println("I".toLowerCase(tr)); // => "?"
System.out.println("i".toUpperCase(en_US)); // => "I"
System.out.println("i".toUpperCase(tr)); // => "?"所以,我們?cè)诓恢雷址怯媚姆N語(yǔ)言編寫的情況下將字符串轉(zhuǎn)換為小寫,會(huì)出現(xiàn)問(wèn)題。
如果我們項(xiàng)目中涉及到土耳其語(yǔ)的字符轉(zhuǎn)換,在 JS 中toLowerCase是達(dá)不到上面的要求的。因?yàn)椋贘avaScript中,toLowerCase方法默認(rèn)使用Unicode規(guī)范進(jìn)行轉(zhuǎn)換,根據(jù)Unicode的規(guī)范,大寫 I 被轉(zhuǎn)換為小寫 i,而不是 ?。這是因?yàn)镴avaScript的toLowerCase方法按照Unicode的標(biāo)準(zhǔn)工作。
要想使用JS正確處理上面的問(wèn)題,我們就需要額外的 API.
"I".toLocaleLowerCase("tr-TR"); // => "?"
"i".toLocaleUpperCase("tr-TR"); // => "?"我們也可以通過(guò)對(duì)String.prototype上做一層封裝。
String.prototype.turkishToUpper = function () {
var string = this;
var letters = { i: "?", ?: "?", ?: "?", ü: "ü", ?: "?", ?: "?", ?: "I" };
string = string.replace(/(([i???ü??]))+/g, function (letter) {
return letters[letter];
});
return string.toUpperCase();
};
String.prototype.turkishToLower = function () {
var string = this;
var letters = { ?: "i", I: "?", ?: "?", ?: "?", ü: "ü", ?: "?", ?: "?" };
string = string.replace(/(([?I??ü??]))+/g, function (letter) {
return letters[letter];
});
return string.toLowerCase();
};
// 代碼演示
"D?N?".turkishToLower(); // => din?
"DIN?".turkishToLower(); // => d?n?這樣就可以正確規(guī)避JS針對(duì)土耳其語(yǔ)言中的準(zhǔn)換問(wèn)題。
在Rust中,我們可以使用如下代碼:
fn turkish_to_upper(input: &str) -> String {
let letters = [
('i', "?"),
('?', "?"),
('?', "?"),
('ü', "ü"),
('?', "?"),
('?', "?"),
('?', "I"),
];
let mut result = String::new();
for c in input.chars() {
let mut found = false;
for &(source, target) in &letters {
if c == source {
result.push_str(target);
found = true;
break;
}
}
if !found {
result.push(c);
}
}
result.to_uppercase()
}
fn turkish_to_lower(input: &str) -> String {
let letters = [
('?', "i"),
('I', "?"),
('?', "?"),
('?', "?"),
('ü', "ü"),
('?', "?"),
('?', "?"),
];
let mut result = String::new();
for c in input.chars() {
let mut found = false;
for &(source, target) in &letters {
if c == source {
result.push_str(target);
found = true;
break;
}
}
if !found {
result.push(c);
}
}
result.to_lowercase()
}
fn main() {
let input = "???ü???";
let upper_result = turkish_to_upper(input);
let lower_result = turkish_to_lower(input);
println!("Upper: {}", upper_result); //Upper: ???ü??I
println!("Lower: {}", lower_result); // Lower: i??ü???
}Reference
[1]ASCII:https://cikgucandoit.wordpress.com/what-is-ascll/
[2]Emoji 簡(jiǎn)介:https://www.ruanyifeng.com/blog/2017/04/emoji.html
[3]graphemer:https://github.com/flmnt/graphemer
[4]text-segmentation:https://github.com/niklasvh/text-segmentation
[5]JS 如何正確處理 Unicode:https://flaviocopes.com/javascript-unicode/
[6]unicode_segmentation:https://docs.rs/unicode-segmentation/latest/unicode_segmentation/
[7]ICU:https://github.com/unicode-org/icu
[8]Unicode規(guī)范化:https://www.unicode.org/glossary/