













從Postgres到ScyllaDB NoSQL,速度提升349倍
譯文譯者 | 布加迪
審校 | 重樓
速度對于Coralogix而言很重要,這是一個開發團隊信任的可觀測性平臺,可以及時發現問題。Coralogix使用了實時流分析管道,提供了監控、可視化和警報等功能,無需索引。
Coralogix主要的差異化優勢之一是分布式查詢引擎,可以快速查詢遠程存儲的客戶歸檔中的映射數據。該引擎使用特殊的Parquet格式查詢存儲在對象存儲(Google Cloud Storage或S3)中的半結構化數據。它最初是底層對象存儲上的無狀態查詢引擎,但是在查詢執行期間讀取Parquet元數據帶來了不可接受的延遲影響。為了克服這個問題,團隊開發了一個元數據存儲(簡稱為“Metastore”),以便更快地檢索和處理執行大型查詢所需的Parquet元數據。
最初的Metastore實現建立在PostgreSQL之上,速度不夠快,無法滿足該公司的需求。因此,團隊嘗試了一種新的實現:這次使用ScyllaDB,嘗試取得了成功。團隊取得了顯著的性能提升——查詢處理時間從30秒縮短到86毫秒。不妨深入了解一下他們是如何做到這一點的,并了解一下他們計劃如何使用WebAssembly用戶定義函數(UDF)和Rust進一步優化它。
Metastore動機和需求
在討論Metastore實現細節之前,不妨先介紹一下當初構建Metastore的理由。
Coralogix的首席軟件工程師Dan Harris解釋道:“我們最初將這個平臺設計為底層對象存儲之上的無狀態查詢引擎,但我們很快意識到,查詢執行期間讀取Parquet元數據的成本占查詢時間的很大一部分。”他們意識到,可以通過將Parquet元數據放在一個可以快速查詢的快速存儲系統中(而不是直接從底層對象存儲讀取和處理Parquet元數據),加快速度。
他們設想的解決方案具有以下功能:
- 以分解格式存儲Parquet元數據,從而獲得高擴展性和高吞吐量。
- 使用布隆過濾器,有效地識別每個查詢要掃描的文件。
- 使用事務提交日志以事務性方式添加、更新和替換底層對象存儲中的現有數據。
關鍵需求包括低延遲、讀/寫容量方面的可擴展性以及底層存儲的可擴展性。為了理解所需的極端可擴展性,請考慮這種情況:單單一個客戶每小時生成2000個Parquet文件(每天50000個),總計每天15TB,因此單單一天僅Parquet元數據就有20GB。
最初的PostgreSQL實現
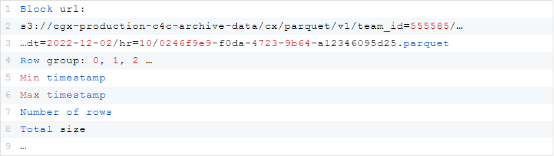
Harris承認:“我們在Postgres上開始了最初的實現,當時我們明白從長遠來看,非分布式引擎是不夠的。”最初的實現存儲諸如塊(block)之類的關鍵信息,表示一行組和一個Parquet文件。這包括元數據,比如文件的URL、行組索引和關于文件的少量細節。比如說:
為了優化讀取操作,他們使用了布隆過濾器進行高效的數據修剪。Harris解釋道:“最終,我們希望支持全文搜索之類的操作。大致來說,當我們將這些文件攝取到系統中時,可以為我們在文件中找到的所有不同的令牌構建一個布隆過濾器。然后,根據特定的查詢,我們可以使用這些布隆過濾器來修剪我們需要掃描的數據。”
他們將布隆過濾器存儲在塊分割的環境中,將它們分成32字節大小的塊,以便高效檢索。它們獨立存儲,因此系統不必在查詢時讀取整個布隆過濾器。

此外,它們為每個Parquet文件存儲列元數據。比如說:

Harris解釋:“我們寫入的文件內容相當寬,有時多達2萬列。因此,如果只讀取我們需要的元數據,就可以真正減少任何特定查詢所需的IO數量。”
ScyllaDB實現
接下來,不妨看看由Harris的同事、Coralogix的高級軟件工程師Sebastian Vercruysse概述的ScyllaDB實現。
塊數據建模
為了新的實現,必須重新考慮塊建模。這里有一個塊URL的例子:s3://cgx-production-c4c-archive-data/cx/parquet/v1/team_id=555585/…
…dt = 2022-12-02 / hr = 10/0246f9e9-f0da-4723-9b64 a12346095d25.parquet
粗體部分是客戶的頂層存儲桶;在存儲桶內,各項按小時劃分。在這種情況下,應該使用什么作為主鍵?
- (表url)?但有些客戶比其他客戶擁有更多的Parquet文件,他們希望保持平衡。
- ((塊url,行組))?這標識了特定塊的獨特身份,但是很難列出某一天的所有塊,因為時間戳不在鍵中。
- ((表url,小時))?這很管用,因為如果你有24小時的查詢時間,就很容易查詢。
- ((表url,小時),塊url,行組)?這是他們選擇的。通過將塊URL和行組添加為聚簇鍵,他們可以在一小時內輕松檢索某個特定塊,這也簡化了更新或刪除塊和行組的過程。
布隆過濾器分塊和數據建模
下一個挑戰是:考慮到ScyllaDB沒有提供相應的開箱即用功能,如何驗證某些位是否已設置。團隊決定讀取布隆過濾器,并在應用程序中處理它們。不過記住,他們每天為每個客戶處理多達50000個塊,每個塊含有布隆過濾器部分的262KB。總共是12GB——對于一個查詢來說太大了,無法拉回到應用程序中。但他們不需要每次都讀取整個布隆過濾器,只需要其中的一部分,這取決于查詢執行期間涉及的令牌。因此,他們最終將布隆過濾器分成幾行,這將讀取的數據減少到易于管理的1.6 MB。
對于數據建模,一種選擇是使用((block_url, row_group),塊索引)作為主鍵。這將為每個布隆過濾器生成8192個32字節的塊,從而生成每個分區約262 KB的均勻分布。對于同一分區中的每個布隆過濾器,使用單個批處理查詢就可以輕松插入和刪除數據。但是有一個問題會影響讀取效率:在讀取布隆過濾器之前,您需要知道塊的ID。此外,該方法需要訪問大量的分區;5萬個塊意味著5萬個分區。正如Vercruysse特別指出:“就算使用像ScyllaDB這樣快的技術,仍然很難為5萬個分區實現亞秒級處理。”
另一個選項(這也是他們最終決定的):((表url,小時,塊索引),塊url,行組)。請注意,這是與塊相同的分區鍵,只是在分區鍵上添加了一個索引,該索引表示查詢引擎所需的第n個令牌。使用這種方法,掃描24小時時間窗口的5個令牌可生成120個分區——與之前的數據建模選項相比,這個改進很出色。
此外,這種方法在讀取布隆過濾器之前不再需要塊ID,從而允許更快的讀取。當然,總存在不足之處。在這里,由于阻塞布隆過濾器方法,他們不得不將單個布隆過濾器拆分為8192個獨特分區。與之前允許一次攝取所有布隆過濾器塊的分區方法相比,這最終限制了攝取速度。然而,能夠在一小時內快速讀取某個塊比快速寫入來得更重要,因此他們認為這種取舍是值得的。
數據建模問題
毫不奇怪,從SQL遷移到NoSQL需要大量的數據建模返工,包括一些試錯。比如說,Vercruysse表示:“有一天,我認識到我們弄亂了最小和最大時間戳——我想知道我該如何修復它。我想也許可以重命名這些列,然后讓它重新運行。但是,如果列是聚簇鍵的一部分,你就無法重命名列。我想也許可以添加新列并運行UPDATE查詢來更新所有行。遺憾的是,這在NoSQL中也行不通。”

最終,他們決定截斷表并重新開始,而不是編寫遷移代碼。在這方面,他們給出的最好建議是第一次就把事情做好。
性能提升
盡管需要進行數據建模工作,但遷移收到了很好的成效。對于Metastore塊列表:
- 每個節點當前處理4到5 TB的數據。
- 他們目前每秒處理大約1萬個寫入操作,P99延遲始終低于1毫秒。
- 塊列表在一小時內生成了大約2000個Parquet文件;就布隆過濾器而言,他們的處理時間不到20毫秒。對于5萬個文件,處理時不到500毫秒。
他們還執行了位校驗。但是對于5萬個Parquet文件而言,500毫秒可以滿足需求。
在列元數據處理中,P50相當不錯,但尾部延遲較高。Vercruysse解釋:“問題在于,如果我們有5萬個Parquet文件,我們的執行器會并行獲取所有這些文件。這意味著我們有很多并發查詢,我們沒有使用最好的磁盤。我們認為這是問題的根源。”
ScyllaDB設置
值得注意的是,Coralogix從最初發現ScyllaDB到部署到擁有TB級數據的生產環境僅用了兩個月(這是需要數據建模工作的SQL到NoSQL遷移,而不是簡單得多的Cassandra或DynamoDB遷移)。
實現是在ScyllaDB Rust驅動程序上用Rust編寫的,他們發現ScyllaDB Operator for Kubernetes、ScyllaDB Monitoring和ScyllaDB Manager都對快速遷移大有幫助。由于為他們自己的客戶提供低成本的可觀測性替代方案對Coralogix很重要,因此團隊對他們的ScyllaDB基礎設施的性價比感到滿意,一個三節點聚簇有以下配置:
- 8個vCPU
- 32 GB內存
- Arm/Graviton
- 帶寬為500mbps、IOPS為12k的EBS卷(gp3)
使用ARM可以降低成本,而決定使用彈性塊存儲(EBS)(gp3)卷最終歸結為可用性、靈活性和性價比。他們承認:“這是一個有爭議的決定,但我們正在努力讓它切實可行,我們會看看我們能堅持多久。”
汲取的經驗
他們在這里學到的主要經驗是:
- 注意分區大小:使用ScyllaDB與使用Postgres的最大區別是,您必須非常仔細地考慮分區和分區大小。有效的分區和聚簇鍵選擇對性能有很大的影響。
- 考慮讀/寫模式:您還必須仔細考慮讀/寫模式。您的工作負載是不是讀取密集型?它是否涉及搭配均衡的讀寫操作?或者,以寫入操作為主?Coralogix的工作負載有大量的寫入操作,就因為他們不斷地攝取數據,但需要優先考慮讀取操作,因為讀取延遲對業務來說最關鍵。
- 避免EBS:團隊承認他們被警告不要使用EBS:“我們沒有聽從,但我們可能應該聽從。如果您在考慮使用ScyllaDB,那么查看具有本地SSD的實例而不是嘗試使用EBS卷可能是好主意。”
未來計劃:結合使用WebAssembly UDF和Rust
將來,他們希望在寫入足夠大的塊和讀取不必要的數據之間找到折衷。他們將數據塊分成大約8000行,認為可以進一步劃分成1000行,這有望加快插入速度。
他們的最終目標是通過充分利用WebAssembly的用戶定義函數(UDF),將更多的工作交給ScyllaDB處理。使用現有的Rust代碼,集成UDF將不需要把數據發回給應用程序,為分塊調整和潛在的改進提供了靈活性。
Vercruysse表示:“我們已經用Rust編寫了所有內容。如果我們可以開始使用UDF,這樣我們不必向應用程序發回任何其他內容。這給了我們更大的余地來處理分塊。”
原文標題:From Postgres to ScyllaDB NoSQL, with a 349x Speed Boost,作者:Cynthia Dunlop





















