深入探討 C++ 多線程性能優(yōu)化
作者 | weiqiangwu
在現(xiàn)代軟件開發(fā)中,多線程編程已成為提升應(yīng)用程序性能和響應(yīng)速度的關(guān)鍵技術(shù)之一。尤其在C++領(lǐng)域,多線程編程不僅能充分利用多核處理器的優(yōu)勢(shì),還能顯著提高計(jì)算密集型任務(wù)的效率。然而,多線程編程也帶來了諸多挑戰(zhàn),特別是在性能優(yōu)化方面。本文將深入探討影響C++多線程性能的一些關(guān)鍵因素,比較鎖機(jī)制與原子操作的性能。通過這些內(nèi)容,希望能為開發(fā)者提供有價(jià)值的見解和實(shí)用的優(yōu)化策略,助力于更高效的多線程編程實(shí)踐。

先在開頭給一個(gè)例子,你認(rèn)為下面這段benchmark代碼結(jié)果會(huì)是怎樣的。這里的邏輯很簡(jiǎn)單,將0-20000按線程切成n片,每個(gè)線程在一個(gè)Set里查找這個(gè)數(shù)字存不存在,存在則計(jì)數(shù)+1。
#include <benchmark/benchmark.h>
#include <iostream>
#include <memory>
#include <mutex>
#include <unordered_set>
constexpr int kSetSize = 10000;
class MyBenchmark : public benchmark::Fixture {
public:
void SetUp(const ::benchmark::State& state) override {
std::call_once(flag, [this]() {
s = std::make_shared<std::unordered_set<int>>();
for (int i = 0; i < kSetSize; i++) {
s->insert(i);
}
});
}
std::shared_ptr<std::unordered_set<int>> GetSet() { return s; }
private:
std::shared_ptr<std::unordered_set<int>> s;
std::once_flag flag;
};
BENCHMARK_DEFINE_F(MyBenchmark, MultiThreadedWork)(benchmark::State& state) {
for (auto _ : state) {
int size_sum = kSetSize * 2;
int size_per_thread = (size_sum + state.threads() - 1) / state.threads();
int sum = 0;
int start = state.thread_index() * size_per_thread;
int end = std::min((state.thread_index() + 1) * size_per_thread, size_sum);
for (int i = start; i < end; i++) {
auto inst = GetSet();
if (inst->count(i) > 0) {
sum++;
}
}
}
}
// 注冊(cè)基準(zhǔn)測(cè)試,并指定線程數(shù)
BENCHMARK_REGISTER_F(MyBenchmark, MultiThreadedWork)->Threads(1);
BENCHMARK_REGISTER_F(MyBenchmark, MultiThreadedWork)->Threads(2);
BENCHMARK_REGISTER_F(MyBenchmark, MultiThreadedWork)->Threads(4);
BENCHMARK_REGISTER_F(MyBenchmark, MultiThreadedWork)->Threads(8);
BENCHMARK_MAIN();跑出來的結(jié)果如下:

將任務(wù)切分成多個(gè)片段并交由多線程執(zhí)行后,整體性能不僅沒有提升,反而下降了,且性能與線程數(shù)成反比。那么,問題來了:導(dǎo)致這種結(jié)果的原因是什么?如何才能實(shí)現(xiàn)合理的并行執(zhí)行,從而降低CPU的執(zhí)行時(shí)間?在接下來的部分,筆者將為你揭示答案。
影響多線程性能的因素
筆者認(rèn)為,影響多線程性能的主要因素有以下兩個(gè):
- Lock Contention
- Cache Coherency
Lock Contention對(duì)應(yīng)使用鎖來處理多線程同步問題的場(chǎng)景,而Cache Coherency則對(duì)應(yīng)使用原子操作來處理多線程同步問題的場(chǎng)景。
1.Lock Contention
在多線程環(huán)境中,多個(gè)線程同時(shí)嘗試獲取同一個(gè)鎖(Lock)時(shí),會(huì)發(fā)生競(jìng)爭(zhēng)現(xiàn)象,這就是所謂的鎖競(jìng)爭(zhēng)(Lock Contention)。鎖競(jìng)爭(zhēng)會(huì)導(dǎo)致線程或進(jìn)程被阻塞,等待鎖被釋放,從而影響系統(tǒng)的性能和響應(yīng)時(shí)間。大多數(shù)情況下,開發(fā)人員會(huì)選擇使用鎖來解決線程間的同步問題,因此鎖競(jìng)爭(zhēng)問題也變得廣為人知且容易理解。由于鎖的存在,位于臨界區(qū)的代碼在同一時(shí)刻只能由一個(gè)線程執(zhí)行。因此,優(yōu)化的思路就是盡量避免多個(gè)線程同時(shí)訪問同一資源。常見的優(yōu)化方向有兩種:
- 減少臨界區(qū)大小:臨界區(qū)越小,這段代碼的執(zhí)行時(shí)間就越短,從而在整體程序運(yùn)行時(shí)間中所占的比例也越小,沖突也就越少。?
- 對(duì)共享資源進(jìn)行分桶操作:每個(gè)線程只會(huì)在某個(gè)桶上訪問資源,理想情況下,每個(gè)線程都會(huì)訪問不同的桶,這樣就不會(huì)有沖突。
減少臨界區(qū)大小需要開發(fā)者對(duì)自己的代碼進(jìn)行仔細(xì)思考,將不必要的操作放在臨界區(qū)外,例如一些初始化和內(nèi)存分配操作。
對(duì)共享資源進(jìn)行分桶操作在工程實(shí)踐中也非常常見。例如,LevelDB的LRUCache中,每個(gè)Key只會(huì)固定在一個(gè)桶上。如果hash函數(shù)足夠優(yōu)秀且數(shù)據(jù)分布足夠隨機(jī),這種方法可以大大提高LRUCache的性能。
2.Cache Coherency
緩存一致性(Cache Coherency)是指在多處理器系統(tǒng)中,確保各個(gè)處理器的緩存中的數(shù)據(jù)保持一致的機(jī)制。由于現(xiàn)代計(jì)算機(jī)系統(tǒng)通常包含多個(gè)處理器,每個(gè)處理器都有自己的緩存(如L1、L2、L3緩存),因此在并發(fā)訪問共享內(nèi)存時(shí),可能會(huì)出現(xiàn)緩存數(shù)據(jù)不一致的問題。緩存一致性協(xié)議旨在解決這些問題,確保所有處理器在訪問共享內(nèi)存時(shí)看到的是一致的數(shù)據(jù)。
當(dāng)我們對(duì)一個(gè)共享變量進(jìn)行寫入操作時(shí),實(shí)際上需要通過緩存一致性協(xié)議將該變量的更新同步到其他線程的緩存中,否則可能會(huì)讀到不一致的值。實(shí)際上,這個(gè)同步過程的單位是一個(gè)緩存行(Cache Line),而且同步過程相對(duì)較慢,因?yàn)樯婕暗娇绾送ㄐ拧?/p>
由此引申出兩個(gè)嚴(yán)重影響性能的現(xiàn)象:
- Cache Ping-Pong?
- False Sharing
(1) Cache Ping-Pong
緩存乒乓效應(yīng)(Cache Ping-Pong)是指在多處理器系統(tǒng)中,多個(gè)處理器頻繁地對(duì)同一個(gè)緩存行(Cache Line)進(jìn)行讀寫操作,導(dǎo)致該緩存行在不同處理器的緩存之間頻繁地來回傳遞。這種現(xiàn)象會(huì)導(dǎo)致系統(tǒng)性能下降,因?yàn)榫彺嫘械念l繁傳遞會(huì)引起大量的緩存一致性流量和處理器間通信開銷。
講到這里,其實(shí)就可以解釋為什么開頭那段代碼會(huì)隨著線程數(shù)量的增加而性能反而下降。代碼中的變量 s 是一個(gè)共享資源,但它使用了 shared_ptr。在復(fù)制 shared_ptr 時(shí),會(huì)引起引用計(jì)數(shù)的增加(計(jì)數(shù)+1),多個(gè)線程頻繁對(duì)同一個(gè)緩存行進(jìn)行讀寫操作,從而引發(fā)緩存乒乓效應(yīng),導(dǎo)致性能下降。最簡(jiǎn)單的修改方式就是去掉 shared_ptr,代碼如下,同時(shí)還可以得到我們預(yù)期的結(jié)果,即CPU時(shí)間隨著線程數(shù)的增加而降低:
#include <benchmark/benchmark.h>
#include <iostream>
#include <memory>
#include <mutex>
#include <unordered_set>
constexpr int kSetSize = 10000;
class MyBenchmark : public benchmark::Fixture {
public:
void SetUp(const ::benchmark::State& state) override {
std::call_once(flag, [this]() {
for (int i = 0; i < kSetSize; i++) {
s.insert(i);
}
});
}
const std::unordered_set<int>& GetSet() { return s; }
private:
std::unordered_set<int> s;
std::once_flag flag;
};
BENCHMARK_DEFINE_F(MyBenchmark, MultiThreadedWork)(benchmark::State& state) {
for (auto _ : state) {
int size_sum = kSetSize * 2;
int size_per_thread = (size_sum + state.threads() - 1) / state.threads();
int sum = 0;
int start = state.thread_index() * size_per_thread;
int end = std::min((state.thread_index() + 1) * size_per_thread, size_sum);
for (int i = start; i < end; i++) {
const auto& inst = GetSet();
if (inst.count(i) > 0) {
benchmark::DoNotOptimize(sum++);
}
}
}
}
// 注冊(cè)基準(zhǔn)測(cè)試,并指定線程數(shù)
BENCHMARK_REGISTER_F(MyBenchmark, MultiThreadedWork)->Threads(1);
BENCHMARK_REGISTER_F(MyBenchmark, MultiThreadedWork)->Threads(2);
BENCHMARK_REGISTER_F(MyBenchmark, MultiThreadedWork)->Threads(4);
BENCHMARK_REGISTER_F(MyBenchmark, MultiThreadedWork)->Threads(8);
BENCHMARK_MAIN();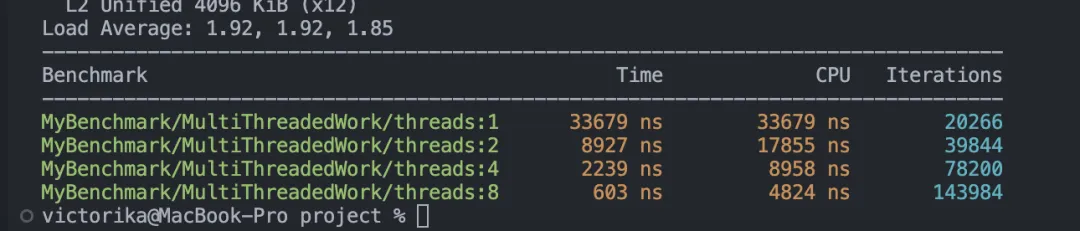
(2) False Sharing
偽共享(False Sharing)實(shí)際上是一種特殊的緩存乒乓效應(yīng)(Cache Ping-Pong)。它指的是在多處理器系統(tǒng)中,多個(gè)處理器訪問不同的數(shù)據(jù),但這些數(shù)據(jù)恰好位于同一個(gè)緩存行中,導(dǎo)致該緩存行在不同處理器的緩存之間頻繁傳遞。盡管處理器訪問的是不同的數(shù)據(jù),但由于它們共享同一個(gè)緩存行,仍然會(huì)引發(fā)緩存一致性流量,導(dǎo)致性能下降。
為了更好地理解這一現(xiàn)象,我們可以對(duì)上面的代碼進(jìn)行一些修改。假設(shè)我們使用一個(gè) vector<atomic> 來記錄不同線程的 sum 值,這樣雖然不同線程修改的是不同的sum,但是還是在一個(gè)緩存行上。使用 atomic 是為了強(qiáng)制觸發(fā)緩存一致性協(xié)議,否則操作系統(tǒng)可能會(huì)進(jìn)行優(yōu)化,不會(huì)立即將修改反映到主存。
#include <benchmark/benchmark.h>
#include <atomic>
#include <iostream>
#include <memory>
#include <mutex>
#include <unordered_set>
constexpr int kSetSize = 10000;
class MyBenchmark : public benchmark::Fixture {
public:
void SetUp(const ::benchmark::State& state) override {
std::call_once(flag, [this, &state]() {
for (int i = 0; i < kSetSize; i++) {
s.insert(i);
}
sums = std::vector<std::atomic<int>>(state.threads());
});
}
const std::unordered_set<int>& GetSet() { return s; }
std::vector<std::atomic<int>>& GetSums() { return sums; }
private:
std::unordered_set<int> s;
std::once_flag flag;
std::vector<std::atomic<int>> sums;
};
BENCHMARK_DEFINE_F(MyBenchmark, MultiThreadedWork)(benchmark::State& state) {
for (auto _ : state) {
int size_sum = kSetSize;
int size_per_thread = (size_sum + state.threads() - 1) / state.threads();
int sum = 0;
int start = state.thread_index() * size_per_thread;
int end = std::min((state.thread_index() + 1) * size_per_thread, size_sum);
for (int i = start; i < end; i++) {
const auto& inst = GetSet();
if (inst.count(i) > 0) {
benchmark::DoNotOptimize(GetSums()[state.thread_index()]++);
}
}
}
}
// 注冊(cè)基準(zhǔn)測(cè)試,并指定線程數(shù)
BENCHMARK_REGISTER_F(MyBenchmark, MultiThreadedWork)->Threads(1);
BENCHMARK_REGISTER_F(MyBenchmark, MultiThreadedWork)->Threads(2);
BENCHMARK_REGISTER_F(MyBenchmark, MultiThreadedWork)->Threads(4);
BENCHMARK_REGISTER_F(MyBenchmark, MultiThreadedWork)->Threads(8);
BENCHMARK_MAIN();
可以看到,盡管不同線程沒有使用同一個(gè)變量,但由于 sums 里面的元素共享同一個(gè)緩存行(Cache Line),同樣會(huì)導(dǎo)致性能急劇下降。
針對(duì)這種情況,只要我們將 sums 中的元素隔離,使它們不在同一個(gè)緩存行上,就不會(huì)引發(fā)這個(gè)問題。一般來說,緩存行的大小為64字節(jié),我們可以使用一個(gè)類填充到64個(gè)字節(jié)來實(shí)現(xiàn)隔離。優(yōu)化后的代碼如下:
#include <benchmark/benchmark.h>
#include <atomic>
#include <iostream>
#include <memory>
#include <mutex>
#include <unordered_set>
constexpr int kSetSize = 10000;
struct alignas(64) PaddedCounter {
std::atomic<int> value{0};
char padding[64 - sizeof(std::atomic<int>)]; // 填充到緩存行大小
};
class MyBenchmark : public benchmark::Fixture {
public:
void SetUp(const ::benchmark::State& state) override {
std::call_once(flag, [this, &state]() {
for (int i = 0; i < kSetSize; i++) {
s.insert(i);
}
sums = std::vector<PaddedCounter>(state.threads());
});
}
const std::unordered_set<int>& GetSet() { return s; }
std::vector<PaddedCounter>& GetSums() { return sums; }
private:
std::unordered_set<int> s;
std::once_flag flag;
std::vector<PaddedCounter> sums;
};
BENCHMARK_DEFINE_F(MyBenchmark, MultiThreadedWork)(benchmark::State& state) {
for (auto _ : state) {
int size_sum = kSetSize;
int size_per_thread = (size_sum + state.threads() - 1) / state.threads();
int sum = 0;
int start = state.thread_index() * size_per_thread;
int end = std::min((state.thread_index() + 1) * size_per_thread, size_sum);
for (int i = start; i < end; i++) {
const auto& inst = GetSet();
if (inst.count(i) > 0) {
benchmark::DoNotOptimize(GetSums()[state.thread_index()].value++);
}
}
}
}
// 注冊(cè)基準(zhǔn)測(cè)試,并指定線程數(shù)
BENCHMARK_REGISTER_F(MyBenchmark, MultiThreadedWork)->Threads(1);
BENCHMARK_REGISTER_F(MyBenchmark, MultiThreadedWork)->Threads(2);
BENCHMARK_REGISTER_F(MyBenchmark, MultiThreadedWork)->Threads(4);
BENCHMARK_REGISTER_F(MyBenchmark, MultiThreadedWork)->Threads(8);
BENCHMARK_MAIN();
3.Lock VS Atomic
(1) Lock Atomic Benchmark
很多人都認(rèn)為鎖(lock)比原子操作(atomic)要更慢,那么實(shí)際上真的是這樣嗎?下面我們通過兩個(gè)測(cè)試來進(jìn)行對(duì)比。
公平起見,我們將使用一個(gè)基于 atomic 變量實(shí)現(xiàn)的自旋鎖(SpinLock)與 std::mutex 進(jìn)行性能對(duì)比。自旋鎖的實(shí)現(xiàn)摘自 Folly 庫。其原理是使用一個(gè) atomic 變量來標(biāo)記是否被占用,并使用 acquire-release 內(nèi)存序來保證臨界區(qū)的正確性。在沖突過大時(shí),自旋鎖會(huì)使用 sleep 讓出 CPU。代碼如下:
#pragma once
#include <atomic>
#include <cstdint>
class Sleeper {
static const uint32_t kMaxActiveSpin = 4000;
uint32_t spin_count_;
public:
constexpr Sleeper() noexcept : spin_count_(0) {}
inline __attribute__((always_inline)) static void sleep() noexcept {
struct timespec ts = {0, 500000};
nanosleep(&ts, nullptr);
}
inline __attribute__((always_inline)) void wait() noexcept {
if (spin_count_ < kMaxActiveSpin) {
++spin_count_;
#ifdef __x86_64__
asm volatile("pause" ::: "memory");
#elif defined(__aarch64__)
asm volatile("yield" ::: "memory");
#else
// Fallback for other architectures
#endif
} else {
sleep();
}
}
};
class SpinLock {
enum { FREE = 0, LOCKED = 1 };
public:
constexpr SpinLock() : lock_(FREE) {}
inline __attribute__((always_inline)) bool try_lock() noexcept { return cas(FREE, LOCKED); }
inline __attribute__((always_inline)) void lock() noexcept {
Sleeper sleeper;
while (!try_lock()) {
do {
sleeper.wait();
} while (AtomicCast(&lock_)->load(std::memory_order_relaxed) == LOCKED);
}
}
inline __attribute__((always_inline)) void unlock() noexcept {
AtomicCast(&lock_)->store(FREE, std::memory_order_release);
}
private:
inline __attribute__((always_inline)) bool cas(uint8_t compare, uint8_t new_val) noexcept {
return AtomicCast(&lock_)->compare_exchange_strong(compare, new_val, std::memory_order_acquire,
std::memory_order_relaxed);
}
inline __attribute__((always_inline)) static std::atomic<uint8_t>* AtomicCast(uint8_t* value) {
return reinterpret_cast<std::atomic<uint8_t>*>(value);
}
private:
uint8_t lock_;
};在第一個(gè)benchmark中,我們測(cè)試了無競(jìng)爭(zhēng)情況下的性能。也就是說,原子變量的CAS操作只會(huì)執(zhí)行一次,不會(huì)進(jìn)入 sleep 狀態(tài)。在這種情況下,自旋鎖(SpinLock)等價(jià)于一次原子 set 操作。代碼如下:
#include <benchmark/benchmark.h>
#include <atomic>
#include <iostream>
#include <memory>
#include <mutex>
#include <unordered_set>
#include "spin_lock.h"
constexpr int kSetSize = 10000;
// struct alignas(64) PaddedCounter {
// std::atomic<int> value{0};
// char padding[64 - sizeof(std::atomic<int>)]; // 填充到緩存行大小
// };
struct alignas(64) PaddedCounterLock {
int value{0};
char padding[64 - sizeof(std::atomic<int>)]; // 填充到緩存行大小
};
class MyBenchmark : public benchmark::Fixture {
public:
void SetUp(const ::benchmark::State& state) override {
std::call_once(flag, [this, &state]() {
for (int i = 0; i < kSetSize; i++) {
s.insert(i);
}
sums_atomic = std::vector<PaddedCounterLock>(state.threads());
sum_lock = std::vector<PaddedCounterLock>(state.threads());
});
}
const std::unordered_set<int>& GetSet() { return s; }
std::vector<PaddedCounterLock>& GetSumsAtomic() { return sums_atomic; }
std::vector<PaddedCounterLock>& GetSumLock() { return sum_lock; }
private:
std::unordered_set<int> s;
std::once_flag flag;
std::vector<PaddedCounterLock> sums_atomic;
std::vector<PaddedCounterLock> sum_lock;
};
BENCHMARK_DEFINE_F(MyBenchmark, MultiThreadedWorkAtomic)(benchmark::State& state) {
SpinLock m;
for (auto _ : state) {
int size_sum = kSetSize;
int size_per_thread = (size_sum + state.threads() - 1) / state.threads();
int sum = 0;
int start = state.thread_index() * size_per_thread;
int end = std::min((state.thread_index() + 1) * size_per_thread, size_sum);
for (int i = start; i < end; i++) {
const auto& inst = GetSet();
if (inst.count(i) > 0) {
std::lock_guard<SpinLock> lg(m);
benchmark::DoNotOptimize(GetSumsAtomic()[state.thread_index()].value++);
}
}
}
}
BENCHMARK_DEFINE_F(MyBenchmark, MultiThreadedWorkLock)(benchmark::State& state) {
std::mutex m;
for (auto _ : state) {
int size_sum = kSetSize;
int size_per_thread = (size_sum + state.threads() - 1) / state.threads();
int sum = 0;
int start = state.thread_index() * size_per_thread;
int end = std::min((state.thread_index() + 1) * size_per_thread, size_sum);
for (int i = start; i < end; i++) {
const auto& inst = GetSet();
if (inst.count(i) > 0) {
std::lock_guard<std::mutex> lg(m);
benchmark::DoNotOptimize(GetSumLock()[state.thread_index()].value++);
}
}
}
}
// 注冊(cè)基準(zhǔn)測(cè)試,并指定線程數(shù)
BENCHMARK_REGISTER_F(MyBenchmark, MultiThreadedWorkAtomic)->Threads(1);
BENCHMARK_REGISTER_F(MyBenchmark, MultiThreadedWorkAtomic)->Threads(2);
BENCHMARK_REGISTER_F(MyBenchmark, MultiThreadedWorkAtomic)->Threads(4);
BENCHMARK_REGISTER_F(MyBenchmark, MultiThreadedWorkAtomic)->Threads(8);
BENCHMARK_REGISTER_F(MyBenchmark, MultiThreadedWorkLock)->Threads(1);
BENCHMARK_REGISTER_F(MyBenchmark, MultiThreadedWorkLock)->Threads(2);
BENCHMARK_REGISTER_F(MyBenchmark, MultiThreadedWorkLock)->Threads(4);
BENCHMARK_REGISTER_F(MyBenchmark, MultiThreadedWorkLock)->Threads(8);
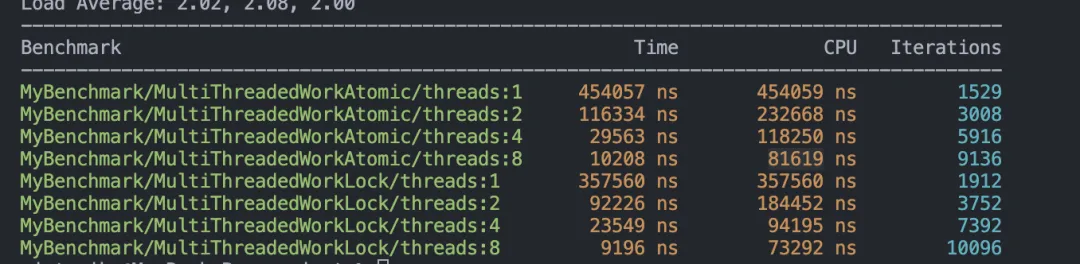
BENCHMARK_MAIN();benchmark結(jié)果:
第二個(gè)benchmark是對(duì)比競(jìng)爭(zhēng)激烈時(shí)的性能,代碼如下:
#include <benchmark/benchmark.h>
#include <atomic>
#include <iostream>
#include <memory>
#include <mutex>
#include <unordered_set>
#include "spin_lock.h"
constexpr int kSetSize = 10000;
class MyBenchmark : public benchmark::Fixture {
public:
void SetUp(const ::benchmark::State& state) override {
std::call_once(flag, [this, &state]() {
for (int i = 0; i < kSetSize; i++) {
s.insert(i);
}
count_ = 0;
});
}
const std::unordered_set<int>& GetSet() { return s; }
void SpinLockAndAdd() {
std::lock_guard<SpinLock> lg(m1_);
count_++;
}
void MutexLockAndAdd() {
std::lock_guard<std::mutex> lg(m2_);
count_++;
}
private:
std::unordered_set<int> s;
std::once_flag flag;
uint32_t count_;
SpinLock m1_;
std::mutex m2_;
};
BENCHMARK_DEFINE_F(MyBenchmark, MultiThreadedWorkAtomic)(benchmark::State& state) {
for (auto _ : state) {
int size_sum = kSetSize;
int size_per_thread = (size_sum + state.threads() - 1) / state.threads();
int sum = 0;
int start = state.thread_index() * size_per_thread;
int end = std::min((state.thread_index() + 1) * size_per_thread, size_sum);
for (int i = start; i < end; i++) {
const auto& inst = GetSet();
if (inst.count(i) > 0) {
SpinLockAndAdd();
}
}
}
}
BENCHMARK_DEFINE_F(MyBenchmark, MultiThreadedWorkLock)(benchmark::State& state) {
for (auto _ : state) {
int size_sum = kSetSize;
int size_per_thread = (size_sum + state.threads() - 1) / state.threads();
int sum = 0;
int start = state.thread_index() * size_per_thread;
int end = std::min((state.thread_index() + 1) * size_per_thread, size_sum);
for (int i = start; i < end; i++) {
const auto& inst = GetSet();
if (inst.count(i) > 0) {
MutexLockAndAdd();
}
}
}
}
// 注冊(cè)基準(zhǔn)測(cè)試,并指定線程數(shù)
BENCHMARK_REGISTER_F(MyBenchmark, MultiThreadedWorkAtomic)->Threads(1);
BENCHMARK_REGISTER_F(MyBenchmark, MultiThreadedWorkAtomic)->Threads(2);
BENCHMARK_REGISTER_F(MyBenchmark, MultiThreadedWorkAtomic)->Threads(4);
BENCHMARK_REGISTER_F(MyBenchmark, MultiThreadedWorkAtomic)->Threads(8);
BENCHMARK_REGISTER_F(MyBenchmark, MultiThreadedWorkLock)->Threads(1);
BENCHMARK_REGISTER_F(MyBenchmark, MultiThreadedWorkLock)->Threads(2);
BENCHMARK_REGISTER_F(MyBenchmark, MultiThreadedWorkLock)->Threads(4);
BENCHMARK_REGISTER_F(MyBenchmark, MultiThreadedWorkLock)->Threads(8);
BENCHMARK_MAIN();benchmark結(jié)果:
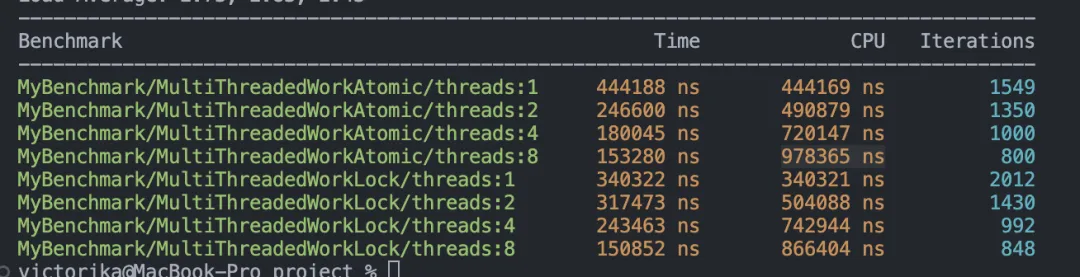
可以看到,無論是哪一種情況,std::mutex 的性能都更優(yōu)。當(dāng)然,這個(gè)測(cè)試結(jié)果可能會(huì)因不同的操作系統(tǒng)而有所不同,但至少可以得出一個(gè)結(jié)論:這兩者的性能是一個(gè)量級(jí)的,并不存在 atomic 一定比 std::mutex 更快的說法。這其實(shí)是因?yàn)楝F(xiàn)代 C++ 中的 std::mutex 實(shí)現(xiàn)已經(jīng)高度優(yōu)化,其實(shí)現(xiàn)與上面的自旋鎖(SpinLock)非常相似,在低競(jìng)爭(zhēng)的情況下并不會(huì)陷入內(nèi)核態(tài)。
那么,按上面的說法,是不是我們根本不需要 atomic 變量呢?先來分析一下 atomic 的優(yōu)點(diǎn)。
atomic 的優(yōu)點(diǎn)有:
- 可以實(shí)現(xiàn)內(nèi)存占用極小的鎖。?
- 當(dāng)臨界區(qū)操作可以等價(jià)于一個(gè)原子操作時(shí),性能會(huì)更高。
對(duì)于第二個(gè)結(jié)論,我們可以做個(gè)測(cè)試。同樣,拿前面的例子稍作修改。
case 1如下:
#include <benchmark/benchmark.h>
#include <atomic>
#include <iostream>
#include <memory>
#include <mutex>
#include <unordered_set>
#include "spin_lock.h"
constexpr int kSetSize = 10000;
class MyBenchmark : public benchmark::Fixture {
public:
void SetUp(const ::benchmark::State& state) override {
std::call_once(flag, [this, &state]() {
for (int i = 0; i < kSetSize; i++) {
s.insert(i);
}
});
}
const std::unordered_set<int>& GetSet() { return s; }
private:
std::unordered_set<int> s;
std::once_flag flag;
};
BENCHMARK_DEFINE_F(MyBenchmark, MultiThreadedWorkAtomic)(benchmark::State& state) {
std::atomic<uint32_t> sum = 0;
for (auto _ : state) {
int size_sum = kSetSize;
int size_per_thread = (size_sum + state.threads() - 1) / state.threads();
int sum = 0;
int start = state.thread_index() * size_per_thread;
int end = std::min((state.thread_index() + 1) * size_per_thread, size_sum);
for (int i = start; i < end; i++) {
const auto& inst = GetSet();
if (inst.count(i) > 0) {
benchmark::DoNotOptimize(sum++);
}
}
}
}
BENCHMARK_DEFINE_F(MyBenchmark, MultiThreadedWorkLock)(benchmark::State& state) {
std::mutex m;
uint32_t sum = 0;
for (auto _ : state) {
int size_sum = kSetSize;
int size_per_thread = (size_sum + state.threads() - 1) / state.threads();
int sum = 0;
int start = state.thread_index() * size_per_thread;
int end = std::min((state.thread_index() + 1) * size_per_thread, size_sum);
for (int i = start; i < end; i++) {
const auto& inst = GetSet();
if (inst.count(i) > 0) {
std::lock_guard<std::mutex> lg(m);
sum++;
}
}
}
}
// 注冊(cè)基準(zhǔn)測(cè)試,并指定線程數(shù)
BENCHMARK_REGISTER_F(MyBenchmark, MultiThreadedWorkAtomic)->Threads(1);
BENCHMARK_REGISTER_F(MyBenchmark, MultiThreadedWorkAtomic)->Threads(2);
BENCHMARK_REGISTER_F(MyBenchmark, MultiThreadedWorkAtomic)->Threads(4);
BENCHMARK_REGISTER_F(MyBenchmark, MultiThreadedWorkAtomic)->Threads(8);
BENCHMARK_REGISTER_F(MyBenchmark, MultiThreadedWorkLock)->Threads(1);
BENCHMARK_REGISTER_F(MyBenchmark, MultiThreadedWorkLock)->Threads(2);
BENCHMARK_REGISTER_F(MyBenchmark, MultiThreadedWorkLock)->Threads(4);
BENCHMARK_REGISTER_F(MyBenchmark, MultiThreadedWorkLock)->Threads(8);
BENCHMARK_MAIN();benchmark結(jié)果:
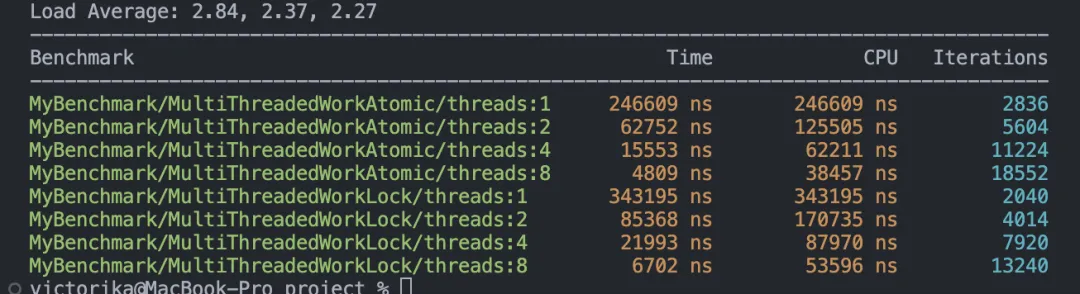
case 2如下:
#include <benchmark/benchmark.h>
#include <atomic>
#include <iostream>
#include <memory>
#include <mutex>
#include <unordered_set>
#include "spin_lock.h"
constexpr int kSetSize = 10000;
class MyBenchmark : public benchmark::Fixture {
public:
void SetUp(const ::benchmark::State& state) override {
std::call_once(flag, [this, &state]() {
for (int i = 0; i < kSetSize; i++) {
s.insert(i);
}
count_ = 0;
atomic_count_ = 0;
});
}
const std::unordered_set<int>& GetSet() { return s; }
void AtomicAdd() { atomic_count_++; }
void MutexLockAndAdd() {
std::lock_guard<std::mutex> lg(m);
count_++;
}
private:
std::unordered_set<int> s;
std::once_flag flag;
uint32_t count_;
std::atomic<uint32_t> atomic_count_;
std::mutex m;
};
BENCHMARK_DEFINE_F(MyBenchmark, MultiThreadedWorkAtomic)(benchmark::State& state) {
for (auto _ : state) {
int size_sum = kSetSize;
int size_per_thread = (size_sum + state.threads() - 1) / state.threads();
int sum = 0;
int start = state.thread_index() * size_per_thread;
int end = std::min((state.thread_index() + 1) * size_per_thread, size_sum);
for (int i = start; i < end; i++) {
const auto& inst = GetSet();
if (inst.count(i) > 0) {
AtomicAdd();
}
}
}
}
BENCHMARK_DEFINE_F(MyBenchmark, MultiThreadedWorkLock)(benchmark::State& state) {
for (auto _ : state) {
int size_sum = kSetSize;
int size_per_thread = (size_sum + state.threads() - 1) / state.threads();
int sum = 0;
int start = state.thread_index() * size_per_thread;
int end = std::min((state.thread_index() + 1) * size_per_thread, size_sum);
for (int i = start; i < end; i++) {
const auto& inst = GetSet();
if (inst.count(i) > 0) {
MutexLockAndAdd();
}
}
}
}
// 注冊(cè)基準(zhǔn)測(cè)試,并指定線程數(shù)
BENCHMARK_REGISTER_F(MyBenchmark, MultiThreadedWorkAtomic)->Threads(1);
BENCHMARK_REGISTER_F(MyBenchmark, MultiThreadedWorkAtomic)->Threads(2);
BENCHMARK_REGISTER_F(MyBenchmark, MultiThreadedWorkAtomic)->Threads(4);
BENCHMARK_REGISTER_F(MyBenchmark, MultiThreadedWorkAtomic)->Threads(8);
BENCHMARK_REGISTER_F(MyBenchmark, MultiThreadedWorkLock)->Threads(1);
BENCHMARK_REGISTER_F(MyBenchmark, MultiThreadedWorkLock)->Threads(2);
BENCHMARK_REGISTER_F(MyBenchmark, MultiThreadedWorkLock)->Threads(4);
BENCHMARK_REGISTER_F(MyBenchmark, MultiThreadedWorkLock)->Threads(8);
BENCHMARK_MAIN();benchmark結(jié)果:
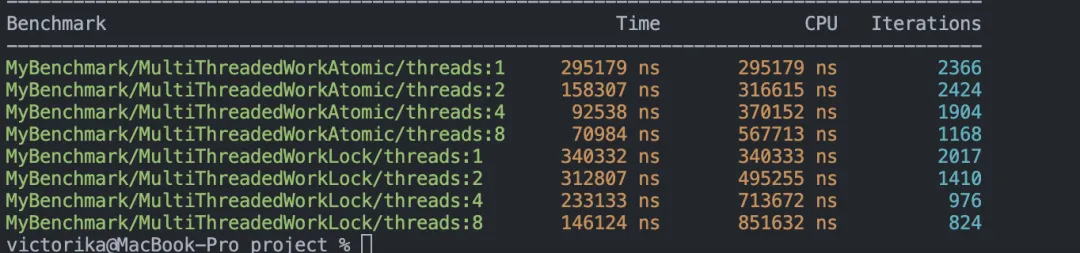
接下來結(jié)合這兩個(gè)優(yōu)點(diǎn)來看,鏈?zhǔn)綌?shù)據(jù)結(jié)構(gòu)的場(chǎng)景非常適合使用 atomic 變量。
- 內(nèi)存占用少:即使每個(gè)節(jié)點(diǎn)都實(shí)現(xiàn)一個(gè)自旋鎖(SpinLock),也不會(huì)浪費(fèi)太多內(nèi)存。?
- 鏈?zhǔn)綌?shù)據(jù)結(jié)構(gòu)的臨界區(qū)通常可以優(yōu)化成一個(gè)指針的 CAS 操作。
(2) Epoch Based Reclamation
雖然如此,但要寫一個(gè)高性能的并發(fā)安全的鏈?zhǔn)綌?shù)據(jù)結(jié)構(gòu)是非常困難的,這主要是因?yàn)閷懖僮靼藙h除操作。舉個(gè)最簡(jiǎn)單的例子:
假設(shè)有一個(gè)鏈表 A->B->C,一個(gè)線程正在讀B節(jié)點(diǎn),另一個(gè)線程正在刪除B節(jié)點(diǎn),如何保證讀線程在讀B節(jié)點(diǎn)期間不會(huì)被另一個(gè)線程給刪掉?
再舉個(gè)更復(fù)雜的例子:
假設(shè)有一個(gè)鏈表 A->B->C。一個(gè)線程正在讀取 B 節(jié)點(diǎn),另一個(gè)線程正在修改 B 節(jié)點(diǎn)。顯然,最簡(jiǎn)單的實(shí)現(xiàn)是鎖住 B,同時(shí)只允許一個(gè)操作,但顯然這樣從各方面來看性能都不是最佳的,這是第一個(gè)方法。
第二個(gè)方法是類似于 Copy On Write(COW)。寫操作時(shí)先重新構(gòu)造一個(gè)節(jié)點(diǎn) B1,再修改對(duì)應(yīng)的數(shù)據(jù),最后通過 CAS 操作修改指針連接 A->B1。
我們來分析一下為什么第二個(gè)方法遠(yuǎn)比第一個(gè)方法要好。
首先,上鎖會(huì)觸發(fā)原子寫,意味著即便是你只是為了讀數(shù)據(jù),也會(huì)觸發(fā)一次 Cache Line 一致性同步的問題。而且在找到 B 節(jié)點(diǎn)之前的每一個(gè)節(jié)點(diǎn)都要依次上鎖來保證讀取的正確性,這意味著極大概率會(huì)發(fā)生 Cache Ping-Pong 問題。
再來看寫操作,寫操作除了上鎖以外還需要修改節(jié)點(diǎn)的數(shù)據(jù)。第二個(gè)方法需要先構(gòu)造一個(gè)新的節(jié)點(diǎn)再修改,意味著這個(gè)節(jié)點(diǎn)在插入鏈表之前一定不在其他線程的 Cache 里(排除剛好有某個(gè)變量和這個(gè)新節(jié)點(diǎn)的內(nèi)存在同一個(gè) Cache Line 的情況)。而第一個(gè)方法修改的節(jié)點(diǎn)已經(jīng)在鏈表里,這表示在之前一定有線程已經(jīng)訪問過這個(gè)節(jié)點(diǎn),那么它很可能在 Cache 里面,從而觸發(fā)一次 Cache Line 一致性同步的問題。
然而事情沒有這么簡(jiǎn)單。試想一下,在修改完指針 A->B1 后,B 節(jié)點(diǎn)需要被丟棄釋放,這時(shí)候其他線程有可能正在訪問 B 節(jié)點(diǎn)而導(dǎo)致崩潰。
可以看出這些問題都是因?yàn)閯h除操作引起的,這個(gè)問題有幾個(gè)著名的解決方案,比如 Epoch Based Reclamation 和 Hazard Pointer 等。這里只介紹其中的 Epoch Based Reclamation,感興趣的話請(qǐng)自行搜索了解其他實(shí)現(xiàn)方式。
該算法的思路是刪除操作會(huì)嘗試觸發(fā)版本 +1,但只有當(dāng)所有線程都是最新版本 e 時(shí)才能成功,成功后會(huì)回收 e-1 版本的內(nèi)存。因此,最多會(huì)累積 3 個(gè)版本未釋放節(jié)點(diǎn)的內(nèi)存。是個(gè)以空間換時(shí)間,輕讀重寫的方案。
首先,每個(gè)線程維護(hù)自己的線程變量:
- active:標(biāo)記該線程是否正在讀數(shù)據(jù)
- epoch:標(biāo)記該線程當(dāng)前的版本
全局維護(hù)變量:
- global_epoch:全局最新的版本
- retire_list:等待釋放的節(jié)點(diǎn)
讀操作:
- 首先把線程 active 標(biāo)記為 true,表示正在讀數(shù)據(jù)。?
- 然后把 global_epoch 賦值給 epoch,記錄當(dāng)前正在讀的版本。?
- 如果線程需要?jiǎng)h除節(jié)點(diǎn),則把節(jié)點(diǎn)放到全局的 retire_list 末尾。?
- 結(jié)束讀后,將 active 標(biāo)記為 false。
寫操作:
- 如果要?jiǎng)h除節(jié)點(diǎn),則把節(jié)點(diǎn)放到全局的 retire_list 末尾,并且嘗試增加版本。?
- 增加版本時(shí)檢查所有線程的狀態(tài),當(dāng)所有線程滿足 epoch 等于當(dāng)前版本 e 或者 active 為 false 時(shí),進(jìn)行版本 e = e + 1 操作。?
- 清空 e-2 版本的 retire_list。
這里給出一個(gè)簡(jiǎn)單的實(shí)現(xiàn),代碼如下:
#pragma once
#include <array>
#include <atomic>
#include <mutex>
#include <numeric>
#include <vector>
constexpr uint8_t kEpochSize = 3;
constexpr uint8_t kCacheLineSize = 64;
template <uint32_t kReadThreadNum>
class ThreadIDManager;
template <uint32_t kReadThreadNum>
struct ThreadID {
ThreadID() { tid = ThreadIDManager<kReadThreadNum>::GetInstance().AcquireThreadID(); }
~ThreadID() { ThreadIDManager<kReadThreadNum>::GetInstance().ReleaseThreadID(tid); }
uint32_t tid;
};
template <uint32_t kReadThreadNum>
class ThreadIDManager {
public:
ThreadIDManager() : tid_list_(kReadThreadNum) { std::iota(tid_list_.begin(), tid_list_.end(), 1); }
ThreadIDManager(const ThreadIDManager &) = delete;
ThreadIDManager(ThreadIDManager &&) = delete;
ThreadIDManager &operator=(const ThreadIDManager &) = delete;
~ThreadIDManager() = default;
static ThreadIDManager &GetInstance() {
static ThreadIDManager inst;
return inst;
}
uint32_t AcquireThreadID() {
std::lock_guard<std::mutex> lock(tid_list_mutex_);
auto tid = tid_list_.back();
tid_list_.pop_back();
return tid;
}
void ReleaseThreadID(const uint32_t tid) {
std::lock_guard<std::mutex> lock(tid_list_mutex_);
tid_list_.emplace_back(tid);
}
private:
std::vector<uint32_t> tid_list_;
std::mutex tid_list_mutex_;
};
struct TLS {
TLS() : active(false), epoch(0) {}
TLS(TLS &) = delete;
TLS(TLS &&) = delete;
void operator=(const TLS &) = delete;
~TLS() = default;
std::atomic_flag active;
std::atomic<uint8_t> epoch;
} __attribute__((aligned(kCacheLineSize)));
template <class RCObject, class DestroyClass, uint32_t kReadThreadNum>
class EbrManager {
public:
EbrManager() : tls_list_(), global_epoch_(0), update_(false), write_cnt_(0) {
for (int i = 0; i < kEpochSize; i++) {
retire_list_[i].store(nullptr, std::memory_order_release);
}
}
EbrManager(const EbrManager<RCObject, DestroyClass, kReadThreadNum> &) = delete;
EbrManager(EbrManager<RCObject, DestroyClass, kReadThreadNum> &&) = delete;
EbrManager &operator=(const EbrManager<RCObject, DestroyClass, kReadThreadNum> &) = delete;
~EbrManager() { ClearAllRetireList(); }
void ClearAllRetireList() {
for (int i = 0; i < kEpochSize; i++) {
ClearRetireList(i);
}
}
inline void StartRead() {
auto &tls = GetTLS();
tls.active.test_and_set(std::memory_order_release);
tls.epoch.store(global_epoch_.load(std::memory_order_acquire), std::memory_order_release);
}
inline void EndRead() { GetTLS().active.clear(std::memory_order_release); }
inline void FreeObject(RCObject *object) {
auto epoch = global_epoch_.load(std::memory_order_acquire);
auto *node = new RetireNode;
node->obj = object;
do {
node->next = retire_list_[epoch].load(std::memory_order_acquire);
} while (!retire_list_[epoch].compare_exchange_weak(node->next, node, std::memory_order_acq_rel));
auto write_cnt = write_cnt_.fetch_add(1, std::memory_order_relaxed);
if (write_cnt > kReadThreadNum) {
if (!update_.test_and_set(std::memory_order_acq_rel)) {
TryGC();
update_.clear(std::memory_order_release);
}
}
}
private:
inline TLS &GetTLS() {
thread_local ThreadID<kReadThreadNum> thread_id;
return tls_list_[thread_id.tid];
}
inline void TryGC() {
auto epoch = global_epoch_.load(std::memory_order_acquire);
// TODO 優(yōu)化記錄上一次搜索到的位置
for (int i = 0; i < tls_list_.size(); i++) {
if (tls_list_[i].active.test(std::memory_order::memory_order_acquire) &&
tls_list_[i].epoch.load(std::memory_order::memory_order_acquire) != epoch) {
return;
}
}
global_epoch_.store((epoch + 1) % kEpochSize, std::memory_order_release);
ClearRetireList((epoch + 2) % kEpochSize);
write_cnt_.store(0, std::memory_order_relaxed);
}
inline void ClearRetireList(int index) {
auto *retire_node = retire_list_[index].load(std::memory_order_acquire);
while (retire_node != nullptr) {
DestroyClass destroy(retire_node->obj);
auto *old_node = retire_node;
retire_node = retire_node->next;
delete old_node;
}
retire_list_[index].store(nullptr, std::memory_order_release);
}
struct RetireNode {
RCObject *obj;
RetireNode *next;
};
std::array<char, kCacheLineSize> start_padding_;
std::array<TLS, kReadThreadNum> tls_list_;
std::atomic<uint8_t> global_epoch_;
std::array<char, kCacheLineSize> mid_padding_;
std::atomic_flag update_;
std::atomic<uint32_t> write_cnt_;
std::atomic<RetireNode *> retire_list_[kEpochSize];
std::array<char, kCacheLineSize> end_padding_;
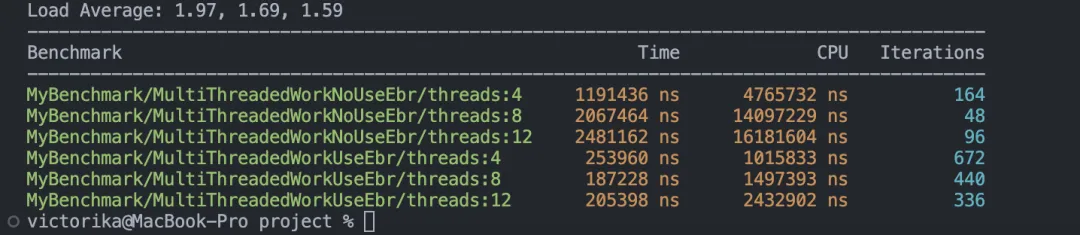
};這里再給出一個(gè)benchmark,對(duì)比一下使用 Epoch Based Reclamation(EBR)和不使用 EBR 的區(qū)別。由于筆者時(shí)間有限,只能寫一個(gè)非常簡(jiǎn)單的版本,僅供參考。
#include <benchmark/benchmark.h>
#include <mutex>
#include "ebr.h"
#include "spin_lock.h"
struct Node {
Node() : lock(), next(nullptr) {}
int key;
int value;
Node *next;
SpinLock lock;
};
class NodeFree {
public:
NodeFree(Node *node) { delete node; }
};
/*
* 快速測(cè)試起見,簡(jiǎn)單寫了個(gè)list版本的kv結(jié)構(gòu),里面只會(huì)有3個(gè)元素,然后只支持Get和Modify,Modify也必定會(huì)命中key。
* 不是直接把key,value,next設(shè)置成atomic變量而是使用SpinLock的原因是模擬復(fù)雜情況,真實(shí)情況下會(huì)存在Add和Remove操作,實(shí)現(xiàn)沒有如此簡(jiǎn)單。
*/
class MyList {
public:
MyList() {
Node *pre_node = nullptr;
auto *&cur_node = root_;
// 這里雖然插入了10個(gè)元素,但后面的實(shí)現(xiàn)會(huì)假設(shè)第一個(gè)key 9作為header是絕對(duì)不會(huì)被修改或者讀到的。
for (int i = 0; i < 10; i++) {
cur_node = new Node;
cur_node->key = i;
cur_node->value = i;
cur_node->next = pre_node;
pre_node = cur_node;
}
}
int Get(int key, int *value) {
root_->lock.lock();
auto *cur_node = root_->next;
auto *pre_node = root_;
while (cur_node != nullptr) {
cur_node->lock.lock();
pre_node->lock.unlock();
if (key == cur_node->key) {
*value = cur_node->value;
cur_node->lock.unlock();
return 0;
}
pre_node = cur_node;
cur_node = cur_node->next;
}
pre_node->lock.unlock();
return 1;
}
int Modify(int key, int value) {
root_->lock.lock();
auto *cur_node = root_->next;
auto *pre_node = root_;
while (cur_node != nullptr) {
cur_node->lock.lock();
pre_node->lock.unlock();
if (key == cur_node->key) {
cur_node->value = value;
cur_node->lock.unlock();
return 0;
}
pre_node = cur_node;
cur_node = cur_node->next;
}
pre_node->lock.unlock();
return 1;
}
int GetUseEbr(int key, int *value) {
ebr_mgr_.StartRead();
auto *cur_node = root_->next;
while (cur_node != nullptr) {
if (key == cur_node->key) {
*value = cur_node->value;
ebr_mgr_.EndRead();
return 0;
}
cur_node = cur_node->next;
}
ebr_mgr_.EndRead();
return 1;
}
int ModifyUseEbr(int key, int value) {
root_->lock.lock();
auto *cur_node = root_->next;
auto *pre_node = root_;
while (cur_node != nullptr) {
cur_node->lock.lock();
if (key == cur_node->key) {
auto *new_node = new Node;
new_node->key = cur_node->key;
new_node->value = value;
new_node->next = cur_node->next;
pre_node->next = new_node;
cur_node->lock.unlock();
pre_node->lock.unlock();
ebr_mgr_.FreeObject(cur_node);
return 0;
}
auto *next_node = cur_node->next;
pre_node->lock.unlock();
pre_node = cur_node;
cur_node = next_node;
}
pre_node->lock.unlock();
return 1;
}
private:
Node *root_;
EbrManager<Node, NodeFree, 15> ebr_mgr_;
};
class MyBenchmark : public benchmark::Fixture {
public:
void SetUp(const ::benchmark::State &state) override {}
MyList &GetMyList() { return l; }
private:
MyList l;
std::once_flag flag;
};
constexpr int kKeySize = 10000;
BENCHMARK_DEFINE_F(MyBenchmark, MultiThreadedWorkNoUseEbr)(benchmark::State &state) {
for (auto _ : state) {
auto &mylist = GetMyList();
if (0 == state.thread_index()) {
// modify
for (int i = 0; i < kKeySize; i++) {
mylist.Modify(i % 9, i);
}
} else {
// get
for (int i = 0; i < kKeySize; i++) {
int value;
mylist.Get(i % 9, &value);
}
}
}
}
BENCHMARK_DEFINE_F(MyBenchmark, MultiThreadedWorkUseEbr)(benchmark::State &state) {
for (auto _ : state) {
auto &mylist = GetMyList();
if (0 == state.thread_index()) {
// modify
for (int i = 0; i < kKeySize; i++) {
mylist.ModifyUseEbr(i % 9, i);
}
} else {
// get
for (int i = 0; i < kKeySize; i++) {
int value;
mylist.GetUseEbr(i % 9, &value);
}
}
}
}
// 注冊(cè)基準(zhǔn)測(cè)試,并指定線程數(shù)
BENCHMARK_REGISTER_F(MyBenchmark, MultiThreadedWorkNoUseEbr)->Threads(4);
BENCHMARK_REGISTER_F(MyBenchmark, MultiThreadedWorkNoUseEbr)->Threads(8);
BENCHMARK_REGISTER_F(MyBenchmark, MultiThreadedWorkNoUseEbr)->Threads(12);
BENCHMARK_REGISTER_F(MyBenchmark, MultiThreadedWorkUseEbr)->Threads(4);
BENCHMARK_REGISTER_F(MyBenchmark, MultiThreadedWorkUseEbr)->Threads(8);
BENCHMARK_REGISTER_F(MyBenchmark, MultiThreadedWorkUseEbr)->Threads(12);
BENCHMARK_MAIN();benchmark結(jié)果: