













Hadoop 是什么?它是如何工作的?
Hadoop是什么?它是如何工作的?為什么 Hadoop可以成為全球最流行的大數據處理框架之一?如何基于 Hadoop搭建一套簡單的分布式文件系統?這篇我們一起來來深入討論。

一、Hadoop是什么?
Hadoop是一個開源的分布式計算框架,用于處理和存儲大規模數據集,它是由 Apache Software Foundation維護,能夠幫助用戶在商用硬件集群上以可靠、高效、容錯的方式處理和分析海量數據。為了更好地理解 Hadoop是什么,我們列舉了Hadoop一些里程碑:
- 2002年: Nutch項目啟動,目標是實現全面的網頁抓取、索引和查詢功能。
- 2003年: Google發布了三篇具有影響力的論文(Google File System(GFS)、MapReduce和Bigtable),為 Hadoop的文件存儲架構奠定了基礎。
- 2004年: Cutting在 Nutch中實現了類似 GFS的功能,形成了后來的 Hadoop分布式文件系統(HDFS)。
- 2005年: Nutch項目中實現了 MapReduce的初步版本,隨后 Hadoop從 Nutch中分離出來,成為一個獨立的開源項目。
- 2006年: Yahoo!雇傭 Doug Cutting,并為Hadoop的發展提供支持,同年,Apache Hadoop項目正式啟動。
- 2008年: Hadoop成為 Apache頂級項目,并迎來了快速發展。同年,Cloudera公司成立,推動 Hadoop商業化進程。
- 從此,Hadoop迅猛發展,成為全球最流行的大數據處理框架之一。
二、Hadoop的核心組件
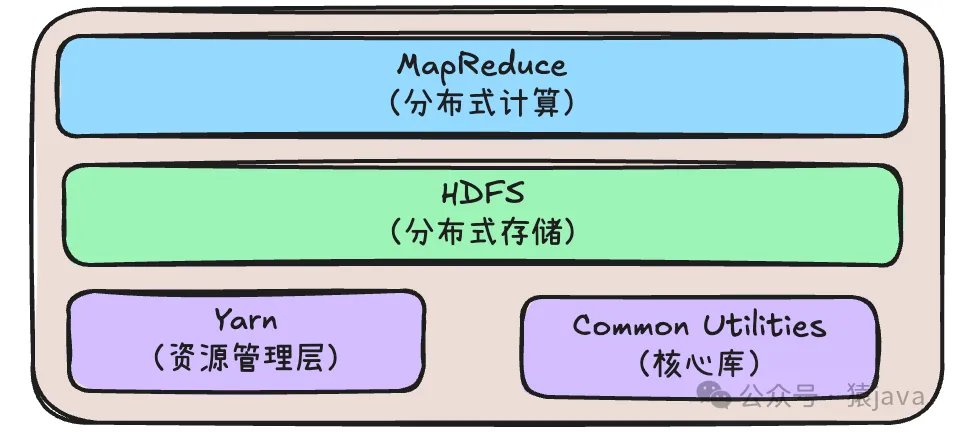
Hadoop的核心組件包括以下 4個:
- HDFS:HDFS是 Hadoop的數據存儲層,它負責將大量數據分塊存儲到集群中的不同節點上,從而實現分布式保存和冗余備份。數據被切分成小塊,并復制到多個節點,以防硬件故障。
- MapReduce:MapReduce是 Hadoop的分布式計算模型,它將處理大規模數據集的任務分發到多個節點,允許并行處理。MapReduce由兩個階段組成:Map階段負責將任務分解為多個小任務;Reduce階段負責對小任務的結果進行匯總。
- YARN:YARN 是 Hadoop的資源管理層,它負責管理和調度集群中的計算資源。YARN允許多個作業在同一 Hadoop集群上并行執行,這大大提高了 Hadoop集群的利用率和擴展能力。
- Hadoop Common:Hadoop Common是 Hadoop的核心庫,提供必要的工具和實用程序,用于支持其他 Hadoop模塊。
它們的關系如下:
接下來我們將對各個組件進行詳細的分析。
1. HDFS
HDFS,全稱 Hadoop Distributed File System(分布式文件系統),它是 Hadoop的核心組件之一,旨在解決海量數據的存儲問題。
(1) HDFS 架構概述
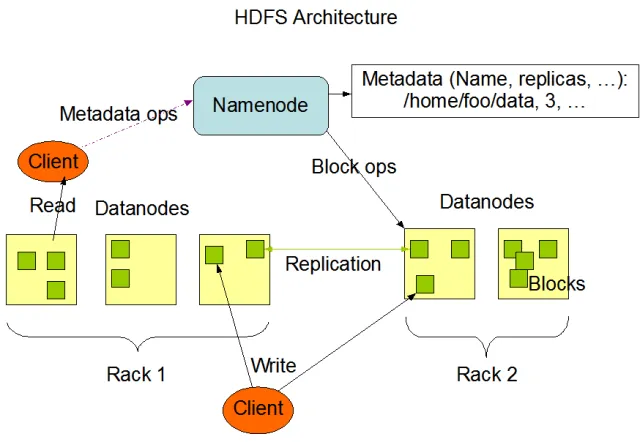
HDFS是主從結構的分布式文件系統,由兩類節點組成:
- NameNode :NameNode(主節點是 HDFS 的中心控制節點,負責管理文件系統的元數據(比如文件和目錄的樹狀結構,文件塊的位置、用戶權限等)。它不直接存儲數據,而是記錄數據存儲在哪些 DataNode 上。
- DataNode :DataNode(數據節點)是實際存儲數據的節點,它們接收數據塊,并定期向 NameNode匯報自己存儲的塊信息和健康狀態。
此外,還有一個可選的組件Secondary NameNode,它用于輔助 NameNode 的元數據備份和日志合并,幫助維持文件系統的高可用性。
HDFS的架構如下圖:
(2) 數據存儲機制
HDFS的文件是分塊存儲的,大文件被按照固定大小(默認是 128MB,早期版本是 64MB)劃分為多個數據塊(Block),每個文件塊被存儲在集群中的不同 DataNode 上。
為了防止數據因節點故障而丟失,HDFS做了數據冗余與容錯機制,它會對每個數據塊進行復制,默認情況下每個數據塊有 3 副本:
- 一個副本存儲在與客戶端最近的節點上。
- 第二個副本存儲在不同機架的節點上(防止機架故障)。
- 第三個副本存儲在第二個副本所在機架的其他節點上。
基于上述的副本機制,HDFS可以確保即使部分 DataNode 失效,數據依然可以通過其他存有副本的節點恢復。
(3) 讀寫操作流程
HDFS 文件寫入過程:
- 客戶端與 NameNode 交互:客戶端首先將寫請求發給 NameNode,然后 NameNode 返回存儲該文件每個塊的若干 DataNode 節點位置。
- 數據塊寫入 DataNode:客戶端將數據塊發送至其中一個 DataNode,這個 DataNode 會將數據塊傳遞給下一個 DataNode,依次類推,直到所有節點都保存該數據塊的副本。
- 狀態更新:上傳完成后,所有涉及的 DataNode 會將其存儲狀態通知 NameNode,并提交流程結束。
HDFS 文件讀取過程:
- 獲取元數據:客戶端向 NameNode 請求文件位置信息,NameNode 返回相關文件塊及其所在 DataNode 的位置。
- 從 DataNode 讀取數據塊:客戶端根據 NameNode 提供的位置從相關的 DataNode 直接讀取文件的不同數據塊并組裝回文件。
- 容錯處理:如果某個 DataNode 失效,客戶端無法從該NameNode獲取塊信息,它會嘗試從存儲副本的其他 DataNode 讀取。
2. MapReduce
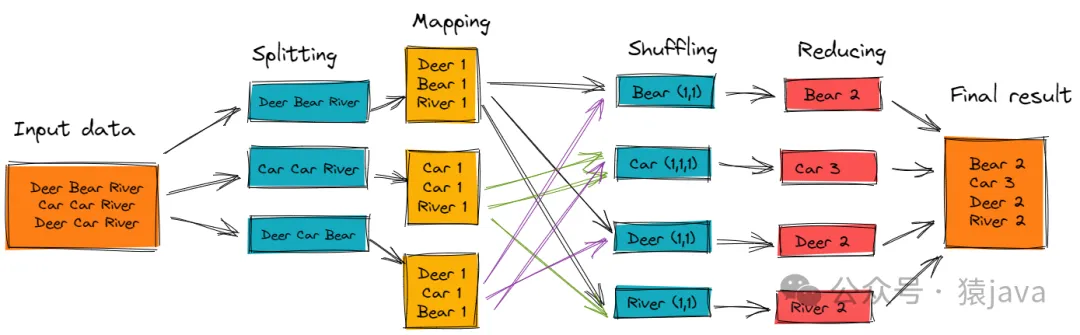
MapReduce是 Hadoop的分布式計算框架,通過將復雜的任務分解成多個獨立的簡單任務來實現并行計算,它的核心思想是“Map”和“Reduce”兩個階段:
- Map階段:將原始數據映射(map)為鍵值對(key-value pairs)。
- Reduce階段:將具有相同鍵的數值進行聚合(reduce)。
(1) MapReduce 執行流程
MapReduce 執行流程包含以下5個步驟:
① Job劃分
一個完整的 MapReduce任務稱為一個Job,Job是由多個Task構成的,分為Map Task和Reduce Task。
② Input Splitting(輸入分片)
MapReduce處理輸入數據時,首先將大文件切分成較小的Splits,Map Task的數量通常與輸入分片數量一致,每一個Map Task處理一個分片的數據。
③ Map階段
- 每個Map Task拿到一份Input Split的數據,通過RecordReader將數據轉化為一對對的<key, value>形式,這里的鍵值對((K1, V1))根據業務的需求構造。
- Map函數逐條處理這些鍵值對,輸出<K2, V2>形式的新的鍵值對。
- 這些中間鍵值對<K2, V2>在寫入本地磁盤之前會進行Sort(排序) 和 Partition(分區) 操作,Partition的作用是將具有相同鍵(K2)的鍵值對分發到相同的 Reducer中執行。
④ Shuffle and Sort(分發與排序)
Shuffle發生在 Map階段結束和 Reduce階段之間,具體過程如下:
- 排序:每個Map Task輸出的<K2, V2>對會按鍵(K2)進行排序,確保同一鍵的所有值(V2)聚集在一起。
- 分區:Map Task的輸出會根據 Partition函數的哈希值發送到不同的Reduce任務中。
- 拉取數據:Reducer從每個 Map輸出中拉取需要的分區文件,經過網絡傳輸將其聚合。
⑤ Reduce階段
- 每個Reduce Task接收到的內容是經過 Shuffle過程后所有鍵值對(<K2, List<V2>>)的集合。
- Reduce函數(用戶自定義)會對每個K2執行聚合計算,輸出為新的鍵值對<K3, V3>。
- 最終輸出結果會通過 RecordWriter寫入 HDFS或者其他存儲系統。
整個流程可以用下圖解釋:
2. YARN
YARN(Yet Another Resource Negotiator,另一種資源調度器)是Hadoop 2.x版本中引入的一個集群資源管理框架,它的設計初衷是解決 Hadoop 1.x中 MapReduce計算框架的資源調度和管理局限性,可以支持各種應用程序調度的需求。
(1) 核心組件
YARN包含以下 5個核心組件:
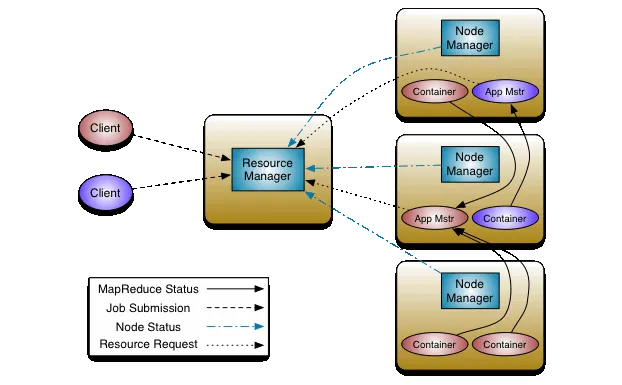
① ResourceManager
ResourceManager(RM,資源管理器)負責全局集群資源的管理和調度,它是YARN的中央控制器,協調集群中的所有應用和計算資源。ResourceManager有兩個重要的子組件:
- Scheduler(調度器):負責為應用程序按需分配資源,但不負責任務的執行和重新啟動。調度器的排期是決定如何把資源多租戶化、多應用程序化的關鍵,它可以實現不同的調度策略(如公平調度器,容量調度器等)。
- Applications Manager(應用程序管理器):負責各種應用程序的生命周期管理,包括應用程序的啟動、檢查、資源監控和故障恢復。
② NodeManager
NodeManager(NM,節點管理器)是YARN架構中的分布式代理,負責管理每個計算節點上的資源,具體負責:
- 資源報告:將本節點的CPU、內存等資源使用情況匯報給ResourceManager。
- 容器管理:協調和管理每一個容器(Container)的生命周期,包括啟動、監控和停止容器。
- 任務監控和報告:監控執行的任務,并向ResourceManager報告其狀態和進度。
③ ApplicationMaster
ApplicationMaster(AM,應用程序管理器)是為每個具體應用程序(如MapReduce Job、Spark Job)啟動的專用進程,它負責協調整個應用程序生命周期的調度和執行,協調 ResourceManager與 NodeManager,動態申請和釋放資源。每一個應用程序在提交時都會啟動一個對應的ApplicationMaster實例。 AM的職責包括:
- 申請資源:向ResourceManager請求所需的資源,定義CPU和內存需求。
- 任意調度:根據資源信息及負載情況,決定將任務分配到哪個節點/容器執行。
- 容器監控:監控啟動的任務并處理故障。
④ Container
Container(容器)是YARN中的資源分配單位,它將邏輯運行環境(如CPU、內存等涉及硬件維度的資源)與應用程序任務綁定在一起。ApplicationMaster可以向ResourceManager申請多個容器,并在這些容器中分配任務進行具體的計算。
⑤ Client
客戶端負責與YARN進行交互,提交應用程序請求,并向YARN查詢任務的執行進度和結果。客戶端將資源需求信息傳遞給ResourceManager,RM會為該任務分配資源,然后將其控制權交給對應的ApplicationMaster。
核心組件模型如下圖:
(2) 工作流程
YARN工作流程包含以下4個步驟:
① 應用程序啟動流程
- 啟動應用程序:客戶端通過API或命令行向YARN集群提交應用程序。此時,客戶端給RM發送請求,描述任務的資源需求及執行規范。
- 生成ApplicationMaster:ResourceManager根據集群的整體資源利用情況,為應用程序分配第一個容器(Container),并啟動相應的ApplicationMaster。
- ApplicationMaster初始化:ApplicationMaster會在啟動后向ResourceManager注冊自己,并根據初始任務和資源需求向RM申請更多的資源。
- 分配資源:ResourceManager根據集群的實時負載情況和調度策略,將余下的容器分配給ApplicationMaster,AC根據任務需求啟動容器,并將計算任務分配給這些容器去執行。
② 資源調度流程
- 請求資源:ApplicationMaster向ResourceManager提交資源申請。請求中指定了計算任務所需的資源(如CPU、內存)以及在何處優先執行(一定節點上或任意節點)。
- 資源心跳與分配:NodeManager通過定期心跳將節點的可用資源(包括剩余內存、CPU等情況)匯報給ResourceManager。ResourceManager根據集群整體資源情況,通過調度器(Scheduler)為機器或容器分配任務。
- 任務分配與啟動:ApplicationMaster得到資源分配信息后,再與NodeManager通信,為任務啟動容器并分配計算任務。
③ 任務運行與監控
一旦任務開始執行,NodeManager會為Container提供隔離的運行環境(如JVM),ApplicationMaster監視任務的運行狀態,并通過心跳與NodeManager通信,確保任務成功完成或在出現故障時重新調度任務。
④ 應用完成與資源回收
當ApplicationMaster檢測到所有任務均已成功完成,它會向ResourceManager發送一個"完成"信號,表示應用程序已經完成。隨后,ResourceManager會通知NodeManager釋放任務所占用的資源容器,集群整體資源狀態更新。
三、代碼實戰
在代碼實戰環節,我們將通過一個完整的示例來展示如何在 Java中實現一個 MapReduce任務,并將處理結果存儲回 HDFS。
任務描述:計算給定文件中每個單詞出現的次數文件格式:CVS或者JSON項目結構:項目結構如下:
wordcount/
├── src/
│ ├── main/
│ │ ├── java/
│ │ │ ├── WordsCounterMapper.java
│ │ │ ├── WordsCounterReducer.java
│ │ │ └── WordsCounterDriver.java
│ └── resources/
├── input/
│ └── input.cvs
│ input.cvs
└── output/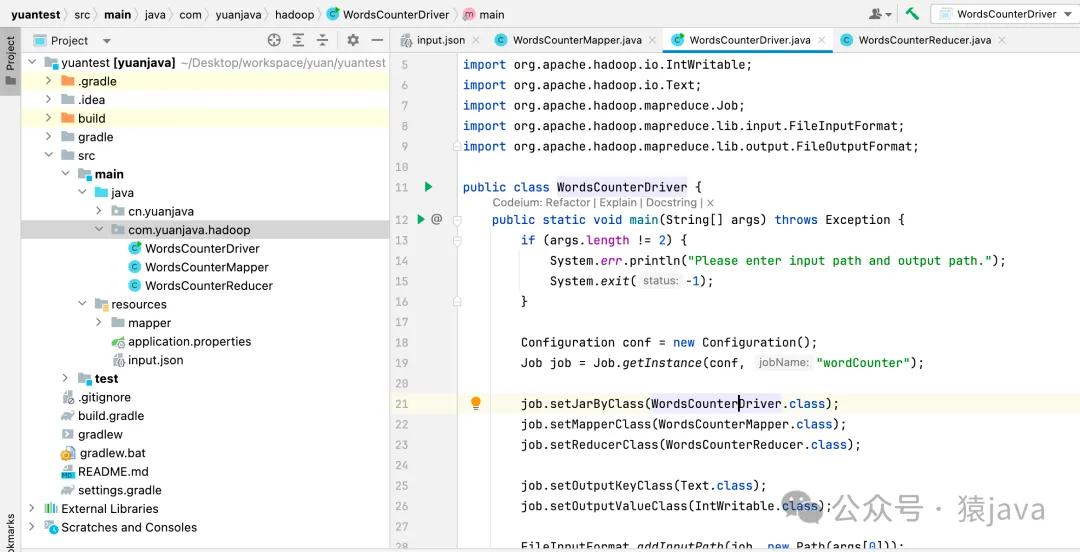
1.安裝Hadoop
我自己Mac電腦安裝的是 Hadoop-3.4.1,查看版本指令:hadoop version,關于安裝 Hadoop,可以參考這篇文章

2.處理文件
(1) 處理 CSV文件
假設我們有一個超大的 CSV文件:input.csv,如下內容只是展示前幾行數據:
id,name,address
1,yuanjava,hangzhou
2,juejin,beijin
3,didi,beijing
...我們可以使用開源的 Apache Commons CSV工具類來處理該文件,對應的依賴如下:
// maven依賴
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-csv</artifactId>
<version>1.12.0</version>
</dependency>
// gradle 依賴
implementation 'org.apache.commons:commons-csv:1.12.0'(2) 處理 Json文件
假設我們有一個超大的 Json文件:input.json,如下內容只是展示前幾行數據:
[
{"id": 1, "name": "yuanjava", "address": "hangzhou"},
{"id": 2, "name": "juejin", "address": "beijing"},
{"id": 3, "name": "didi", "address": "beijing"},
...
]我們可以使用開源的 Jackson庫來處理文件,對應的依賴如下:
// maven依賴
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
<version>2.18.1</version>
</dependency>
// gradle 依賴
implementation 'com.fasterxml.jackson.core:jackson-databind:2.18.1'3.增加 Hadoop依賴
// maven依賴
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>3.4.1</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>3.4.1</version>
</dependency>
// gradle依賴
implementation 'org.apache.hadoop:hadoop-common:3.4.1'
implementation 'org.apache.hadoop:hadoop-mapreduce-client-core:3.4.1'4.編寫 Mapper類
Mapper類的作用是處理輸入數據,并為每個輸入記錄生成鍵值對,在詞頻統計任務中,Mapper 的任務是將每個單詞映射為一個中間鍵值對 (word, 1)。
import com.fasterxml.jackson.databind.JsonNode;
import com.fasterxml.jackson.databind.ObjectMapper;
import org.apache.commons.csv.CSVFormat;
import org.apache.commons.csv.CSVRecord;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
import java.io.StringReader;
public class WordsCounterMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
private ObjectMapper objectMapper = new ObjectMapper();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString().trim();
if (line.isEmpty()) {
return; // Skip empty lines
}
// json以'{'開頭, CVS以'['開頭
if (line.startsWith("{") || line.startsWith("[")) {
processJson(line, context);
} else {
processCsv(line, context);
}
}
private void processJson(String line, Context context) throws IOException, InterruptedException{
JsonNode rootNode = objectMapper.readTree(line);
if (rootNode.isArray()) {
for (JsonNode node : rootNode) {
String name = node.get("name").asText();
word.set(name);
context.write(word, one);
}
} else if (rootNode.isObject()) {
String name = rootNode.get("name").asText();
word.set(name);
context.write(word, one);
}
}
private void processCsv(String line, Context context) throws IOException, InterruptedException{
StringReader reader = new StringReader(line);
Iterable<CSVRecord> records = CSVFormat.DEFAULT.parse(reader);
for (CSVRecord record : records) {
// Assuming the CSV has a header row and "name" is one of the columns
String name = record.get("name");
word.set(name);
context.write(word, one);
}
}
}5.編寫 Reducer類
Reducer類的作用是對來自 Mapper的中間鍵值對進行匯總,在詞頻統計任務中,Reduce 的任務是對相同單詞的計數進行累加。
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class WordsCounterDriver {
public static void main(String[] args){
if (args.length != 2) {
System.err.println("Please enter input path and output path.");
System.exit(-1);
}
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "wordCounter");
job.setJarByClass(WordsCounterDriver.class);
job.setMapperClass(WordsCounterMapper.class);
job.setReducerClass(WordsCounterReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}6.編寫 Driver 類
Driver 類用于配置 MapReduce 作業并啟動作業。它指定了 Mapper 和 Reducer 的實現類,以及輸入和輸出路徑等。
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class WordsCounterDriver {
public static void main(String[] args){
if (args.length != 2) {
System.err.println("Please enter input path and output path.");
System.exit(-1);
}
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "wordCounter");
job.setJarByClass(WordsCounterDriver.class);
job.setMapperClass(WordsCounterMapper.class);
job.setReducerClass(WordsCounterReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}7.運行和查看結果
(1) 運行步驟:
- 編譯和打包:將上述代碼編譯并打包成一個 JAR 文件。
- 上傳數據到 HDFS:將待處理的 CSV 和 JSON 數據上傳到 HDFS 的一個目錄中。
- 執行 MapReduce作業:在 Hadoop集群上運行該 JAR文件,并指定輸入和輸出路徑,指令如下:
hadoop jar wordcounter.jar WordCounterDriver input/input.cvs output/
hadoop jar wordcounter.jar WordCounterDriver input/input.json output/- /input/input.cvs(json) 是 HDFS上包含 CSV和 JSON文件的目錄。
- /output 是用于存儲結果的 HDFS目錄。注意:輸出目錄不能預先存在,否則作業將失敗。
(2) 查看輸出結果
任務完成后,輸出結果將會保存在指定的輸出目錄中,我們可以使用以下命令查看結果:
hadoop fs -cat output/part-r-00000輸出結果可能如下:
yuanjava 100
juejin 3000
didi 100
...8.代碼解釋與優化
(1) Mapper詳解
繼承與泛型:Mapper<LongWritable, Text, Text, IntWritable> 表示輸入鍵值對的類型和輸出鍵值對的類型。輸入鍵是行偏移量,值是行文本,輸出鍵是單詞,值是整數 1。
map 方法:對每一行文本進行分割,然后對每個單詞輸出一個鍵值對。
(2) Reducer詳解
繼承與泛型:Reducer<Text, IntWritable, Text, IntWritable> 表示輸入和輸出鍵值對類型。輸入鍵是單詞,值是整數列表,輸出鍵是單詞,值是單詞的累加計數。
reduce 方法:對每個單詞的所有計數進行累加輸出。
(3) Driver詳解
Job 配置:設置 Mapper和 Reducer類,指定輸入輸出格式。
路徑設置:通過命令行參數指定輸入輸出路徑。
(4) 優化建議
- Combiner使用:在 Map端進行部分匯總,減少傳輸到 Reduce端的數據量。
- 數據壓縮:啟用中間數據壓縮減少網絡傳輸開銷。
- 分區與排序:根據數據特性自定義分區器和排序規則。
通過這個簡單的例子,我們展示了如何在 Java中實現一個基本的 MapReduce程序,通過定義 Mapper和 Reducer 再結合 Driver,能夠實現對大規模數據集的分布式處理。如果要處理更復雜的任務,可以通過自定義分區器、排序規則、Combiner 等方式進行優化。
通過此示例,我們可以更好地理解 Hadoop MapReduce 的工作原理和編程模型以及它對于大數據處理的重要性。
四、總結
本文,我們分析了 Hadoop的核心組件及其工作原理,讓我們對 Hadoop有了一定的認識。本人有幾年 Hadoop的使用經驗,從整體上看,Hadoop的使用屬于中等難度,Hadoop的生態比完善,學習難度比較大,但是,不得不說 Hadoop的設計思維很優秀,值得我們花時間去學習。
2003年,Google發布 Google File System(GFS)、MapReduce和 Bigtable 三篇論文后,Doug Cutting和 Michael J. Cafarella抓住了機會,共同創造了 Hadoop。Google的這三篇經典論文是大數據領域的經典之作,但它的影響力遠不止大數據領域,因此,如果想成為一名優秀的工程師,閱讀原滋原味的優秀論文絕對是受益無窮的一種方式。
Hadoop展示了大數據領域一個優秀的架構模式:集中管理,分布式存儲與計算。這種優秀的架構模式同樣還運用在 Spark、Kafka、Flink、HBase、Elasticsearch、Cassandra等這些優秀的框架上,它在大數據領域展示了顯著的優勢。
最近一年,我從事的項目有幸和 MIT,Standford這樣頂尖學府出來的工程師合作,他們強悍的數學建模能力以及對同一個問題思考的深度確實讓我望塵莫及,在互聯網大廠卷了這么多年,每天都有寫完的需求開不完的會,絕大多數程序員都被業務裹挾著,導致很多優秀的人無法從業務中抽離出來去研究更深層領域的東西,陷入無盡的內卷。
如何在這個內卷的環境中讓自己立于不敗之地?基本功絕對是重中之重。
最后,因為 Hadoop的內容太多,很難僅憑本文把 Hadoop講透,希望在分享我個人對 Hadoop理解的同時也能拋磚引玉,激發同行寫出更多優秀的文章,對于技術,對于行業產生共多思考的共鳴。

























