詳解Java中的SPI技術以及在架構設計的運用
衡量一個架構設計的好壞,其中一個標準就是看這個架構是否具有可擴展性,架構設計中有很多常用的實現擴展性的技術,這次我們就來探討一下比較常見的 SPI 技術。
我們首先了解一下什么是 SPI,然后講一講 JDK 是如何基于 SPI 機制來獲取到具體的數據庫驅動實現的。接下來,我們分析 JDK SPI 機制的不足之處。最后,概要講解一下 Apache Dubbo 對 SPI 進行了哪些改進,以及 Apache Dubbo 是如何基于增強 SPI 實現 Dubbo 框架的可擴展性的。
服務提供者接口(Service provider interface,SPI),是指被第三方實現或者擴展的接口,它可以用來實現框架的擴展性和實現組件的可替換性。這里服務提供者接口中的服務是指一組接口和抽象類,服務提供者基于服務提供者接口來實現具體的服務。
JDK 中的 SPI 機制
了解了 SPI 的基本定義,我們接下來看一下 SPI 是如何在 JDK 中使用的。在 Java 開發中,我們經常使用下面這段代碼來獲取一個數據庫連接。
DriverManager.getConnection("a database url of the form jdbc:subprotocol:subnam");比如獲取 MySQL 數據庫連接,我們可以用如下代碼來操作:
DriverManager.getConnection("jdbc:mysql://localhost:3306/testDb?useUnicode=true&characterEncoding=UTF-8");或者要獲取 Oracle 數據庫連接,對應代碼如下所示:
DriverManager.getConnection("jdbc:oracle:thin:@localhost:3306:testDb");獲取完數據庫連接后,我們該怎么用呢?
基于 MySQL 數據庫的示例,下面這段代碼就展示了如何基于連接做數據庫表的操作:
public static void main(String[] argc) throws SQLException {
Connection con = null;
try {
//1. 獲取 MySQL 數據庫連接
con = DriverManager.getConnection(
"jdbc:mysql://localhost:3306/testDb?useUnicode=true&characterEncoding=UTF-8");
//2. 執行 SQL 語句
Statement stmt = con.createStatement();
ResultSet rs = stmt.executeQuery("SELECT * FROM table");
//3. 處理結果集數據
while (rs.next()) {
String name = rs.getString("name");
String desc = rs.getString("desc");
System.out.println(name + ", " + desc);
}
} catch (SQLException e) {
e.printStackTrace();
} finally {
//4. 關閉連接
if (con != null) {
con.close();
}
}我們先獲取到 MySQL 數據庫的一個連接,然后基于連接執行查詢操作,接著處理查詢操作返回的數據集,處理完畢后關閉連接。
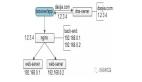
從上面示例可知,DriverManager.getConnection 方法根據傳遞的 database url 不同,可以獲取不同數據庫的連接,也就是說 DriverManager.getConnection 方法是與具體的數據庫驅動實現無關的。這是一個很好的設計,那么它是如何實現的呢?
首先,我們來剖析下 DriverManager.getConnection 的實現機制,我們列出來 DriverManager.getConnection 相關的類圖模型:
java.sql.Driver 文件的內容如下圖:
 圖片
圖片
Oracle 驅動包中 META-INF/services/java.sql.Driver 文件的內容如下所示:
 圖片
圖片
從 META-INF/services/java.sql.Driver 文件找到具體驅動的實現類的名稱后,會調用 ServiceLoader 內的 nextService 方法,使用 Class.forName(“驅動實現類名稱”…)來創建這個驅動的 Class 對象,然后通過 Class 對象的 newInstance() 方法創建一個驅動實現類的實例對象。
private S nextService() {
...
// 創建驅動實現類的 Class 對象
Class<?> c = null;
try {
c = Class.forName(cn, false, loader);
} catch (ClassNotFoundException x) {
fail(service,
"Provider " + cn + " not found");
}
...
// 基于驅動實現類的 Class 對象創建一個實例對象
try {
S p = service.cast(c.newInstance());
providers.put(cn, p);
return p;
} catch (Throwable x) {
...
}
}另外,我們會發現具體的驅動實現類,比如 MySQL 驅動的 Driver 類內,存在一個 static 的代碼塊。
public class Driver extends NonRegisteringDriver implements java.sql.Driver {
public Driver() throws SQLException {
}
static {
// 注冊 MySQL 驅動到 DriverManager
try {
DriverManager.registerDriver(new Driver());
} catch (SQLException var1) {
throw new RuntimeException("Can't register driver!");
}
}
}這個 static 代碼塊會在創建 Driver 的實例對象時被觸發執行,而上面 ServiceLoader 類的 nextService 方法內就創建了 Driver 的實例,所以觸發了 Driver 類的 static 代碼塊執行,也就是把 Driver 類注冊到了 DriverManager 中的 registeredDrivers 列表里面。
到這里,我們講解了 DriverManager.getConnection 內的一部分邏輯,也就是 loadInitialDrivers 方法的邏輯。它的內部使用 ServiceLoader 掃描 classpath 下所有的 jar 包,并找到實現 Driver 接口的驅動包,然后注冊驅動實現類到 DriverManager。
上面我們講解了如何注冊驅動到 DriverManager,下面我們繼續看當 DriverManager.getConnection 獲取數據庫連接時,如何使用驅動來具體獲取數據庫連接的:
private static Connection getConnection(
String url, java.util.Properties info, Class<?> caller) throws SQLException{}
...
// 遍歷 registeredDrivers
for(DriverInfo aDriver : registeredDrivers) {
if(isDriverAllowed(aDriver.driver, callerCL)) {
try {
// 從驅動獲取連接
Connection con = aDriver.driver.connect(url, info);
if (con != null) {
return (con);
}
} catch (SQLException ex) {
if (reason == null) {
reason = ex;
}
}
}
...
}
...
}
}由上面代碼可知,getConnection 方法內會遍歷 registeredDrivers 中的驅動實現類,然后調用驅動實現類的 connect 方法,每個驅動實現類的 connect 方法根據 URL 來判斷當前請求的 URL 是否需要自己處理,如果不需要就返回 null,否則返回具體的連接對象。
總的來說,JDK 對數據庫驅動進行了抽象,提供了 SPI 接口 Driver 和 Connection。然后,驅動開發者就可以實現這個 SPI 接口,來提供具體數據庫的驅動實現包。驅動開發者提供的驅動包里面需要包含 META-INF/services/java.sql.Driver 文件,并且文件內要寫入驅動實現類的類名。
JDK 提供的 ServiceLoader 機制會掃描 classpath 下的所有 jar 包,并且找到含有 META-INF/services/java.sql.Driver 文件的 jar,判定它為數據庫驅動包,然后 ServiceLoader 會根據實現類的名稱實例化這個驅動實現類,并注冊驅動實現類到 DriverManager 內。當我們調用 DriverManager 的 getConnection 方法時,就可以獲取到具體的驅動實現類并獲取數據庫連接了。
請注意,在 JDK 的 SPI 機制實現中,ServiceLoader 會把所有驅動實現包中的驅動實現類都實例化(創建一個對應的實例對象)。如果某些驅動實現類初始化很耗時,實例化會很浪費資源,并且會降低應用啟動速度。
Dubbo 中的 SPI 機制
Apache Dubbo 是一款微服務框架,為大規模微服務實踐提供高性能 RPC 通信、流量治理、可觀測性等解決方案。
Dubbo 的 SPI 實現借鑒了 JDK 的 SPI 思想,但是進行了一些優化改進,解決了 JDK SPI 的以下問題:
- JDK SPI 會一次性實例化所有實現類,有的擴展實現類初始化很耗時,但實際又沒用,還會拖慢啟動速度;
- JDK SPI 在實例化擴展實現類失敗時,不會友好地通知用戶具體異常。
Dubbo SPI 增加了對擴展實現類的 IoC 和 AOP 的支持,一個擴展實現類可以直接注入其它擴展實現類,也可以使用 Wrapper 類對擴展實現類進行功能增強。
Dubbo 框架的實現采用了分層架構思想,架構中的每層都是一個獨立模塊,上層依賴下層提供的功能,下層對上層提供服務,下層的改變對上層不可見。
 圖片
圖片
在這個架構圖中,從上往下看,除去 Service 和 Config 層是 API 層外,剩下的從 Proxy 層到 Serialize 層都是 SPI 層,這意味著從 Proxy 層到 Serialize 層每層都是可擴展的、可被替換的。
比如,Cluster 層默認提供了豐富的集群容錯策略,但是如果開發者有定制化需求,可以通過 Dubbo 提供的 SPI 擴展接口 org.apache.dubbo.rpc.cluster.Cluster 提供個性化的集群容錯策略,其中 SPI 接口 org.apache.dubbo.rpc.cluster.Cluster 的定義如下:
@SPI("failover")
public interface Cluster {
@Adaptive
<T> Invoker<T> join(Directory<T> var1) throws RpcException;
}我們通過 CustomCluster 類實現了 SPI 接口——Cluster,其中 CustomClusterInvoker 為具體的容錯策略的實現。
public class CustomCluster implements Cluster {
@Override
public <T> Invoker<T> join(Directory<T> directory) throws RpcException {
return new CustomClusterInvoker<>(directory);
}
}創建好 CustomCluster 類后,我們需要在 resources 目錄下創建一個名稱為 META-INF.dubbo 的文件夾,然后在它的下面創建一個名為 org.apache.dubbo.rpc.cluster.Cluster 的文件,文件內容為:customCluster=org.apache.dubbo.demo.cluster.CustomCluster。
 圖片
圖片
最后,我們在消費端發起請求時,可以設置集群容錯策略。
// 0.創建服務引用對象實例
ReferenceConfig<GreetingService> referenceConfig = new ReferenceConfig<GreetingService>();
// 1.設置應用程序信息
referenceConfig.setApplication(new ApplicationConfig("first-dubbo-consumer"));
// 2.設置服務注冊中心
referenceConfig.setRegistry(new RegistryConfig("zookeeper://127.0.0.1:2181"));
// 3.設置服務接口和超時時間
referenceConfig.setInterface(GreetingService.class);
// 4.設置集群容錯策略
referenceConfig.setCluster("customCluster");
// 5.設置服務分組與版本
referenceConfig.setVersion("1.0.0");
referenceConfig.setGroup("dubbo");
// 6.引用服務
greetingService = referenceConfig.get();代碼 4 就是我們設置的集群容錯策略——customCluster。你可能會問,Dubbo 如何根據集群容錯策略的名稱——customCluster 找到具體的容錯策略實現類呢?其實就是通過 Dubbo 的增強 SPI 機制來實現的,這個機制和 JDK SPI 機制差不多。
總結
 圖片
圖片
今天我們首先學習了 SPI 的定義,然后基于 JDK 中數據庫驅動的例子,重點講解了如何基于 SPI 來實現數據庫驅動的擴展性。JDK 對數據庫驅動進行了抽象,提供了抽象的 Driver 和 Connection 接口,這些接口就是 SPI 接口。
具體的驅動包實現者可以實現這些 SPI 接口來實現具體數據庫驅動。JDK 通過使用 ServiceLoader 機制來掃描驅動包的實現類,并注冊這些驅動到 DriverManager,所以我們可以通過 DriverManager.getConnection 方法獲取數據庫連接。
接下來,我們了解了 JDK SPI 的不足,概要介紹了 Dubbo 中增強的 SPI 的特點以及 Dubbo 如何基于 SPI 實現可擴展性。最后,我們基于 Dubbo 的集群容錯策略擴展接口,講解了 Dubbo 中如何來實現擴展。