高并發場景下,Kafka如何實現百萬級吞吐?
Kafka是大型架構必備技能,下面我就重點詳解Kafka生產者如何實現高吞吐@mikechen
批量發送優化
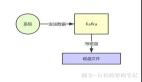
Kafka 的 Producer 并不是每寫一條消息就立即發送,而是將多條消息收集起來。
組成一個批次(batch)一起發送,以減少網絡開銷并提高吞吐。
 最新文章
最新文章
這里適當增加 linger.ms 的值(例如:設置為幾毫秒…..到幾十毫秒)。
[ProducerRecord]
↓
[BufferPool]←多條消息緩沖
↓
[Batch formed ]←達到 batch.size 或 linger.ms 觸發發送
↓
[KafkaBroker]允許生產者收集更多消息形成更大的批次,從而提高吞吐量。
但需要注意,過高的 linger.ms 會增加消息的端到端延遲。
異步發送機制
Kafka Producer 的 send() 方法是異步的,調用后會立即返回一個 Future<RecordMetadata> 對象。
 最新文章
最新文章
producer.send(record,(metadata, exception)->{
if(exception ==null){
System.out.println("Success: "+ metadata.offset());
}else{
exception.printStackTrace();
}
});生產者發送消息后不立即等待 Broker 的響應,而是繼續發送后續消息,通過回調機制處理發送結果。
這樣,生產者無需等待 Broker 的確認,可以流水線式地發送消息,極大地提高了發送速率。
壓縮機制
在生產者端對消息數據進行壓縮,減小網絡傳輸的數據量,從而提高有效吞吐量。
 最新文章
最新文章
比如:
gzip: 壓縮率高,但 CPU 消耗也相對較高。
snappy: 壓縮和解壓縮速度快,CPU 消耗較低,壓縮率適中。
在吞吐量和 CPU 利用率之間提供了較好的平衡,是常見的選擇。
lz4: 壓縮和解壓縮速度非常快,CPU 消耗很低,但壓縮率可能不如 gzip 或 snappy,適用于對延遲非常敏感的場景。
zstd: 提供比 gzip 更高的壓縮率,同時保持良好的壓縮和解壓縮速度,但 CPU 消耗可能略高。
在高吞吐場景中推薦使用 lz4 、或 zstd。
在對 CPU 敏感的系統中可選擇 snappy。
并發發送能力
Kafka Broker 利用 Page Cache 順序寫,提高寫入效率。
 最新文章
最新文章
當 Kafka Broker 接收到生產者的消息并需要將其寫入磁盤時,它首先將數據寫入到操作系統為該日志文件維護的 Page Cache 中。
由于是順序寫入,新的數據總是追加到 Page Cache 的尾部,這是一個非常快速的內存操作。
順序寫極大地減少了磁盤尋道時間,而 Page Cache 的使用將大部分寫操作變成了快速的內存操作,只有在操作系統進行刷盤時才會有磁盤 I/O。
這種機制,使得 Kafka Broker 能夠承受非常高的寫入吞吐量。